Why Shift to CNNs: Solving Simple Neural Network Limitations and Understanding CNN [part1]
 Muhammad Fahad Bashir
Muhammad Fahad Bashir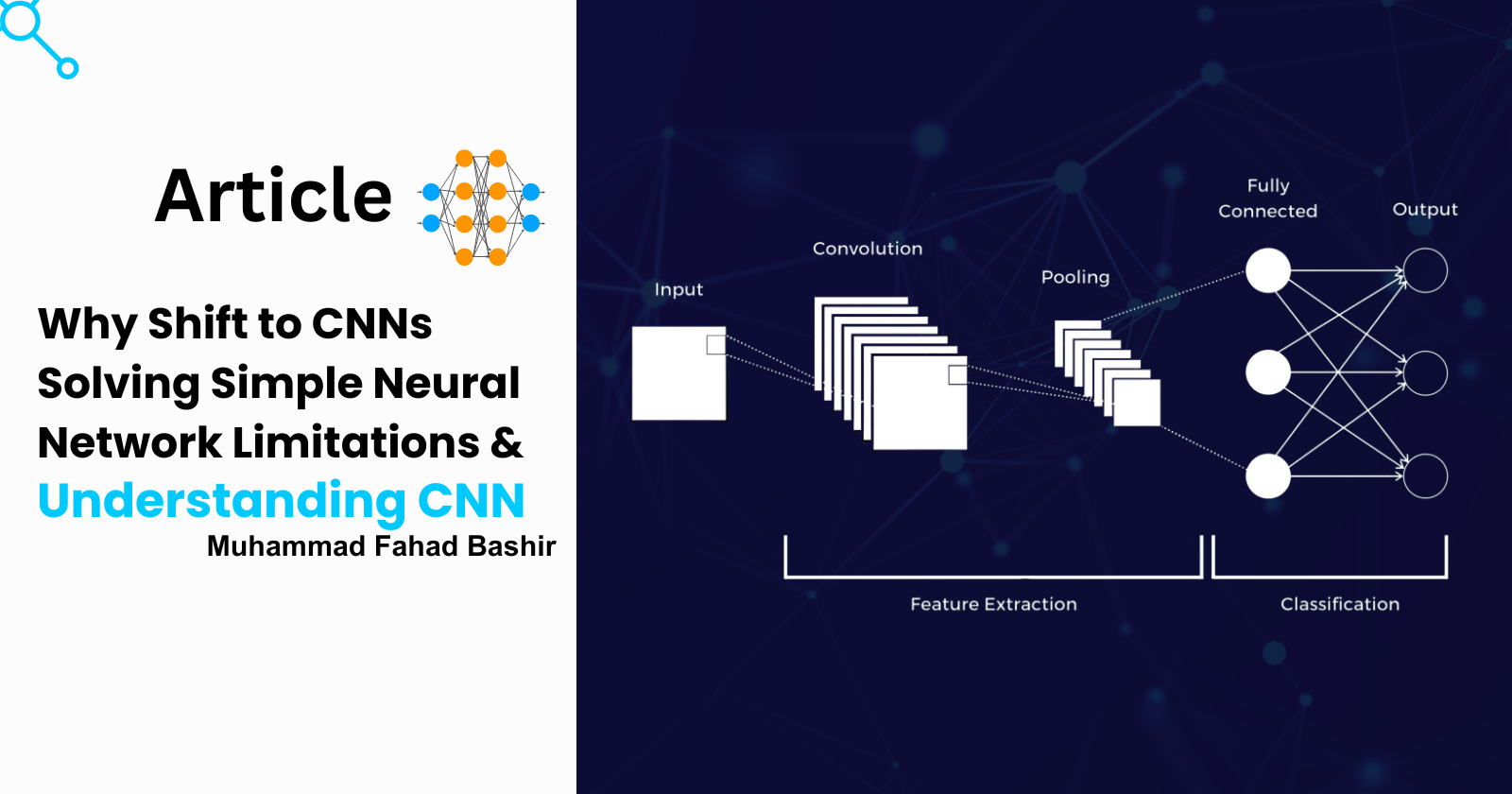
Today, we’re excited to explore one of the most widely used neural networks, especially in image processing: Convolutional Neural Networks (CNNs).
You might be wondering — we already have simple neural networks that can handle images as we explored in previous article - Neural Networks Simplified: The Future Beyond Traditional ML . So, why did we feel the need to move to CNNs? After all, simple neural networks can perform tasks like classification, and they’re easier to understand.
Well, here’s the reason:
Limitations of Simple Neural Networks
Fully Connected Structure
In a simple neural network, each neuron is connected to every neuron in the next layer (this is what we call fully connected). So, if we add just one neuron, it gets connected to all the neurons in the next layer, which increases the number of parameters drastically.
Imagine dealing with an image that’s even a modest size — say 32x32 pixels. The number of parameters grows exponentially as the image size increases. Now, think about images in today’s world, where we have megapixel-sized images. A simple neural network just can’t handle that efficiently; it would need billions of parameters for just one image. This takes a lot of time and costs a lot of computational power.
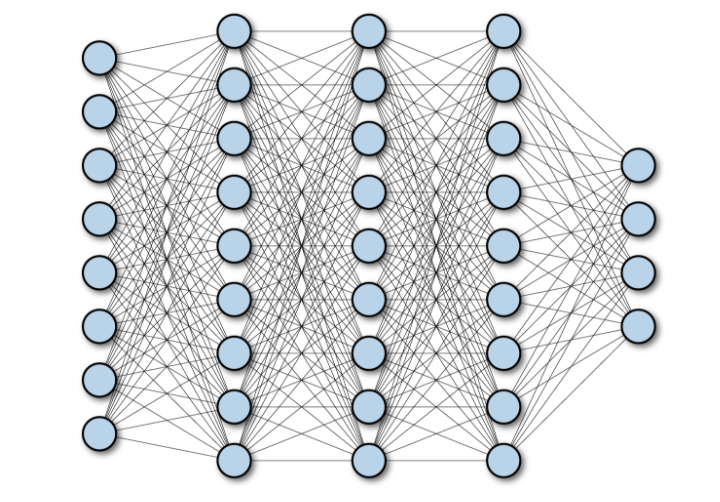
Example:
Let's say you have an image of size 32x32 pixels with 3 color channels (RGB), which is very common. So, the total number of input neurons would be:
32 x 32 x 3 = 3,072 input neurons.
Now, imagine you have a fully connected layer with 1,000 neurons. Each neuron in this layer is connected to every input neuron. So, the total number of parameters (weights) required to connect this layer to the input would be:
3,072 input neurons x 1,000 neurons = 3,072,000 parameters.
That’s already over 3 million parameters for a single layer, and this is for a relatively small image.while if f the image is 128x128 pixels with 3 channels with same number of neuron then
128 x 128 x 3 = 49,152 input neurons.
49,152 input neurons x 1,000 neurons = 49,152,000 parameters.
Loss of Image Information:
Another limitation is that simple neural networks convert images into 1D arrays before processing them, meaning we lose important spatial information like the position of pixels and other intricate details.
Sure, a simple neural network can give an answer for basic images, but when it comes to complex images, it starts to struggle. That’s because it can’t effectively capture local patterns and structures within the image.
Why CNNs Are Better
CNNs drastically reduce the number of parameters because they only connect neurons locally. Instead of connecting every neuron to every other neuron, CNNs use small filters that slide over the image. This not only preserves the spatial structure of the image but also reduces the computational load, allowing CNNs to handle large, high-dimensional images more efficiently.
For example, instead of having millions or billions of parameters for a single layer, CNNs only need thousands of parameters, which makes them far more scalable and practical for image-related tasks.
Understanding Convolutional Neural Networks (CNNs)
So, to overcome the limitations, we turn to Convolutional Neural Networks (CNNs). CNNs are mainly used in tasks related to images and videos, like classification, object detection, and more.
The convolution operation itself has been around for years in image processing, and CNNs have built on that trusted foundation. CNNs perform these convolutions through convolutional layers, and instead of connecting each neuron to all others like in simple neural networks, CNNs focus on smaller, localized regions of the input.

How Do CNNs Work?
The main idea behind CNNs is the use of filters (small matrices) that slide over the input image to detect patterns. Let’s break it down:
Convolution Operation:
The convolution operation applies filters to the image. These filters are small grids of numbers that move (or “slide”) over the image and perform mathematical operations to create feature maps.
This allows CNNs to detect features such as edges, textures, and patterns in the image. Each filter has a specific task — one might detect vertical edges, while another could detect horizontal edges.Convolutional Layers:
These layers are where the filters are applied to the image. Early layers detect basic features (like edges), while deeper layers start detecting more complex patterns and structures.
The key point is that each convolutional neuron performs convolutional operations to detect features, and these neurons don’t lose the image's structure — unlike fully connected neural networks.
Source Image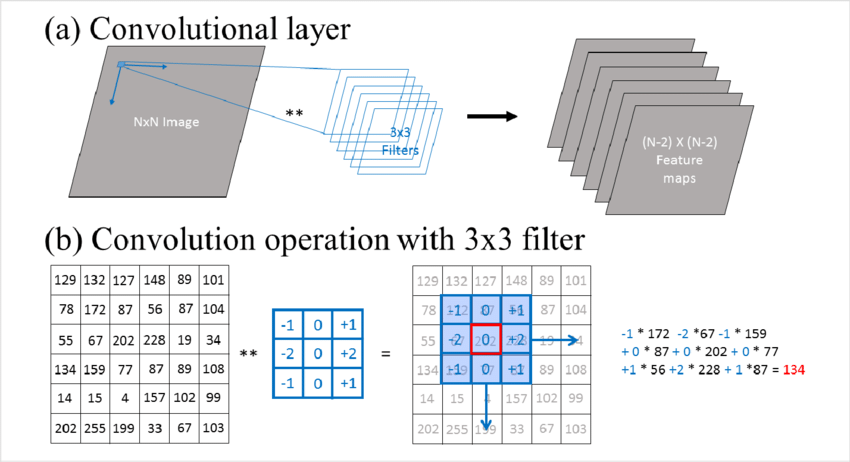
Feature Hierarchy:
As the image passes through successive convolutional layers, the network starts recognizing more complex features. So, the first layer might detect simple lines or edges, and as the image goes through more layers, the network can recognize more sophisticated patterns like shapes or even objects.Pooling Layers:
After each convolutional layer, there’s usually a pooling layer, which helps summarize the feature maps. Pooling layers reduce the size of the feature maps, making the network more efficient by focusing on the most important features.Think of pooling layers as taking the essence or summary of the features detected in the convolutional layers and passing it forward.
Image Source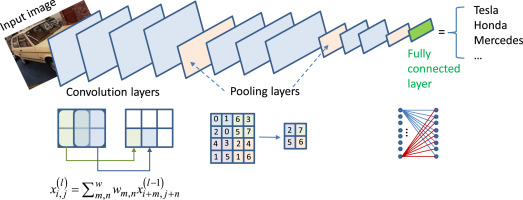
Fully Connected Layer (FCN):
After all the convolutions and pooling operations, the final step involves using a fully connected layer (similar to what we see in traditional neural networks).
Here, the CNN uses all the extracted features to make its final prediction, whether it’s classifying the image or detecting an object.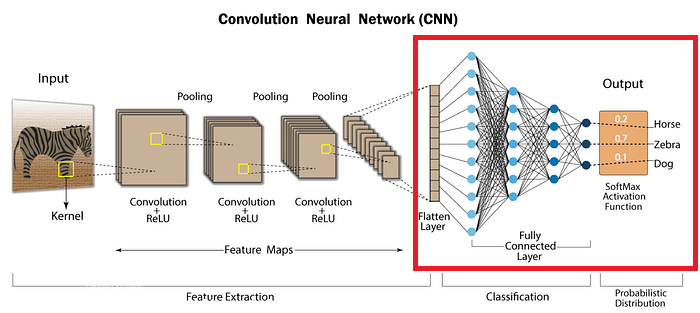
CNN Structure
To summarize, a typical CNN consists of:
Convolutional Layer:
Applies the convolution operation, detects basic and complex features.Pooling Layer:
Reduces the size of the feature maps and summarizes the important features.Flattening Layer:
Converts the output of the last pooling layer into a 1D array to prepare it for the fully connected layer.Fully Connected Layer:
Takes the flattened features and gives the final output, such as classifying the image.
A complete picture for understanding CNN is
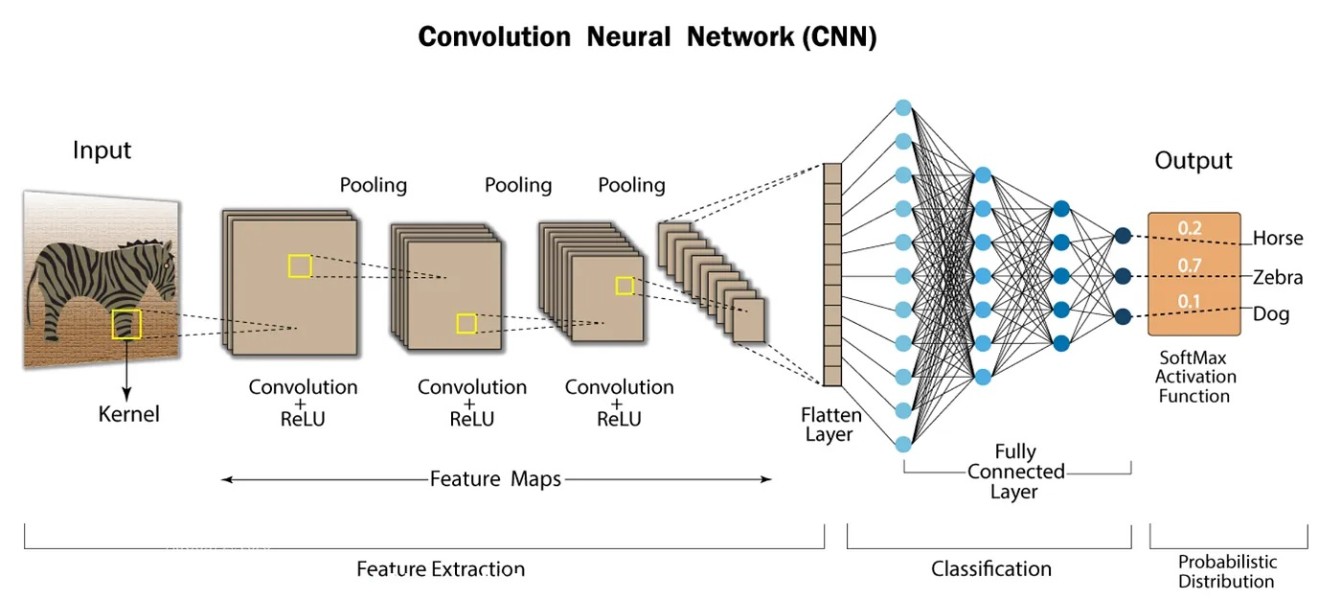
Conclusion
So, to wrap things up, CNNs solve the problems that traditional neural networks face when it comes to handling images. CNNs keep the spatial structure of the image intact and significantly reduce the number of parameters, making them efficient and capable of processing today's high-dimensional data. CNNs have transformed the way we work with images, allowing us to extract both simple and complex features, all while saving on computation time and resources.
Subscribe to my newsletter
Read articles from Muhammad Fahad Bashir directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by