Getting Started with Chaos Engineering on Azure
 Niels Buit
Niels Buit
Chaos Engineering as a discipline within Site Reliability Engineering has been around for quite a few years. It was eventually adopted on a cloud-scale by Netflix, who used their infamous Chaos Monkey tool to put the resiliency features of production systems to the test. Given the recent General Availability status of Azure Chaos Studio, the topic deserves some attention in an Azure context.
So we're causing chaos?
By definition, Chaos Engineering is not about introducing chaos into your solution. It’s about gaining confidence in your solution thriving amidst the chaos of a distributed system, such as a public cloud. This distinction is important to make, because the thought of introducing chaos may not appeal to those tasked with improving reliability.
Rather, Chaos Engineering is the practice of subjecting a system to the real-world failures and dependency disruptions it will face in production. It comes with a structured, almost scientific approach to experimentation. A hypothesis is formed, an experiment is conducted, results are analyzed, and improvements are deployed, after which the cycle restarts.
Should everyone be doing this now?
Chaos Engineering is an advanced practice in reliability engineering. This is an important consideration, because if you are just starting out with cloud solutions or are working through an initial round of reliability improvements, then there may be a other things focus on first before picking up Chaos engineering. A good start would be to improve monitoring and deployment automation first. These are instrumental in both directly improving reliability as well as supporting the experimentation cycle mentioned above:
Your cloud solution should have monitoring in place to understand what is going on. If you can't measure the results, there's not much use in doing experiments. There's many tools for monitoring and Azure has first party services to this end. However, collecting data and showing it on a dashboard is not sufficient in larger or more complex solutions. You need to understand when the solution is in a healthy state, i.e. when everything is working as designed. Additionally, you need to know what the (business) impact of an outage is. This is where a Health Model can be useful. For more details, refer to my earlier blog post.
Another key aspect of the Chaos Engineering experimentation cycle is making rapid improvements based on the results of the experiments. This can only happen if there is a well-defined and properly automated process to push changes out to production. If production deployments are cumbersome and time consuming or you have no way of ensuring consistency between environments, you should consider addressing this first.
Do we do this in the production environment?
Yes! Well, maybe no. It depends.
In a Continuous Validation approach, Chaos experiments may be part of CI/CD pipelines. These tests should be performed in a dev or test environment. Ideally this is a (dynamically created) environment specifically for this purpose. Like a unit test deployed with a code feature, a chaos experiment should accompany a resiliency feature and be run during the automated testing phase. The execution could be triggered by the change path in the code repository. For example, the experiment from our previous example could be run during a PR build every time a change is made to the infrastructure template, proving the solution can still handle n requests when one compute node dies. Additionally, you could run all the tests before moving a code branch to a higher environment.
Alternatively, you can take a game-day or BCDR Drill approach. This can help to validate the assumptions, identify the weaknesses, and improve the resilience of the system under various disaster scenarios. The advantage over this approach is that it can also help train the teams on how to respond to incidents and collaborate effectively to resolve incidents. For this reason, performing experiments in the production environment would bring extra value. The experiments can be designed to target specific components, regions, or layers of the system, or to simulate realistic scenarios such as compute failures, network timeouts, or service degradation. In some cases, such as under specific regulatory regimes in some regions, validating resiliency measures is required to happen in production.
Finally, there's the Chaos Monkey. The monkey that swings through your datacenter along dangling ethernet cables and wreaks havoc on anything it can find, famous from the Netflix story. In reality it may not be swinging through your application as randomly as the story leads to believe, but rather picks faults from a list to apply to components from another list. This only works if you've built in resiliency measures at every level in your cloud application, and the blast radius of the monkey's faults is thus contained to a small area, away from impacting real customers. Needless to say such practice is suitable only for those with a very mature reliability engineering practice.
Don’t forget that to properly evaluate the response to a fault, you also need realistic traffic patterns. There’s not much value in testing the application with no requests coming in, since everything behaves differently. If you’re not testing on your production environment, make sure to combine the chaos experiment with a load test, simulating regular traffic.
What should we be testing?
Reliability Engineering
The proper way to come up with chaos experiments is through a process for reliability engineering, in which you examine your application through a reliability lens:
Create a map of your application. Start with identifying Critical Flows and form the dependency tree for each of them.
Create a health model for your application. This helps you understand what it means to be healthy and, if something goes wrong, the impact on your business.
For each component on the dependency tree, identify what could go wrong. The state of the system in which something went wrong is called a Failure Mode. Not only do we want to know how big the chance is that the failure mode occurs, we also want to know the potential impact and how likely is that we can see it coming and stop it. In essence: Risk = Probability x Impact x Undetectability.
For the high risk failure modes, implement mitigations. These can include using multiple zones or regions, inserting caching or CDN layers at strategic places, relying on default values where lookups fail, etc.
Validate that your mitigations have been implemented correctly using chaos experiments. This will give you confidence that they will work if the failure occurs, and ensure that there are no surprising side effects.
For each mitigation, you’ll need an experiment that simulates the failure mode you’re mitigating for. If the failure mode renders a resource unavailable, you can block access to the resource. If the failure mode is about slow responses, you can add simulated network latency, etc. Common failure modes to mitigate for in cloud services are resource unavailable, increased response latency, or incorrect or corrupt response. Azure Chaos Studio supports creating faults for these situations.
Common Scenarios
We’ll discuss two common scenarios here, based on common mitigations for failure modes: Zone Resiliency and Multi Region Resiliency
Validating Zone Resiliency
Each Azure region is built up of three availability zones, which are independent datacenter facilities with their own cooling, power, and network. The idea is that failures are contained to a single AZ, leaving the other two running. Customers are responsible for ensuring their applications take full advantage of this model:
Virtual Machines should be deployed to each of the zones. Virtual Machine ScaleSets should be spread out over the zones.
Azure-managed services (PaaS) should have ‘zone redundancy’ enabled as a configuration option.
Because the zone redundancy of PaaS services is managed by Microsoft, Microsoft is responsible for testing this. This is outside the scope of your chaos experiments. You do, however, need to validate that the zonal resources (VMs) your application runs on are able to handle the zonal failure. This specifically important for cluster-based workloads (e.g. AKS or Service Fabric), where you need to validate that the configuration for re-balancing the nodes (scheduling, replica counts, taints, etc) was done correctly.
Chaos Studio has a template for creating a zone down simulation on VM resources.
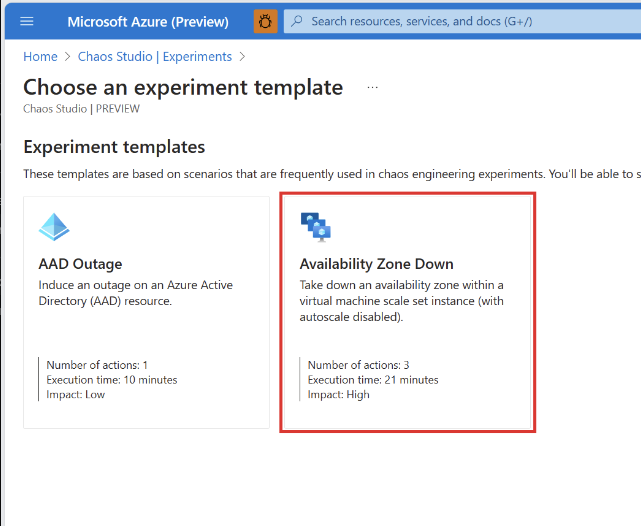
You can use this template to create the experiment needed to disable autoscale and shutdown compute nodes on a specific availability zone. This will ensure that both your application as well as your cluster configuration are capable of handling a zonal outage. Don’t forget to combine the experiment with a load test that will simulate your regular traffic patterns. And can two zones handle the traffic normally handled by three?
Validating Multi-Region Resiliency
Another common resiliency measure is the multi-region deployment. Depending on architectural constraints, your application may serve requests in multiple regions all the time (active-active), or only after you’ve failed over (active-passive). Testing this scenario starts with simulating a failure of the primary region, after which either traffic is rebalanced and handled by the other region (active-active), or your failover process kicks in and the secondary region is activated.
Simulating a multi-region outage for the purpose of seeing traffic switch is not very complicated. This can usually be done by creating a network security group that blocks traffic from the global load balancer into the region. However, one of the key principles of a multi-region architecture is that all cross-region dependencies have been eliminated. If this is not the case, you want to learn that now rather than in a real failover scenario. To add some realism here, you can use a chaos fault to shutdown the compute instances in the primary region and create Network Security Group rules that deny all incoming traffic. This will block any cross-region connection attempt.
I hope this article will inspire you to get started with reliability engineering and Chaos Studio! The official documentation also has some great content on the topic, including an up to date list of the faults you can simulate with it.
Subscribe to my newsletter
Read articles from Niels Buit directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Niels Buit
Niels Buit
I work in the Customer Architecture & Engineering team at Microsoft. We help customers around the globe build the best solutions on Azure. The content of this blog should be considered personal opinion and is not an official Microsoft publication.