Enabling Column Mapping For Spaces In Column Names In Delta Table
 Sandeep Pawar
Sandeep PawarOne of the annoying limitations of Direct Lake (rather of the SQL endpoint) was that you could not have spaces in table and column names in the delta table. It was supported in the delta table but the table was not query-able in the SQL endpoint which meant you had to rename all the tables and columns in the semantic model with business friendly names (e.g. rename customer_name to Customer Name). Tabular Editor and Semantic Link/Labs was helpful for that.
But at #FabConEurope, support for spaces in table names was announced and is supported in all Fabric engines. You have to use the backtick to include spaces, as show below.
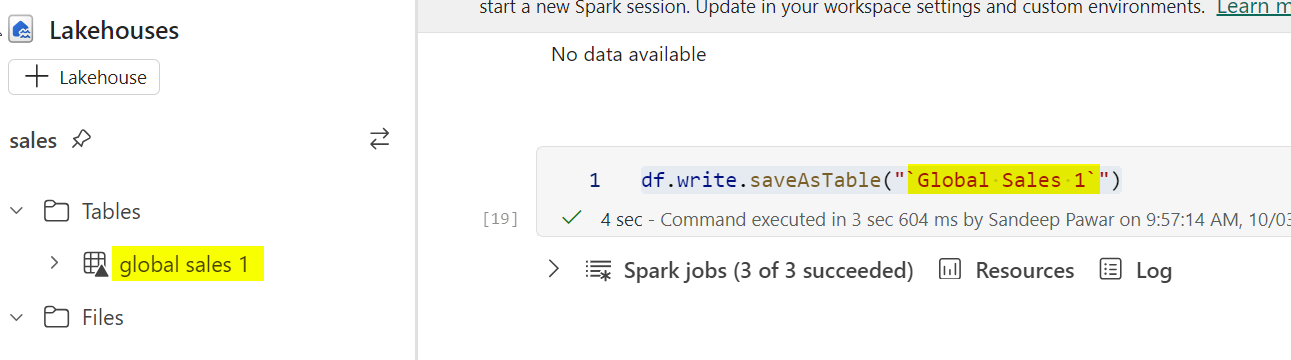
It’s available in the SQL analytics endpoint and Direct Lake without any issues:
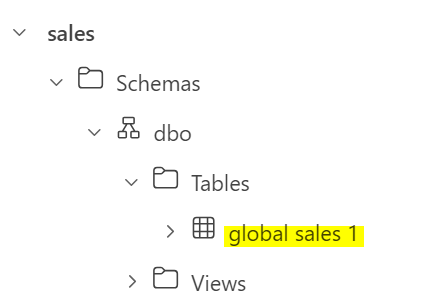
However, notice that I wanted my table name to be Global Sales 1 with title case but it appears in small case in LH explorer and SQL EP.
We can fix this by using save() instead of saveAsTable() by providing abfss path:
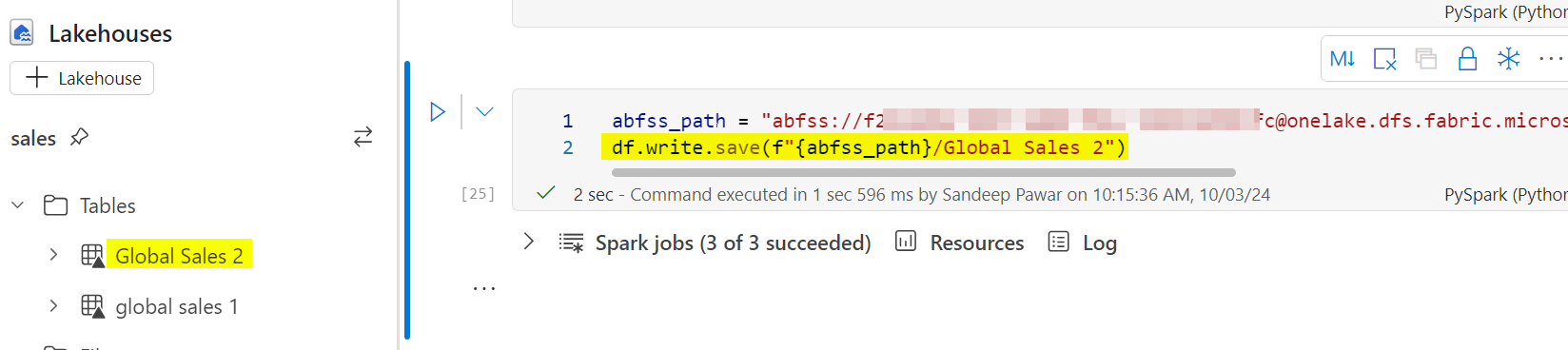
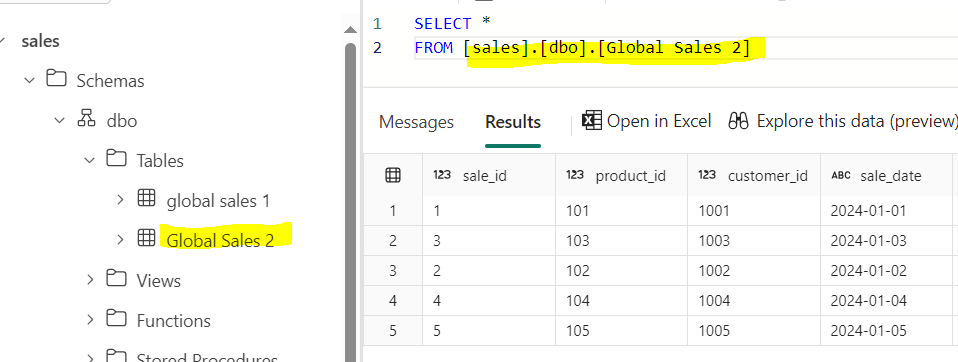
This fixes the table name problem without any additional configuration changes. However, if you try to save the table with spaces in column names, you will get an error recommending you to enable column mapping to support spaces and special characters.

To enable spaces in column names, you will need to enable column mapping and upgrade the delta protocol to minReader=2 and minWriter=5.
%%sql
ALTER TABLE `Global Sales 2` SET TBLPROPERTIES (
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5',
'delta.columnMapping.mode' = 'name'
)
Next, we can use ALETR TABLE to update the schema :
def rename_columns(table_name="Global Sales 2"):
"""
Renames columns of delta table to remove underscores and use title case.
Either use a rename function or provide your own mapping.
"""
#optional
def rename_column(name):
return name.replace("_"," ").title()
column_mapping = {
"sale_id": "Sale Id",
"product_id": "Product Id",
"customer_id": "Customer Id",
"sale_date": "Sale Date",
"sale_amount": "Sale Amount",
"discount_amount": "Discount Amount",
"tax_amount": "Tax Amount",
"total_amount": "Total Amount",
"store_id": "Store Id",
"sales_rep_id": "SalesRep Id"
}
for old_name, new_name in column_mapping.items():
alter_statement = f"ALTER TABLE `{table_name}` RENAME COLUMN `{old_name}` TO `{new_name}`"
spark.sql(alter_statement)
print(f"Columns in table '{table_name}' have been renamed.")
rename_columns()
You can use your own column mapping function. It works in SQL EP as well as in Direct Lake semantic model :
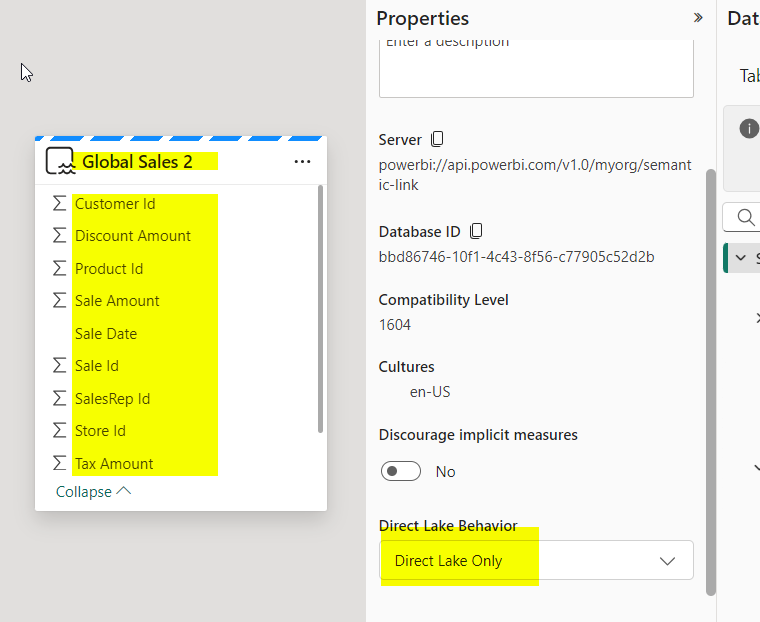
Notes:
This should work in Dataflow Gen 2 but I have not tested.DFg2 does not support it yet.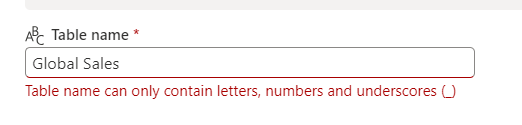
In DWH, you do not need to do anything.
Onelake integrated semantic models (i.e. import semantic model saved as Delta tables to OneLake) could not be used in DL mode. But with column mapping supported, I think it should work- but I haven not tested it.
My understanding is you can always upgrade the protocol but not downgrade. For example, for Liquid Clustering in runtime 1.3, you will need minWriterVersion = 7 which is higher than 5 so both LC and column mapping should work. Be sure to test it.
I tested runtime 1.3 but I think it should work in runtime 1.2 as well.
Miles Cole (Principal PM, Fabric CAT) has an excellent blog on Delta lake versions, features etc. I recommend checking it out.
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.