Mastering ML-Based Software Development: From Data to Code
 Riya Bose
Riya Bose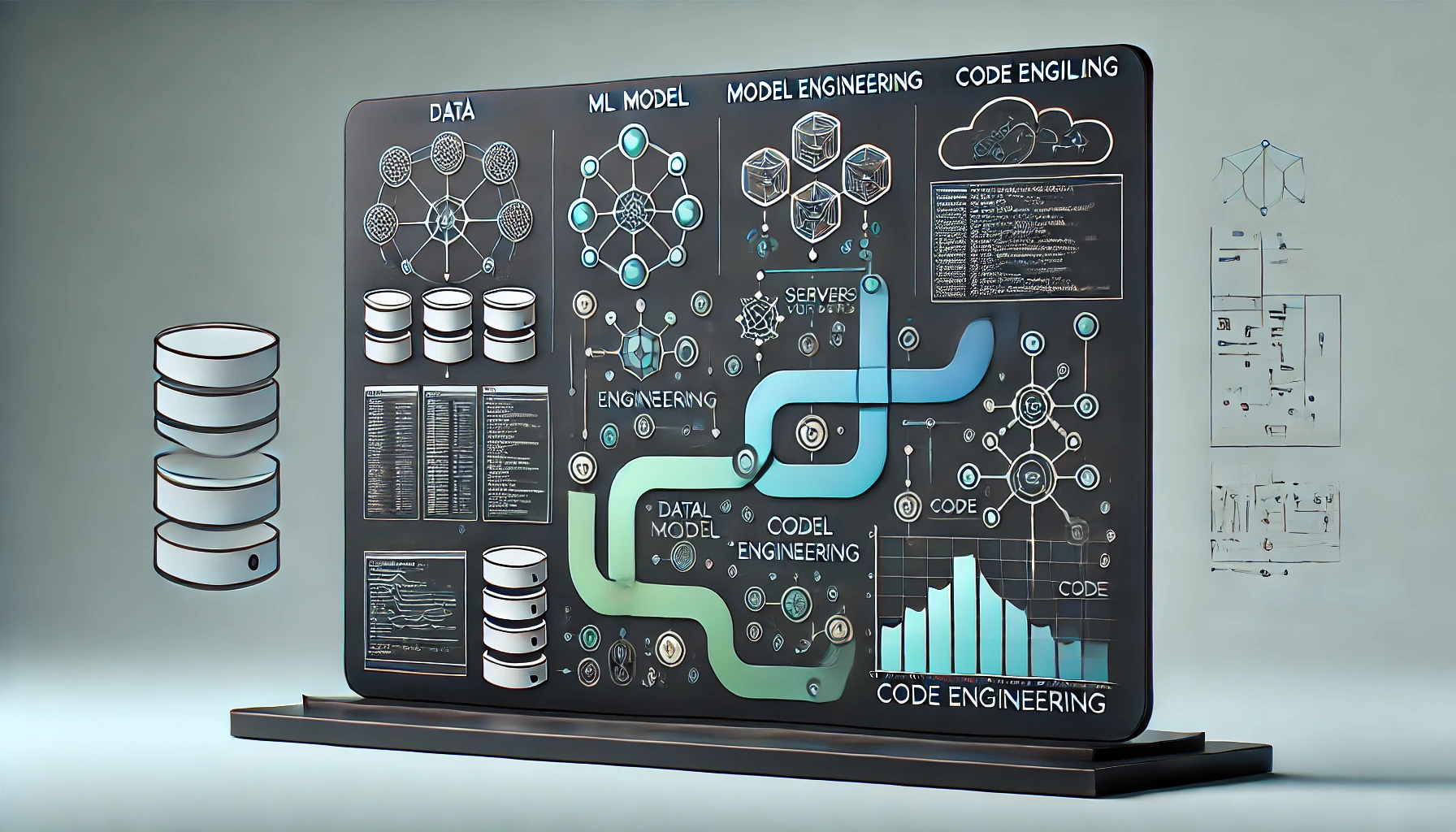
In machine learning (ML)-based software development, three primary artifacts drive the entire process: Data, ML Model, and Code. These artifacts are interconnected and serve as the foundation of any ML application. The development journey can be broken down into three phases:
Data Engineering
ML Model Engineering
Code Engineering
Each of these phases plays a crucial role in ensuring the success of an ML project. In this blog post, we will explore these phases in detail, covering the importance of each artifact, the steps involved in their engineering pipelines, and the role they play in developing robust ML-based applications.
Data Engineering: The Foundation of ML
Data engineering is the starting point of any ML project. It is the most resource-intensive and time-consuming phase because it involves dealing with large, complex datasets that need to be processed before they can be used for model training. The goal is to prevent the propagation of data errors into subsequent phases, ensuring high-quality input for the ML model.
Key Tasks in Data Engineering
Data Acquisition and Preparation: The first step is acquiring data from various sources. This could be real-time data, historical data, or a combination of both. Once acquired, the data needs to be preprocessed and cleaned to ensure it's suitable for model training.
Why It’s Time-Consuming: This phase involves dealing with missing data, noisy data, and inconsistencies that must be addressed. Given the nature of real-world datasets, this step often takes up most of the project time and resources.
Data Engineering Pipeline
Data Integration: Gathering data from multiple sources, such as databases, APIs, and flat files, and integrating them into a unified dataset.
Data Exploration and Validation: Investigating the dataset to understand its structure, correlations, and quality. This step includes validating whether the data fits the project needs.
Data Wrangling: Transforming and cleaning data by removing duplicates, handling missing values, and converting formats.
Data Labeling: For supervised learning models, it’s crucial to label the data, marking features that the model will learn to predict.
Data Splitting: Splitting the data into training, validation, and test sets. This step is critical to ensuring the model’s performance is evaluated correctly.
ML Model Engineering: The Core of Machine Learning
The second phase, ML Model Engineering, is at the heart of the machine learning workflow. This phase involves writing and executing machine learning algorithms to produce the final model. A robust model engineering process ensures the development of a performant and scalable ML model.
Key Tasks in ML Model Engineering
Obtaining the ML Model: The ML model is derived by training it on prepared data using various algorithms (e.g., decision trees, neural networks). The model's purpose is to learn from the data and make predictions on unseen examples.
Execution of Algorithms: Selecting the right algorithms and hyperparameters for training the model is crucial. Models can range from simple linear regression models to complex deep learning architectures.
ML Model Engineering Pipeline
Model Training: In this step, the model is trained on the training data, allowing it to learn patterns and relationships within the data. Hyperparameters are tuned to achieve optimal performance.
Model Evaluation: After training, the model is evaluated on the validation dataset to measure its performance. Evaluation metrics like accuracy, precision, recall, and F1-score are used to assess the model.
Model Testing: Once the model is validated, it's tested on an unseen test dataset. This ensures the model generalizes well and performs consistently on new data.
Model Packaging: This involves preparing the trained model for deployment, making it compatible with the system where it will be integrated. Model packaging includes exporting the model in formats such as ONNX or TensorFlow Lite for deployment in different environments.
Code Engineering: Bridging ML Models with Applications
Code Engineering serves as the glue that ties data and ML models together in a functional application. The code ensures that the data flows smoothly from one component to another, and the model's predictions are integrated into the system efficiently.
Key Tasks in Code Engineering
Connecting Models with the Backend: This phase includes writing the code to serve the model's predictions in real-time or as a batch process, depending on the use case.
Automating Workflows: Continuous integration and deployment (CI/CD) pipelines are set up to automate model updates and performance monitoring.
Model Deployment: Taking the Model to Production
Once the ML model is ready, the final step is deploying it into a production environment. This step is critical for any ML-based software as it allows the model to make predictions on real-world data. Proper deployment ensures the model can scale and serve multiple users without performance degradation.
Key Tasks in Model Deployment
Model Serving: This involves deploying the model so that it can accept requests (e.g., via APIs) and respond with predictions. It can be done in real-time or as part of a batch process, depending on the application requirements.
Model Performance Monitoring: Once deployed, it’s important to monitor the model’s performance over time. This ensures that the model continues to make accurate predictions as data changes.
Model Performance Logging: Continuous logging of model predictions and performance metrics helps in identifying any drift or deterioration in model accuracy. It also aids in retraining the model when needed.
Conclusion
The workflow of ML-based software development revolves around three critical artifacts: Data, ML Model, and Code. Each of these artifacts goes through a respective engineering phase—Data Engineering, ML Model Engineering, and Code Engineering. By mastering these phases and their pipelines, you can build efficient, scalable, and performant machine learning applications.
This structured approach allows for systematic handling of ML models from inception to production, ensuring that your software runs smoothly and delivers value to its users. Whether you’re developing an ML-based product or working on a research project, understanding these workflows will improve the quality and efficiency of your work.
This blog serves as an introduction to the intricate world of ML-based software development. Stay tuned for deeper dives into each phase and the technologies that can help you automate and optimize your workflow.
Subscribe to my newsletter
Read articles from Riya Bose directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by