Understanding How Parsers Work : Writing My Own Programming Language
 Abou Zuhayr
Abou Zuhayr
So, you’ve built a lexer that can break down source code into meaningful tokens—things like keywords, operators, and symbols. But what's next? While lexing breaks the input into smaller parts, it doesn’t tell us how these parts fit together. That’s where the parser comes in. A parser helps us understand the structure of code, and in doing so, it plays a key role in compiling or interpreting a programming language.
In this article, we’ll explore why you need a parser, what a parser does, and how to approach writing one. We’ll also discuss the kind of data structure that’s essential for representing code in a meaningful way—one that can handle the complexity and rules of a programming language.
Why Do We Need a Parser?
The main job of a parser is to take the stream of tokens produced by the lexer and determine if they form a valid sequence according to the grammar of the programming language. Tokens on their own don’t convey enough meaning. For example, consider the tokens int, x, =, and 5. While these individual tokens are clear, we need to know how they fit together to form a valid statement like int x = 5;. This requires understanding the structure of the code.
In essence, the parser analyzes how tokens relate to each other and forms a structure that mirrors the language’s syntax. This step is crucial because it helps transform raw code into something that can be executed by a computer.
What Exactly Is a Parser?
A parser processes the tokens and builds a structure based on the grammar rules of the language. It does this in two main stages:
Syntactic analysis (Parsing): This involves checking whether the sequence of tokens follows the syntax rules defined by the language. Think of it as verifying the grammar in a sentence.
Building a Representation: The parser doesn’t just stop at validation. It also builds an internal structure that represents the code in a way that a compiler or interpreter can understand. This structure will help the program determine what actions to perform when the code runs.
Now, this leads us to an important question: what type of structure do we need? It needs to be something that can represent complex relationships between elements, like expressions, function calls, loops, and conditions.
Designing the Right Data Structure for Parsing
When designing a parser, you’ll quickly realize that the structure you build must reflect not just the sequence of tokens, but also the hierarchy and relationships between them. Let’s use an example to explore this.
Take a simple mathematical expression: 3 + (4 * 2). There are layers of meaning here:
The
*operator binds more tightly than+, so4 * 2needs to be evaluated first.The parentheses tell us to prioritize that part of the expression before adding
3.
To represent this, you need a data structure that captures precedence and grouping. It should:
Preserve the hierarchical nature of expressions.
Allow operations like addition and multiplication to be represented clearly in relation to each other.
Make it easy to navigate and evaluate each part of the structure in the right order.
A linear data structure, such as a list or array, won’t work well here. While arrays can store the sequence of tokens, they lack the ability to represent relationships like “this operation happens before that one,” or “this part of the expression is grouped together.” Arrays would treat everything as equal, losing the vital structure that defines how the expression should be evaluated.
What about linked lists? While slightly better because they allow some level of flexibility, linked lists still struggle with representing nested relationships or the precedence of operators. A parser needs something that can show not only the sequence but also the nested structure of the code. For example, an if statement can contain other statements or expressions inside its condition, so you need a structure that allows nesting and grouping.
A graph-like structure is much closer to what we need. Graphs let us represent nodes (like operators, variables, or keywords) and edges (the relationships between them). But even a general graph may be too flexible—it could allow for circular relationships or invalid connections that don’t make sense in programming.
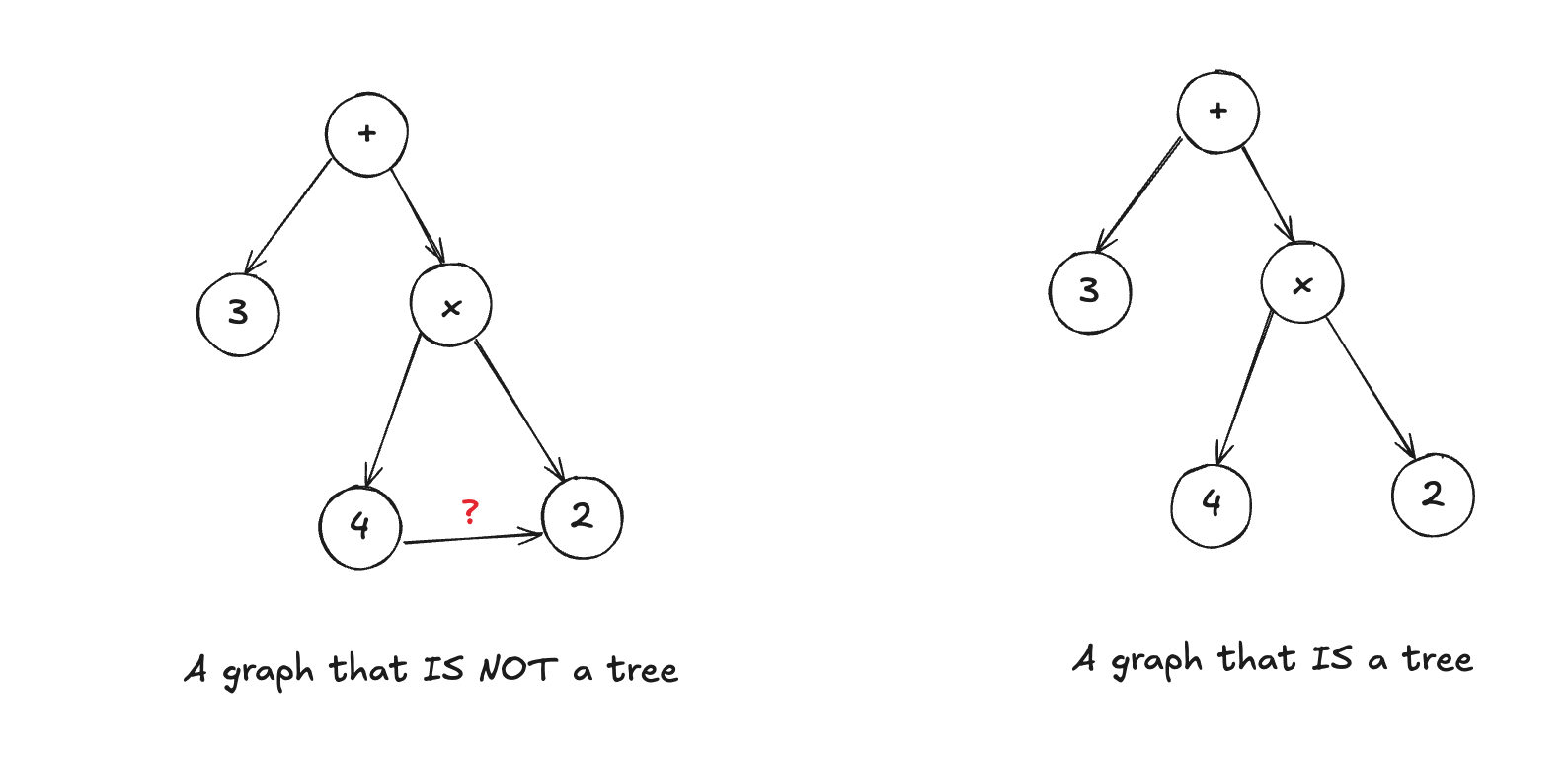
Visualizing the Ideal Structure
What we’re looking for is a data structure that:
Can represent the hierarchy and nested nature of code.
Can clearly show which parts of the code are grouped together (e.g., parentheses or blocks of code).
Can enforce rules about precedence (e.g., multiplication before addition).
Is easy to traverse and analyze, so that later stages (like evaluation or optimization) can process it efficiently.
If you imagine how this structure looks, you’d start with the root of a program (like a function definition) and gradually break it down into smaller parts: expressions, statements, and operators.
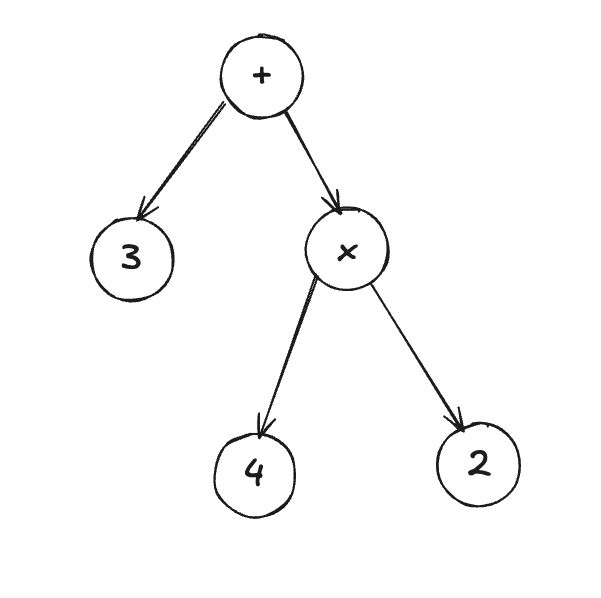
Each level of the program has its own components, some of which might branch out into further subcomponents. For example, an if statement contains both a condition and a block of code that runs if the condition is true.
This kind of structure resembles a tree, where:
The root node represents a higher-level construct (like a statement or expression).
Branches represent the components within that construct (like operators, values, or other expressions).
Leaf nodes represent the actual values or variables in the code.
Introducing the Abstract Syntax Tree (AST)
What we’ve been describing—a structure where tokens are grouped hierarchically and operations have parent-child relationships—is called an Abstract Syntax Tree (AST). The AST represents the syntax of a program in a tree-like form, where each node corresponds to a construct from the grammar of the language.
In our example:
The root of the tree would be the
+operator.One child of the
+would be the3.The other child of the
+would be the*operator, which itself has two children: 4 and2.
This hierarchical structure allows the parser to respect operator precedence, evaluate expressions in the correct order, and maintain a clear, organized view of the program’s syntax. Unlike a flat list or sequence, an AST captures the essence of the program by representing both the relationships and order of operations.
Why ASTs Are the Best Fit
ASTs are efficient because they:
Capture Hierarchical Relationships: Programming languages often have nested expressions, such as function calls within loops or operations within conditionals. ASTs naturally represent these relationships.
Simplify Processing: Since ASTs mirror the structure of the code, they make it easier for later stages (like interpreters or compilers) to process the program. By following the tree, they can execute operations in the correct order.
Abstract Away Redundant Details: ASTs abstract away extraneous syntax (like parentheses in
3 + (4 * 2)), focusing purely on the structure of the operations themselves. This helps reduce complexity during further processing.
By the time you finish parsing a program, the AST is a clean, well-structured representation of your code, ready to be interpreted or compiled.
Conclusion
Writing a parser requires a clear understanding of both the rules of the programming language and how to represent the relationships between tokens. While simpler data structures like lists and stacks may work for basic tasks, they fail to capture the rich, hierarchical relationships present in most programming languages.
An Abstract Syntax Tree (AST) is the perfect solution, providing the flexibility to represent complex expressions, maintain the correct order of operations, and give us a clear, structured view of the code. Once you have an AST, you’ve successfully translated raw tokens into a meaningful structure that a machine can understand.
Subscribe to my newsletter
Read articles from Abou Zuhayr directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abou Zuhayr
Abou Zuhayr
Hey, I’m Abou Zuhayr, Android developer by day, wannabe rockstar by night. With 6 years of Android wizardry under my belt and currently working at Gather.ai, I've successfully convinced multiple devices to do my bidding while pretending I'm not secretly just turning them off and on again. I’m also deeply embedded (pun intended) in systems that make you question if they’re alive. When I'm not fixing bugs that aren’t my fault (I swear!), I’m serenading my code with guitar riffs or drumming away the frustration of yet another NullPointerException. Oh, and I write sometimes – mostly about how Android development feels like extreme sport mixed with jazz improvisation. Looking for new challenges in tech that don’t involve my devices plotting against me!