Rethinking GitHub Search: How I built a Chat Interface to search GitHub
 Rajeev R. Sharma
Rajeev R. Sharma
Here I am again, exploring the world of chat interfaces. If you've been following my journey (I mean my last post), you might think, 'Rajeev, you're becoming obsessed with chatting!' And you wouldn't be entirely wrong. While I'm not always the most talkative person in a room, give me the right topic - like simplifying how we interact with technology - and my excitement becomes difficult to contain.
This time, my enthusiasm has led me to tackle a challenge many developers face often: searching GitHub efficiently. Let me introduce Chat GitHub, a tool where the complexity of code repositories meets the simplicity of conversation.
Why Chat GitHub?
So, why a chat interface for GitHub search? Well, GitHub search, as powerful as it is with all its filters, can’t beat the simplicity of natural language queries. Let’s be real—it won’t answer simple questions like, “When did I make my first commit?” (What filters would you even use to find this information with the current GitHub Search?). GitHub certainly knows (reminds me of “I Know What You Did Last Summer”), but it just won’t answer you directly.
Natural language makes the experience frictionless. Instead of crafting complex queries, you can just ask GitHub, like you would a colleague.
When Sébastien Chopin mentioned the idea to me, I was onboard immediately (also because I was itching to build something…).
How it Works?
At its core, Chat GitHub leverages the power of OpenAI's language models to interpret your natural language queries and translate them into GitHub's search syntax. Here's a simplified breakdown of the process:
You enter a query in plain English
The AI model interprets your request
It then selects the appropriate search endpoint, and generates the necessary GitHub API query parameters
We send a request to GitHub's API with these details
The results are fetched and presented to you in a clean, easy-to-digest chat interface
Here's a sneak peek of what the chat interface looks like:
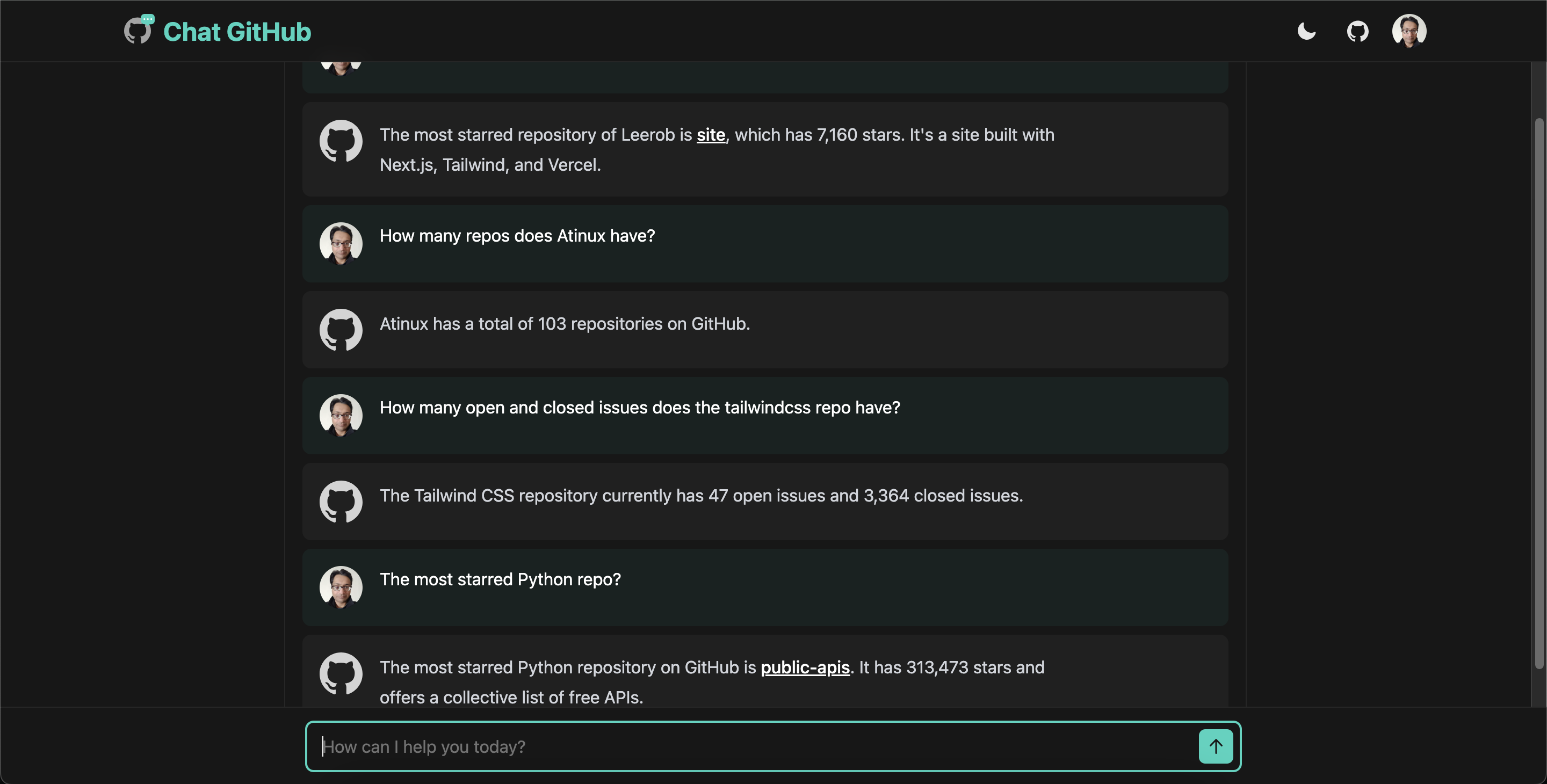
You can try it out live here: https://chat-github.nuxt.dev
We’ll explore the key aspects of this process in the sections to follow. Ready? Let’s get started.
Project Setup
This project follows a similar setup to my last one Hub Chat (GitHub link), and I’ve reused several components with some slight modifications. I won't bore you by repeating the same details, but if you’re new here, feel free to follow along with both posts (previous post) for a more complete picture.
Tech Stack
Here’s a quick breakdown of the tech stack:
Nuxt 3: For the overall framework and routing.
OpenAI APIs: To handle the natural language processing.
GitHub API: To fetch the data you’re looking for—remember? Only it knows what you did last summer.
NuxtUI: To make sure the UI is smooth and responsive.
Nuxt-Auth-Utils: For user authentication and handling GitHub login (Only authenticated users can start a chat).
Nuxt MDC: For parsing and displaying the markdown responses
NuxtHub: For deployment, database, and caching (all powered by Cloudflare).
Prerequisites
GitHub account: You'll need this to generate a
GITHUB_TOKENfor API queries, and to create an OAuth App for authentication.OpenAI account: For creating an OpenAI API key, so the app can process your queries.
Optional: If you're looking to deploy the project yourself, you'll need Cloudflare and a NuxtHub account.
Setting up the project
Follow the setup process from my previous article. Just remember to add the nuxt-auth-utils, @octokit/rest and OpenAI dependencies.
# Add the nuxt-auth-utils module
npx nuxi module add auth-utils
# Add the Octokit Rest & OpenAI libraries
pnpm add @octokit/rest openai
Once the dependencies are set up, you should be able to run the project with pnpm dev and see the default app UI at localhost:3000.
Configs and Environment Variables
At this point, you can enable the hub database and cache in the nuxt.config.ts file for later use, as well as create the necessary API tokens and keys to place in the .env file.
Enabling database and cache in nuxt.config.ts:
hub: {
cache: true,
database: true,
},
Next, generate the following tokens and keys, and store them in your .env file (located in the root of your project):
GitHub Token: Create a GitHub token (no special scope required) for making API calls.
OpenAI API Key: Generate a key from your OpenAI dashboard.
GitHub OAuth App: Create a GitHub OAuth app and get its
CLIENT_IDandCLIENT_SECRET. This will be used to authenticate users (only authenticated users can start a chat). For more information on how to create a GitHub OAuth app, refer to the GitHub documentation.
Your .env should contain the following entries:
NUXT_SESSION_PASSWORD=at_least_32_chars_string
NUXT_OAUTH_GITHUB_CLIENT_ID=github_oauth_client_id
NUXT_OAUTH_GITHUB_CLIENT_SECRET=github_oauth_client_secret
NUXT_GITHUB_TOKEN=your_personal_access_token
OPENAI_API_KEY=your_openai_api_key
Note: NUXT_SESSION_PASSWORD will automatically be created by nuxt-auth-utils in development if you haven’t set it manually.
And that’s it for the setup—phew!
In the next section, we’ll explore the core of the chat process: making sense of the user query, converting it to a GitHub API call amd generating a final response.
From User Query to GitHub API Call
Now, let’s break down how Chat GitHub processes your query, identifies the necessary actions, and makes the appropriate GitHub API call. This involves three main steps: interpreting the user query, calling the necessary tools (the GitHub API), and generating the final response.
1. Interpreting the User Query
The first challenge is understanding what the user is asking for. To do this, the system relies on OpenAI’s language models to parse natural language inputs. It takes into account several factors:
Intent Recognition: What is the user trying to achieve? Are they searching for commits, issues, repositories, or user profiles?
Parameter Extraction: Once the intent is clear, the model extracts necessary parameters like repo name, user, dates, and other filters. These details are critical for constructing a meaningful API call.
Tool Selection: Based on the query, the AI determines if a GitHub API tool needs to be invoked (for example, searching commits or issues).
To guide the AI, I created a detailed system prompt to provide context. Here’s a portion of that prompt:
const systemPropmt = `You are a concise assistant who helps \
users find information on GitHub. Use the supplied tools to \
find information when asked.
Available endpoints and key parameters:
// ...
2. issues (Also searches PRs):
- Sort options: comments, reactions, reactions-+1, ...
- Query qualifiers: type, is, state, author, assignee, ...
- use "type" or "is" qualifier to search issues or PRs (type:issue/type:pr)
// ...
When using searchGithub function:
1. Choose the appropriate search endpoint.
2. Formulate a concise query (q) as per the user's request.
3. Add any relevant sort or order parameters if needed.
4. Always use appropriate per_page value to limit the number of results.
// ...
Examples:
// ...
2. Find the total number of repositories of a user
arguments:
{
"endpoint": "repositories",
"q": "user:<user_login>",
"per_page": 1
}
Summarize final response concisely using markdown when appropriate \
(for all links add {target="_blank"} at the end). Do not include \
images, commit SHA or hashes etc. in your summary.`
Note: I restricted the AI to only the most important GitHub search endpoints /search/commits, /search/issues, /search/repositories and /search/users.
In addition to the system prompt, we create tools definitions that lists the types of tools, their names, and their specific parameters (in this case I only create one function tool, searchGithub).
const tools: OpenAI.ChatCompletionTool[] = [
{
type: 'function',
function: {
name: 'searchGithub',
description:
'Searches GitHub for information using the GitHub API. Call this if you need to find information on GitHub.',
parameters: {
type: 'object',
properties: {
endpoint: {
type: 'string',
description: `The specific search endpoint to use. One of ['commits', 'issues', 'repositories', 'users']`,
},
q: {
type: 'string',
description: 'the search query using applicable qualifiers',
},
sort: {
type: 'string',
description: 'The sort field (optional, depends on the endpoint)',
},
order: {
type: 'string',
description: 'The sort order (optional, asc or desc)',
},
per_page: {
type: 'string',
description:
'Number of results to fetch per page (max 25)',
},
},
required: ['endpoint', 'q', 'per_page'],
additionalProperties: false,
},
},
},
];
A couple of key design decisions we made:
Complimentary System Prompt & Tool Definition: The system prompt gives context, while the tool definition ensures the API queries are correctly structured.
Result Limit: While GitHub allows more items per response, we restrict results to 25 to keep things manageable.
No Pagination: We decided to skip pagination, keeping things simple and avoiding unnecessary complexity.
Now, the AI is ready to handle the user query and transform it into a structured format that the system can use. Here is the relevant code:
let _openai: OpenAI;
function useOpenAI() {
if (!_openai) {
_openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
}
return _openai;
}
export const handleMessageWithOpenAI = async (
event: H3Event,
messages: OpenAI.Chat.ChatCompletionMessageParam[]
) => {
const openai = useOpenAI();
const response = await openai.chat.completions.create({
model: MODEL, // used gpt-4o
messages, // contains system prompt and the complete chat history
tools, // defined above
});
const responseMessage = response.choices[0].message;
const toolCalls = responseMessage.tool_calls;
if (toolCalls) {
messages.push(responseMessage);
for (const toolCall of toolCalls) {
const functionName = toolCall.function.name;
if (functionName === 'searchGithub') {
const functionArgs = JSON.parse(toolCall.function.arguments);
const functionResponse = await searchGithub(
functionArgs.endpoint,
{
q: functionArgs.q,
sort: functionArgs.sort,
order: functionArgs.order,
per_page: functionArgs.per_page,
}
);
// ..
}
}
// ...
}
return responseMessage.content;
}
2. Using Tool Calls for GitHub Search
Once the AI determines the need for a GitHub API call, it generates a tool_call with the necessary parameters. Here’s how we handle this with the searchGitHub function:
export type SearchParams = {
endpoint: string;
q: string;
order?: string;
sort?: string;
per_page: string;
};
const allowedEndpoints = {
commits: 'GET /search/commits',
issues: 'GET /search/issues',
repositories: 'GET /search/repositories',
users: 'GET /search/users',
} as const;
type EndpointType = keyof typeof allowedEndpoints;
let _octokit: Octokit;
function useOctokit() {
if (!_octokit) {
_octokit = new Octokit({
auth: process.env.NUXT_GITHUB_TOKEN,
});
}
return _octokit;
}
export const searchGithub = async (
endpoint: string,
params: Omit<SearchParams, 'endpoint'>
) => {
if (!endpoint || !allowedEndpoints[endpoint as EndpointType]) {
throw createError({
statusCode: 404,
message: 'Endpoint not supported',
});
}
const octokit = useOctokit();
const endpointToUse = allowedEndpoints[endpoint as EndpointType];
try {
const response = await octokit.request(endpointToUse as string, params);
return response.data;
} catch (error) {
console.error(error);
throw createError({
statusCode: 500,
message: 'Error searching GitHub',
});
}
};
The function is a straightforward GitHub API search using the @octokit/rest library. The endpoint and parameters are passed from the tool_call, and we make the request to GitHub’s API, fetching the appropriate data. You can learn more about the GitHub search APIs from the official GitHub Docs.
3. Generating the Final Response
Once the GitHub API returns its results, the final step is to package them into a user-friendly response. The AI processes the raw data—whether commits, issues, repos, or users—and generates readable summaries. Here’s the relevant code snippet:
if (tool_calls) {
// ...
for (const toolCall of toolCalls) {
// ...
messages.push({
tool_call_id: toolCall.id,
role: 'tool',
content: JSON.stringify(functionResponse),
});
}
const finalResponse = await openai.chat.completions.create({
model: MODEL,
messages: messages,
});
return finalResponse.choices[0].message.content;
}
// ..
In the code above, you can see how we take the API response and push it to the messages array, preparing it for the AI to format into a concise response that’s easy for the user to understand.
Managing GitHub API Rate Limits
If you’ve used the GitHub API (or any third-party API), you’ll know that most of them come with rate limits. So, how can we minimize GitHub API calls? The answer is simple: we avoid making duplicate calls by caching every GitHub response. If a user requests the same information that another user (or even themselves) asked for earlier, we pull the data from the cache instead of making another API call.
Now, the question is: how do we implement this in Nuxt? It’s actually quite easy, thanks to Nitro’s Cached Functions (Nitro is an open source framework to build web servers which Nuxt uses internally). Let’s take a look at the revised searchGithub function below:
export const searchGithub = defineCachedFunction(
async (
event: H3Event,
endpoint: string,
params: Omit<SearchParams, 'endpoint'>
) => {
if (!endpoint || !allowedEndpoints[endpoint as EndpointType]) {
throw createError({
statusCode: 404,
message: 'Endpoint not supported',
});
}
const octokit = useOctokit();
const endpointToUse = allowedEndpoints[endpoint as EndpointType];
try {
const response = await octokit.request(endpointToUse as string, params);
return response.data;
} catch (error) {
console.error(error);
throw createError({
statusCode: 500,
message: 'Error searching GitHub',
});
}
},
{
maxAge: 60 * 60, // 1 hour
group: 'github',
name: 'search',
getKey: (
event: H3Event,
endpoint: string,
params: Omit<SearchParams, 'endpoint'>
) => {
const q = params.q.trim().toLowerCase().split(' ');
const mainQuery = q.filter((term) => !term.includes(':')).join(' ');
const qualifiers = q.filter((term) => term.includes(':')).sort();
const finalQuery = [...(mainQuery ? [mainQuery] : []), ...qualifiers]
.join(' ')
.replace(/[\s:]/g, '_');
let key = endpoint + '_q_' + finalQuery;
if (params.per_page) {
key += '_per_page_' + params.per_page;
}
if (params.order) {
key += '_order_' + params.order;
}
if (params.sort) {
key += '_sort_' + params.sort;
}
return key;
},
}
);
We’ve modified our earlier function to use cachedFunction, and added H3Event (from the /chat API endpoint call) as the first parameter—this is needed because the app is deployed on the edge with Cloudflare (more details here). The most important part here is how we create a unique cache key. Here’s a breakdown:
Query Qualifiers: First, we break down the
qparameter into its qualifier pairs (e.g., for finding the first PR of a GitHub user likera-jeev—yes, that’s me—theqvalue would beauthor:ra-jeev type:pr). Sometimes, it may contain the direct query string too, and the code accounts for this.Sorting Qualifiers: Next, we sort the qualifiers alphabetically. This is because the AI could create the same query as
type:pr author:ra-jeev. We could handle this in the system prompt, but why over-complicate things for the AI?Creating the Cache Key: Finally, we combine all the qualifiers and other parameters into a single string, separated by underscores.
We set the cache duration to 1 hour, as seen in the maxAge setting, which means all searchGitHub responses are stored for that time. To use cache in NuxtHub production we’d already enabled cache: true in our nuxt.config.ts.
Now that we’ve tackled rate limiting, it’s time to shift our focus to response streaming. In the next section, we’ll explore how to implement streaming for a more seamless and efficient user experience.
Adding AI Response Streaming
Enabling AI response streaming is usually straightforward: you pass a parameter when making the API call, and the AI returns the response as a stream. In our Hub Chat project, for example, we handled the stream chunks directly client-side, ensuring that responses trickled in smoothly for the user.
But in the case of Chat GitHub, there’s an additional complexity—tool_call responses. So, we have two approaches to manage:
Enable streaming only for the final response generation, but this limits us when there’s no tool_call, wasting an opportunity to stream from the start.
Enable stream response for both the OpenAI calls, but this requires us to manage a stream more carefully on the server side (as we need to handle the
tool_call, if any, there itself).
I took the seemingly complex path and went ahead with the second approach—”Two roads diverged in a wood, and I—I took the one less traveled by, And that has made all the difference.”
Enable Streaming in OpenAI Calls
Here’s how the OpenAI API call was modified to enable streaming:
export const handleMessageWithOpenAI = async function* (
event: H3Event,
messages: OpenAI.ChatCompletionMessageParam[],
) {
const openai = useOpenAI();
const responseStream = await openai.chat.completions.create({
model: MODEL,
messages,
tools,
stream: true, // enable streaming
});
const currentToolCalls: OpenAI.ChatCompletionMessageToolCall[] = [];
for await (const chunk of responseStream) {
const choice = chunk.choices[0];
// if it is normal text chunk just yield it
if (choice.delta.content) {
yield choice.delta.content;
}
// if the delta contains tool_calls, then collect all chunks
if (choice.delta.tool_calls) {
for (const toolCall of choice.delta.tool_calls) {
if (toolCall.index !== undefined) {
if (!currentToolCalls[toolCall.index]) {
currentToolCalls[toolCall.index] = {
id: toolCall.id || '',
type: 'function' as const,
function: {
name: toolCall.function?.name || '',
arguments: '',
},
};
}
if (toolCall.function?.arguments) {
currentToolCalls[toolCall.index].function.arguments +=
toolCall.function.arguments;
}
}
}
}
// once it has returned all chunks with tool_calls, we will
// get the final finish_reason as 'tool_calls'. We can call
// the mentioned tool now
if (choice.finish_reason === 'tool_calls') {
messages.push({
role: 'assistant',
tool_calls: currentToolCalls,
});
for (const toolCall of currentToolCalls) {
if (toolCall.function.name === 'searchGithub') {
try {
const functionArgs = JSON.parse(toolCall.function.arguments);
const toolResult = await searchGithub(
event,
functionArgs.endpoint,
{
q: functionArgs.q,
sort: functionArgs.sort,
order: functionArgs.order,
per_page: functionArgs.per_page,
}
);
messages.push({
role: 'tool',
tool_call_id: toolCall.id,
content: JSON.stringify(toolResult),
});
} catch (error) {
console.error('Error parsing tool call arguments:', error);
throw error;
}
}
}
try {
const finalResponse = await openai.chat.completions.create({
model: MODEL,
messages,
stream: true,
});
for await (const chunk of finalResponse) {
if (chunk.choices[0].delta.content) {
yield chunk.choices[0].delta.content;
}
}
} catch (error) {
console.error(
'Error generating final response or saving user query :',
error
);
throw error;
}
}
}
};
The revised handleMessageWithOpenAI function works like this:
Converted it to an AsyncGenerator: This allows the function to yield data chunks progressively as they are received.
Added
stream: trueto both OpenAI API calls: This tells OpenAI to stream the response back to us.Yielding Response Chunks: For each chunk of text that we get from the stream, we simply
yieldit to the caller.Handling tool_calls: Since streaming is enabled, the
tool_callinformation also arrives in chunks. We collect these chunks until the OpenAI API signals the completion of this part (finish_reason === 'tool_calls'), and then invoke thesearchGitHubfunction using the parameters provided by thetool_call.Final Response: After the GitHub search is done, we
yieldthe response in chunks in the same way.
Converting to a ReadableStream
To complete the process, the chunks from handleMessageWithOpenAI are converted into a ReadableStream format, which is then returned to the client (not shown here). Here’s how that works:
export const asyncGeneratorToStream = (
asyncGenerator: AsyncGenerator<string, void, unknown>
) => {
let cancelled = false;
const encoder = new TextEncoder();
const stream = new ReadableStream({
async start(controller) {
try {
for await (const value of asyncGenerator) {
if (cancelled) {
break;
}
controller.enqueue(
encoder.encode(`data: ${JSON.stringify({ response: value })}\n\n`)
);
}
// Send done to signal end of stream
controller.enqueue(encoder.encode(`data: [DONE]\n\n`));
controller.close();
} catch (err) {
console.log('Error in stream:', err);
/* eslint-disable @stylistic/operator-linebreak */
const errorMessage =
err instanceof Error
? err.message
: 'An error occurred in the stream';
/* eslint-enable @stylistic/operator-linebreak */
controller.enqueue(
encoder.encode(
`event: error\ndata: ${JSON.stringify({
message: errorMessage,
})}\n\n`
)
);
controller.close();
}
},
cancel(reason) {
console.log('Client closed connection. Reason:', reason);
cancelled = true;
},
});
return stream;
};
This code transforms the AsyncGenerator we created earlier into a ReadableStream. Here’s a breakdown of what’s happening:
AsyncGenerator: We pass the AsyncGenerator from
handleMessageWithOpenAIas an argument to this function.Creating a ReadableStream: Inside the
startmethod of the ReadableStream, we wait for chunks from the AsyncGenerator.Formatting Chunks: For each text chunk received, we format it according to the Server-Sent Events (SSE) convention (You can read more about SSE in my previous post). Each chunk is wrapped in this format:
data: ${JSON.stringify({ response: value })}\n\n.Encoding the Stream: Using
TextEncoder, we encode the chunks before sending them to the client. This encoding step is crucial, especially in production environments, as it ensures that the client correctly receives the stream in real-time.Error Handling: If an error occurs (as we throw errors from the AsyncGenerator), we send an
event: errormessage to the client, signaling that something went wrong, and then close the stream to terminate the connection cleanly.
And then this stream is returned to the client from the API endpoint
// inside /api/chat event handler
return asyncGeneratorToStream(
handleMessageWithOpenAI(event, llmMessages)
);
Handling the Stream on the Client-Side
To handle the streamed response, we’ll use a refactored version of the useChat composable, initially created for the Hub Chat project. This time, we’ll extend it to handle error events. Here's the updated code:
export function useChat(apiBase: string, body: Record<string, unknown>) {
async function* chat(): AsyncGenerator<string, void, unknown> {
try {
const response = await $fetch(apiBase, {
method: 'POST',
body,
responseType: 'stream',
});
let buffer = '';
const reader = (response as ReadableStream)
.pipeThrough(new TextDecoderStream())
.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
if (buffer.trim()) {
console.warn('Stream ended with unparsed data:', buffer);
}
return;
}
buffer += value;
const messages = buffer.split('\n\n');
buffer = messages.pop() || '';
for (const message of messages) {
const lines = message.split('\n');
let event = '';
let data = '';
for (const line of lines) {
if (line.startsWith('event:')) {
event = line.slice('event:'.length).trim();
} else if (line.startsWith('data:')) {
data = line.slice('data:'.length).trim();
}
}
if (event === 'error') {
const parsedError = JSON.parse(data);
console.error('Stream error:', parsedError);
throw new Error(
parsedError.message ?? 'Failed to generate response'
);
} else if (data) {
if (data === '[DONE]') return;
try {
const jsonData = JSON.parse(data);
if (jsonData.response) {
yield jsonData.response;
}
} catch (parseError) {
console.warn('Error parsing JSON:', parseError);
}
}
}
}
} catch (error) {
console.error('Error sending message:', error);
throw error;
}
}
return chat;
}
Here’s a breakdown of what the code does:
We use Nuxt’s
$fetchto make aPOSTrequest to the API endpoint, passing theresponseType: 'stream'. This tells the client to expect a streaming response.Once we receive the
ReadableStream, we create astreamReaderfor it. This allows us to process the chunks one at a time as they arrive. We also pass the chunks through aTextDecoderto convert the raw bytes into readable text.The stream is in Server-Sent Events (SSE) format, so we parse and handle the
eventanddataparts appropriately. Each data chunk is parsed and returned to the client component for rendering.The code also listens for and handles any
errorevents that may occur, ensuring a smoother user experience by gracefully handling stream interruptions or API errors.
And this concludes the road less traveled that we took earlier. In the next section, we’ll cover how we can authenticate our users.
User Authentication with GitHub OAuth
Now that our backend is ready to handle client requests, how do we restrict access to authenticated users? And how do we provide context to the AI, like answering a query such as, “When did I make my first ever commit?” To control who can access the backend, we use authentication. And to give the AI context about the user, we rely on GitHub OAuth for authentication.
We’re leveraging nuxt-auth-utils, which simplifies integrating GitHub OAuth into our Nuxt app. This allows us to authenticate users with their GitHub accounts and manage sessions effortlessly.
Server-Side Implementation
On the server side, we need to create a route that handles the GitHub access token when the user logs in. Make sure to create a GitHub OAuth app and add the CLIENT_ID and CLIENT_SECRET to the .env as mentioned in the setup section.
To implement this, create a github.get.ts file in the route/auth folder of the server directory with the following content:
export default oauthGitHubEventHandler({
async onSuccess(event, { user }) {
await setUserSession(event, {
user: {
id: user.id,
login: user.login,
name: user.name,
avatarUrl: user.avatar_url,
htmlUrl: user.html_url,
publicRepos: user.public_repos,
},
});
return sendRedirect(event, '/chat');
},
// Optional, will return a json error and 401 status code by default
onError(event, error) {
console.error('GitHub OAuth error:', error);
return sendRedirect(event, '/');
},
});
The event handler name is important and should be oauthGitHubEventHandler (more details can be found here). On successful login, we call the setUserSession utility function to store the user details in an HTTP cookie and redirect them to the chat page.
For our API routes, we can then call the requireUserSession utility to ensure only authenticated users can make requests. Below is the full /api/chat endpoint handler:
export default defineEventHandler(async (event) => {
const userSession = await requireUserSession(event);
const { messages } = await readBody(event);
if (!messages) {
throw createError({
statusCode: 400,
message: 'User messages are required',
});
}
const llmMessages = [
{
role: 'system',
content: getSystemPrompt(userSession.user.login),
},
...messages,
];
return asyncGeneratorToStream(
handleMessageWithOpenAI(event, llmMessages, userSession.user.login)
);
});
As you can see, we retrieve the currently logged-in GitHub user’s details and pass the login info into the system prompt. This gives OpenAI the context it needs to answer queries like, “When did I make my first commit?” The getSystemPrompt utility helps with that:
export const getSystemPrompt = (loggedInUserName: string) =>
systemPrompt +
`\n\nNote: The currently logged in github user is "${loggedInUserName}".`;
Client-Side Handling
On the client side, we use the built-in AuthState component from nuxt-auth-utils to manage authentication flows, like logging in and checking if a user is signed in.
Here’s how to handle sign-in:
<AuthState v-slot="{ loggedIn }">
<UButton
v-if="loggedIn"
size="lg"
trailing-icon="i-heroicons-arrow-right-16-solid"
to="/chat"
>
Go to Chat
</UButton>
<div v-else class="flex flex-col items-center justify-center gap-y-2">
<UButton
size="lg"
icon="i-simple-icons-github"
to="/auth/github"
external
>
Sign in with GitHub
</UButton>
<p class="text-sm text-gray-600 dark:text-gray-300 text-center">
Start Chatting Now!
</p>
</div>
</AuthState>
Notice the external attribute on the Sign-In button. This attribute is essential—it tells the framework to treat the GitHub authentication as an external process. Without it, the framework will try to redirect you to the /auth/github route on the client side, causing errors (It did get me for sure).
This completes the server-side and client-side setup for user authentication. You can go through the shared GitHub repo to see how we also restrict navigation on the client side by using an auth middleware, ensuring that only authenticated users can access the chat page.
Bonus: Enhancing Engagement
As the project neared completion, I kept thinking about how to make it more engaging. I wanted to show what users were querying about and who they were querying for. However, I didn’t want to save every type of query—especially those like “When did I make my first commit?”—as they were both pointless and numerous. Instead, I decided to save only the queries made about other users, repositories, and other entities, excluding self-referential queries.
Database Setup
To achieve this, we needed a database, which is why we enabled database: true in our nuxt.config.ts file. This setting binds Cloudflare’s D1 database in production and uses its platform proxy during development.
First, we create the necessary database tables using the hubDatabase server composable:
await hubDatabase().exec(
`CREATE TABLE IF NOT EXISTS queries (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
response TEXT NOT NULL,
github_request TEXT NOT NULL,
github_response TEXT NOT NULL,
queried_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
`.replace(/\n/g, '')
);
// ... other tables and indexes
Next, we utilize utility functions to save the queries. The saveUserQuery function is invoked only if a tool call was made from the handleMessageWithOpenAI function we discussed earlier.
export type ToolCallDetails = {
// eslint-disable-next-line @typescript-eslint/no-explicit-any
response: any;
request: SearchParams;
};
export type UserQuery = {
userMessage: string;
toolCalls: ToolCallDetails[];
assistantReply: string;
};
const getAvatarUrl = (toolCall: ToolCallDetails) => {
let avatarUrl;
const responseItem = toolCall.response.items[0];
if (responseItem) {
if (responseItem.author) {
avatarUrl = responseItem.author.avatar_url;
} else if (responseItem.user) {
avatarUrl = responseItem.user.avatar_url;
} else if (responseItem.owner) {
avatarUrl = responseItem.owner.avatar_url;
} else if (responseItem.avatar_url) {
avatarUrl = responseItem.avatar_url;
}
}
return avatarUrl;
};
const shouldSaveUserQuery = (
toolCall: ToolCallDetails,
loggedInUser: string
) => {
const responseItem = toolCall.response.items[0];
if (
responseItem &&
((responseItem.author && responseItem.author.login === loggedInUser) ||
(responseItem.user && responseItem.user.login === loggedInUser) ||
(responseItem.owner && responseItem.owner.login === loggedInUser) ||
responseItem.login === loggedInUser)
) {
return false;
}
return true;
};
export const saveUserQuery = async (
loggedInUser: string,
userQuery: UserQuery
) => {
const toolCall = userQuery.toolCalls[0];
const matchedUser = toolCall.request.q.match(/(?:author:|user:)(\S+)/);
if (matchedUser) {
const queriedUser = matchedUser[1].toLowerCase();
if (queriedUser !== loggedInUser) {
const avatarUrl = getAvatarUrl(toolCall);
await storeQuery(
userQuery.userMessage,
userQuery.assistantReply,
toolCall,
{ login: queriedUser, avatarUrl }
);
}
} else if (shouldSaveUserQuery(toolCall, loggedInUser)) {
await storeQuery(userQuery.userMessage, userQuery.assistantReply, toolCall);
}
};
It checks if the query involves the currently logged-in user. If it does, we simply return without logging anything; otherwise, we store the query details in the database using:
const storeQuery = async (
queryText: string,
assistantReply: string,
toolCall: ToolCallDetails,
queriedUser?: { login: string; avatarUrl?: string }
) => {
try {
const db = hubDatabase();
const queryStmt = db
.prepare(
'INSERT INTO queries (text, response, github_request, github_response) VALUES (?1, ?2, ?3, ?4)'
)
.bind(
queryText,
assistantReply,
JSON.stringify(toolCall.request),
JSON.stringify(toolCall.response)
);
if (queriedUser) {
const [batchRes1, batchRes2] = await db.batch([
queryStmt,
db
.prepare(
`INSERT INTO trending_users (username, search_count, last_searched, avatar_url)
VALUES (?1, 1, CURRENT_TIMESTAMP, ?2)
ON CONFLICT(username)
DO UPDATE SET search_count = search_count + 1, last_searched = CURRENT_TIMESTAMP, avatar_url = COALESCE(?2, avatar_url)`
)
.bind(queriedUser.login, queriedUser.avatarUrl),
]);
console.log('storeQuery: ', batchRes1, batchRes2);
} else {
const res = await queryStmt.run();
console.log('storeQuery: ', res);
}
} catch (error) {
console.error('Failed to store query: ', error);
}
};
API Endpoints
We then create API endpoints to retrieve the trending users and recent queries, as shown below (note the use of endpoint caching):
export const getRecentQueries = async () => {
const db = hubDatabase();
console.log('getRecentQueries');
const result = await db
.prepare(
'SELECT id, text, response, queried_at FROM queries ORDER BY queried_at DESC LIMIT ?'
)
.bind(10)
.all<RecentQuery>();
console.log('getRecentQueries: ', result);
return result.results;
};
export default defineCachedEventHandler(
async () => {
const results = await getRecentQueries();
return results;
},
{
maxAge: 10 * 60, // 10 minutes
}
);
Frontend Integration
This setup allows us to display the data in the frontend, providing users with insights into trending queries and recently searched users, as illustrated in the screenshot below.
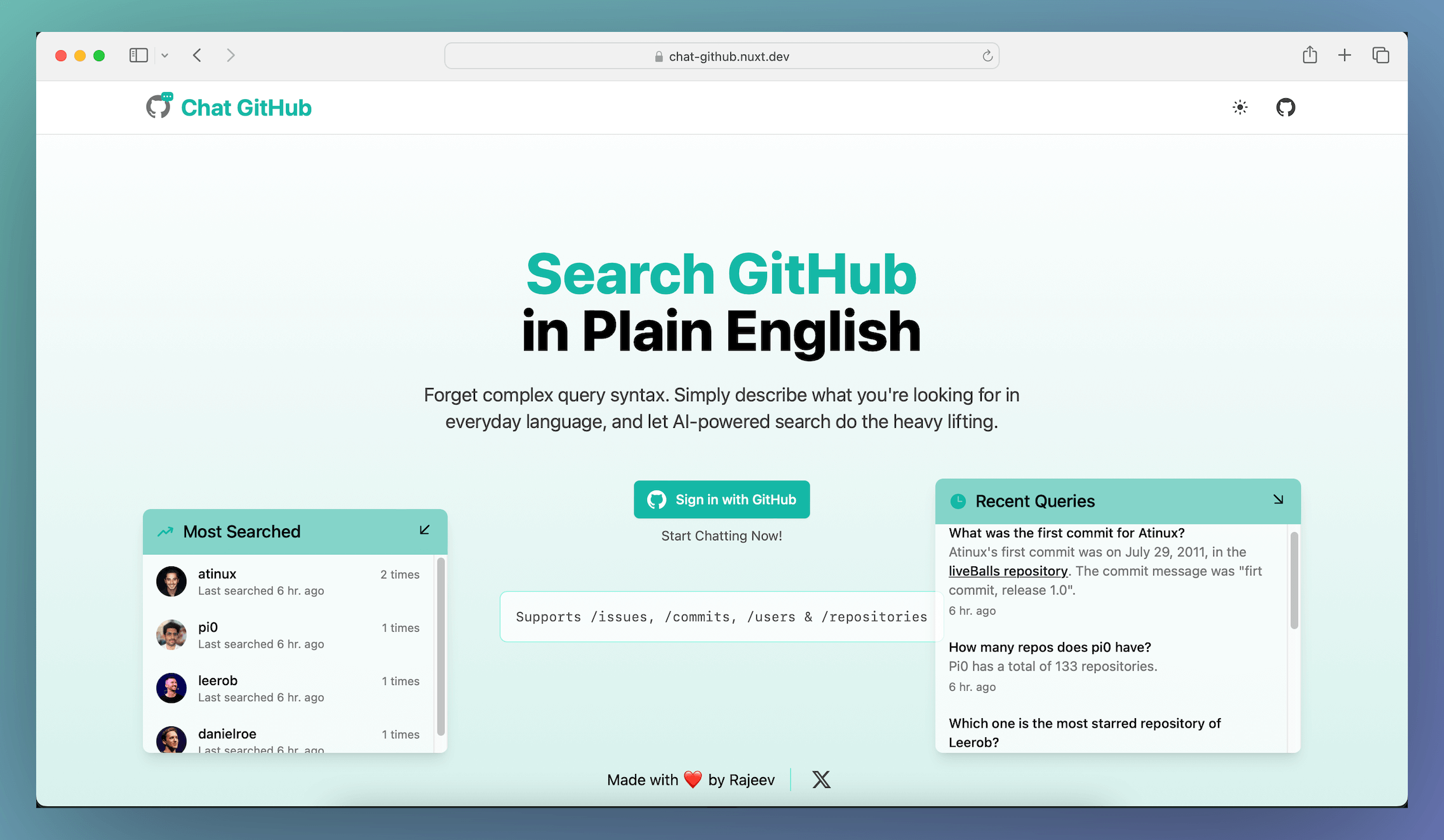
You can go through the shared GitHub repo to see the whole implementation in detail.
And with that, now you can also know what you did last summer—phew!
Source Code
The project’s code is open source and can be checked here
Deployment
You can deploy the app using your NuxtHub admin panel or manually through the NuxtHub CLI. For more details on deploying an app through NuxtHub, refer to the official documentation.
The best part is that this project is now listed as a template on the NuxtHub Templates page. So, if you already have a NuxtHub account, you can deploy this project in one click using the button below (Just remember to add the necessary environment variables in the panel).

Further Enhancements
Currently, we rely on the AI's ability to generate GitHub API queries from natural language input. While we’ve provided it with details about various qualifiers, it can still struggle with more complex or intricate queries. I also experimented with tool-calling models from Cloudflare’s Workers AI and Groq API, and found that gpt-4o performed better for these tasks. Claude 3.5 Sonnet should definitely offer even better results, but it tends to be more expensive.
Here are a few alternative approaches we could explore to improve query accuracy and results:
Fine-tune/train a tool-calling model specifically on the GitHub Search API documentation.
Create embeddings from the GitHub Search documentation and store them in a vector database. Cloudflare offers a free tier for its vector database now, which we could leverage. When a user query is made, we could retrieve relevant information from the embeddings and include it in the system prompt.
If you have any other ideas for improving this project—or any feedback—please feel free to share them in the comments!
Conclusion
And there you have it—a GitHub search tool, powered by OpenAI, wrapped in a chat interface, and ready for action. We’ve gone through setting up the project, streaming responses, authenticating users, and even added a sprinkle of engagement to make things interesting.
While the project has plenty of room for improvements, it’s a solid foundation to build upon. And who knows—maybe with a few tweaks, it’ll be predicting your next GitHub repo before you even think of it :-).
May all your commits be bug-free!
Until next time!
Keep adding the bits and soon you'll have a lot of bytes to share with the world.
Subscribe to my newsletter
Read articles from Rajeev R. Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rajeev R. Sharma
Rajeev R. Sharma
I build end-to-end apps in JavaScript with various frameworks and libraries, sharing detailed write-ups along the way. Lately, I've been experimenting with simple AI tools, while Nuxt remains my go-to fullstack framework. Occasionally, I dive into fun side projects, like crafting simple games with Python Turtle.