A Bird's-Eye View of Amazon Aurora's Amazing Architecture
 Amr Elhewy
Amr Elhewy
In this article i’m going to be simply explaining the architecture Amazon’s well known relational database service Aurora; dive deep into why some decisions were made and the impact they had. I’m going to be abstracting a lot of information just so you can get the general idea. I’ll try to simplify it as much as possible so you don’t have to have deep knowledge to be able to grasp the concept 😊. Enjoy
Introduction
Amazon Aurora is a relational database service for OLTP (Online Transactional Processing) workloads offered as part of Amazon Web Services (AWS).
To be able to grasp the reasoning behind Aurora let’s take it back to what a normal relational database does.
In a traditional relational database system, each database server (the machine running the database) does all the work:
Processing Queries: It handles reading and writing data.
Storing Data: It saves data locally or on disk.
Handling Failures: If a crash happens, the same server needs to recover data, replay logs, and bring everything back online.
This setup means each server is responsible for both compute (processing) and storage, which can create bottlenecks, especially in high-throughput systems. Network traffic is high because servers need to constantly synchronize data between each other to avoid data loss.
The I/O bottleneck usually happens because a single server has to handle both compute(processing) and storage (reading/writing data to disk). This can overwhelm the server's disk, causing performance slowdowns—especially when there's heavy load. But in a cloud environment like AWS Aurora, things work a bit differently.
Aurora’s Architecture
The Skeleton
Aurora separates the storage service from the database instances. This storage service manages functions like redo logging, crash recovery, and backups independently, rather than being tightly integrated with each database instance like in traditional systems.
So in other words it split the processing from the storage completely which now resulted in having processing servers without the overhead of storing the data.
Instead of relying on a single disk or server, Aurora spreads out storage across many servers (called the "storage fleet"). This means that no single disk or server is overloaded, as the storage load is distributed. However, this introduces a new bottleneck: the network.
The database needs to send requests over the network to the storage servers to read or write data.
Even though the data is spread across many servers, the database must communicate with several of them at once, creating a lot of network traffic.
Also, since the database sends multiple write requests in parallel to different storage nodes, if one of those storage nodes or the network path to it is slow, it can cause delays. This means the overall speed of the database can be limited by the slowest node or network path, even if the others are performing well.
In simpler terms: by spreading the work across many storage servers, the disks aren’t the problem anymore, but now the speed of the network between the database and those servers becomes the main thing that can slow things down. Even one slow server in the storage fleet can affect the overall speed.
Now the question is How did they optimize the network problem mentioned above?
Design choices
Reducing Network Traffic with Redo Logs
Traditional Problem: both compute and storage typically reside on the same server. Large chunks of data, such as full data pages, are written to disk during transactions, generating significant I/O load. As databases grow and scale, or in clustered environments, this can lead to performance bottlenecks. When compute and storage are separated, such as in a distributed cloud system like Aurora, these writes would require network communication between the database tier and the storage tier, further amplifying traffic and introducing latency.
Aurora’s Solution: Aurora only sends redo logs (small records that track changes made to the database) to the storage layer, rather than full data pages. These logs are much smaller in size and require less network bandwidth, drastically reducing network I/O. This design reduces the overall data that needs to be transmitted over the network by an order of magnitude.
Parallel Writes to Distributed Storage
Traditional Problem: In a traditional database setup, all writes would go to a single storage device, creating a bottleneck. Even with distributed systems, data replication to multiple nodes increases network load and complexity.
Aurora’s Solution: Aurora writes the redo log in parallel to multiple storage nodes across multiple availability zones (AZs). This ensures that the system is resilient to node failures and improves performance by distributing the work. Instead of a single node handling all writes, they are spread across many nodes. Additionally, by splitting the I/O operations across a fleet of storage servers, it prevents overloading any single server or network link.
Asynchronous Background Operations
Traditional Problem: Operations like backups and crash recovery are usually synchronous and happen in real-time, which can spike network traffic and lead to bottlenecks.
Aurora’s Solution: Aurora offloads complex tasks like backup and redo recovery to the distributed storage fleet, where they are performed continuously in the background and asynchronously. This means the database doesn’t have to pause to perform these tasks, and they don’t generate massive network loads all at once. Instead, traffic is spread out over time and across nodes.
Fault Tolerance and Self-Healing Mechanism
Traditional Problem: If a single node or network path slows down or fails, it can cause significant performance degradation. In a split architecture, the failure of a storage node or network path can delay the entire system.
Aurora’s Solution: Aurora’s storage layer is fault-tolerant and self-healing. If a storage node, disk, or network path becomes slow or fails, the system automatically reroutes traffic to healthy nodes. This reduces the impact of outliers (i.e., slow nodes or links), ensuring that performance issues at one storage node don’t bottleneck the entire system.
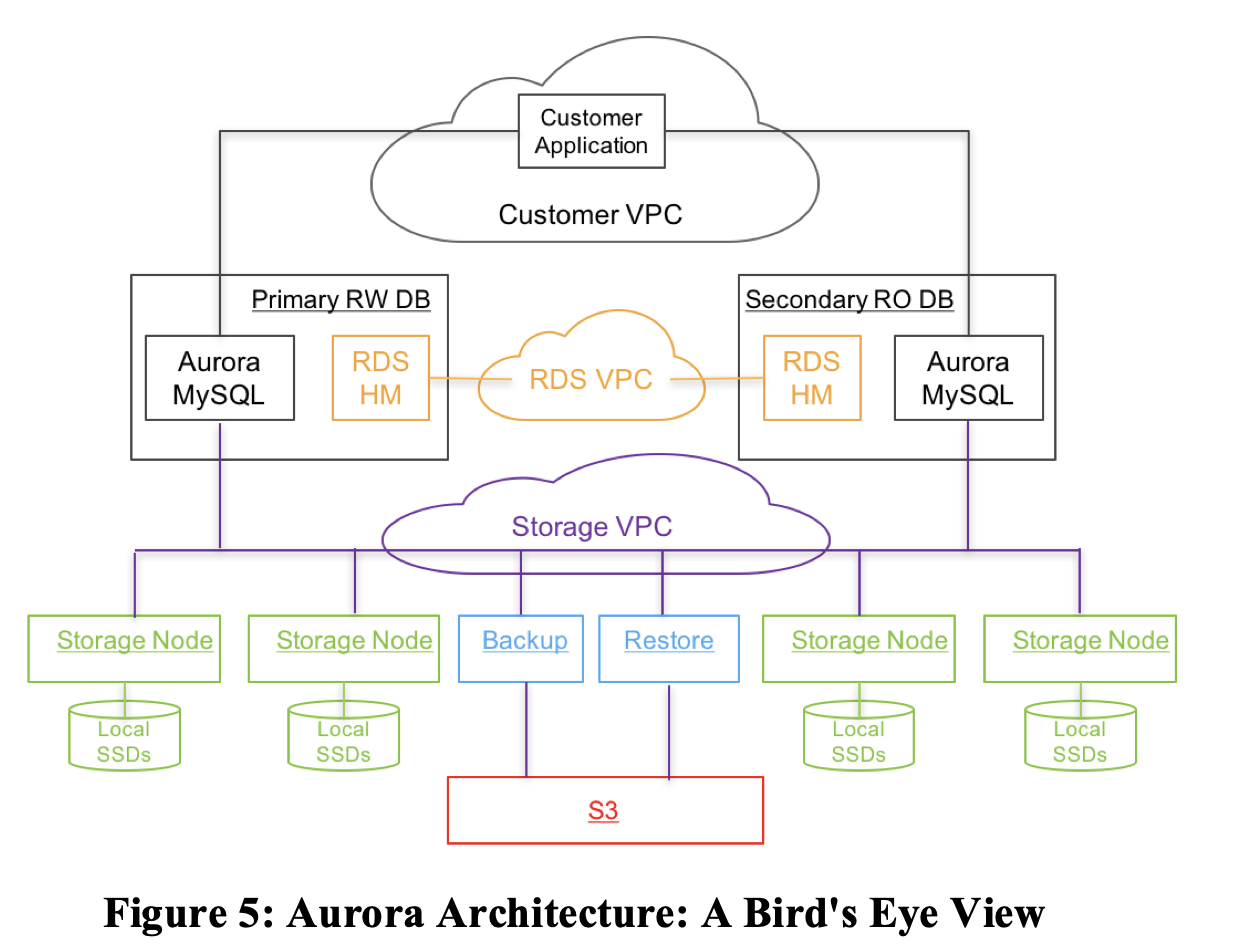
The image above is a birds-eye view of Aurora’s architecture. Aurora Uses the AWS RDS control plane and the database engine is a fork of “community” MySQL/InnoDB and diverges primarily in how InnoDB reads and writes data to disk mainly in the redo-log part as mentioned above. Backups are stored on AWS S3 blob storage.
This was a quick blog summarizing a refreshing architecture to the relational database realm done by Aurora. The main goal of this article was to have a high level understanding of the differences, highlighting the problems that happen at high scale and the reasoning behind these design choices. Every choice always exists because of a problem. Thank you for tuning in and till the next one :)
References
Subscribe to my newsletter
Read articles from Amr Elhewy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by