Unlocking the Power of Retrieval-Augmented Generation (RAG): A Comprehensive Guide
 Sujit Nirmal
Sujit Nirmal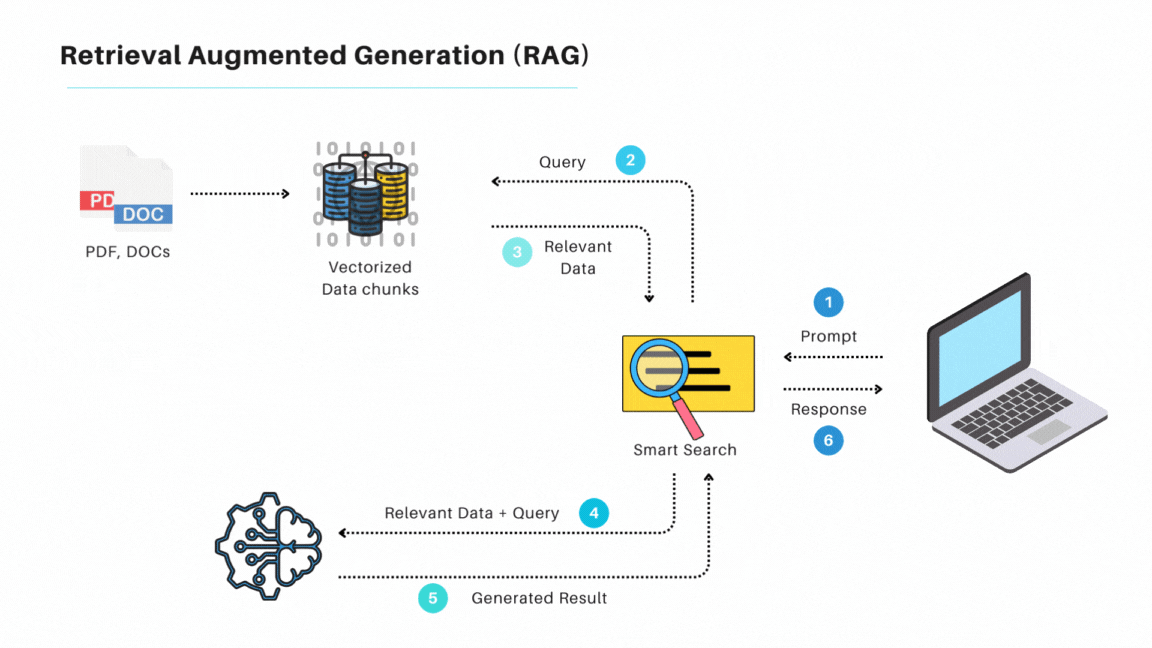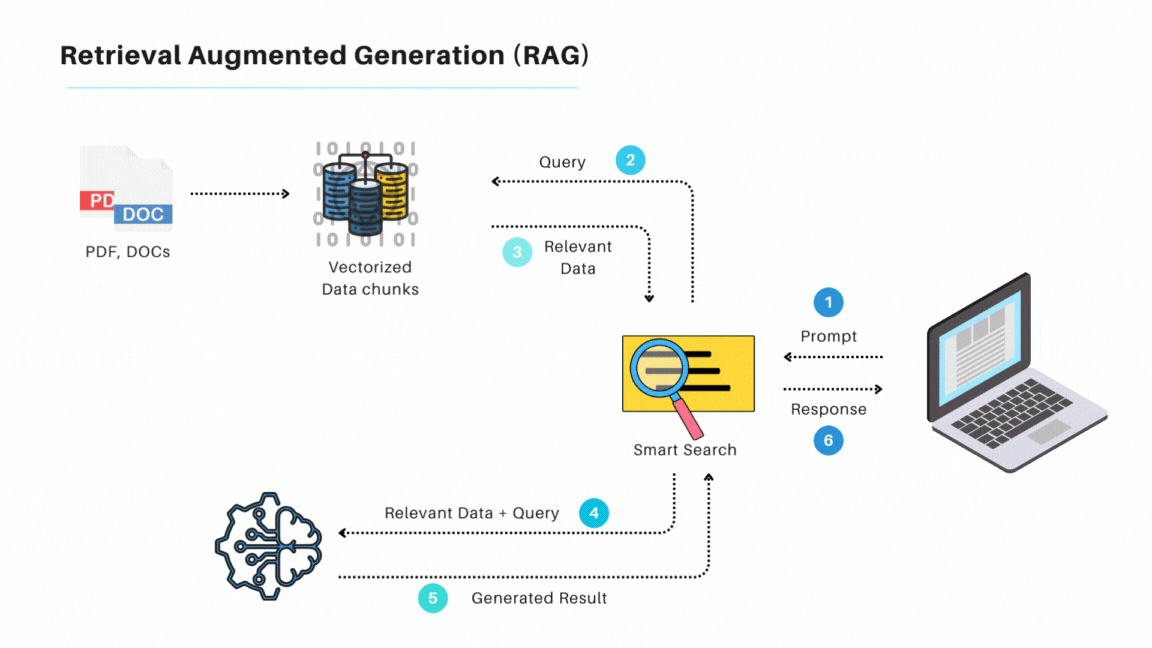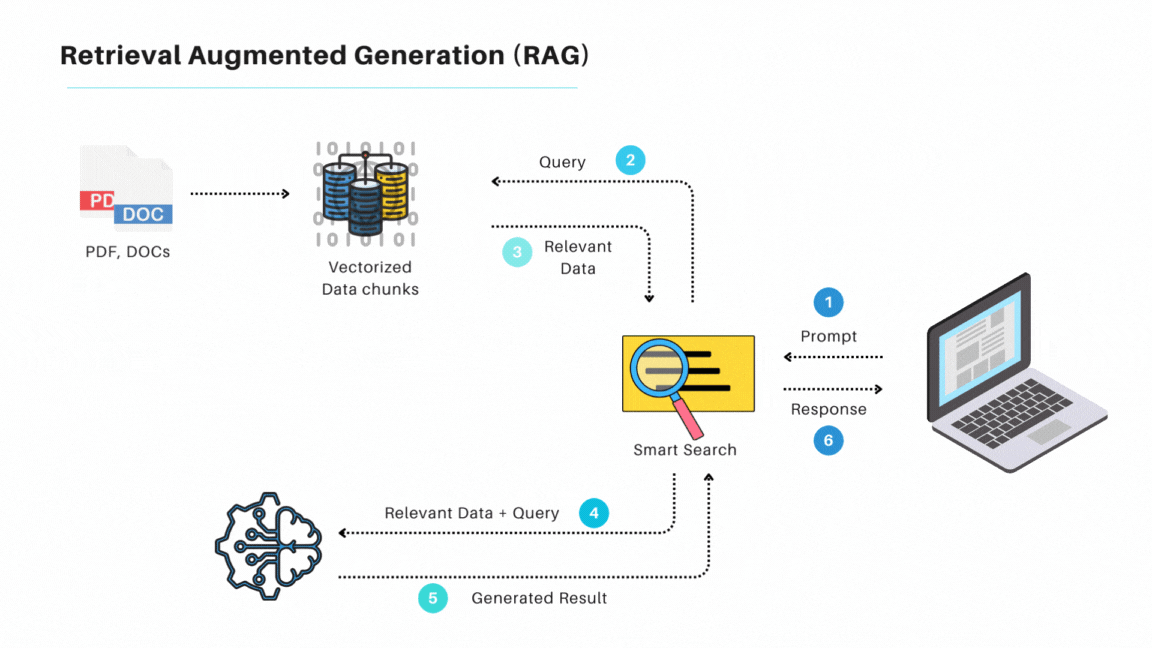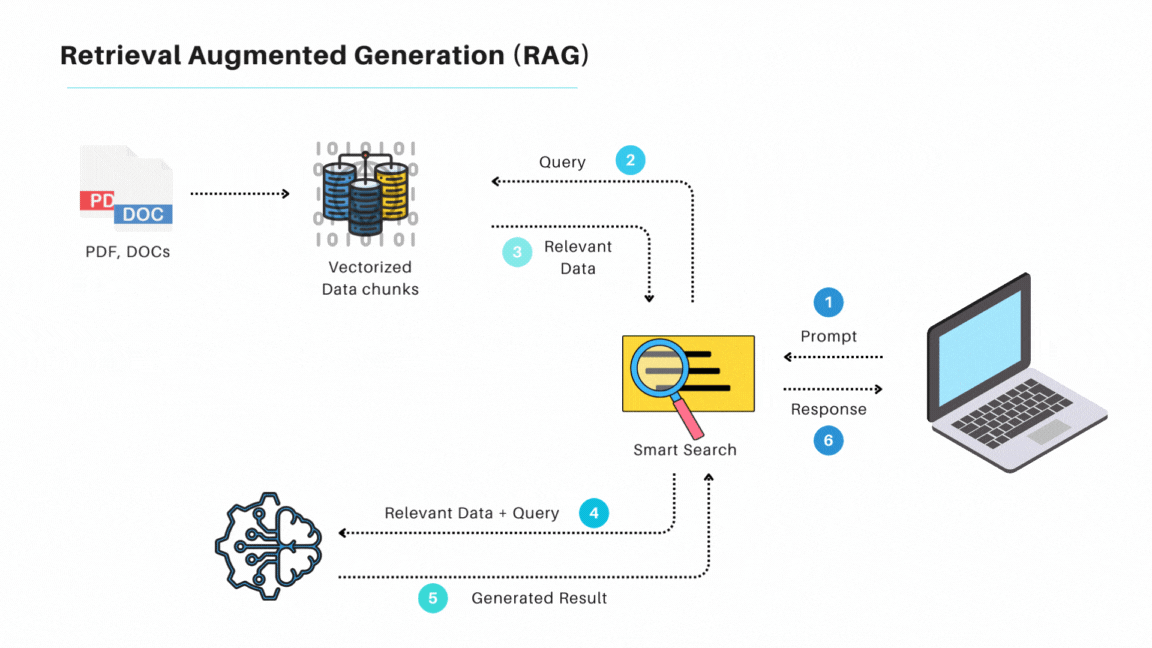
Retrieval-Augmented Generation (RAG) is an innovative AI technique that combines the strengths of information retrieval and text generation. It enhances the capabilities of large language models (LLMs) by integrating external data sources, allowing for more accurate and contextually relevant responses. Here's a comprehensive guide to understanding RAG, its workings, and its applications, along with code snippets and learning resources.
What is RAG?
RAG is a hybrid framework that integrates retrieval models and generative models to produce text that is both contextually accurate and information-rich. It addresses the limitations of traditional language models by enabling real-time data retrieval, which enriches the generated content with up-to-date information.
How RAG Works
Retrieval: The process begins with retrieving relevant information from external data sources. This involves using a retrieval model to search through a large corpus of data to find pertinent information.
Augmentation: The retrieved information is then used to augment the language model's prompt. This step ensures that the generated text is informed by the most current and relevant data.
Generation: Finally, the generative model uses the augmented prompt to produce coherent and contextually rich text.
Key Components
Retrieval Models: These models act as information gatekeepers, searching through data to find relevant pieces of information. They use techniques like vector embeddings and vector search to rank and select data.
Generative Models: Once the retrieval model has sourced the appropriate information, generative models synthesize this information into coherent text. They are usually built upon large language models (LLMs).
Technical Implementation
Here's a basic example of how to implement RAG using Python:
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
# Load and index documents
loader = PyPDFLoader("example.pdf")
documents = loader.load()
index = VectorstoreIndexCreator().from_loaders([loader])
# Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vector_store = Chroma.from_documents(documents, embeddings)
# Query the vector store
query = "What is RAG?"
results = vector_store.similarity_search(query)
# Generate response using LLM
llm = OpenAI()
context = " ".join(results)
prompt = f"Answer the following question based on this context: {context}.\nQuestion: {query}"
response = llm(prompt)
Applications of RAG
Text Summarization: RAG can generate concise summaries of complex articles, enhancing user experience in news aggregation platforms.
Question-Answering Systems: It excels in providing detailed and accurate answers by retrieving relevant information from extensive datasets.
Content Generation: RAG can auto-generate emails, social media posts, and even code, ensuring the output is contextually rich.
Benefits of RAG
Enhanced Accuracy: By incorporating current data, RAG improves the accuracy of responses.
Dynamic Content: Regular updates to external data sources ensure responses remain relevant.
Expanded Knowledge Base: Access to diverse external information broadens the model's knowledge.
Learning Resources
RAG is a powerful approach that combines retrieval-based methods and generative models, offering a promising solution for applications requiring depth, context, and factual accuracy.
Keep Learning !!!
Keep Coding !!!
Coding Inferno !!!
Subscribe to my newsletter
Read articles from Sujit Nirmal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sujit Nirmal
Sujit Nirmal
👋 Hi there! I'm Sujit Nirmal, a AI /ML Developer with a passion for creating intelligent, seamless ML applications. With a strong foundation in both machine learning and Deep Learning I thrive at the intersection of data and technology.