Distributed Computing with Python: Unleashing the Power of Celery for Scalable Applications
 Snehangshu Bhattacharya
Snehangshu Bhattacharya
Have you ever wondered about when you upload an 8K Ultra HD video to YouTube and immediately YouTube starts to process and optimize that video and make multiple copies of it in 1080p, 720p, 480p, 360p and 144p so that your content can be streamed to every network and every device of every size in the world? YouTube does this for not only your video but also at least 1 hour of video content is uploaded to YouTube every second! The answer is distributed systems and job queues. Distributed systems are an extremely important part of system design and are used by top IT companies around the world to serve billions of users!
In this blog, you will learn how to build scalable distributed Python applications capable of handling millions of tasks a minute. This is the second part of my two-part blog series on Multitasking with Python. You can read the previous part here.
First, I will explain task queues and how they work. Then, we'll explore message brokers to build a solid foundation. Once we've covered the basics, we'll dive into Celery in detail and finally create a project to transcode videos in bulk using Celery. Get ready; this is going to be a long blog!
Task Queues🏭
Before we discuss Celery's architecture, we need to establish what task queues are and how they help achieve computing in a distributed manner. In the last part, we discussed techniques for getting more work from a single multi-core, multi-thread system. However, task queues can span multiple systems, even data centres, and thus offer excellent horizontal scalability, which is only limited by hardware, cost, and more physical constraints. Some of the key concepts of task queues are listed below:
Task: Tasks are individual units of work (usually a function or method) placed in the queue to be processed. They are usually compute-heavy or I/O-heavy and take some time to complete.
Producers and Consumers: Producers are parts of an application that creates tasks and add them to the task queue. Consumers of workers are applications that pick up tasks from the task queue and execute them. Producers and consumers run independently of each other, and this level of decoupling adds to the scalable nature of task queues. There can be multiple producers and consumers in a Task Queue. Producers and consumers can be interchangeably named as
publishersandsubscribers, and this programming model is known as the pub/sub model.Broker: Producers and consumers are connected via task queues. The physical implementation of task queues is provided by message brokers. Brokers act as a communication highway between producers and consumers. Usually, the queues implemented by brokers are First-In-First-Out by nature, but we can assign priority to tasks to control the execution order.
Some common use cases of task queues include background job processing, data pipelines, long-running asynchronous processes etc. Some examples of task queues include Celery (obviously), Sidekiq (written in Ruby, used in the backend of GitLab), RQ or Redis Queue (Redis-based job queue in Python), etc. Here is a list of the most commonly used task queues: https://taskqueues.com/#libraries.
Message Brokers and RabbitMQ
A 6-lane highway 🛣️ for pub/sub model
If Task is the unit of work for a Task Queue, the unit of communication for a message broker is Message. The message can be in JSON, XML, binary, or any other serialised format and can include events, complete functions, commands etc. A message broker is a piece of software that enables communication between producers and consumers, and is the cornerstone of this decoupled architecture where both producers and consumers can work and scale independently.
Before we discuss Celery, we should discuss RabbitMQ, the most used, fast and resource-efficient message broker for Celery.
RabbitMQ: One broker to queue them all🐰

RabbitMQ is an open-source message broker written in Erlang💡 that allows communication between different applications by routing messages. It uses widely adopted AMQP (Advanced Message Queueing Protocol) to communicate between systems. RabbitMQ also supports MQTT (Message Queuing Telemetry Transport, heavily used in IoT applications), and STOMP (Simple/Streaming Text Orientated Messaging Protocol) protocols to interact with other systems.
RabbitMQ comes with many customisations that are out of the box and introduce some features that can cater to various requirements. Some of the key features of RabbitMQ are-
Queues: This is a buffer where messages reside until a consumer consumes them. Queues are heavily configurable in RabbitMQ, like you can choose where to store the messages, in memory or on disk, should the messages persist a system restart etc. Multiple consumers can consume from the same queue.
Exchanges: An exchange enforces rules on how to route messages to queues and in turn consumers based on routing rules. The exchange types are discussed later.
Bindings: Binding is a connection between exchange and queues, the routing rules are defined here. The binding holds the
binding key.Routing Keys: Routing keys are set by the producer to route messages to the desired queue(s).
Acknowledgements: After processing the message, a consumer (worker) can send an acknowledgement (Ack) signal to RabbitMQ. In case of failed processing, the worker sends back a negative acknowledgement (Nack). RabbitMQ can be configured to re-queue or discard the message subject to requirement.
Based on the routing rules, exchanges can be classified into four types -
Direct Exchange: Direct exchange compares the
routing keyof the message and thebinding keyof the message and only allows messages to pass to queues if there is an exact match betweenrouting keyandbinding key.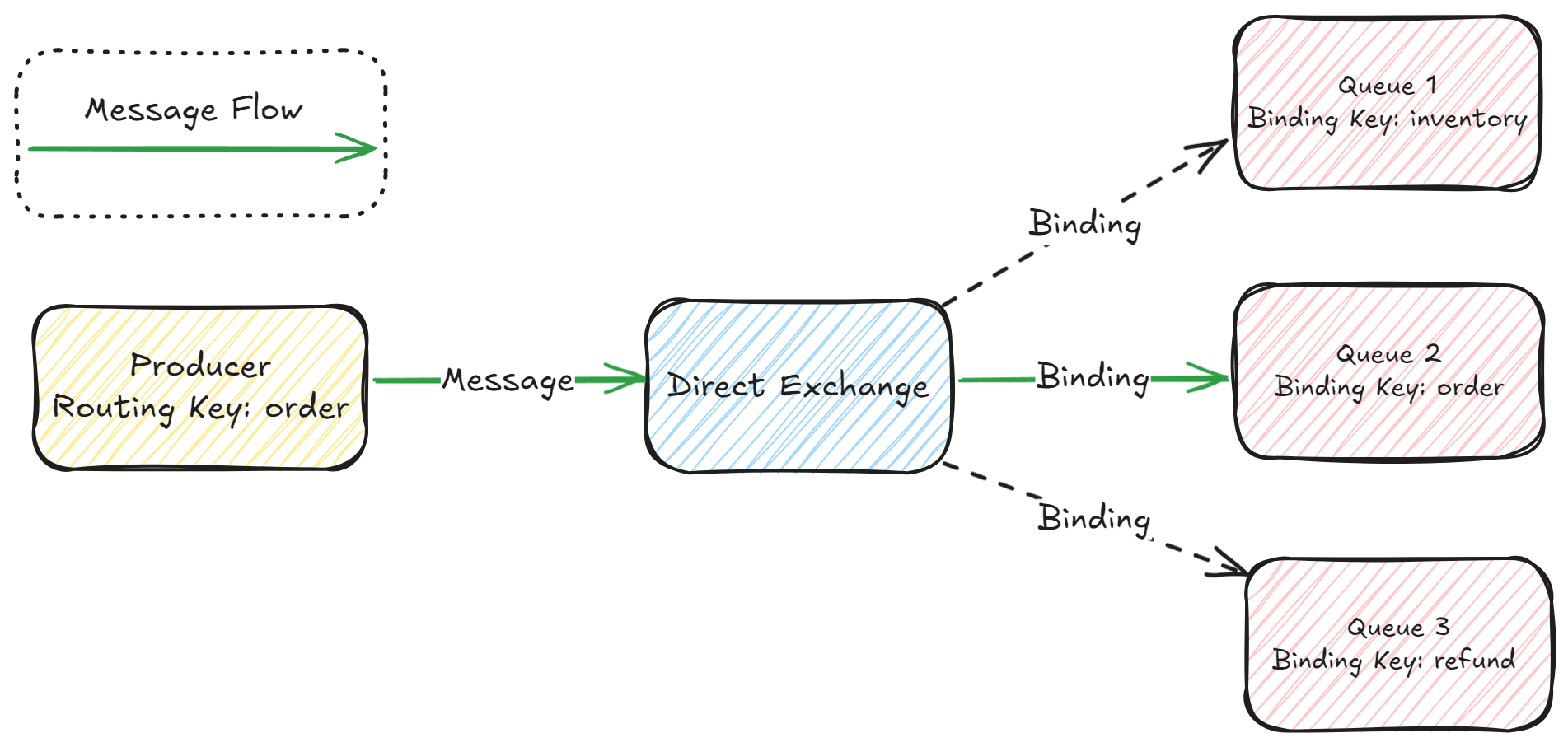
Fanout Exchange: Fanout exchange pass messages to all bound queues, regardless of the
routing keyorbinding key.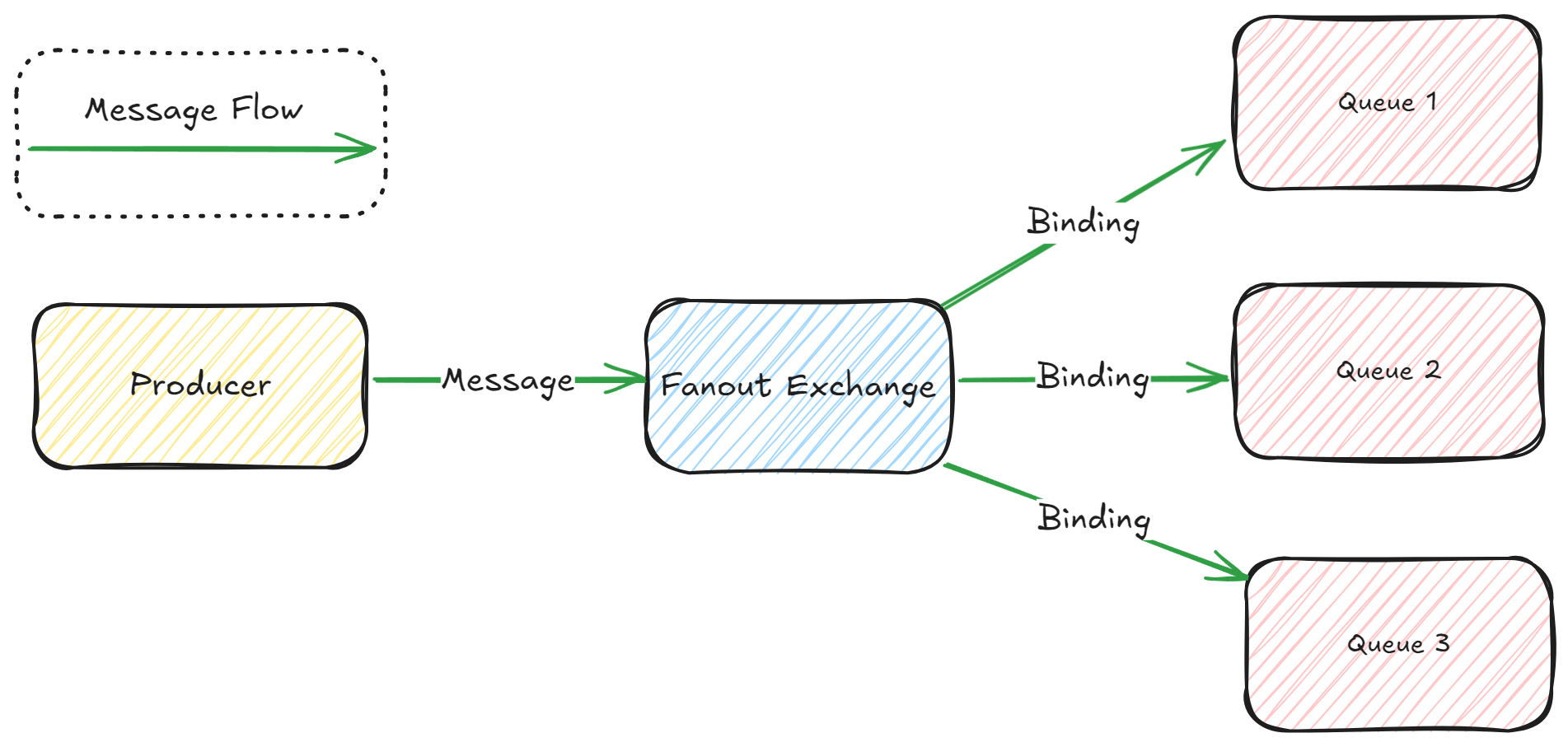
Topic Exchange: Topic exchange is almost the same as
Direct Exchange. But we matchrouting keyandbinding keyusing patterns here. If arouting keyisxyz.*andbinding keyisxyz.tangoorxyz.foxtrotthen the topic exchange will match and forward the message.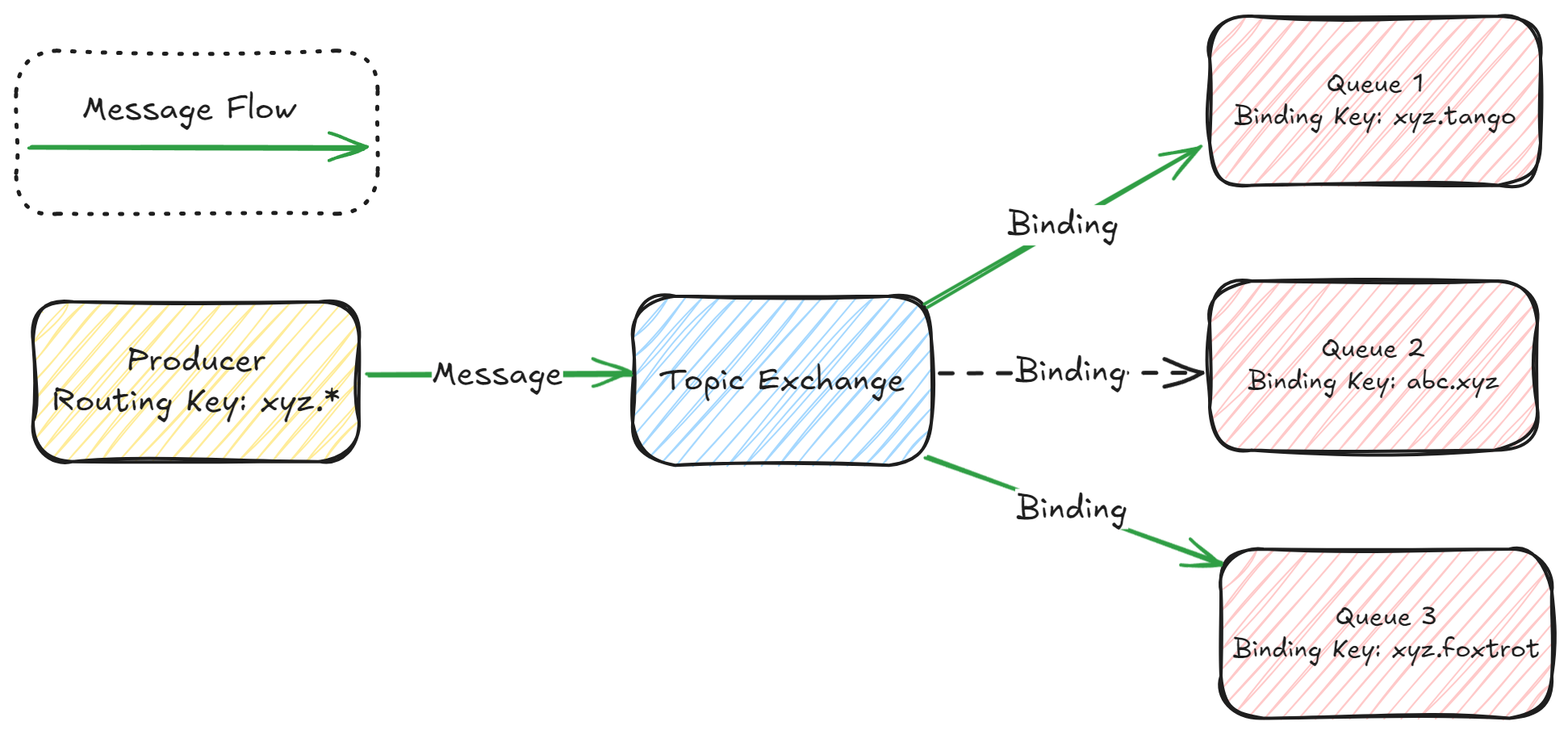
But if the binding key is
xyz.tango.zuluit will not matchxyz.*, because*matches a single word, while#matches multiple words. Let’s arrange a table to understand this better -
| routing key | binding key |
| xyz.abc | xyz.abc (matches) (mimics direct exchange) |
| xyz.* | xyz.tango (matches) |
| xyz.* | xyz.foxtrot (matches) |
| xyz.* | xyz.tango.zulu (does not match) |
| xyz.# | xyz.tango.zulu (matches) |
| #.zulu | xyz.tango.zulu (matches) |
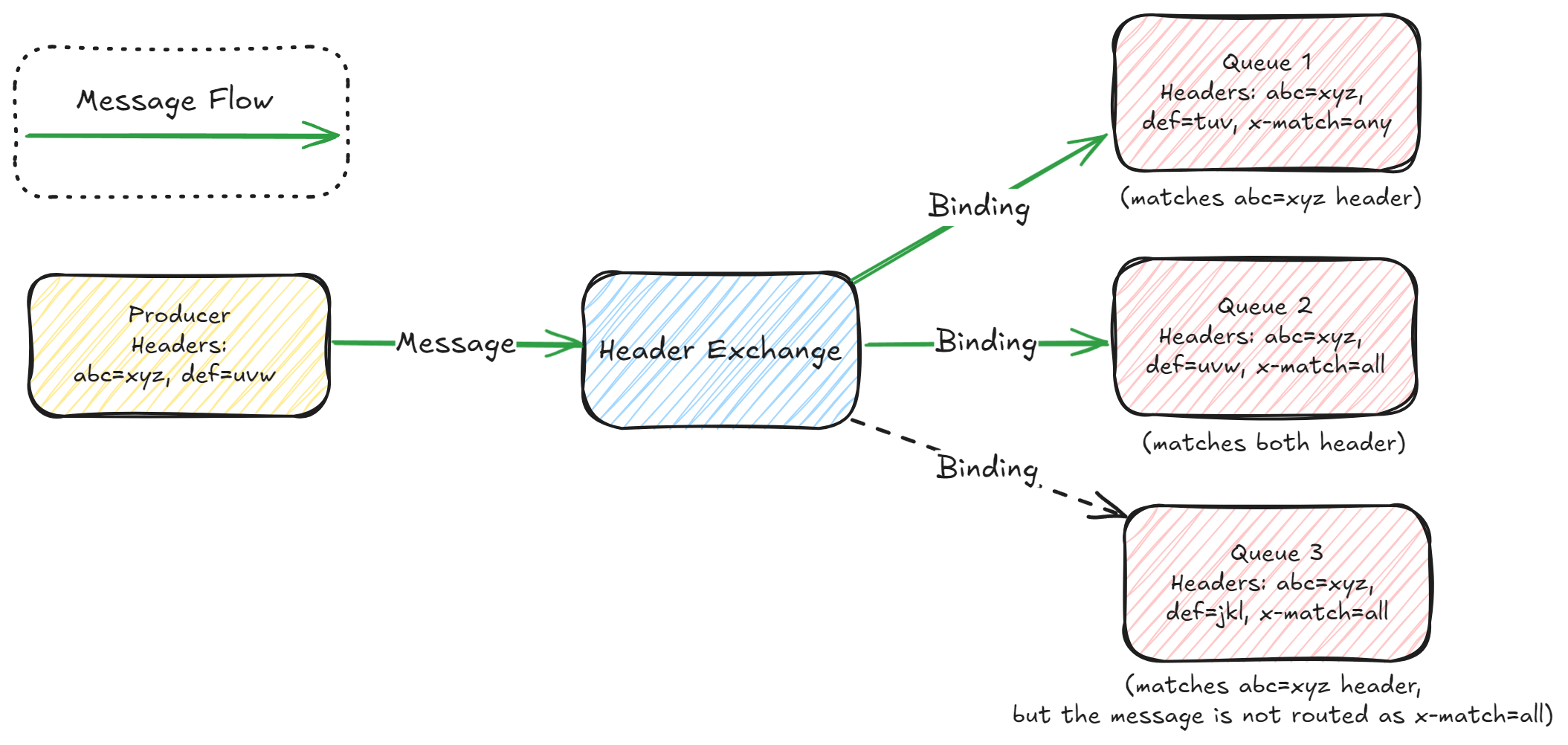
Header Exchange: Header exchange matches message headers and an exact match of header is needed to route the messages. Unlike a topic, there can be multiple headers of a message. To handle this, you can specify a special argument called
x-matchin the binding. Supportedx-matchvalues are -any: If any one of the headers matches, route the message.all: If all of the headers match, then only route the message.
Celery - a Distributed Task Queue🥬
As we already had an introduction to task queues, we can start with different components of Celery and see how it works! But, as we have learned enough theory already, we can start with our project and do some hands-on! We can start with installing the dependencies.

Celery dependencies
As we already established, task queues need message brokers to communicate between producers/publishers and consumers/subscribers. Celery officially supports multiple brokers like -
RabbitMQ
Redis
Amazon SQS
We will be using RabbitMQ for our example. To install RabbitMQ, head over to rabbitmq.com/docs/download and install it for your system of choice. I strongly suggest Ubuntu, Docker or any Linux distribution to use. I have tested my example project in Windows Subsystem for Linux(WSL) 2 - Ubuntu 24.04 distribution and MacOS Sequoia running in Macbook Air M1 (16GB).
Next, we have to install Celery, as it is a Python library we can easily install it using pip -
pip install celery
The most basic program in Celery
Now that we have installed our dependencies, we create a Python file called celery_worker.py.
from celery import Celery
app = Celery('hello', broker='amqp://guest@localhost//')
@app.task
def hello():
print('Hello, World!')
Now that we have our starting file, I will explain it step by step -
We are importing the main Celery class first.
Next, we instantiate Celery into a variable called
app. The first argument is the name of the current module.For the broker keyword argument, we pass the broker URL. For RabbitMQ, the template for the broker URL looks like this -
amqp://myuser:mypassword@localhost:5672/myvhostWhere
amqp://is the main protocol supported by RabbitMQ,myuseris the username andmypasswordis the username and password if credentials are set,localhost:5672is the domain/IP and port where the RabbitMQ server is running, and finallymyvhostis the virtual host of RabbitMQ which helps segregate multiple applications using the same RabbitMQ server.So, for our first celery program, we are connecting to a RabbitMQ broker running in
localhostwith theguestuser, that does not require any password, and using the default vhost/.Next, we create a new method called
hellothat printsHello, World!. We are also annotating the method withapp.taskusing the celery instance we created.
Summarising what we did, we made a very basic celery config and declared a celery task. So we have two of the main components of a task queue configured. Now we will start with the consumer (or worker) first. To launch a celery worker, run this command from the same directory of celery_worker.py and observe the output -
$ celery -A celery_worker worker
-------------- celery@forkbomb-pc v5.4.0 (opalescent)
--- ***** -----
-- ******* ---- Linux-5.15.146.1-microsoft-standard-WSL2-x86_64-with-glibc2.39 2024-10-04 22:52:46
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: hello:0x7fd1cd3b1bd0
- ** ---------- .> transport: amqp://guest:**@localhost:5672//
- ** ---------- .> results: disabled://
- *** --- * --- .> concurrency: 12 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
Though a Python module, celery is also available as an executable. In this command, -A denotes the module name (the filename without extension) and worker keyword asks celery to run a worker. Once the worker is started, it will wait for any task forever. The task is also created, but we now need a producer to enqueue the task.
Let us create another file called producer.py. We will import the Task from celery_worker.py here and enqueue the task.
from celery_worker import hello
# Enqueue the task
hello.delay()
<task_method>.delay() enqueue the task and after running producer.py, immediately you will see that the worker outputs the following -
[2024-10-04 23:02:42,342: WARNING/ForkPoolWorker-8] Hello, World!
If you can see the above output, then congratulations! You have successfully run your first Celery code.
But before we continue further doing advanced stuff, we need to discuss two key components of Celery: 1. Backend (or Result Backend), 2. Worker concurrency models.
Celery Result Backends
In our last example, we have seen the task only prints a line of text to stdout. But what if we want to enqueue a task that produces a result and returns it. Celery has provisions for defining a backend (or storage backend) that can store, retrieve, and monitor task results. The backend can also store task states like pending, success and failure along with task results. Celery backends can be broadly categorized like below -
Database Backends: Celery can store results in databases like PostgreSQL, MySQL, SQLite etc.
Cache Backends: We can store results in in-memory caches like Redis or Memcached. These backends are usually the fastest.
ORM Backends: ORMs or Object Relational Mappers abstract SQL queries to OOP-object or model operations. Celery supports Django ORM and SQLAlchemy as backends.
Message Queue Backends: RabbitMQ, though designed as a broker, can act as a result backend too. Celery writes the task result to a temporary queue and the producer can read the task result from the queue.
Considering the trade-offs, the fastest backends are cache (Redis or Memcached) but they offer limited persistence. But, if the task results are important, any DB or ORM backend will offer much better data persistence but will not be very performant under heavy load.
Celery Worker Concurrency Models⚙️
Concurrency in Celery Workers helps execute tasks in parallel. In my last blog, I discussed multiple ways to achieve parallel execution of tasks in Python. Celery uses similar concurrency models like -
Prefork: The main worker process of Celery launches multiple forked processes that can execute tasks. This worker model is the default, and as it is based on processes, this is recommended for CPU-bound tasks and common use cases. We do not need to specify the
preforkworker using the-Pflag while launching the worker as it is the default, but we can specify the number of forked processes one worker can have using the—concurrencyflag, the default concurrency value for prefork worker is the number of CPU cores.celery -A celery_worker worker --concurrency=4Greenlets: Greenlets are lightweight threads that offer very high concurrency for running I/O-bound tasks. To run a celery worker with greenlets, we need either
eventlet(older, not recommended) orgevent(newer, maintained) library installed.celery -A celery_worker worker --concurrency=1000 -P eventlet celery -A celery_worker worker --concurrency=1000 -P geventNote as greenlets are very lightweight, we can easily run thousands of green threads for each worker.
Threads: Celery uses Python threads to achieve concurrency and needs the Python
concurrent.futuresmodule to be present. Due to the GIL limitation of Python, this worker model is not recommended for CPU-bound workloads.celery -A celery_worker worker --concurrency=10 -P threadsSolo: The solo worker executes one task at a time sequentially in the main worker process.
celery -A celery_worker worker -P soloCustom: Adds support for custom worker pools for third-party implementations.
Getting Task Results with Redis Backend
Now that we have established the required backend and worker knowledge, we can start implementing a backend. We will be using Redis - an in-memory database as a backend. To install Redis, follow the official guide from here: https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/

We also need to install the redis client library so that Python can connect to Redis -
pip install redis
Next, we can change our celery_worker.py to include the Redis backend running in localhost:6379 and db 0 -
app = Celery('hello', backend='redis://localhost:6379/0', broker='amqp://guest@localhost//')
Let’s modify the task method to take a number as input and return its square -
@app.task
def square(x):
return x * x
In the producer, we can now enqueue the task -
from celery_worker import square
result = square.delay(12)
print(result.get())
# Outputs 144
We have now executed two programs and have seen how to schedule tasks and get task results using a backend. The <task_method>.delay() call replicates the method signature and we can pass both method argument and keyword arguments to it.
There is another more advanced method called apply_async() that supports task chaining, callbacks, errbacks (code to execute if the task fails), execution time and expiry. Visit the official Celery doc to learn more about apply_async().
Video🎥 Transcoding with FastAPI, Celery and FFmpeg
From the YouTube example in the Introduction, the video transcoding happens in the background while you add a title, some description, tags etc. and can take many hours depending on your original video quality.
Video transcoding (or downscaling here) is a compute-intensive task that is heavily CPU-bound (or GPU-bound if you use GPU as an accelerator). Distributed task queues can be a perfect fit to solve this problem statement.
Ingredients for our project
We will be using the following tools for our project -
Celery
RabbitMQ as broker
Redis as a result backend
FastAPI for our web framework
FFmpeg - an open-source tool to record, stream, and edit audio, video and other multimedia files. Install it in your system of choice from the official page.
Our requirements.txt looks like this -
celery~=5.4.0 # Celery library
fastapi[standard]~=0.115.0 # FastAPI and its standard dependencies
ffmpeg-python~=0.2.0 # Python library for ffmpeg
redis~=5.1.0 # Python library for connecting to redis
Worker setup
Please clone my repository before proceeding. As this blog is getting longer, it will not be possible to explain every line of source code. I will explain the key syntaxes and the source code will be well commented.
celery_worker.py
from celery import Celery
app = Celery('celery-video-transcoder',
backend='redis://localhost:6379/0',
broker='amqp://guest@localhost//',
include=['helpers.video'])
We are connecting to RabbitMQ as a broker and Redis as a backend with their default settings. However, our tasks are not defined in the same file in the project. To make Celery find the tasks, we need to pass an include argument with the module where the tasks are defined. Our task resize_video_with_progress is defined in helpers/video.py.
API Routes
In the api.py, we have three main routes -
/: We host the home page here which takes a video file as input./upload_file/: Used for handling upload, generating the video thumbnail, and enqueueing a video downscaling task for each quality setting from2160pto144p./task_status/{task_id}/: Used for polling video conversion progress to show the progress in the front end.
About FFmpeg
FFmpeg doesn't come with a GUI or library by default. To use it with Python, we are using the ffmpeg-python library. FFmpeg creates filter graphs for any audio or video operation. Complex filter graphs, with many operations like trimming, merging, mixing, cropping, and adding overlays, can be difficult to manage in the command line. However, the Python library offers a simple syntax to handle these operations.
For example, to downscale a video with a scale filter named rickroll.mp4 to 480p has a syntax like this -
import ffmpeg
ffmpeg.input('rickroll.mp4').filter('scale', -1, 480).output('rickroll_480p.mp4').run()
Here the scale filter takes two arguments, the first is width and the second is height. To scale any video to 480p we set the height to 480 and set the with to -1✳️ to let ffmpeg auto-calculate it.
-1. If the final calculated width is not divisible by 2, the scale filter will fail. Usually, we calculate the output width by multiplying the output height with the original aspect ratio (width/height). So to get a value divisible by 2, we can divide the output width by 2, round off the value and again multiply by 2. The formula is expressed as trunc(oh * (iw / ih) / 2) * 2 where oh = output height, iw = input width and ih = input height.Also using the same scale filter and only taking out a single frame from a random timestamp of the video we can extract a thumbnail.
import random
file_path = 'rickroll.mp4'
thumbnail_path = 'rickroll_thumbnail.jpg'
ffmpeg.input(file_path, ss=random.randint(0, int(float(media_length)))).filter('scale', 1280, -1).output(
thumbnail_path, vframes=1).overwrite_output().run()
I have also used ffmpeg.probe(<file_path>) to extract codec information from the input file which contains video dimension and length.
I added two types of filters, one for normal CPU encoding (with the scale filter) and another one that uses CUDA and nvenc encoder to accelerate the process using NVIDIA GPUs. There is a cuda flag that enables GPU encoding in our task method. Video encoding with nvenc is out of the scope of this blog.
Kowalski, status report!🐧
Celery tracks the status of a task with six predefined states: PENDING, STARTED, SUCCESS, FAILURE, RETRY, REVOKED. To implement status polling from the UI and track the video transcoding progress, I have implemented a custom task state called PROGRESS.
We can call the update_state method from inside the task, that periodically sets a state and marks the progress. I am setting the state PROGRESS and setting a dictionary with a key progress with the percentage of the task completed.
self.update_state(state='PROGRESS', meta={'progress': percent_complete})
To read the task status, I am sending the enqueued task IDs to the front end and polling the /task_status/{task_id} endpoint to get the task status.
from celery.result import AsyncResult
task = AsyncResult(task_id)
if task.state == 'PROGRESS':
task.info.get('progress', 0)
The demo!
To run the demo on your machine you can clone the repository here: https://github.com/f0rkb0mbZ/celery-video-transcoder. I have provided a docker-compose.yml file to make the setup of Redis and Rabbitmq easier. Please pardon my poor UI and javascript skills as I am not a frontend developer. In the demo, I have used the internet’s favourite video in 1080p to downscale it to 720p, 480p, 360p, 240p and 144p, also it generates a thumbnail as a bonus!
Ending note✍🏼
In conclusion, distributed computing with Python, particularly using Celery, offers a robust solution for building scalable applications capable of handling millions of tasks efficiently. We have learned that -
By leveraging task queues and message brokers like RabbitMQ, developers can achieve significant horizontal scalability and decoupling of application components.
Celery's integration with various backends and concurrency models provides flexibility in managing task results and optimizing performance for different workloads.
The practical example of video transcoding demonstrates Celery's capability to handle compute-intensive tasks, showcasing its potential in real-world applications.
As you explore Celery further, you'll find it a valuable tool in your distributed computing toolkit, enabling you to build resilient and scalable systems.
It took a lot of time and effort for me to gather all this information and write this blog. If you've made it this far and appreciate my effort, please give it a 💚. Share this blog with anyone who might find it useful. If you have any questions or need help understanding any concept, feel free to ask in the comments section! Thank you for reading!
References📋
Subscribe to my newsletter
Read articles from Snehangshu Bhattacharya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Snehangshu Bhattacharya
Snehangshu Bhattacharya
I am an Electronics and Communication Engineer passionate about crafting intricate systems and blending hardware and software. My skill set encompasses Linux, DevOps tools, Computer Networking, Spring Boot, Django, AWS, and GCP. Additionally, I actively contribute as one of the organizers at Google Developer Groups Cloud Kolkata Community. Beyond work, I indulge in exploring the world through travel and photography.