Riding the Rust Wave: A Journey from Pandas to Polars in Data Analysis
 Filippo Mameli
Filippo Mameli
There is an interesting trend in the data community involving the rebuilding of popular products using Rust. Polars is one example of this, and it has really caught my interest.
YADL (Yet Another Dataframe Library)?
I've seen many articles claiming that library X can replace or improve Pandas, but I've never seen these libraries used in real work environments. I'm talking about Dask, Vaex, Modin, and Koalas, just to name a few in the Python world. These libraries are fine, but the adoption rate among developers is lackluster. It never crossed my mind to suggest to my colleagues to use these technologies. They might interest data science enthusiasts, but when it comes to using a tool at work, things like:
Community
Documentation
Stability
Ease of use
are the main focus. No one wants to debug an error that can't be solved by looking at the documentation, Stack Overflow, or by asking ChatGPT/Copilot, etc.
I could also mention Julia DataFrames, but I'm not planning to bet on that language anytime soon. Just take a look at Julia's popularity in the 2024 Stack Overflow survey:
Pandas is always the first choice because its advantages far outweigh the disadvantages. If it's too slow, you can just rewrite everything with PySpark.
So, why should I care about Polars?
You need to be quite confident about your product if you describe it on the homepage like this:
Polars is a blazingly fast DataFrame library for manipulating structured data.
I don't know if I'm just caught up in the hype, but Polars really seems like something different. The library is indeed FAST. It's not only faster than the old Pandas but also compared to the new 2.0 release that uses Apache Arrow.
The philosophy behind the product is different. It's not just a carbon copy (or a "rust" copy, ba dum tss!) of Pandas. It's a new, opinionated library that is quickly catching up with the competition. Additionally, I attended PyCon this year and saw a passionate community around this library, which is promising.
The focus of this blog post isn't to praise Polars or demonstrate its speed. There are plenty of articles you can check out, such as:
I just want to share my perspective on a semi-real use case migration from a Pandas notebook to a Polars notebook.
The use case
Okay, so Polars is great. I can use it in my personal projects, and that's fine. But that's not the main point. What about something more practical and useful?
I wanted to see if I could migrate an existing Pandas notebook to Polars. If I can do it easily, I could really propose this to my (imaginary) team, and it wouldn't just be another suggestion to follow the trend of the moment.
I don't want to cherry pick a notebook to showcase Polars. So I went to Google and searched “kaggle pandas titanic” and picked the first result.
The migration
The process is quite straightforward:
Copy and convert all the Pandas code to Polars
Use the Polars approach for developing the notebook whenever possible
So this:
import pandas as pd
titanic_df = pd.read_csv('./kaggle/input/titanic/train.csv')
titanic_df.head()
Become this:
import polars as pl
titanic_df = pl.read_csv('./kaggle/input/titanic/train.csv')
titanic_df.head()
Easy peasy...
Some function names may change, but it's not a big issue. For example, info() becomes describe(), and for isna().sum(), there is the null_count() function, etc.
You can check out the Pandas and Polars notebooks here and here.
Seaborn
I was pleased to see that Seaborn worked right away. I didn't need to change any part of the code. So this:
import seaborn as sns
sns.catplot(x='Sex', data=titanic_df, kind='count')
It's the same for both Polars and Pandas.
Ecosystem
One of the best features of Pandas is its ability to work with major data science libraries. Polars is still new, but it's catching up. It can now be used with Matplotlib, Plotly, Seaborn, and Scikit-Learn, and I'm hopeful for its future.
The syntax
Honestly, I was never a fan of the Pandas syntax. It's not always consistent or easy to read. Operations like .iloc[], .loc[], and [] (bracket notation) can behave differently depending on the situation. Some Pandas methods modify the object directly (e.g., df.drop(inplace=True)), while others return a new object. These aspects can be confusing, even for those who aren't beginners.
I'm a data engineer, and I use PySpark daily. The Polars syntax felt familiar and was easier to understand and write. Polars often uses more explicit, verb-based methods compared to the concise notation of Pandas.
For example, to create a new column ‘Person’ in which every person under 16 is a child. In Pandas, it looks like this:
#Pandas
# Create a new column 'Person' in which every person under 16 is child.
titanic_df['Person'] = titanic_df.Sex
titanic_df.loc[titanic_df['Age'] < 16, 'Person'] = 'Child'
Using loc to conditionally update the 'Person' column feels less intuitive. You have to remember that 'Person' starts as a copy of 'Sex' and then gets changed for certain rows. This approach is difficult to follow and maintain.
On the other hand:
# Polars
# Create a new column 'Person' in which every person under 16 is child.
titanic_df = titanic_df.with_columns(
Person = pl.when(pl.col("Age") < 16)
.then(pl.lit('Child'))
.otherwise(pl.col("Sex"))
)
Polars is more straightforward. It uses the functions when, then, and otherwise to create a new column Person, making it much easier to understand.
Polars Plot
The Polars documentation mentions some plotting features, but as of version 1.0, they are still considered unstable. For example, while Pandas lets you easily use .hist(bins=80) on a DataFrame, Polars doesn't yet have a similarly reliable built-in option. Because of this, I still use libraries like Seaborn for visualization.
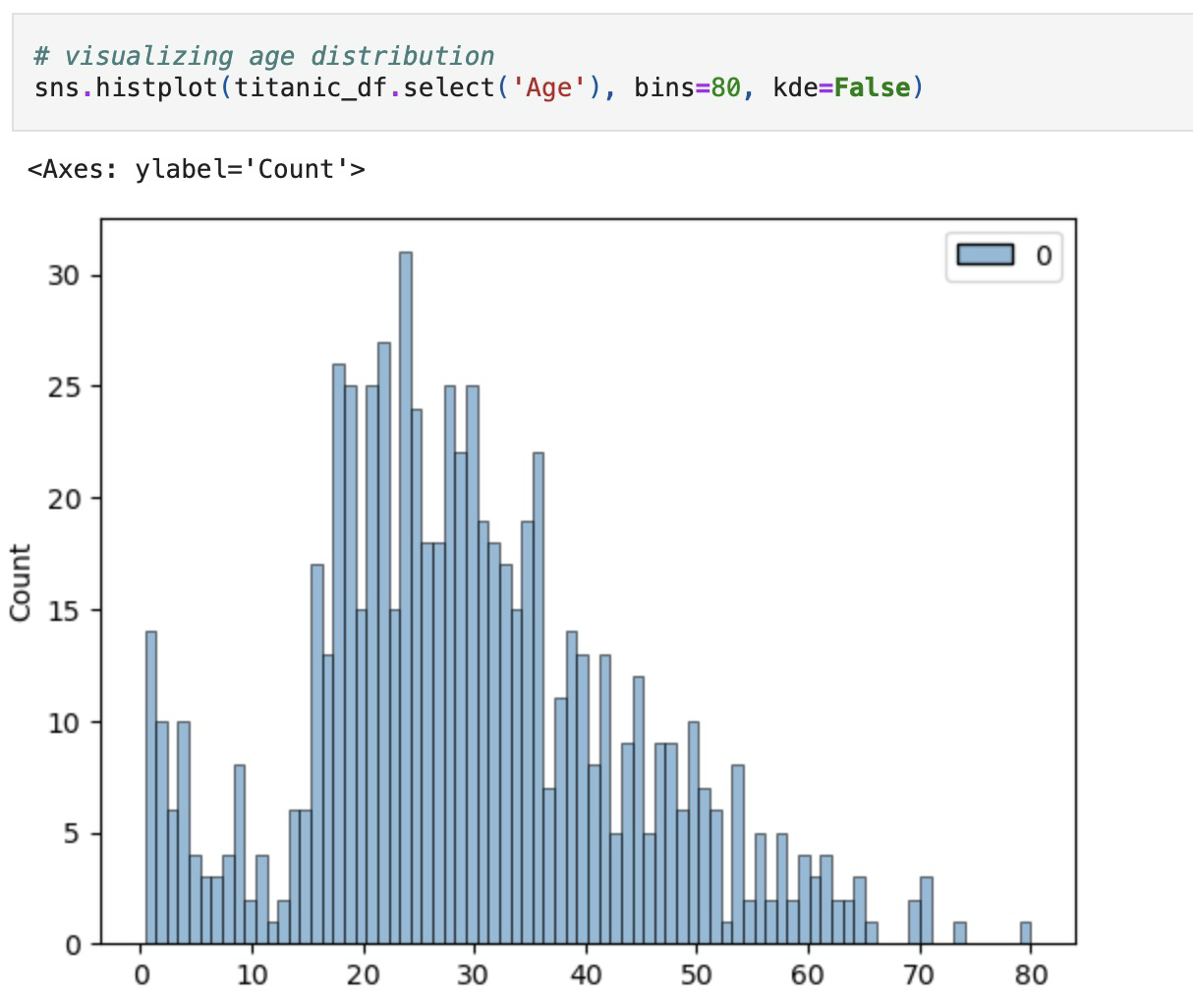
Missing data
However, what Polars lacks in visualization, it more than makes up for in clear, efficient handling of data. Consider the differences in how null values are managed. In Pandas, removing null values from a column is as simple as titanic_df['Cabin'].dropna(). In Polars, the equivalent operation is titanic_df.select(pl.col('Cabin').drop_nulls()). While this may seem like a small difference, it reflects an important improvement. In Pandas, dropna() is used to remove both null and NaN values, which can lead to confusion, especially when working with different data types. In Polars, the functionality is split: drop_nulls() specifically handles null values, while drop_nans() is for NaN values, making the code more explicit and less prone to errors. For example, titanic_df.select(pl.col('Cabin').drop_nans()) would not have the same result as dropping nulls.
Data transformation
Another notable improvement is Polars' efficiency with data transformations. Writing for-loops over a Series in Pandas is often not ideal for performance. Consider this Pandas example:
#Pandas
# let's grab that letter for the deck level with a simple for loop
levels = []
for level in deck:
levels.append(level[0])
cabin_df = pd.DataFrame(levels)
cabin_df.columns = ['Cabin']
cabin_df.sort_values(by='Cabin', inplace=True)
This approach is wordy and not very efficient. In Polars, you can use the with_columns function to handle these operations directly, resulting in code that is more concise, readable, and faster.
# Polars
# let's grab that letter for the deck level with a simple for loop
cabin_df = titanic_df.with_columns(
pl.col('Cabin').str.slice(0, 1).alias('Cabin')
).select('Cabin').drop_nulls().sort('Cabin')
Finally, while using .loc for indexing in Pandas works for smaller datasets, Polars' with_columns() and its conditional functions provide cleaner syntax and much better performance for larger datasets.
Should I switch?
I'm not trying to persuade you to hop on the Polars Hype Train, but I must say that for relatively simple data analysis, choosing Polars is a no-brainer.
For personal projects, I’ll likely stick with Polars, but for work, the decision is more complex. There are several key factors to weigh:
Does your current workflow rely on Pandas alongside less common libraries?
How receptive is your team to adopting a new tool like Polars?
Are you actually facing performance or maintainability issues with Pandas?
Could upgrading to Pandas 2.0 with Arrow integration address these challenges?
If you find that Pandas is holding you back and switching is feasible, Polars is definitely worth trying.
References
https://codecut.ai/pandas-vs-polars-syntax-comparison-for-data-scientists/
https://docs.pola.rs/user-guide/expressions/missing-data/#notanumber-or-nan-values
https://blog.jetbrains.com/pycharm/2024/07/polars-vs-pandas/
https://www.linkedin.com/pulse/polars-vs-pandas-benchmarking-performances-beyond-l6svf
https://www.kaggle.com/code/faressayah/data-science-best-practices-using-pandas-titanic
Subscribe to my newsletter
Read articles from Filippo Mameli directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Filippo Mameli
Filippo Mameli
Hi! I'm Filippo Mameli and I'm a Ai Engineer. I studied Computer Science at the University of Florence and have a Master in Data Science I like Machine Learning, Data Engineering and Web Development. You can find all my personal projects on my Github page. I enjoy listening to music, photography, cinema, and video games.