The Illusion of Reasoning in AI: A Critical Analysis
 Gerard Sans
Gerard Sans
In recent years, Large Language Models (LLMs) like GPT-4 and its successors have taken the AI world by storm, demonstrating remarkable abilities in natural language processing tasks. However, as we delve deeper into their capabilities, a crucial question emerges: Can these models truly reason? This article critically examines the limitations of LLMs in reasoning and challenges the notion that they possess genuine cognitive abilities.
The Fallacy of Statistical Pattern Matching
At their core, LLMs are sophisticated pattern recognition machines. They process vast amounts of text data and generate responses based on statistical probabilities. This fundamental nature raises serious doubts about their ability to engage in authentic reasoning:
Lack of Logical Framework: Unlike human cognition or traditional AI systems built on formal logic, LLMs do not follow a structured, step-by-step reasoning process. Their outputs are probabilistic predictions, not logical deductions.
Inconsistency in Responses: The statistical nature of LLMs means that identical inputs may yield different outputs. This lack of reproducibility is antithetical to true reasoning, which should produce consistent results given the same premises.
GPT-4 o1: Nothing more than a sophisticated illusion
AI systems like GPT-4 o1 that rely on creating tailored training data guided by prompt techniques like Chain-of-Thought (CoT) to enhance performance may give the appearance of reasoning. However, they are fundamentally limited by the same underlying architecture and flaws mentioned above.
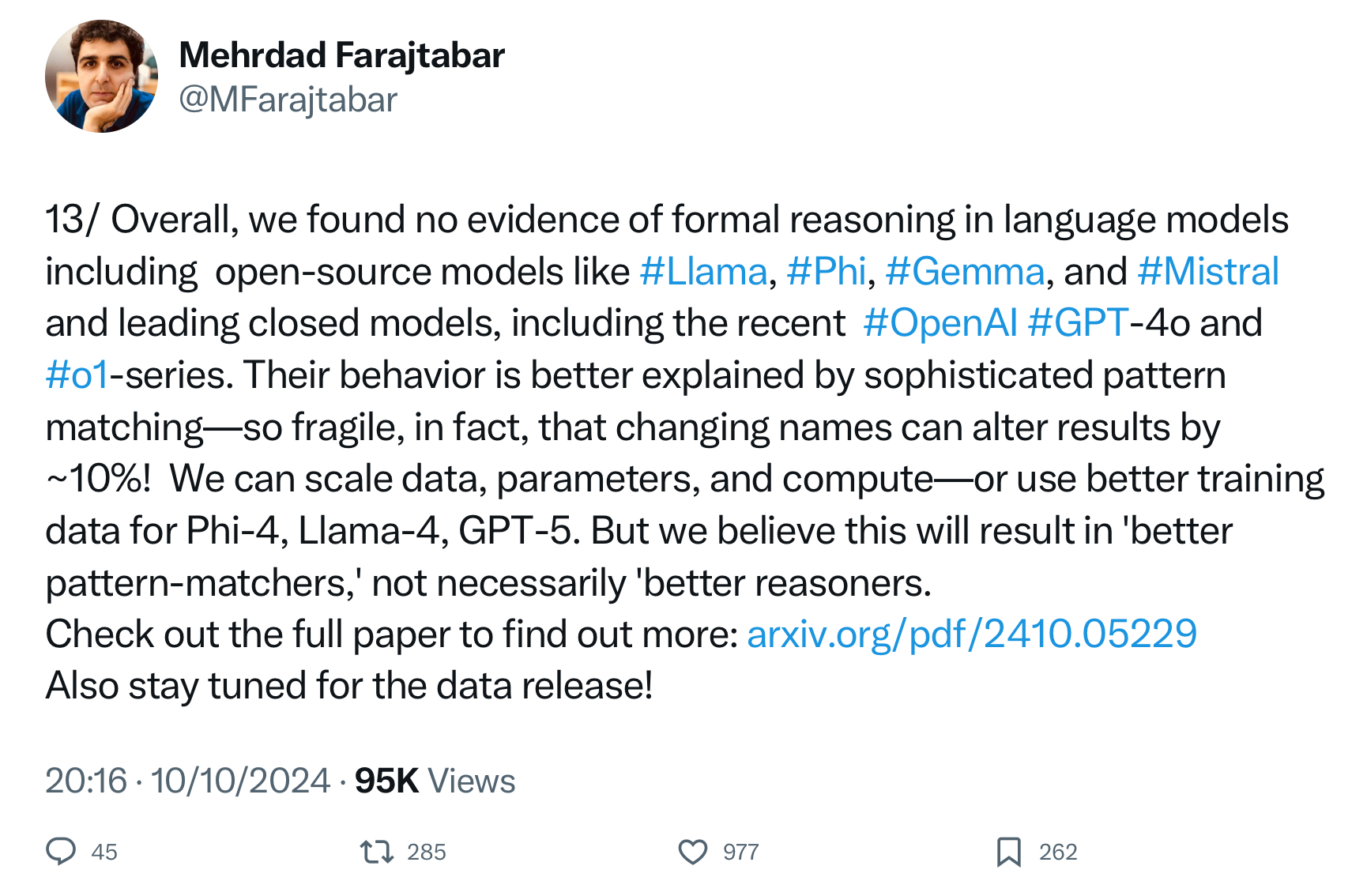
These approaches, while impressive in their ability to mimic reasoning-like outputs, still operate within the confines of statistical pattern matching. They do not address the core issues of lacking a true logical framework or the inherent inconsistency in responses.
The Problem of Falsifiability
A cornerstone of scientific reasoning is falsifiability - the ability to test and potentially disprove a hypothesis. LLMs fall short in this crucial aspect:
Black Box Nature: The opaque decision-making process of LLMs makes it impossible to trace how they arrive at their conclusions. This lack of transparency hinders our ability to validate or refute their reasoning steps.
Absence of Testable Hypotheses: Unlike formal logical systems, LLMs don't generate falsifiable hypotheses. Their probabilistic outputs cannot be definitively proven wrong, making them incompatible with rigorous scientific reasoning.
The Mirage of Context-Dependent Performance
Proponents of LLMs often point to their impressive performance in specific scenarios as evidence of reasoning abilities. However, this argument is fundamentally flawed:
Limited Generalization: While LLMs may excel in narrow, data-rich contexts, they struggle with out-of-distribution problems or tasks requiring multi-step reasoning. This indicates a lack of true understanding and generalization.
Illusion of Intelligence: The context-sensitive success of LLMs can create a false impression of reasoning. In reality, their performance is heavily dependent on the patterns present in their training data, not on genuine cognitive processes.
To illustrate context-dependent performance, notice how mentioning ‘Lisbon’ changes the output without logic or warning. This sensitivity to unrelated words makes LLMs unreliable for high-stakes applications like healthcare or finance, where an unrelated term in a patient history could have serious, hard-to-detect consequences.
Implications for AI Development
Recognizing these limitations is crucial for the responsible development and application of AI:
Realistic Expectations: We must temper our expectations of what LLMs can achieve, especially in critical domains requiring robust reasoning.
Ethical Considerations: Overestimating the reasoning capabilities of LLMs could lead to misuse in high-stakes scenarios, raising serious ethical concerns.
Research Directions: Acknowledging these shortcomings should drive research towards developing AI systems that can truly reason, perhaps by integrating LLMs with other AI paradigms.

Conclusion
While Large Language Models have undoubtedly advanced the field of AI, claiming they possess true reasoning abilities is premature and potentially dangerous. Their statistical nature, lack of falsifiability, and context-dependent performance reveal fundamental limitations in their cognitive capabilities.
As we continue to push the boundaries of AI, it's crucial to maintain a critical perspective on the abilities of these systems. Only by honestly acknowledging their limitations can we hope to develop AI that genuinely reasons, rather than merely mimicking human-like responses based on statistical patterns.
The journey towards AI with true reasoning capabilities is far from over. It requires not just technological advancements, but a deeper understanding of cognition itself. Until then, we must approach the outputs of LLMs with healthy skepticism and resist the temptation to anthropomorphise these powerful, yet fundamentally limited, tools.
Subscribe to my newsletter
Read articles from Gerard Sans directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gerard Sans
Gerard Sans
I help developers succeed in Artificial Intelligence and Web3; Former AWS Amplify Developer Advocate. I am very excited about the future of the Web and JavaScript. Always happy Computer Science Engineer and humble Google Developer Expert. I love sharing my knowledge by speaking, training and writing about cool technologies. I love running communities and meetups such as Web3 London, GraphQL London, GraphQL San Francisco, mentoring students and giving back to the community.