Kubernetes architecture overview
 Megha Sharma
Megha SharmaTable of contents
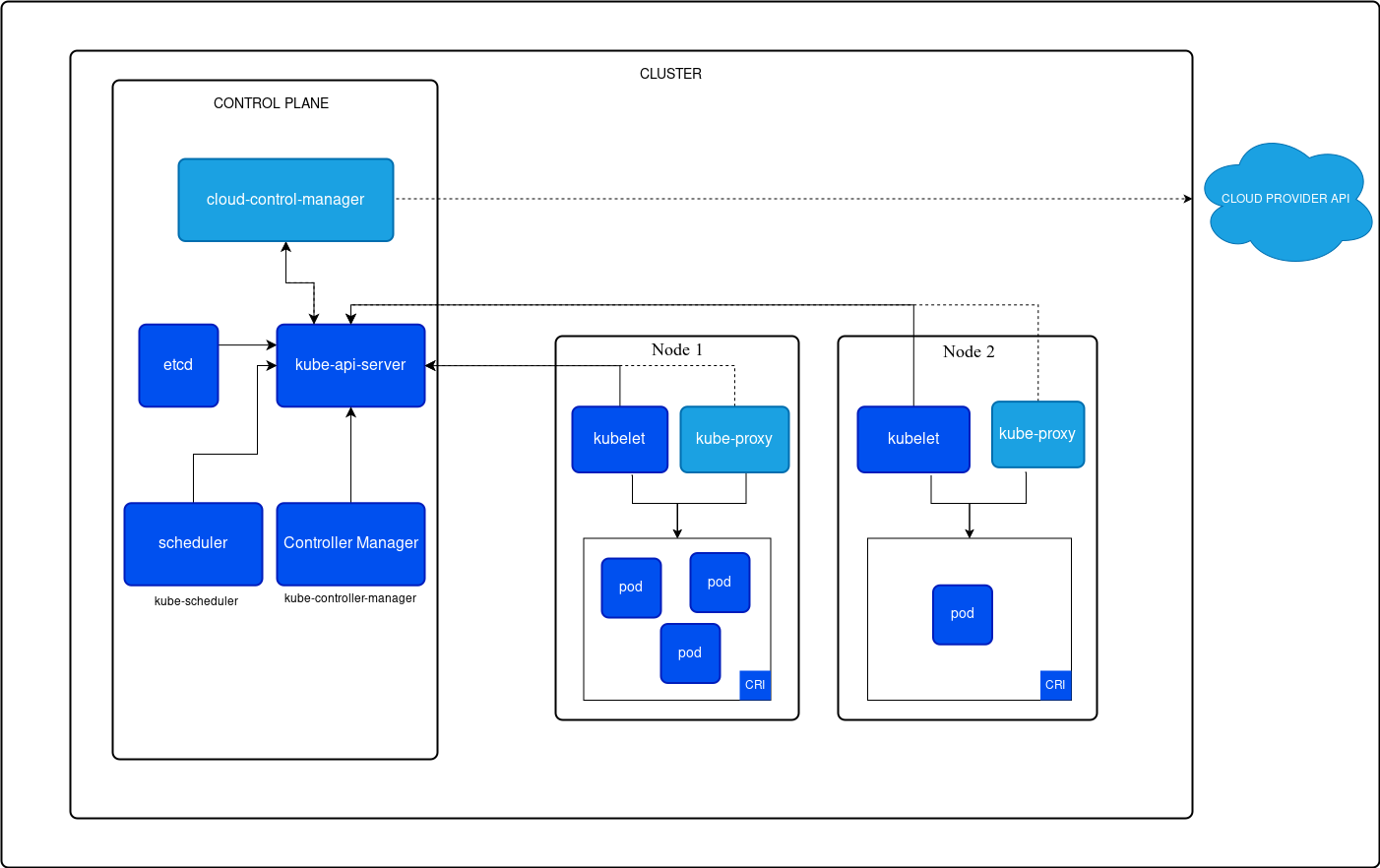
Kubernetes architecture is built around a master-slave (control plane-worker node) model that allows for the efficient deployment, management, and scaling of containerized applications across a cluster of machines. The architecture is highly modular, allowing for flexibility and extensibility.
Kubernetes comes with a client-server architecture. It consists of master and worker nodes, with the master being installed on a single Linux system and the nodes on many Linux workstations. The master node, contains the components such as API Server, controller manager, scheduler, and etcd database for stage storage. kubelet to communicate with the master, the kube-proxy for networking, and a container runtime such as Docker to manage containers.
A Kubernetes cluster consists of a control plane plus a set of worker machines, called nodes, that run containerized applications. Every cluster needs at least one worker node in order to run Pods.
The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault-tolerance and high availability.
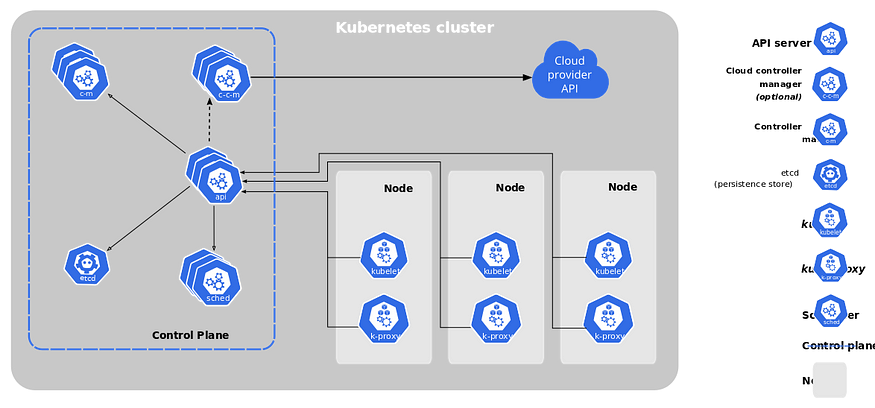
Kubernetes cluster components:
Kubernetes is composed of a number of components, each of which plays a specific role in the overall system. These components can be divided into two categories:
👉Control plane components(Master Node):
The control plane is responsible for managing the state of the Kubernetes cluster. It handles the scheduling, scaling, and orchestration of the containers across the worker nodes. You can access master node via the CLI, GUI, or API.
The master watches over the nodes in the cluster and is responsible for the actual orchestration of containers on the worker nodes.
The control plane’s components make global decisions about the cluster (for example, scheduling), as well as detecting and responding to cluster events (for example, starting up a new pod when a Deployment’s replicas field is unsatisfied).
Control plane components can be run on any machine in the cluster. However, for simplicity, setup scripts typically start all control plane components on the same machine, and do not run user containers on this machine.
The control plane consists of the following components:
➢ kube-apiserver:
The API server is the front end of the Kubernetes control plane. It exposes the Kubernetes API, which is used by all components to communicate and manage the cluster. Users and system components interact with the API server through kubectl, other command-line tools, or custom automation.
It basically redirects all the API to a particular component, for example, if we wish to create a pod, then our request is received by the API server, and then it will forward it to the control manager and End-user only will talk to API server only. Masters communicate with the rest of the cluster through the kube-apiserver, the main access point to the control plane. kube-apiserver also makes sure that configurations in etcd match with configurations of containers deployed in the cluster.
➢ etcd:
etcd is a distributed reliable key-value store that stores all the data and configuration of the Kubernetes cluster. It serves as the source of truth for the cluster’s state, including what nodes exist, what pods are running, and what resources are allocated. It’s a critical component for ensuring high availability and consistency across the cluster.
When you have multiple nodes and multiple masters in your cluster, etcd stores all that information on all the nodes in the cluster in a distributed manner. etcd is responsible for implementing locks within the cluster to ensure there are no conflicts between the Masters.
➢ kube-scheduler:
The scheduler determines which worker node should run a newly created pod (a collection of one or more containers). It makes decisions based on resource requirements, policies, and constraints (e.g., memory, CPU). It ensures that workloads are balanced across the nodes and efficiently utilize resources.
When API Server receives a request for Scheduling Pods then the request is passed on to the Scheduler. It intelligently decides on which node to schedule the pod for better efficiency of the cluster.
Scheduler task is to schedule the tasks(like creating pod) on the proper node, it checks for the highest ram and storage available node and schedules the tasks accordingly, it basically manages the load between the nodes. It looks for newly created containers and assigns them to Nodes.
➢ kube-controller-manager:
The controller manager is responsible for running a series of controllers, which are processes that continually monitor the cluster’s state and make adjustments to ensure the desired state.
It will check for the number of workers in the k8 cluster is available for not.
It will check for node state every 5 seconds, if any of the nodes will not respond for 40 seconds then node schedular will mark it as unreachable.
After that, if that node still does not respond in the next 5 minutes, then k8 will schedule the pod present in that node to some other node.
Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
There are many different types of controllers. Some examples of them are:
Node controller: Monitors the health of worker nodes and takes action if a node becomes unresponsive.
Job controller: Watches for Job objects that represent one-off tasks, then creates Pods to run those tasks to completion.
EndpointSlice controller: Populates EndpointSlice objects (to provide a link between Services and Pods).
ServiceAccount controller: Create default ServiceAccounts for new namespaces.
Replication Controller: Ensures that a specified number of pod replicas are running.
Namespace Controller: Manages namespace lifecycle.
➢ cloud-controller-manager:
A Kubernetes control plane component that embeds cloud-specific control logic. The cloud controller manager lets you link your cluster into your cloud provider’s API, and separates out the components that interact with that cloud platform from components that only interact with your cluster.
The cloud-controller-manager only runs controllers that are specific to your cloud provider. If you are running Kubernetes on your own premises, or in a learning environment inside your own PC, the cluster does not have a cloud controller manager.
As with the kube-controller-manager, the cloud-controller-manager combines several logically independent control loops into a single binary that you run as a single process. You can scale horizontally (run more than one copy) to improve performance or to help tolerate failures.
The following controllers can have cloud provider dependencies:
Node controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding
Route controller: For setting up routes in the underlying cloud infrastructure
Service controller: For creating, updating and deleting cloud provider load balancers
👉 Node components:
Node components run on every node, maintaining running pods and providing the Kubernetes runtime environment.
Worker nodes are the machines that run the actual application workloads (containers). Each worker node has several critical components that ensure containers are running properly and can communicate across the cluster.
These are the nodes where the actual work happens. Each Node can have multiple pods and pods have containers running inside them. There are 3 processes in every Node that are used to Schedule and manage those pods.
➢ kubelet:
kubelet is an agent that runs on each worker node. It communicates with the control plane, receives instructions (such as which containers to run), and ensures that the containers are running in the correct state as defined in the PodSpec. It continuously monitors the status of pods and reports back to the control plane.
An agent that runs on each node in the cluster. It makes sure that containers are running in a Pod.
The kubelet takes a set of PodSpecs that are provided through various mechanisms and ensures that the containers described in those PodSpecs are running and healthy. The kubelet doesn’t manage containers which were not created by Kubernetes.
➢ kube-proxy:
kube-proxy is a network proxy that runs on each node in your cluster, It maintains network rules and ensures that network traffic is properly routed to and from the containers running on the node. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
kube-proxy uses the operating system packet filtering layer if there is one and it’s available. Otherwise, kube-proxy forwards the traffic itself.
If you use a network plugin that implements packet forwarding for Services by itself, and providing equivalent behavior to kube-proxy, then you do not need to run kube-proxy on the nodes in your cluster.
Kube proxy will create and manage the network rules, it will help to establish communication between two pods which are in different nodes.
The kube-proxy is responsible for ensuring network traffic is routed properly to internal and external services as required and is based on the rules defined by network policies in kube-controller-manager and other custom controllers.
➢ Container runtime:
The container runtime is the software responsible for running the actual containers on the node. Kubernetes supports different container runtimes, including Docker, containerd, and CRI-O.
The container runtime pulls container images, starts and stops containers, and integrates with the kubelet to maintain the desired state.
➢ Pods:
A pod is the smallest, most basic deployable unit in Kubernetes. Each pod represents a single instance of a running process in a cluster.
A pod can contain one or more containers that share the same network namespace and can communicate with each other via localhost.
Pods are ephemeral by nature. Kubernetes automatically schedules pods on nodes and can restart or move them based on the cluster’s state and resource availability.
👉 High-Level Workflow in Kubernetes
User Interaction: Users or CI/CD pipelines interact with the kube-apiserver via
kubectlor other clients to define the desired state for an application (e.g., creating a deployment or service).Scheduler Action: The kube-scheduler identifies appropriate nodes to run the workloads based on available resources and other constraints.
kubelet: The kubelet on each worker node ensures that the specified containers are running in pods on the correct nodes and reports back to the control plane.
Networking and Services: The kube-proxy handles the routing and load balancing of traffic between services and pods.
State Management: The control plane uses etcd to store and persist the cluster’s desired state. Controllers within the kube-controller-manager ensure that the cluster is continuously working toward that desired state.
Subscribe to my newsletter
Read articles from Megha Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Megha Sharma
Megha Sharma
👋 Hi there! I'm a DevOps enthusiast with a deep passion for all things Cloud Native. I thrive on learning and exploring new technologies, always eager to expand my knowledge and skills. Let's connect, collaborate, and grow together as we navigate the ever-evolving tech landscape! SKILLS: 🔹 Languages & Runtimes: Python, Shell Scripting, YAML 🔹 Cloud Technologies: AWS, Microsoft Azure, GCP 🔹 Infrastructure Tools: Docker, Terraform, AWS CloudFormation 🔹 Other Tools: Linux, Git and GitHub, Jenkins, Docker, Kubernetes, Ansible, Prometheus, Grafana