Parent Document Retrieval: Balancing Detail and Context for Complex Queries
 Zahiruddin Tavargere
Zahiruddin Tavargere
Why Use Parent Document Retrieval?
Traditional RAG methods can struggle with intricate questions due to their reliance on smaller text segments that may not encapsulate the broader themes or details of the original documents.
When building a RAG-based solution, answer the following questions before creating the indexing pipeline.
What type of queries will the system handle?
- Are the queries typically seeking specific details, or do they require a broader contextual understanding?
How important is precision versus context in the system’s responses?
- Should the system prioritize precise answers to detailed questions (favoring smaller chunks), or should it provide more comprehensive responses even if they are less precise (favoring larger chunks)?
How much detail or noise is acceptable in the retrieved results?
- Will smaller chunks provide too little context, or will larger chunks introduce too much irrelevant information?
Can the user’s query context vary significantly?
- If the user queries tend to be more context-dependent, would using larger chunks improve understanding, or could the system risk missing key details?
What is the nature of the content being used for retrieval?
- Does the content lend itself better to smaller chunks (e.g., factual, concise information), or does it require larger chunks to capture essential relationships and context (e.g., narrative or complex data)?
What is Parent Document Retrieval (PDR)?
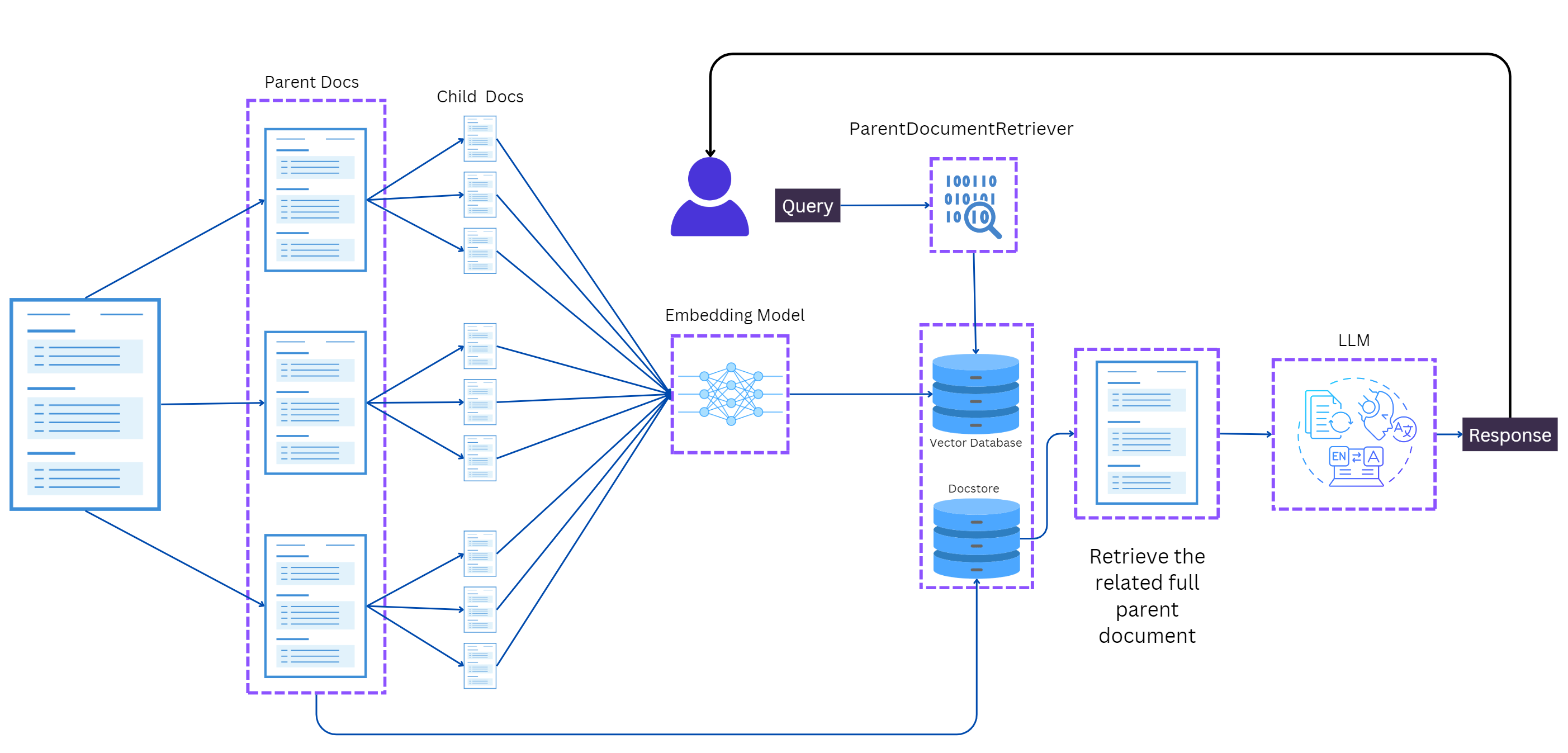
Parent Document Retrieval (PDR) is a sophisticated technique utilized in Retrieval-Augmented Generation (RAG) models to enhance the retrieval process by obtaining full parent documents to augment the LLM generation.
This method addresses the limitations of standard RAG approaches that often rely on smaller text chunks, which may lack the necessary context for complex queries.
By retrieving complete parent documents, PDR allows for a more comprehensive understanding of the material, leading to richer and more informative responses, particularly for nuanced inquiries.
Where is Parent Document Retrieval Applied?
PDR is applicable in various domains where context-rich responses are essential. Some common applications include:
Customer Support: Enhancing automated systems to provide detailed responses based on comprehensive product documentation.
Legal and Compliance: Assisting in retrieving relevant legal documents or regulations that require in-depth understanding.
Research and Academia: Facilitating access to full research papers or articles when specific sections are referenced.
Content Generation: Improving the quality of content produced by language models by providing them with extensive background information.
When Should Parent Document Retrieval be Used?
PDR should be employed particularly in scenarios where:
The queries are complex or multifaceted, requiring detailed context.
The available data consists of lengthy documents that need to be segmented for better comprehension.
There is a need to ensure high accuracy and relevance in responses generated by language models.
Users seek comprehensive answers rather than brief snippets of information.
Using PDR can significantly enhance the performance of RAG systems in these situations
Who Benefits from Parent Document Retrieval?
Various stakeholders can benefit from PDR, including:
Developers and Data Scientists: Those working on RAG systems can leverage PDR to improve model performance and user satisfaction.
Businesses: Organizations seeking efficient customer support solutions can enhance their automated systems with PDR.
Researchers and Academics: Individuals needing thorough literature reviews or data analysis can utilize PDR for more effective information retrieval.
End Users: Anyone seeking detailed and contextually rich information will benefit from systems employing PDR.
How to implement PDR using LangChain?
You can go through the entire code in this notebook. Sharing some important snippets below.
from langchain.schema import Document
from langchain.vectorstores import Chroma
from langchain.retrievers import ParentDocumentRetriever
from langchain.chains import RetrievalQA
from langchain_openai import OpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders import TextLoader,WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import os
import tiktoken
from google.colab import userdata
# Loading a single website
loaders = [
WebBaseLoader("https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3864624/"),
WebBaseLoader("https://www.mayoclinic.org/diseases-conditions/lung-cancer/symptoms-causes/syc-20374620")
]
docs = []
for loader in loaders:
token_count = num_tokens_from_string(str(loader.load()),"cl100k_base")
print(f"Tokens for {loader.web_path}: {token_count}")
docs.extend(loader.load())
Output below
Tokens for https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3864624/: 43869
Tokens for https://www.mayoclinic.org/diseases-conditions/lung-cancer/symptoms-causes/syc-20374620: 4997
Create parentsplitter and childsplitter using the RecursiveCharacterTextSplitter module in LangChain.
Use Chrom DB as a vector store and LangChain’s InMemoryStore to store large docs or chunks.
# This text splitter is used to create the parent documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(
collection_name="split_parents", embedding_function=OpenAIEmbeddings(model="text-embedding-3-small")
)
# The storage layer for the parent documents
store = InMemoryStore()
Instantiate the ParentDocumentRetriever class using the above as parameters.
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
Add the docs we created using the WebPageLoader to the retriever object.
retriever.add_documents(docs)
Test the vector store with a query.
sub_docs = vectorstore.similarity_search("What are the symptoms of Lung Cancer?")
print(sub_docs[0].page_content)
The response.
SymptomsLung cancer typically doesn't cause symptoms early on. Symptoms of lung cancer usually happen when the disease is advanced.
Signs and symptoms of lung cancer that happen in and around the lungs may include:
A new cough that doesn't go away.
Chest pain.
Coughing up blood, even a small amount.
Hoarseness.
Shortness of breath.
Wheezing.
Let’s see the parent doc that is returned for the same query using the retriever object.
retrieved_docs = retriever.invoke("What are the symptoms of Lung Cancer?")
print(retrieved_docs[0].page_content)
Response.
Patient Care & Health Information
Diseases & Conditions
Lung cancer
Request an Appointment
Symptoms &causesDiagnosis &treatmentDoctors &departmentsCare atMayo Clinic
Print
Overview
Lung cancer
Enlarge image
Close
Lung cancer
Lung cancer
Lung cancer begins in the cells of the lungs.
Lung cancer is a kind of cancer that starts as a growth of cells in the lungs. The lungs are two spongy organs in the chest that control breathing.
Lung cancer is the leading cause of cancer deaths worldwide.
People who smoke have the greatest risk of lung cancer. The risk of lung cancer increases with the length of time and number of cigarettes smoked. Quitting smoking, even after smoking for many years, significantly lowers the chances of developing lung cancer. Lung cancer also can happen in people who have never smoked.Products & ServicesA Book: Mayo Clinic Family Health BookNewsletter: Mayo Clinic Health Letter — Digital EditionShow more products from Mayo Clinic
SymptomsLung cancer typically doesn't cause symptoms early on. Symptoms of lung cancer usually happen when the disease is advanced.
Signs and symptoms of lung cancer that happen in and around the lungs may include:
A new cough that doesn't go away.
Chest pain.
Coughing up blood, even a small amount.
Hoarseness.
Shortness of breath.
Wheezing.
Signs and symptoms that happen when lung cancer spreads to other parts of the body may include:
Bone pain.
Headache.
Losing weight without trying.
Loss of appetite.
Swelling in the face or neck.
When to see a doctorMake an appointment with your doctor or other healthcare professional if you have any symptoms that worry you.
If you smoke and haven't been able to quit, make an appointment. Your healthcare professional can recommend strategies for quitting smoking. These may include counseling, medicines and nicotine replacement products.
Request an appointment
1925
Let’s create a chain using an LLM to generate responses using the query and the context from the retriever.
from langchain_core.runnables import RunnablePassthrough
# Prompt template
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
chain.invoke("How are smoking and Lung Cancer related?")
Response
Smoking is the primary cause of most lung cancers.
It introduces cancer-causing substances, known as carcinogens, into the lungs, which damage the cells that line the lung tissue.
This damage can lead to changes in the cells' DNA, causing them to grow and multiply uncontrollably, ultimately resulting in cancer.
Additionally, smoking can also affect non-smokers through secondhand smoke exposure. While lung cancer can occur in individuals who have never smoked, the exact causes in these cases may not be clear. Overall, smoking significantly increases the risk of developing lung cancer.
As you can see the response seems to be pretty neat and grounded.
Let me know in the comments how your experiments went.
Subscribe to my newsletter
Read articles from Zahiruddin Tavargere directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Zahiruddin Tavargere
Zahiruddin Tavargere
I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.