How OpenAI o1 models simulate human reasoning
 Sai Chowdary Gullapally
Sai Chowdary Gullapally
TLDR 🤏
The OpenAI o1 model uses a dedicated ‘reasoning stage’ to generate reasoning tokens, which help break down complex problems into manageable subtasks, simulating a structured thinking process similar to human reasoning.
This dedicated reasoning stage, enhanced by training the model with Reinforcement Learning to generate effective chain-of-thought tokens, allows the o1 model to tackle complex questions more effectively and efficiently, setting it apart from previous models that relied heavily on prompt engineering to mimic reasoning.
Introduction 👋
The new OpenAI o1 model promises to revolutionize how AI handles complex problems—by 'thinking' like a human. This model doesn’t just answer questions; it reasons its way through them[2]. In this article, we’ll dive deep into how the OpenAI o1 model achieves this ‘thinking’ capability that enables it to outperform even advanced models like GPT-4o, particularly in tasks that require complex reasoning.
What does ‘Reasoning’ mean in this context? 🧠
When given a complex question like making a business plan, we need to think deeply. We consider various aspects, break them down, analyze each part, and evaluate multiple approaches with their pros and cons. This process of understanding the task, breaking it down, and creating a coherent chain-of-thought is what OpenAI refers to as ‘Reasoning’.[1].
Why can’t regular LLMs ‘Reason’ well? 🤔
Consider the following 2 constraints
LLMs can only think one step at a time 🚫
When generating an answer, the LLM acts as a sequence completer, predicting one token at a time in an autoregressive manner. It uses self-attention to analyze patterns in the previous tokens and predict the next one. However, since the model processes tokens step by step, it cannot foresee if its approach will lead to an incorrect answer further down the sequence. This means the model is effectively thinking one step at a time.
LLMs do not usually change their answer midway 🚫
When humans encounter complex questions, we often adapt our approach if the initial one proves ineffective. In contrast, LLMs tend to follow their initial method without adjusting midway, proceeding step by step. This behavior likely stems from how information is typically documented, where final answers are presented without showing the iterative problem-solving process. Since LLMs are primarily trained on such data from sources like the internet, they lack exposure to this iterative reasoning, limiting their ability to switch strategies during problem-solving.
Imagine driving down a one-way street with no option to turn back, even if your destination is in the opposite direction. LLMs function similarly due to the above constraints—they make decisions step by step without the ability to ‘rewind’ or correct their approach, making it critical for them to start in the right direction. Usually, language flows smoothly and predictably, allowing self-attention to accurately learn patterns in the input prompt and predict the next words. But this method often falls short when solving complex tasks like intricate math problems where flow need not be smooth, leading to mistakes
Previous approaches for ‘Reasoning’ 🤓
Let’s consider the following question and the LLMs answer for it:

In the example above (from the paper [7]), the LLM is asked a relatively simple math question, yet it fails to provide the correct answer. This is likely because the LLM cannot break the problem down into smaller, manageable subtasks like we do in our minds. To guide the LLM in this direction, the authors of paper [7] modified the prompt, as shown below:

The authors introduce an example question-answer pair into the LLM's prompt, and instead of providing a simple, one-word answer, they break the solution into intermediate steps. Each step addresses a simpler subtask, ultimately leading to the correct result. The idea is that since LLMs analyze patterns in sequences, giving them an example answer in the prompt that follows a structured approach helps them replicate it when answering the main question. As demonstrated, the LLM follows this chain-of-thought reasoning, arriving at the correct answer, much like humans do. This method, known as Chain-of-Thought prompting, encourages LLMs to reason step by step.
The example above is from a 2022 paper [7], and since then, LLMs have made significant progress. Most modern LLMs can now reason through simple questions independently, without the need for 'chain-of-thought' prompting. This advancement is likely due to instruction fine-tuning, where LLMs are trained on supervised data with prompt-answer pairs. These pairs often feature answers broken down into step-by-step reasoning, helping LLMs learn how to address tasks by breaking them into smaller steps [8]. However, contemporary LLMs still struggle when faced with more complex questions.
OpenAI o1 vs GPT-4o 🌟
Now, we will explore how the OpenAI o1 model excels in solving questions requiring complex reasoning questions where other LLMs fail. We will achieve this by comparing the performance of the OpenAI o1 model to that of the GPT-4o model on a challenging question.
The Question 📜
This task involves analyzing data from a cricket match, specifically focusing on six overs (each over consists of six balls, so we have data for a total of 36 balls) from the 2024 T20 World Cup Final between India and South Africa. In cricket, each ball bowled can lead to different outcomes, such as runs scored, no runs, or the batsman getting out.
Our goal is to determine how many times Virat Kohli scored exactly four runs from a single ball, known as hitting a "four" in cricket terminology. The dataset contains detailed information for each ball bowled during these six overs, including the runs scored and the player who scored them. We need to filter through this data to count the total number of "fours" hit by Kohli.
To simplify this for those unfamiliar with cricket, imagine a baseball game where you count how many times a player hits a double (reaches second base) in an inning. Similarly, in this task, we are counting how many times Kohli hit four runs from one delivery.
You can review the ball-by-ball data here. This data was generated by post-processing and cleaning data from ESPN CricInfo web page[7]. Since the datas is too large to display, I will use the variable ESPN_DATA to represent the data when showing the prompt structure in this post (This is the link to the cleaned/processed data that is used in experiments).
According to the data, Kohli hit 4 fours, which is the correct answer the LLM should provide.
GPT-4o struggles with the task 🚫
We will pose the following question[link to full question] for GPT-4o which is a very good model in general.
Based on the 'CONTEXT' given below answer the 'QUESTION' below
the 'CONTEXT':
'CONTEXT':
<ESPN_DATA>
'QUESTION'
How many fours did Kohli hit?
Let us see GPT-4o’s answer:
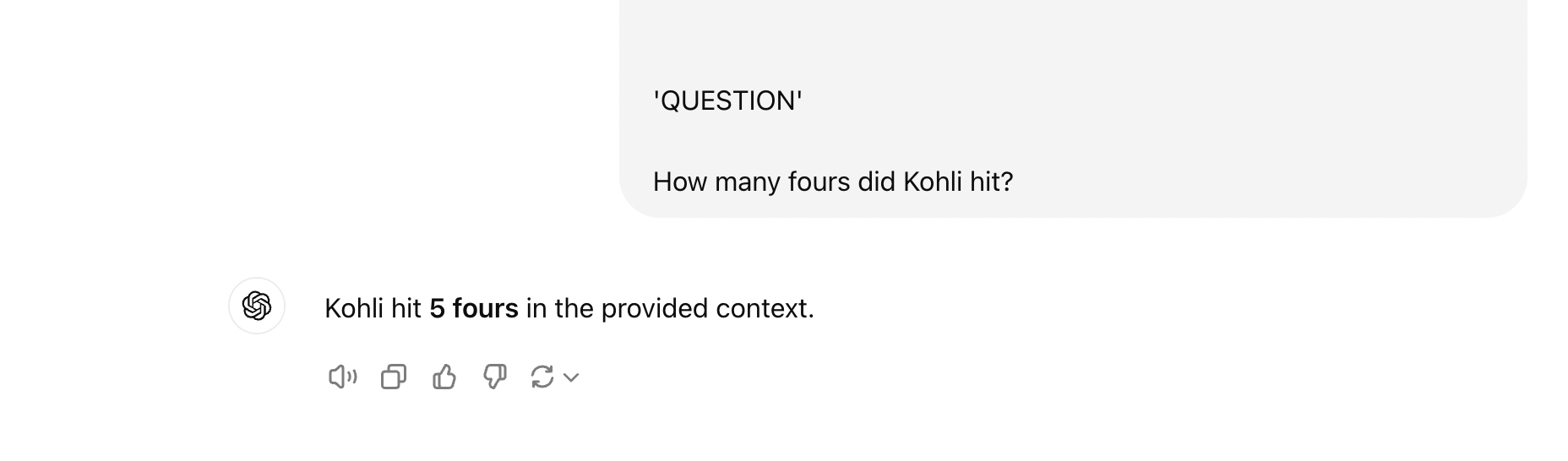
As you can see that instead of reasoning step by step, it directly predicts the answer as 5, which is actually incorrect. This question was too complex for GPT-4o model.
Can GPT-4o solve this if we ‘think’ on its behalf? ✅
Now, let's conduct an experiment where we 'think' on behalf of GPT-4o and guide it through solving this complex problem. As humans, our approach would look something like this:
We have data from 6 overs (numbered 0-5), with each over consisting of 6 deliveries. I would scan through each over and count how many fours were hit by Kohli in each one.
Then, I would aggregate this information to find the total number of fours he scored.
Since GPT-4o couldn't break the task down this way on its own, we’ll guide it by splitting the task into two simpler subtasks. This staged breakdown will also help us later when comparing it to how the o1 model handles the problem.
- First, we provide the following prompt to GPT-4o to analyze the number of fours hit by Kohli in each over:
Based on the 'CONTEXT' given below answer the 'QUESTION' below
the 'CONTEXT':
'CONTEXT':
<ESPN_DATA>
'QUESTION'
If we go through and inspect all the balls in each over
and keep track of the number of fours Kohli hit in
each of those overs. We can list down the number of fours
in each over in
'over X: <number of fours in over X> format as shown below'
For this GPT-4o is able to correctly analyze over by over as follows:

- For the next subtask, we’ll take the previous prompt along with GPT-4o’s over-by-over analysis and include it as additional context in the prompt. Then, we’ll ask GPT-4o to address the main question. With this added context, the final prompt will look like this:
Based on the 'CONTEXT' given below answer the 'QUESTION' below
the 'CONTEXT':
'CONTEXT':
<ESPN_DATA>
'QUESTION'
If we go through and inspect all the balls in each over
and keep track of the number of fours Kohli hit in
each of those overs. We can list down the number of fours
in each over in
'over X: <number of fours in over X> format as shown below'
Here’s the list of the number of fours Kohli hit in each over:
Over 0: 3 fours
Over 1: 0 fours
Over 2: 0 fours
Over 3: 1 four
Over 4: 0 fours
Over 5: 0 fours
This gives us the number of fours Kohli hit per
over based on the context provided.
How many fours did Kohli hit?
Now GPT-4o correctly answers as follows!!

The takeaway here is that GPT-4o was capable of solving both the above subtasks by itself, it just needed some guidance from us i.e we did the ‘thinking’ on behalf of GPT-4o.
OpenAI o1 model does not need guidance ✅
Now let us see if the o1 model can solve this, we use the same prompt as before:
Based on the 'CONTEXT' given below answer the 'QUESTION' below
the 'CONTEXT':
'CONTEXT':
<ESPN_DATA>
'QUESTION'
How many fours did Kohli hit?
Let us see OpenAI o1’s answer:
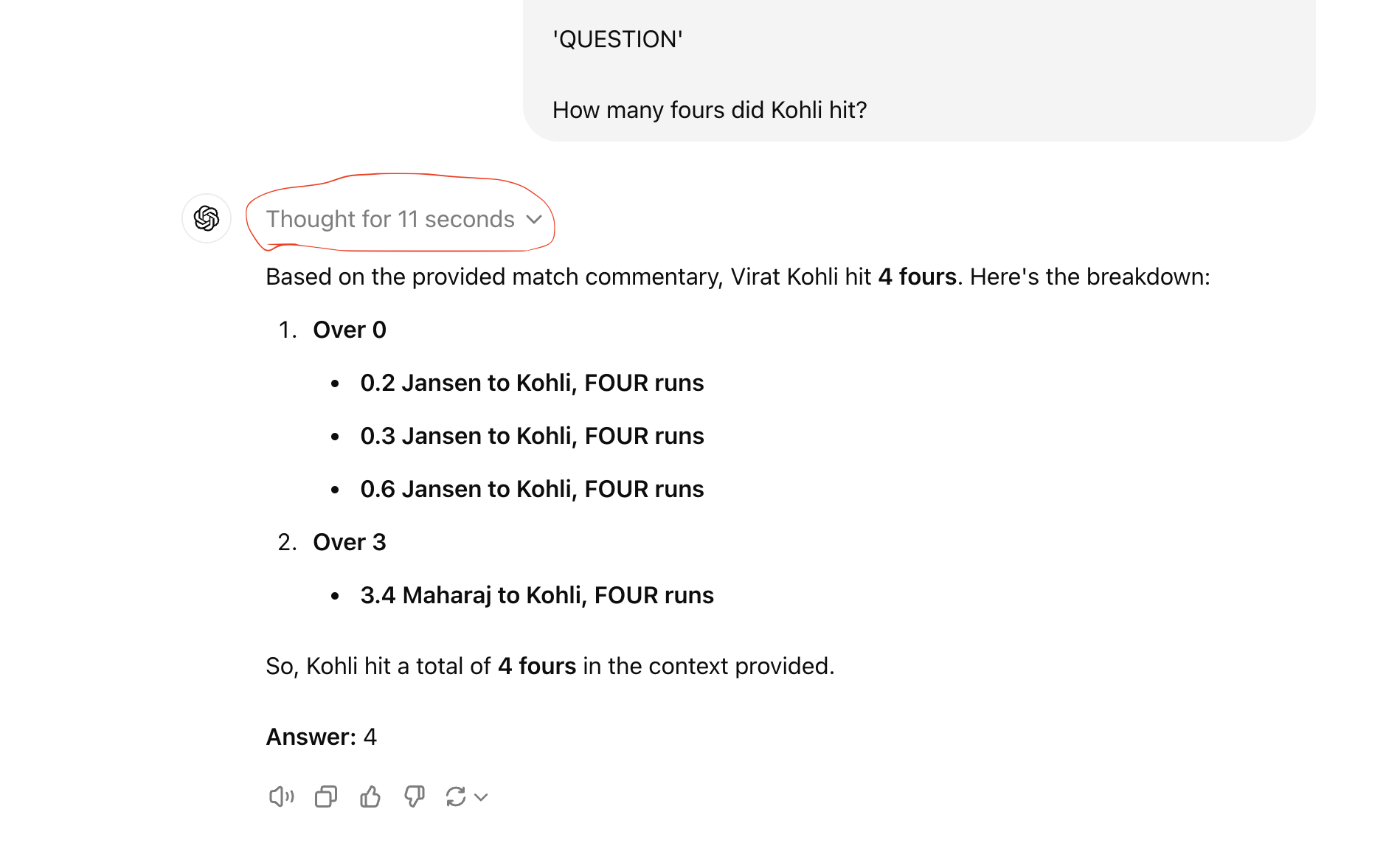
As demonstrated, OpenAI o1 successfully solves this problem and provides the correct answer. It appears to have approached the solution similarly to how humans would, by analyzing each over and aggregating the results at the end.
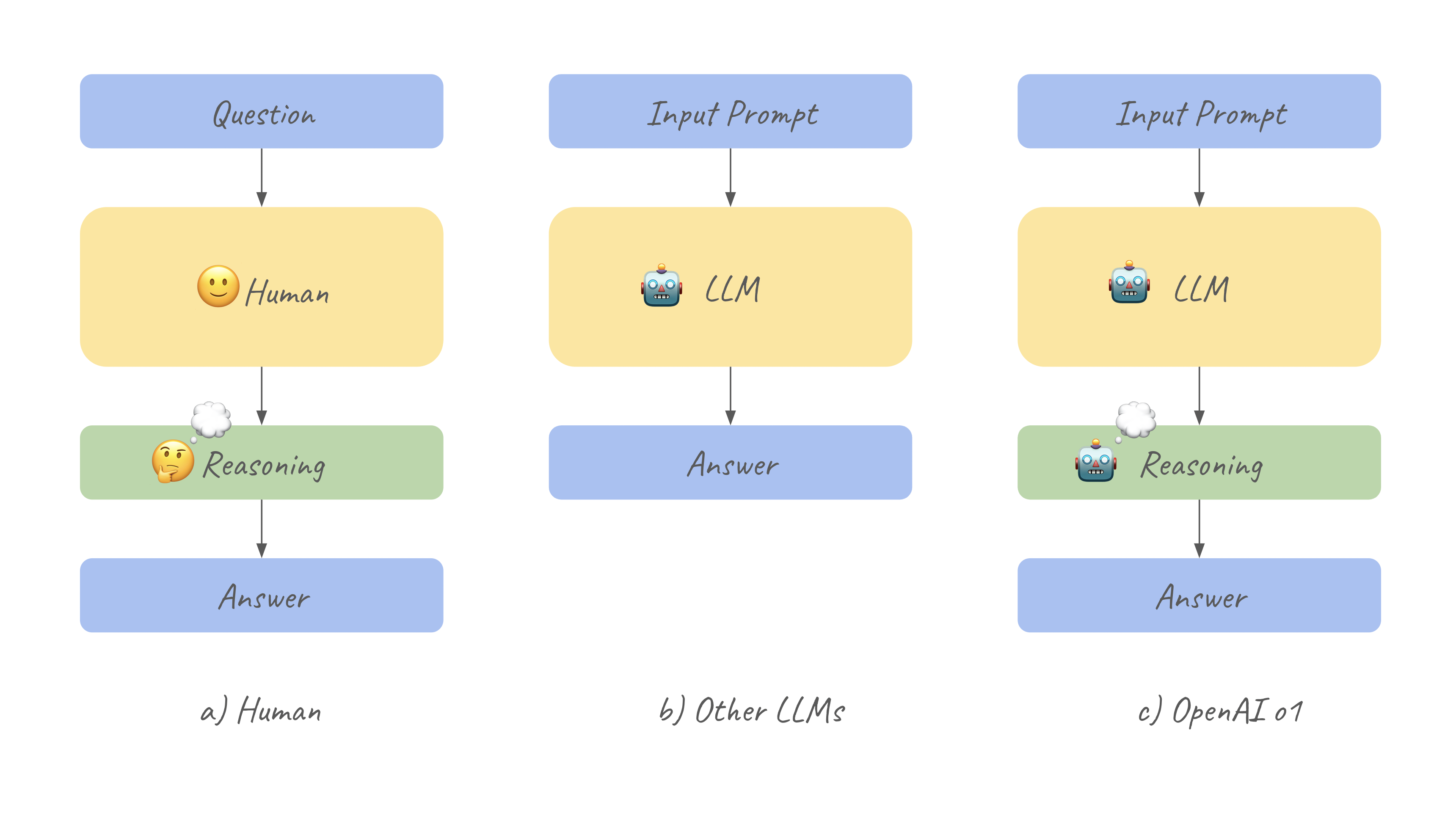
How is the o1 model able to solve this so well? 🧠
When presented with a question, most LLMs immediately begin predicting the answer, as shown below (b). In contrast, the OpenAI o1 model takes a different approach by introducing an additional phase known as the 'reasoning stage.' During this stage, the model generates a distinct set of tokens called 'reasoning tokens,’ separate from the answer-related output tokens. These reasoning tokens, along with the input prompt, are then used in the next stage i.e 'answering' to produce the final answer, as demonstrated below (c). This process mimics how humans first think through a problem before responding (a). These reasoning tokens play a crucial role in ‘Human reasoning simulation’ i.e simulating a ‘thinking’ process.
Now, let's take a closer look at the response from the OpenAI o1 model and delve into its 'reasoning tokens’. If you look at the area I highlighted in red, you'll see a dropdown arrow labeled ‘Thought for 11 seconds.’ Click on that arrow to expand the panel and view the reasoning tokens.
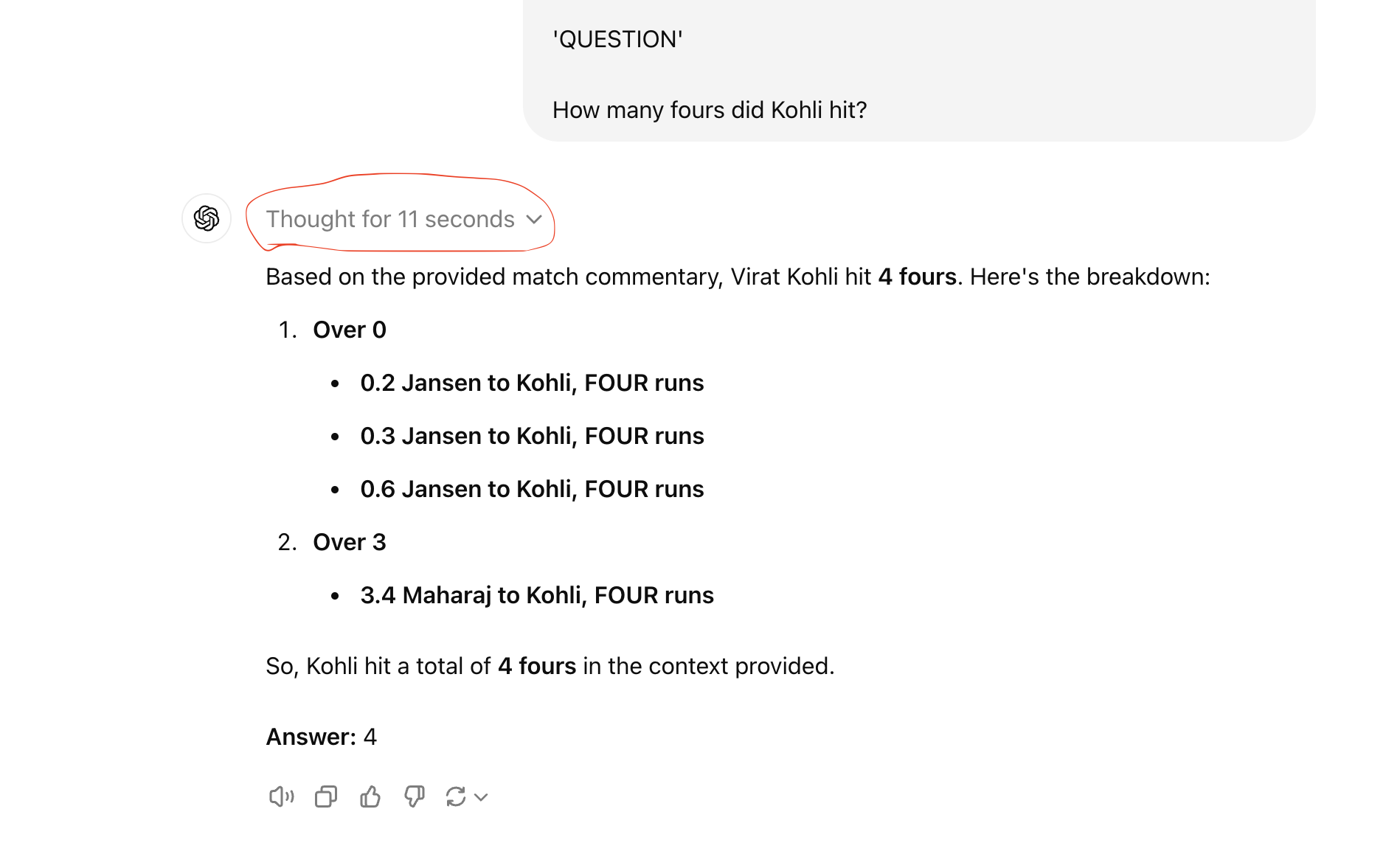
When you expand the arrow, the model’s 'reasoning tokens' appear between the original question and the final answer, as shown below.
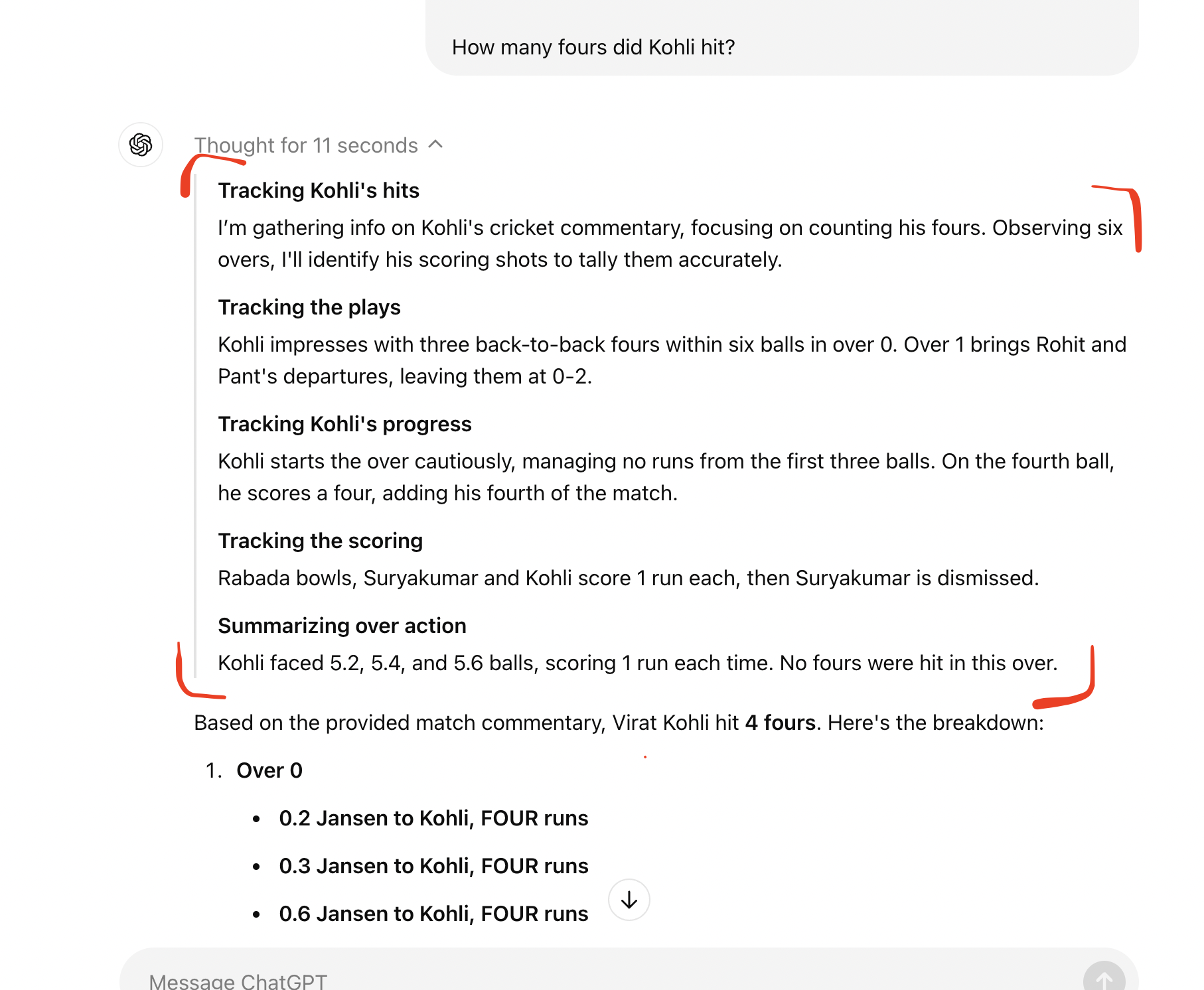
Upon examining the model's reasoning tokens, you will notice statements such as, ‘Observing six overs, I’ll identify his scoring shots to tally accurately’. This mirrors the guidance we provided to GPT-4o in reviewing each delivery and compiling the total number of fours. Additionally, each point in the ‘reasoning’ includes an over-by-over summary with detailed notes on Kohli's fours, closely resembling the manual analysis we applied to GPT-4o. Overall, the reasoning tokens generated by the OpenAI o1 model reflect similar content and structure to the manual reasoning we used to assist GPT-4o in solving the problem.
The reasoning tokens allow the model to break down the task into manageable subtasks, guiding it through a structured approach to reach the correct answer. This mechanism reflects the manual guidance given by us to the GPT-4o model above, where the task was divided into smaller steps to ensure accurate problem-solving. Essentially, the reasoning tokens automate this decomposition and guidance, enabling the o1 model to achieve human like reasoning and tackle complex questions more effectively and efficiently.
In general these reasonings tokens correspond to anything that assists the model in succeeding during the answering phase, for example they could be - breaking down the problem into smaller tasks and solving these subtasks(like above), considering various approaches and selecting one, or summarizing the problem, among other strategies. You can think of this as similar to how we humans create checklists to help us while tackling complex tasks. The process of training the model to generate useful and appropriate reasoning tokens is handled through Reinforcement Learning. During training, this method encourages the model to produce effective chain-of-thought tokens during the reasoning phase, improving its ability to solve complex tasks.
So the take away is that having a separate reasoning stage that creates ‘reasoning tokens’ which simplify the task is what o1 models allows the model to simulate a thinking process, enabling it to tackle complex questions more efficiently and accurately, similar to human reasoning.This is far more efficient than the earlier prompt engineering (Chain-of-thought prompting) approaches we saw earlier which are all based on human involvement to simplify the problem for AI.
Can GPT-4o solve this if the OpenAI o1 model ‘thinks’ on its behalf? ✅
Let’s try a curious experiment to see if OpenAI o1 model’s reasoning tokens can be useful in helping GPT-4o solve the question. Let us we add the reasoning tokens generated by OpenAI o1 model to the input prompt of GPT-4o as shown below:
Based on the 'CONTEXT' given below answer the 'QUESTION' below
the 'CONTEXT':
'CONTEXT':
<ESPN_DATA>
THINKING TOKENS
Tracking Kohli's hits
I’m gathering info on Kohli's cricket commentary,
focusing on counting his fours. Observing six overs,
I'll identify his scoring shots to tally them accurately.
Tracking the plays
Kohli impresses with three back-to-back fours
within six balls in over 0. Over 1 brings Rohit
and Pant's departures, leaving them at 0-2.
Tracking Kohli's progress
Kohli starts the over cautiously, managing no runs from
the first three balls. On the fourth ball, he scores a four,
adding his fourth of the match.
Tracking the scoring
Rabada bowls, Suryakumar and Kohli score 1 run each,
then Suryakumar is dismissed.
Summarizing over action
Kohli faced 5.2, 5.4, and 5.6 balls, scoring 1 run each time.
No fours were hit in this over.
'QUESTION'
How many fours did Kohli hit?
This is the answer from GPT-4o:

As you can see, GPT-4o is able to answer correctly when the prompt is enhanced with the reasoning tokens. This serves as further empirical evidence that reasoning tokens are effective in assisting large language models in answering complex questions!
Should you use OpenAI o1 model? 🤔
The OpenAI model is really good at complex reasoning tasks, if you really deal with such tasks then it might be a good idea to try it out. However you need to consider the following:
OpenAI o1 is 6x more expensive than GPT-4o - So it might be too expensive to use in production systems at scale
It is much slower than GPT-4o due to the additional ‘reasoning’ stage - So it might be too slow to run in production systems at scale
This is the first model with such human like thinking capabilities but definitely will not be the last. Based on history the future iterations of this model might be much cheaper and faster
Overall while OpenAI o1 model is far superior in a small subset of tasks that require human like reasoning and might be the only LLM that can get such tasks done, on all other the tasks GPT-4o and other LLMs are pretty much on par with OpenAI o1 and they would be better choice at the moment as they are much cheaper and faster.
Conclusion 🤝
The OpenAI o1 model is a significant advancement in language models, particularly in reasoning through complex tasks.
It incorporates a distinct ‘reasoning stage’ that generates AI reasoning tokens, simulating a structured thinking process.
This allows the model to break down complex problems into manageable subtasks, mirroring human problem-solving strategies.
The model's ability to automate this reasoning process sets it apart from previous models that relied heavily on prompt engineering.
The o1 model's approach enhances its problem-solving capabilities and provides a framework to assist other models, like GPT-4o, in achieving similar results when guided appropriately.
This innovation marks a promising step forward in developing more advanced AI models intelligent and complex problem-solving AI
What are your thoughts on AI’s ability to reason? Do you think models like o1 could change the future of complex problem-solving? Let me know in the comments below!
References 📝
Subscribe to my newsletter
Read articles from Sai Chowdary Gullapally directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by