Week 19: Azure Sales Data Pipeline Automation Project 🔄
 Mehul Kansal
Mehul Kansal
Hey data enthusiasts! 👋
The Azure Sales Data Pipeline Automation project focuses on building an end-to-end automated data pipeline for processing sales order files dropped into a storage account by third parties. The goal is to validate these files, ensure data consistency by checking for duplicates and valid order statuses, and subsequently process and report the data.
Project Requirements
Consider a scenario where a third-party drops a file named ‘orders.csv‘ in the landing folder in our storage account. As soon as the file arrives, we need to perform the following checks:
Check for duplicate order IDs
Check for valid orders status’
If both the conditions are met, we need to move the file to the staging folder else we need to move it to the discarded folder.
Further, the data for ‘order items’ and ‘customers’ gets loaded by third-parties into the storage and we need to find out:
Number of orders placed by each customer
Total amount spent by each customer
Building the Data Pipeline
Creating the required resources
- Storage account
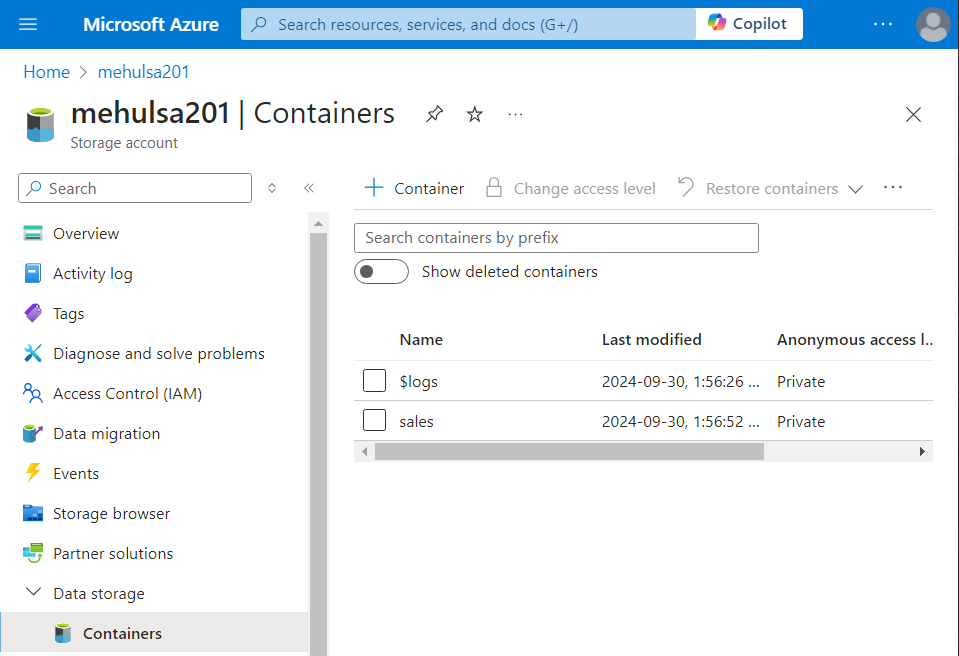
- We create an ADLS Gen2 storage account in our Azure account and create a container named ‘sales‘ inside it.
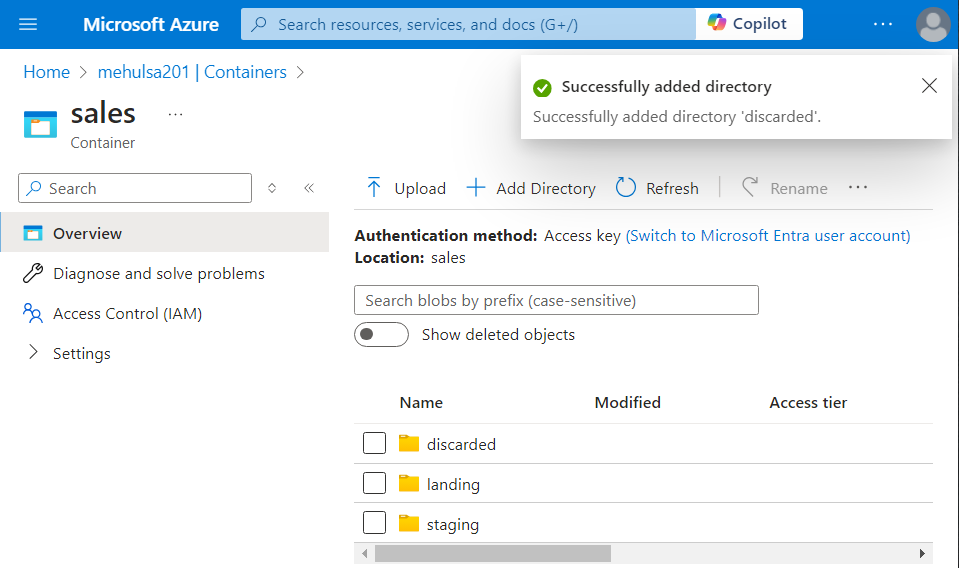
- Inside the ‘sales‘ container, we create three directories: landing, staging and discarded.
- Databricks
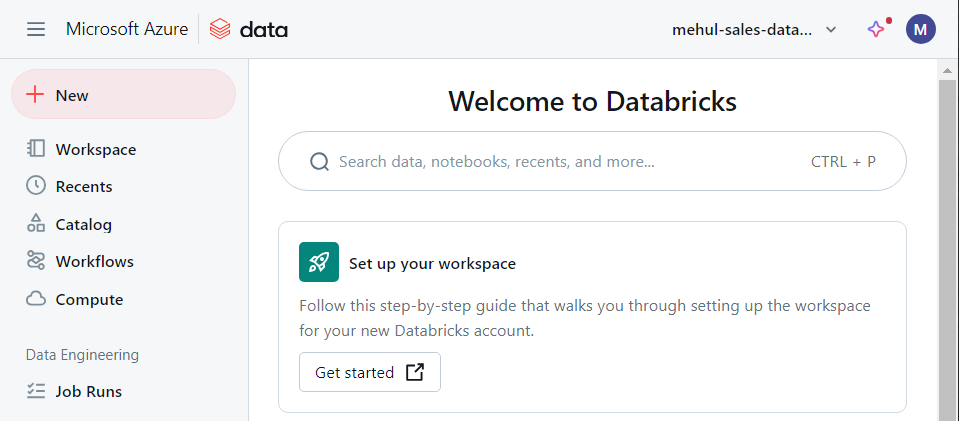
- We create a databricks workspace to perform transformations.
- Data factory
- We create a Data factory service, which need to be connected to ADLS Gen2 storage and Databricks compute.
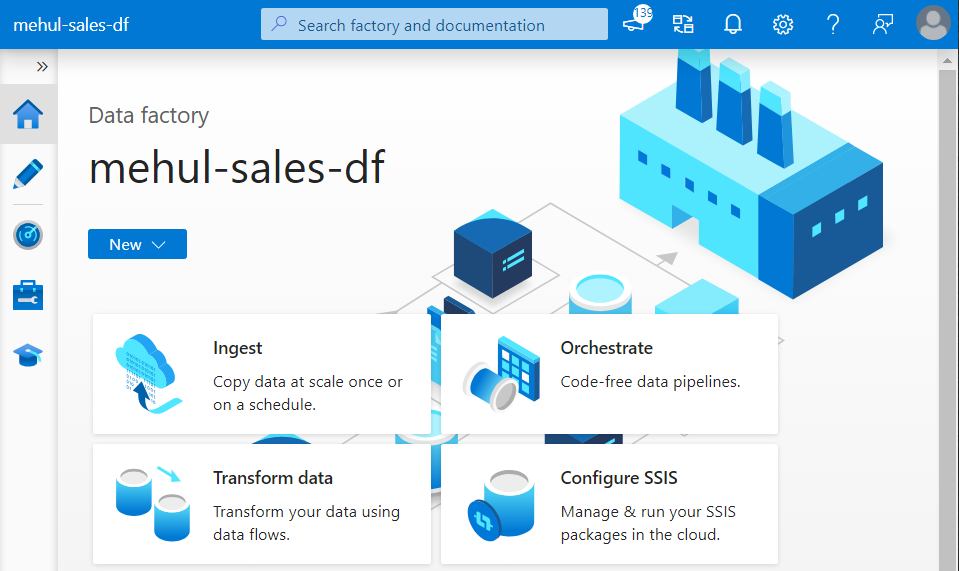
- In order to connect the ADF to the storage account, we create a linked service to our ADLS Gen2.
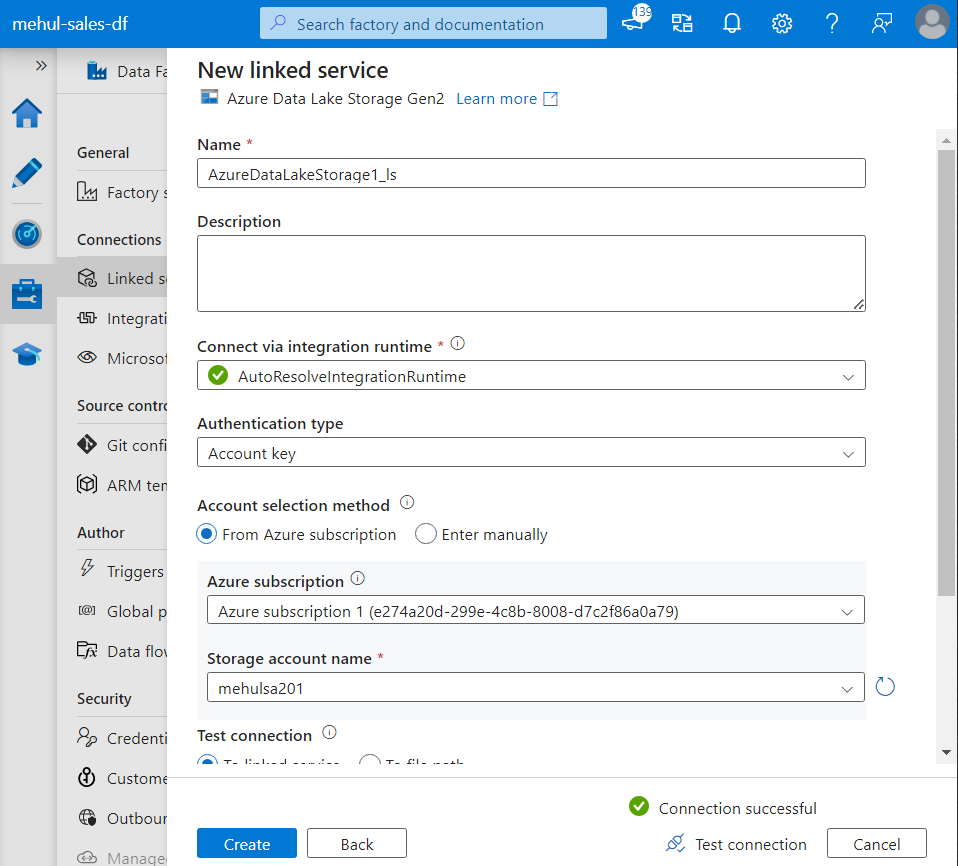
- For connecting with the Databricks workspace, we first need to create a Databricks access token.
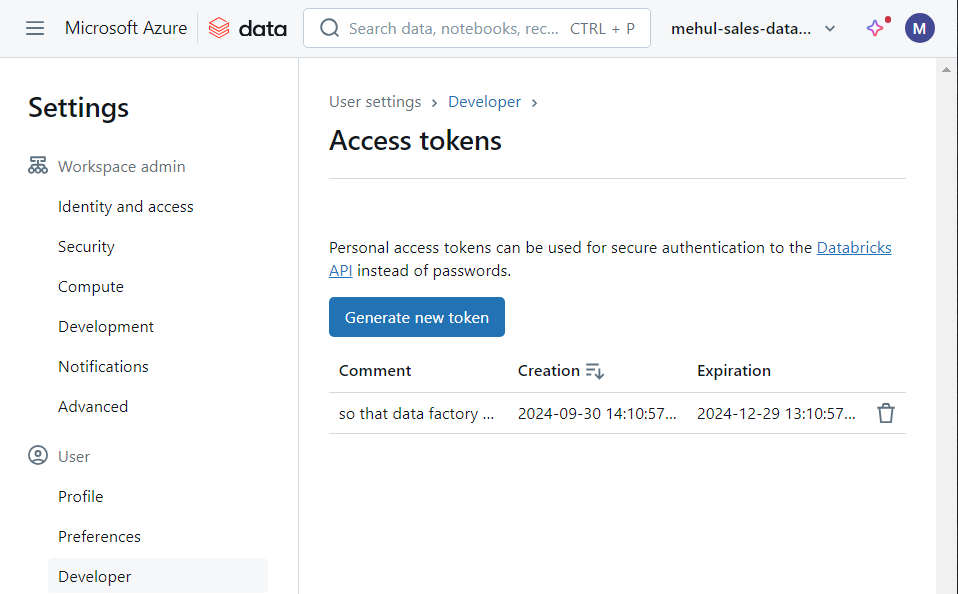
- As a security consideration, we store this access token inside Azure Key Vault.
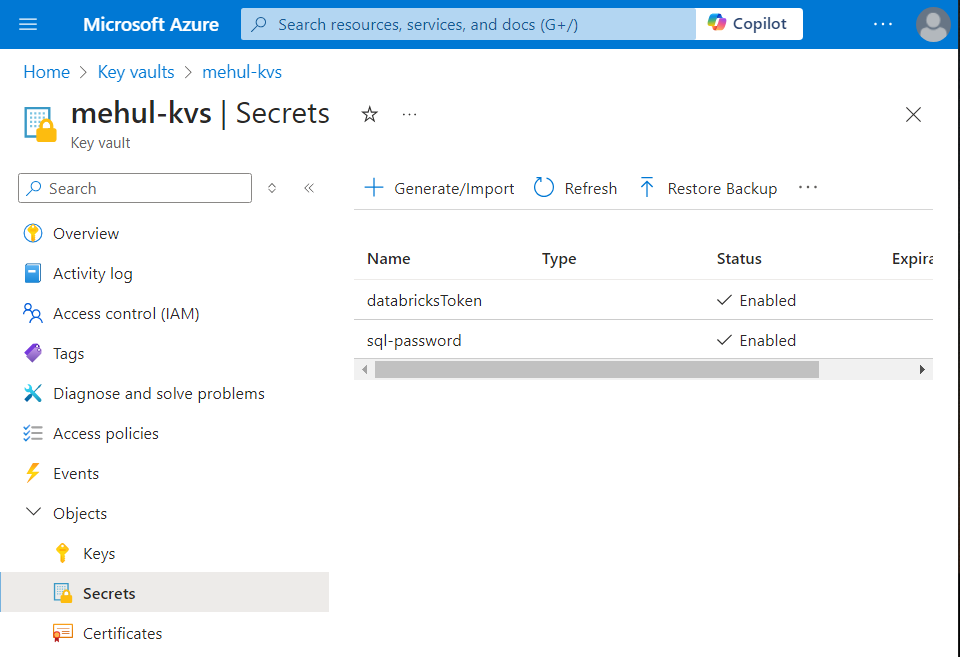
- Now, providing the Azure Key Vault’s secret value, we create a linked service for Databricks.
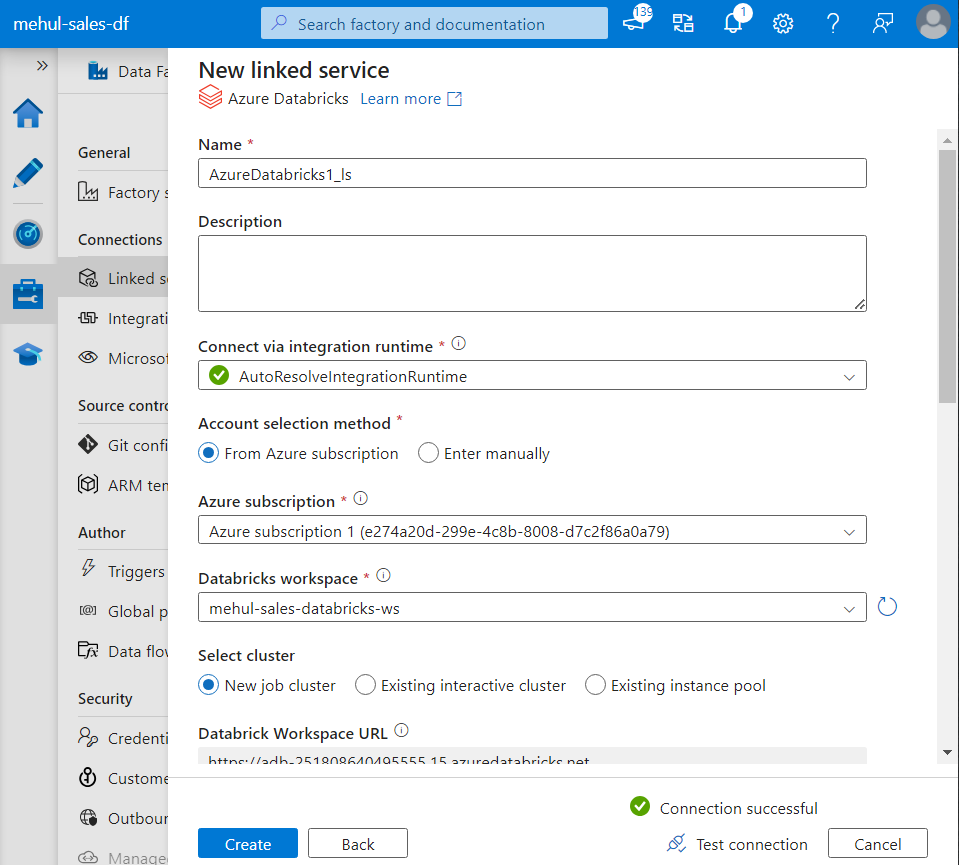
Creating Lookup table for valid order status
- In order to maintain a list of valid order status’, we create a table inside Azure SQL Database and populate it with the required order status’.
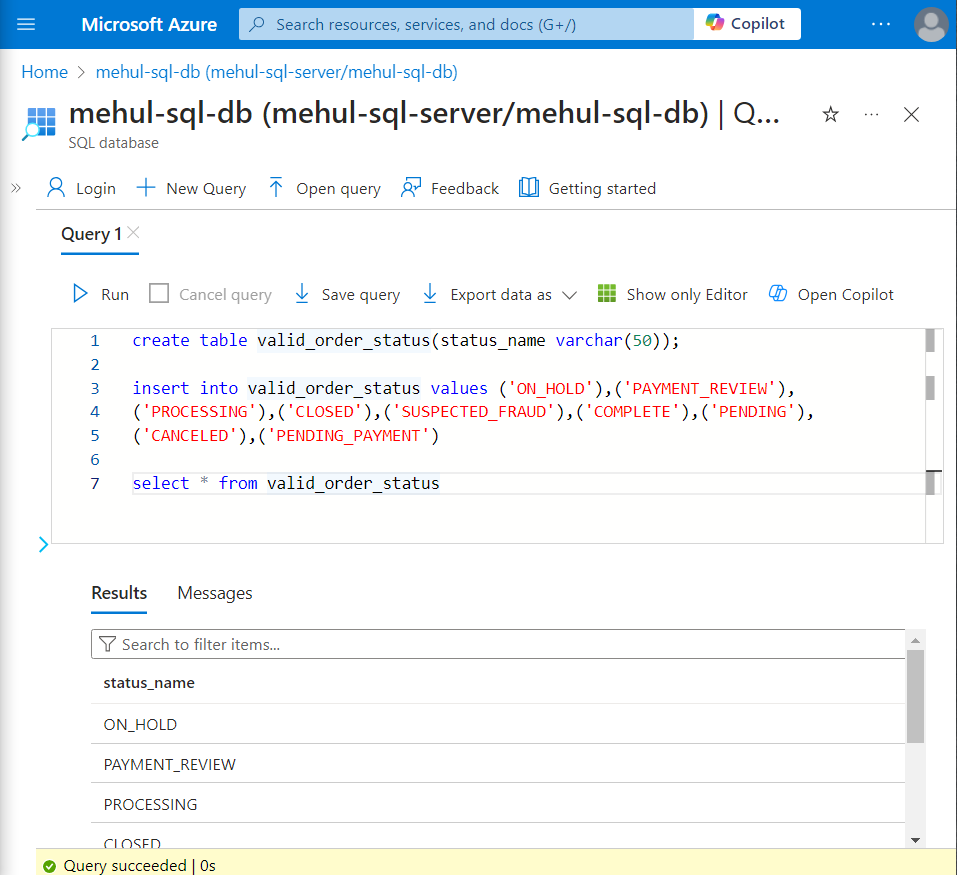
Developing logic using Databricks
We create an interactive cluster inside Databricks that will execute the notebook for transforming the data.
Firstly, we create a mount point to get access to the storage account. This requires an access key from our ADLS Gen2 account, which gets provided inside ‘extra_configs‘ parameter.
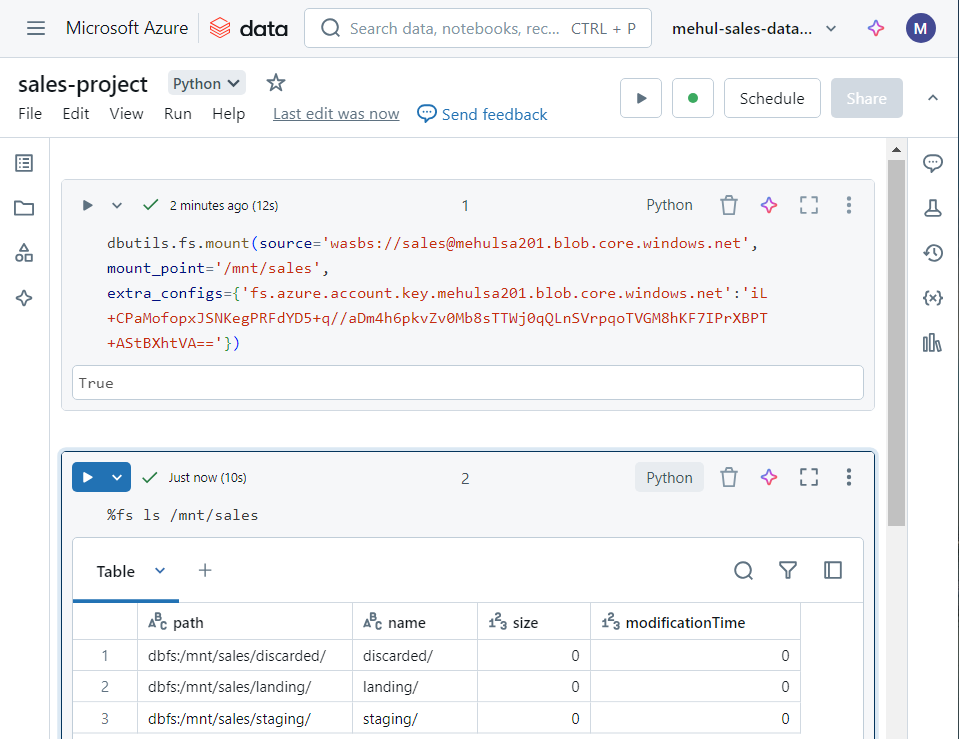
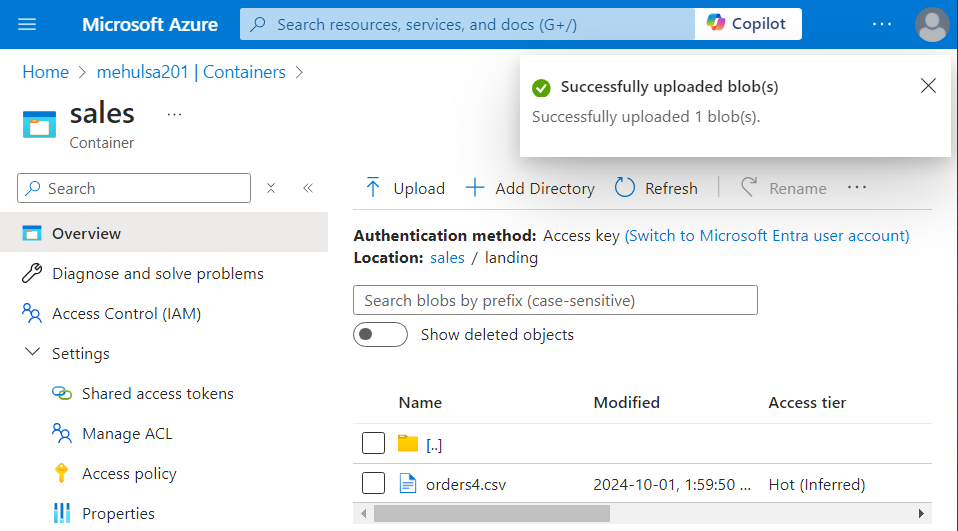
- We upload a sample file inside ‘landing‘ folder, upon which we will perform transformations.
- We load the file into a dataframe, named ‘ordersDf‘.
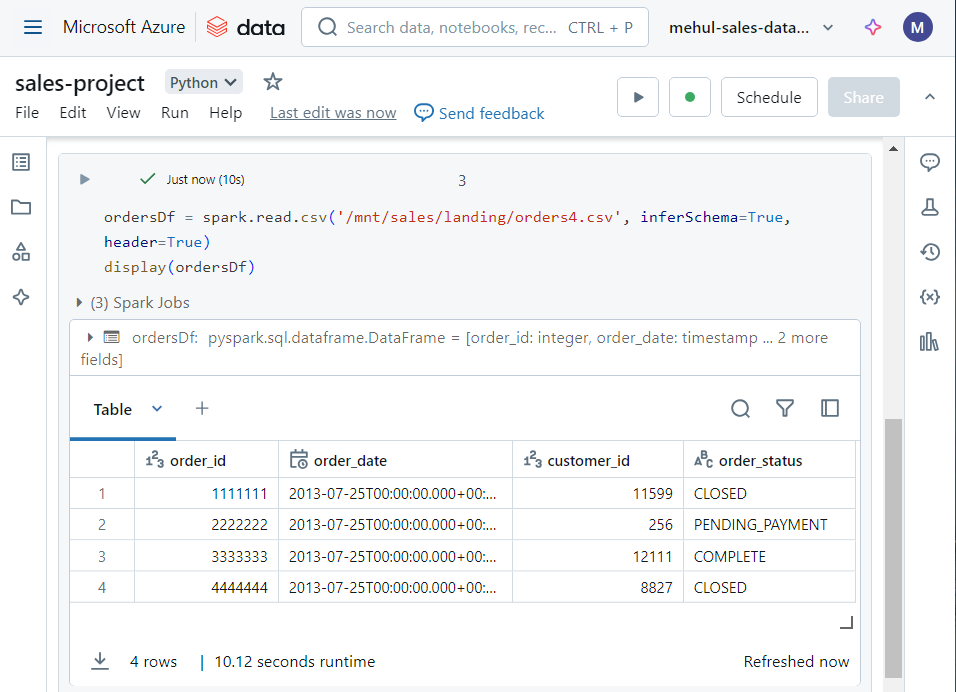
- Now, for checking the duplicate order status’, we write the following code. Note that if duplicates exist, we move the file into ‘discarded‘ folder and if duplicates don’t exist, we create a Spark table ‘orders‘ out of the dataframe.
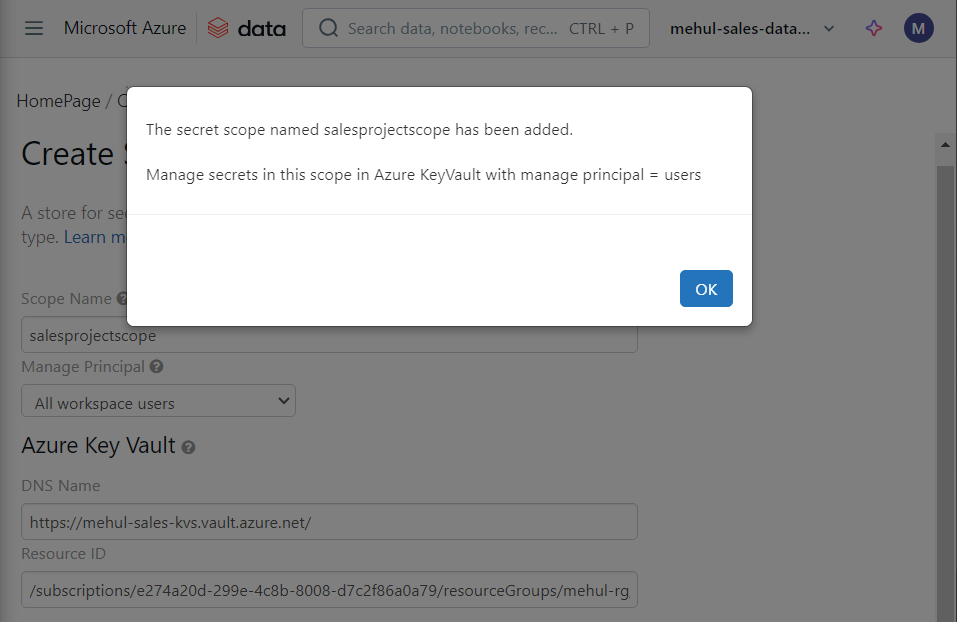
- For further processing, we need to connect to Azure SQL Database. In order to achieve this, we store the credentials for our database inside Azure Key Vault and we create a secret scope ‘salesprojectscope‘ inside Databricks for connecting to the key vault.
- After creating the scope, we write the following code to connect to the database inside Azure SQL Database.
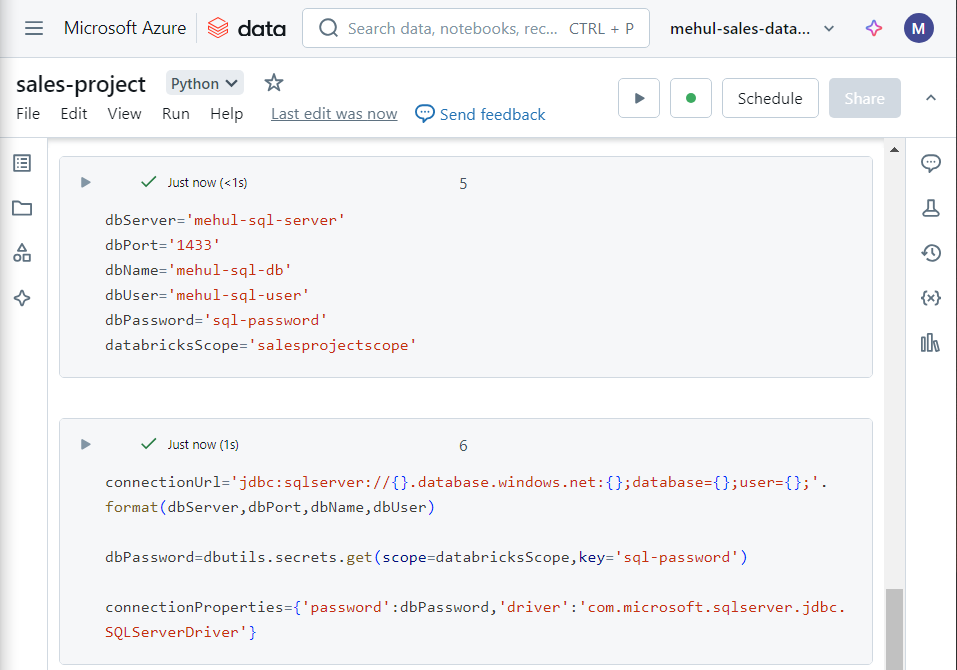
- We can verify the successful connection to the database by reading the ‘valid_order_status‘ table inside Azure SQL into a dataframe.
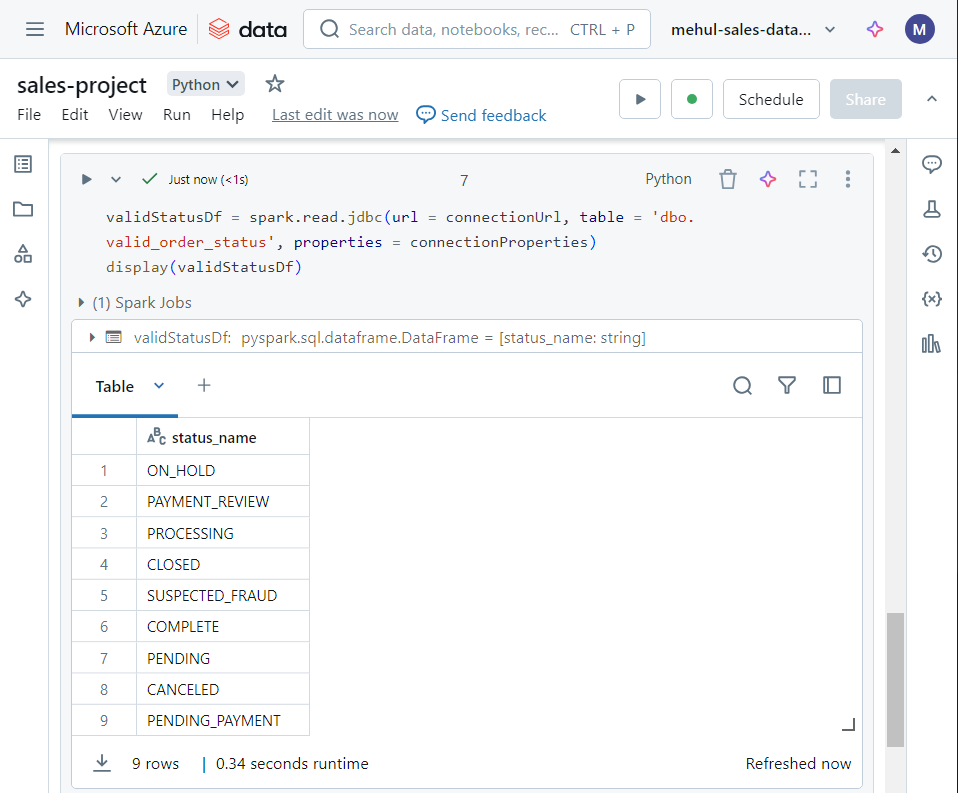
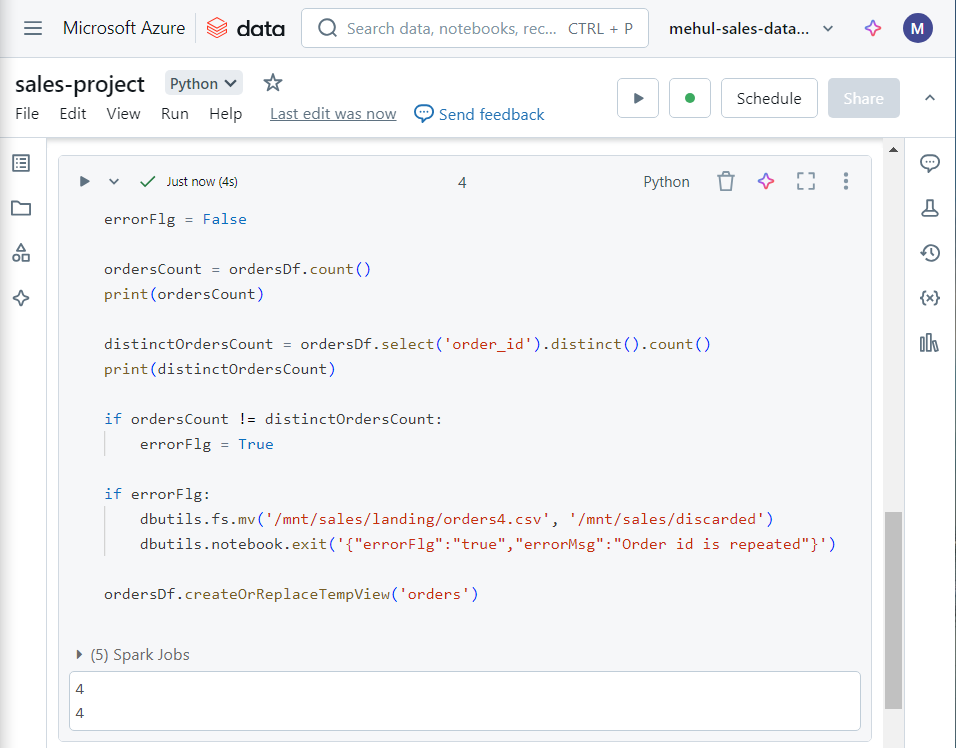
- Now, in order to check for valid order status’, we create a Spark table out of our dataframe and perform the following SQL statement for validating the condition.
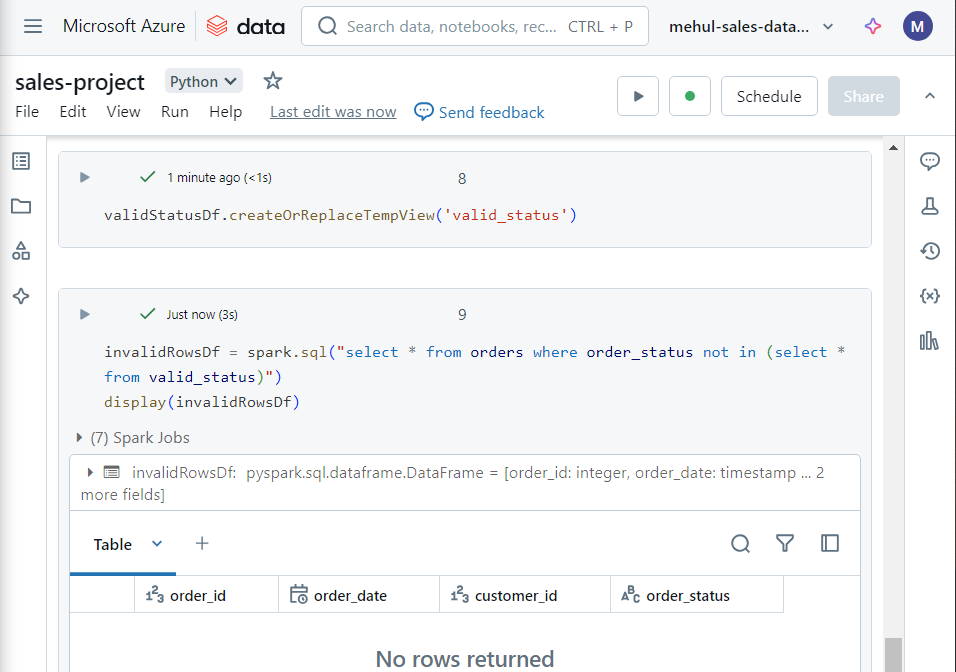
- In the above dataframe’s results, if any invalid order status exists, we move the file into ‘discarded‘ folder, otherwise we move it into the ‘staging‘ folder.
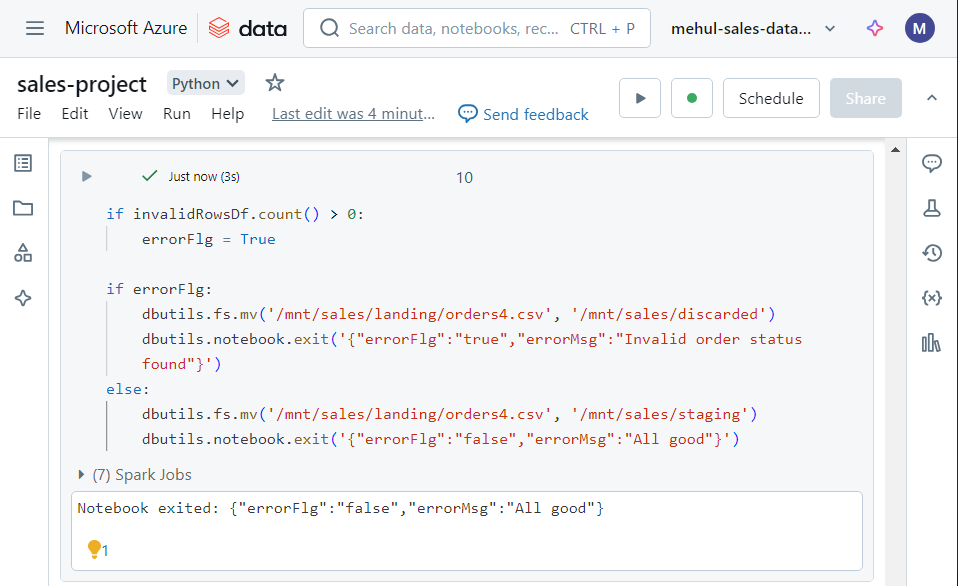
- Upon executing the above commands, the file gets moved into the ‘staging’ folder indeed, since there were neither any duplicates nor any invalid order status’ inside the file.
Automating the pipeline in Azure Data Factory
- We add a Databricks notebook activity in our pipeline and connect it with our notebook we created earlier, with the help of a linked service.
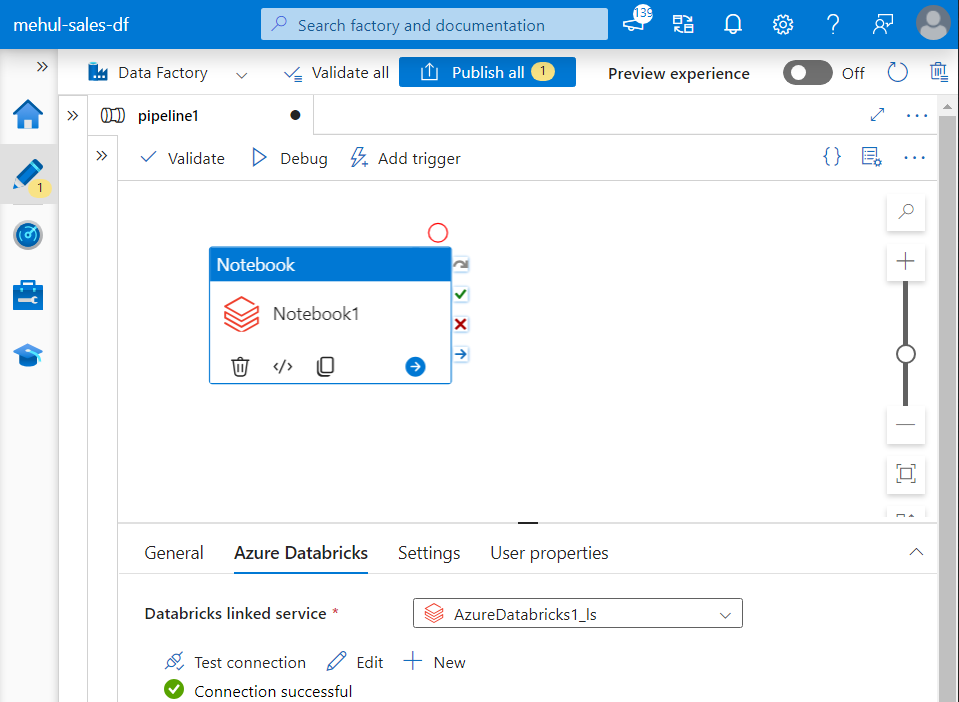
- Then, we create a Storage Event Trigger so that whenever a file arrives inside ‘landing‘ folder in the storage account, the pipeline gets executed automatically.
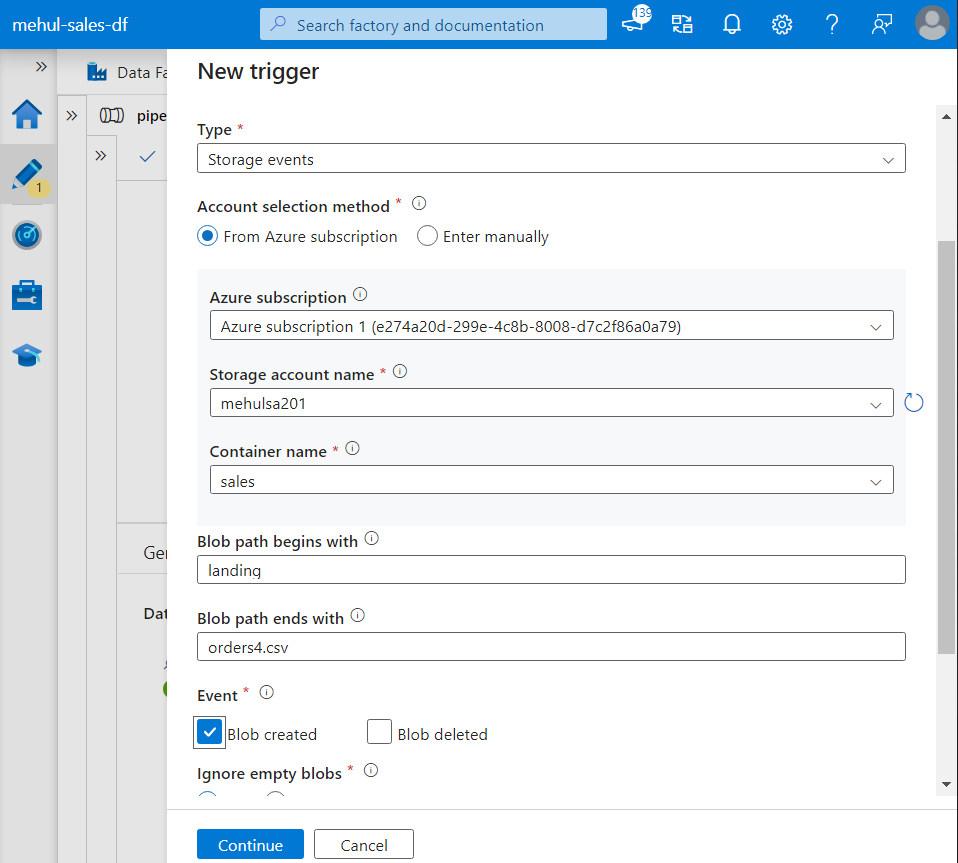
- For testing purposes, we upload a file inside the ‘landing‘ folder.
- As expected, the pipeline gets triggered automatically and the notebook activity starts running.
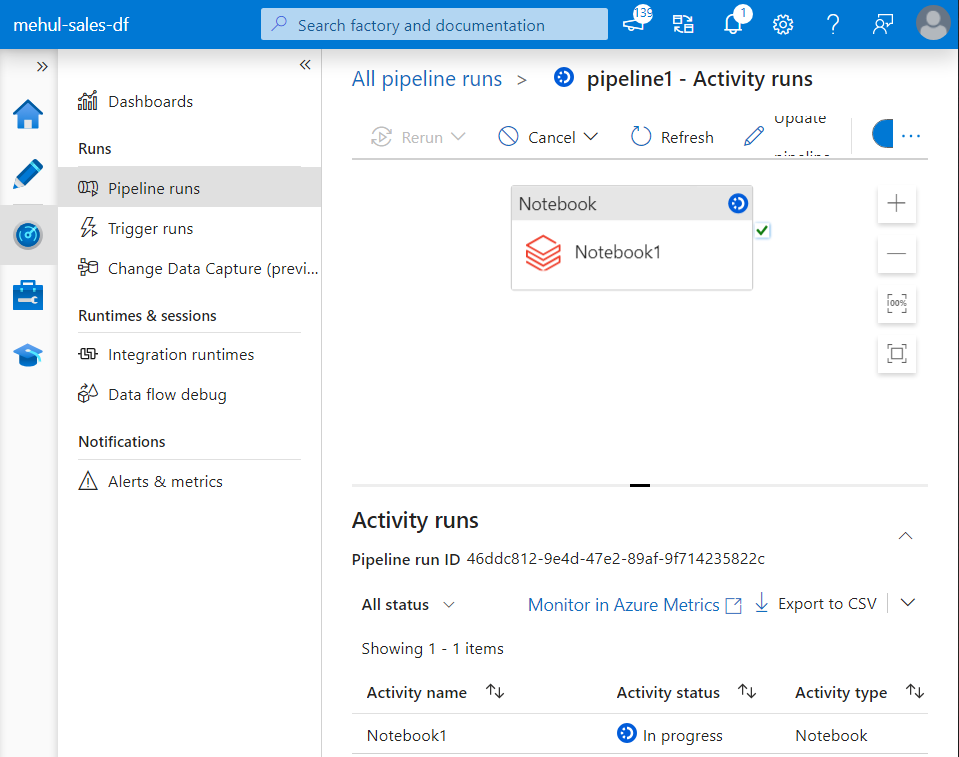
- Inside the notebook run, we can verify that all the commands get executed successfully and the notebook exits after confirming that there was no error in the file.
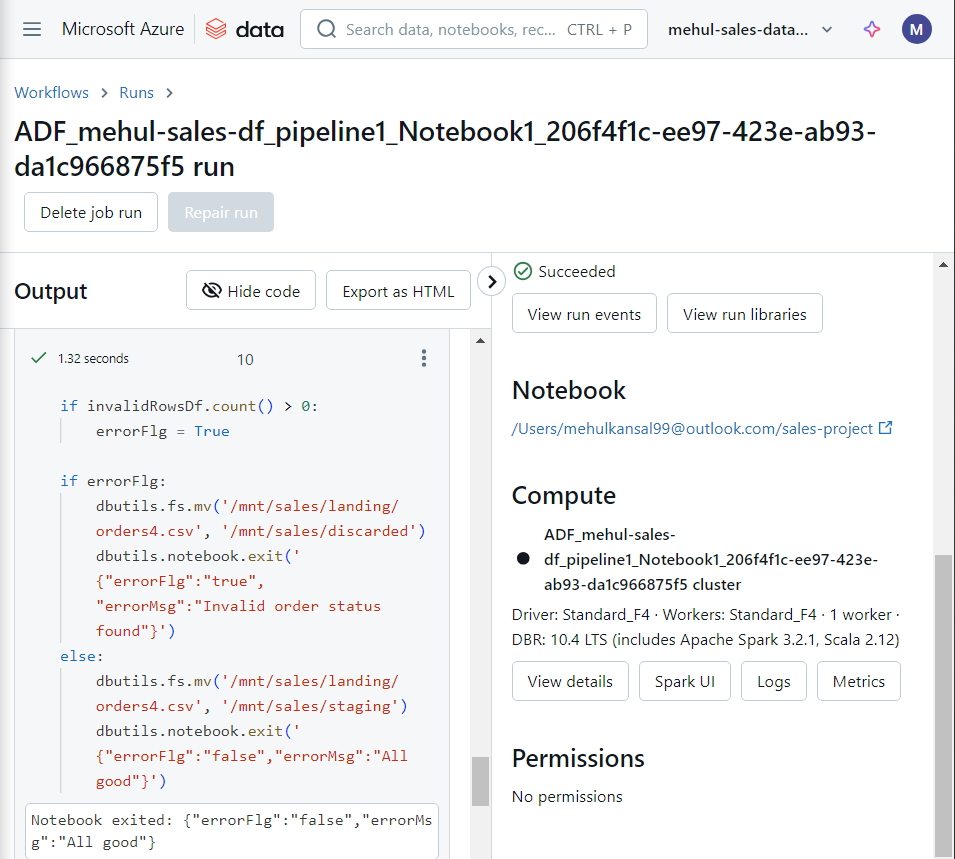
- Since there was no error in the file i.e. both the required conditions were met, the file gets moved into the ‘staging‘ folder.
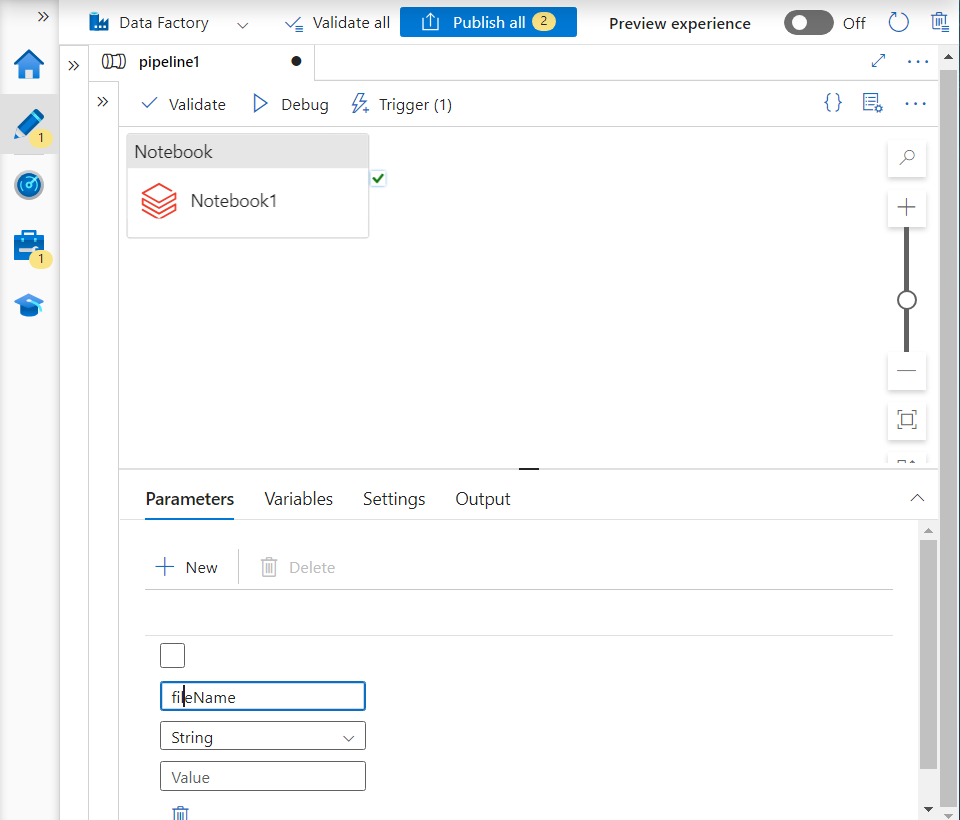
Parameterization for reading the files dynamically
- We create a parameter named ‘fileName‘ inside Data factory.
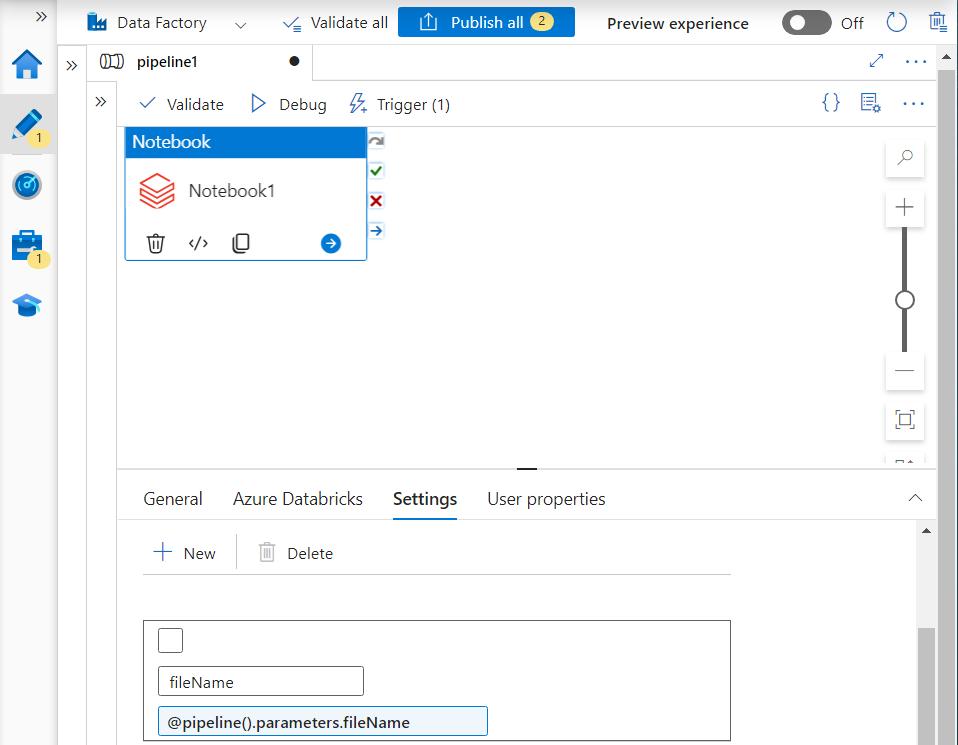
- We create a Databricks activity’s parameter with the same name as ‘fileName‘ and its value gets provided by the Data factory’s parameter.
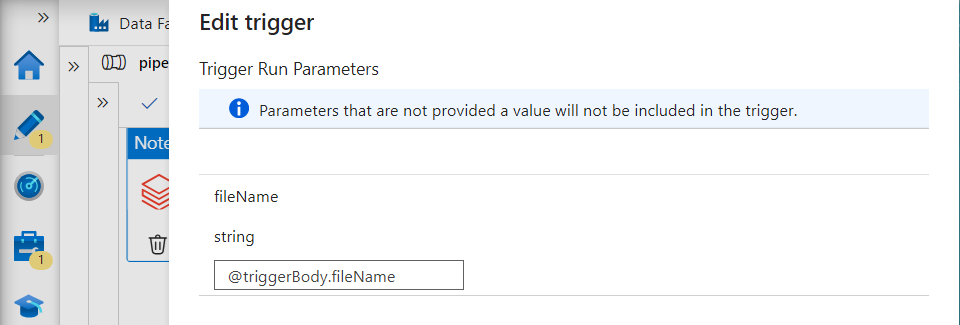
- In trigger, we add the parameter as follows. Note that this parameter will be provided to the Data factory and the Data factory will provide it to the Databricks notebook activity.
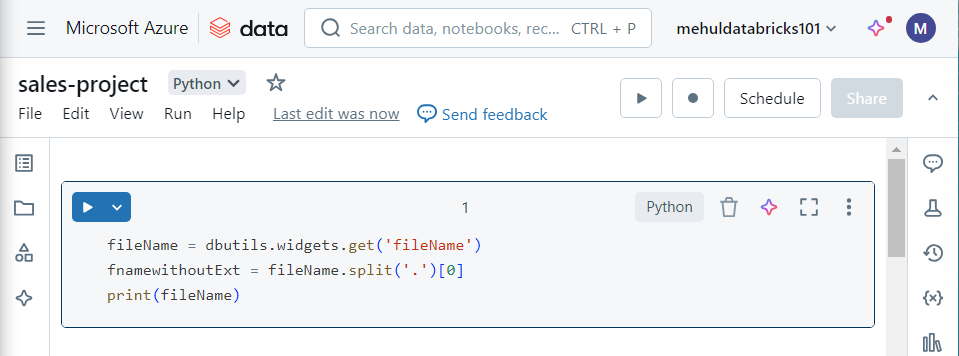
- In the Databricks notebook, we can access this parameter using the ‘dbutils.widgets‘ property as follows.
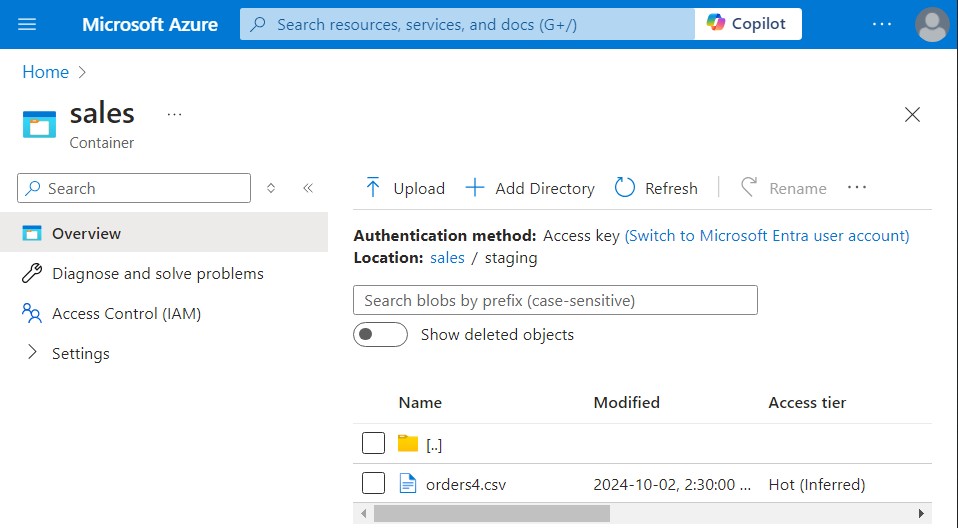
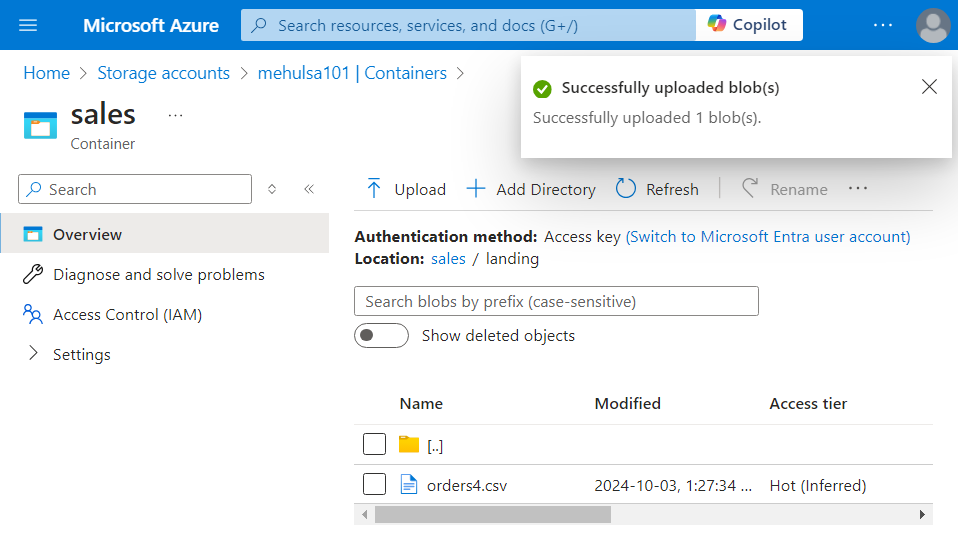
- For testing, we upload a file named ‘orders4.csv‘ inside the storage.
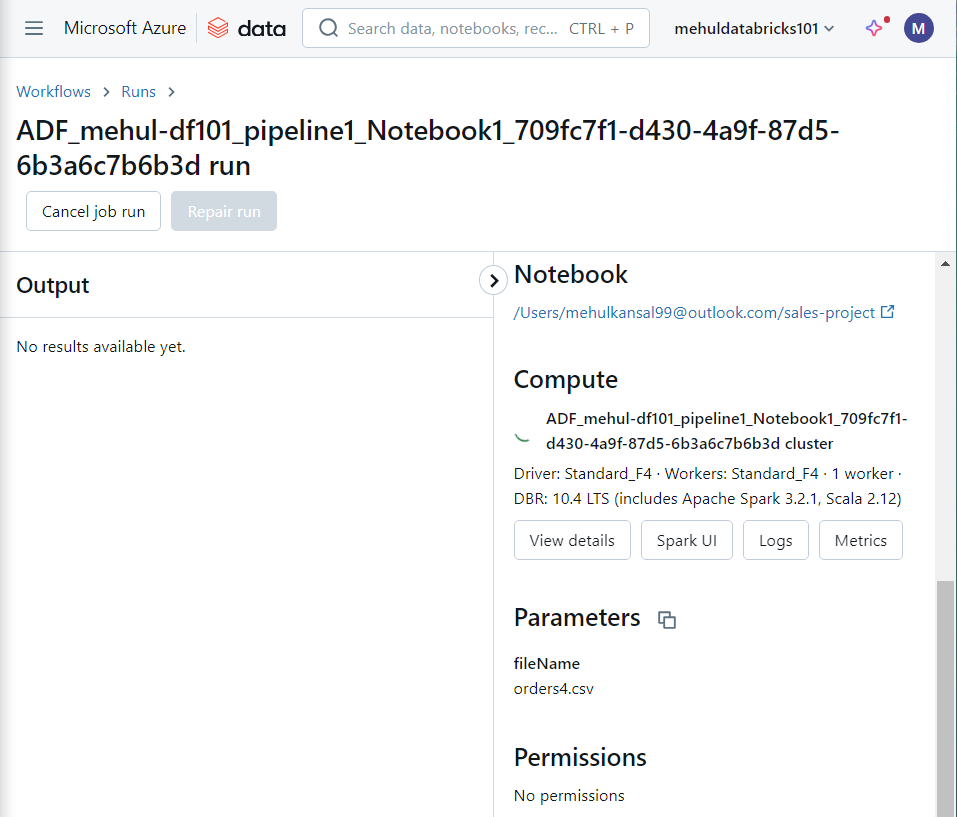
- While executing the notebook, the parameter ‘fileName‘ takes the value as ‘orders4.csv‘, dynamically.
- For making the notebook generic, we make the necessary modifications by replacing the hard-coded filename with its dynamic alternative.
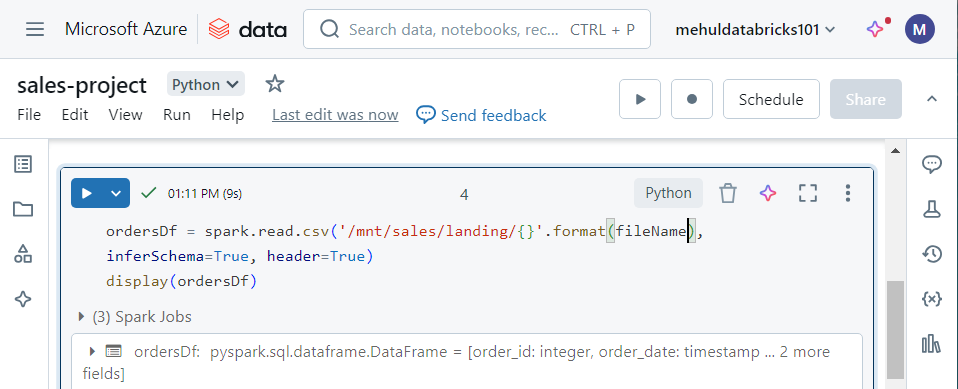
Generic mount code
Earlier, the code for mounting the storage account container into the notebook was hard-coded.
In order to make it generic, before mounting, we check if a mount point already exists or not.
Note that we also access the storage account key through the Key Vault now.
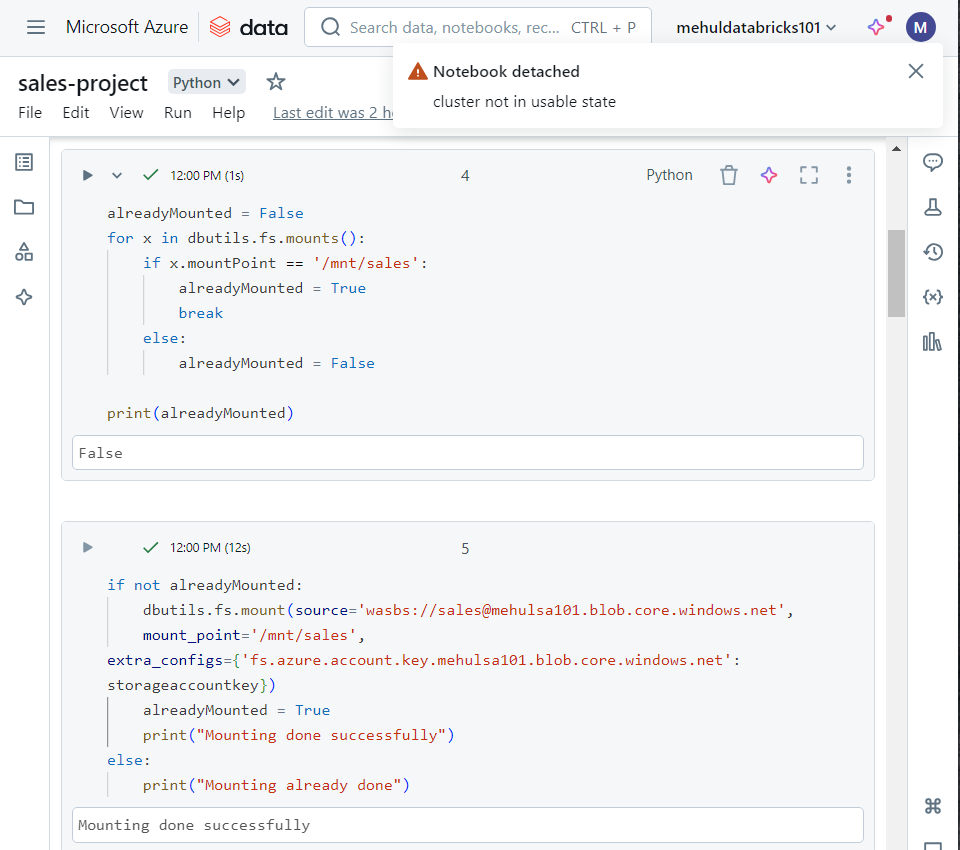
Background activities
Ingesting data from Amazon S3 to ADLS Gen2
- Consider that a third-party is adding ‘order_items.json‘ file into Amazon S3, under a folder named ‘order-items‘. We need this data inside ADLS Gen2 for further processing.
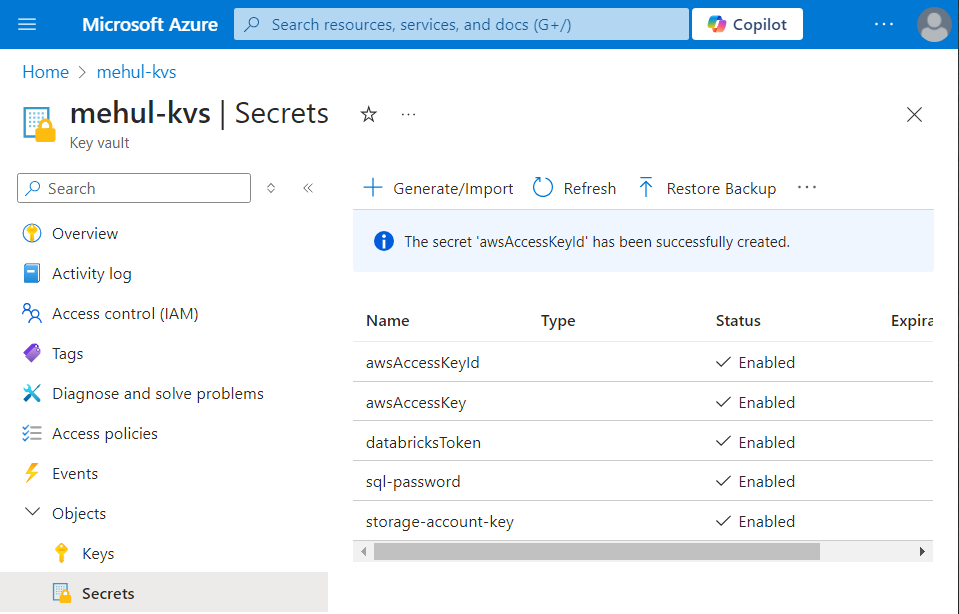
- We generate a secret access key inside AWS and store its value inside Azure Key Vault.
- With the help of these credentials, we create a linked service to Amazon S3 bucket.
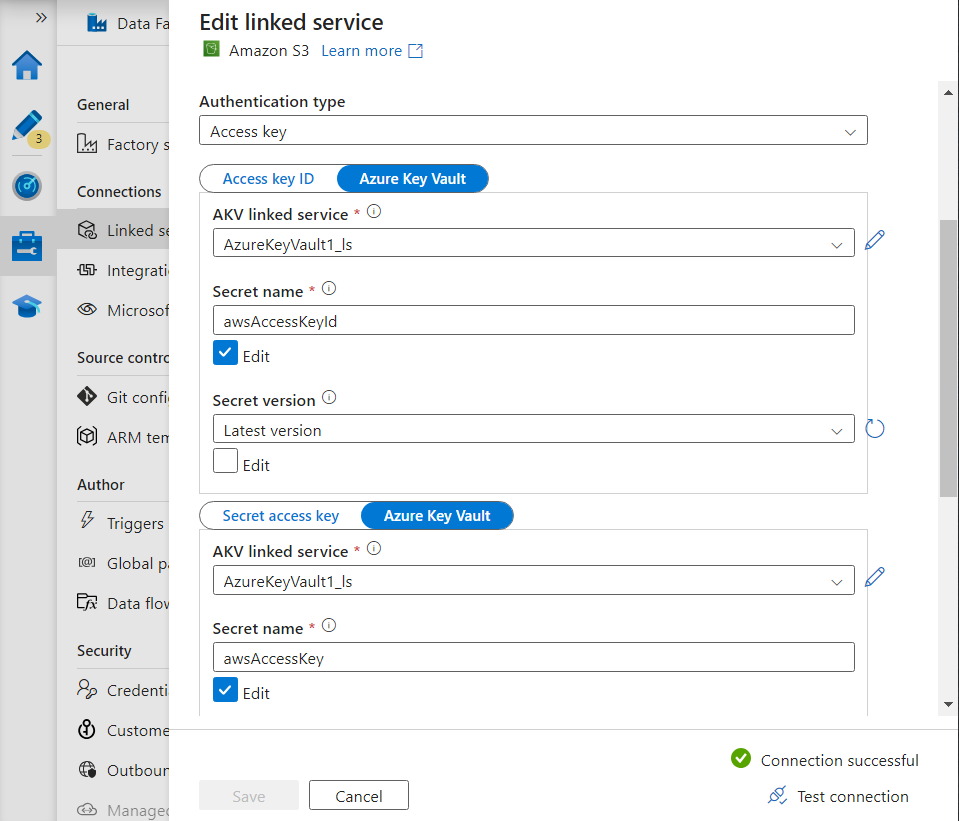
Inside our pipeline, we add a copy activity and provide its source as the Amazon S3 bucket in JSON format and the sink as ADLS Gen2 dataset.
After the successful copying of data, the notebook activity will get executed.
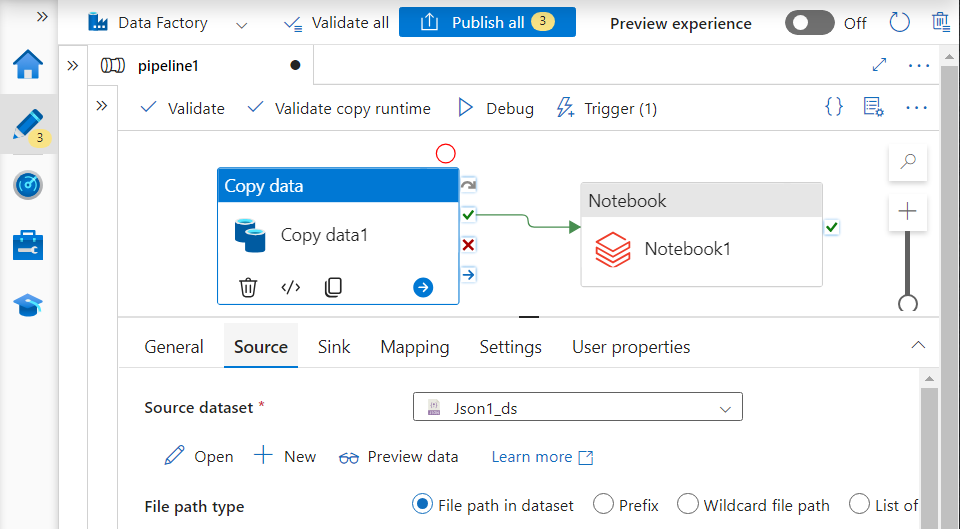
Ingesting data from Azure SQL DB to ADLS Gen2
Consider that a third-party publishes ‘customers‘ data inside Azure SQL Database, with the help of another pipeline, and we need to mimic this case.
In order to populate the table in Azure SQL DB, we create a linked service to our database.
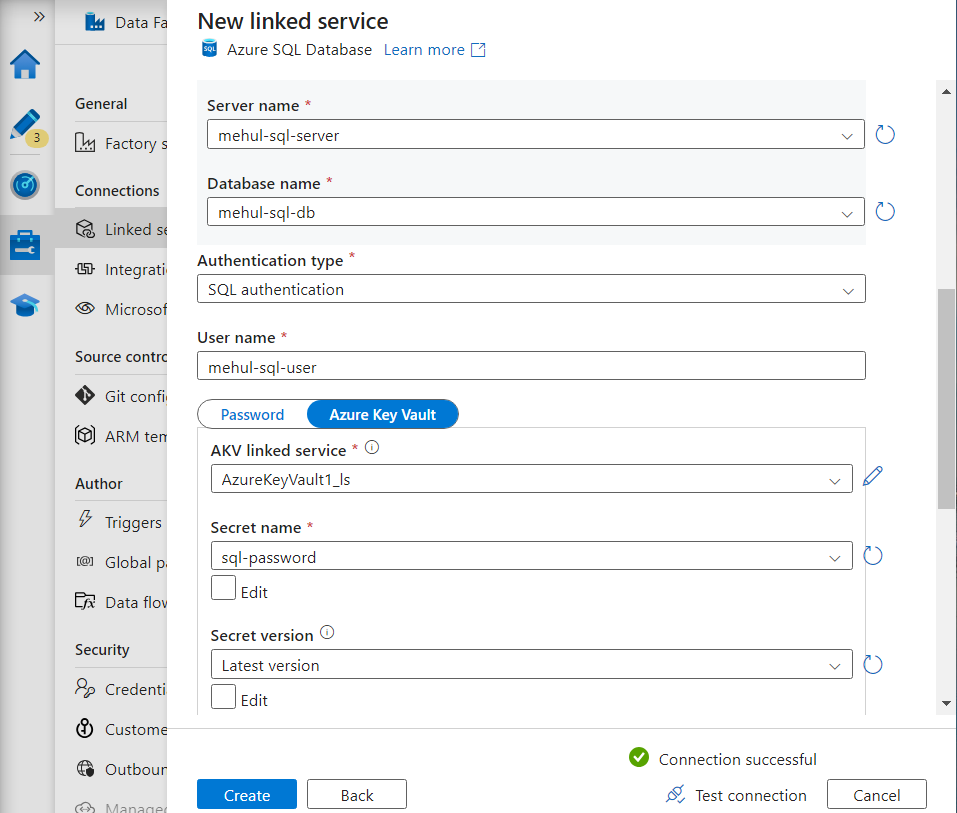
- Suppose that the third-party loads the data from a CSV file ‘customers4.csv‘ in storage account into the Azure SQL database.
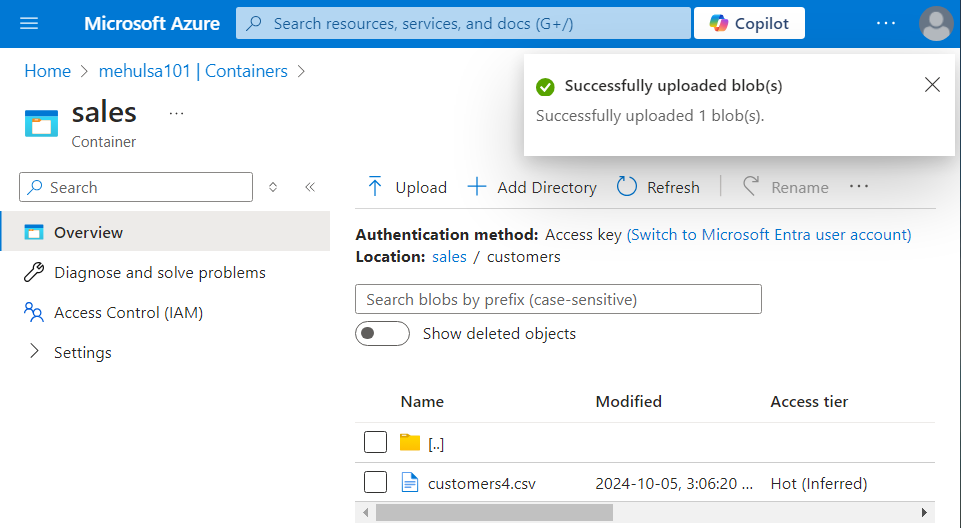
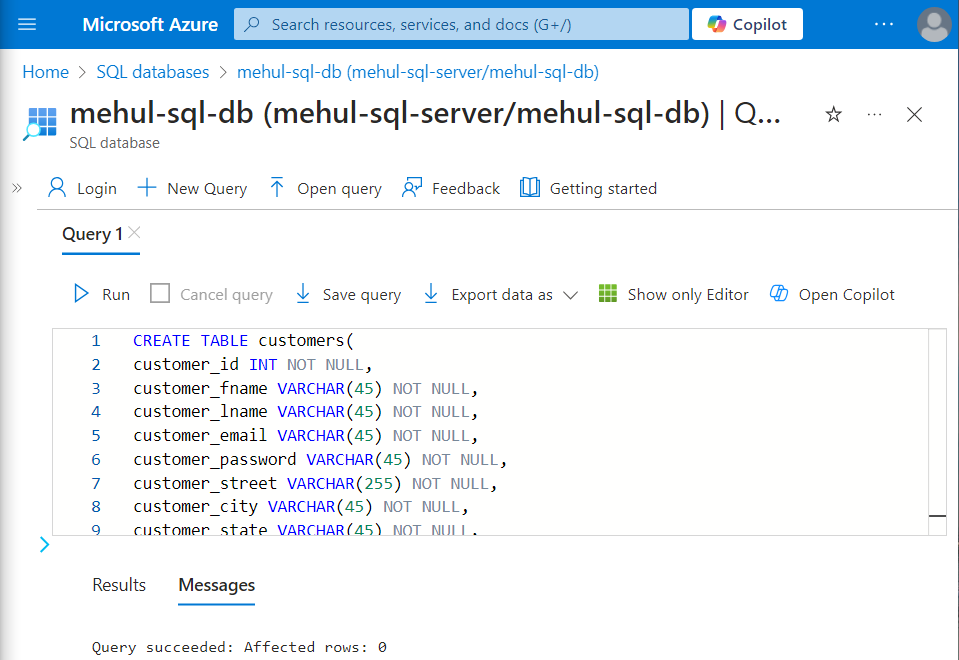
- The third-party loads the data into the ‘customers’ table, the structure of which looks as follows.
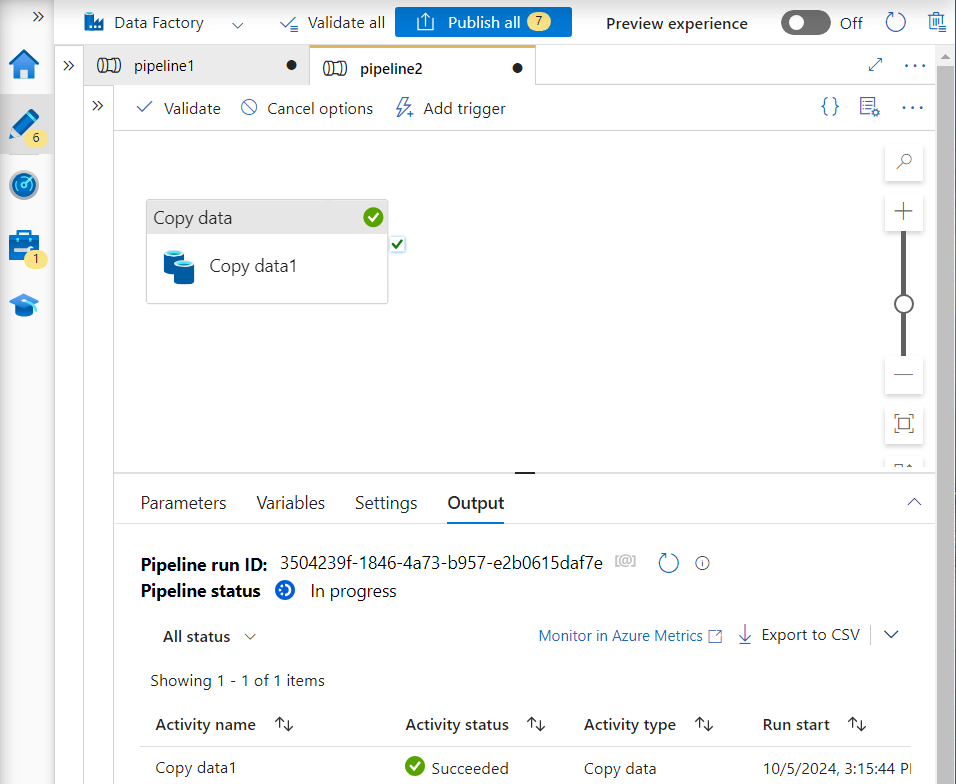
- Using the copy activity in their pipeline, they load the data.
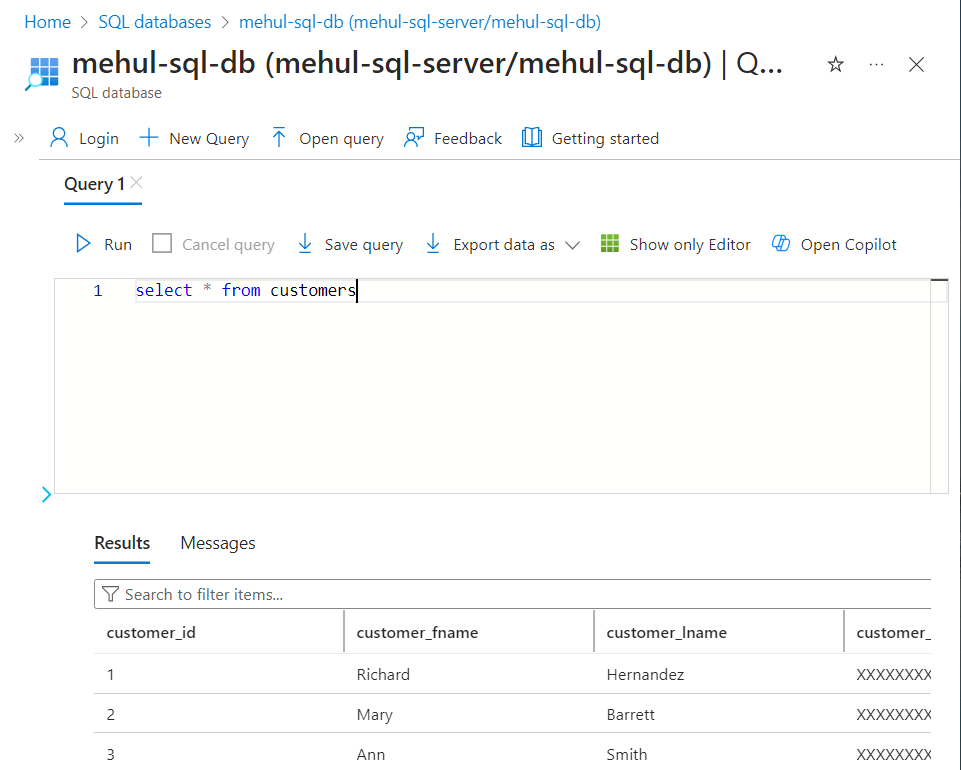
- After the third-party’s pipeline runs, the SQL table gets populated.
Joining tables
Until now, we already have the ‘orders‘ data with us, in the form of a Spark table.
Now, in order to get the data for ‘order items’ and ‘customers’, we first create datasets out of these and then create Spark tables out of them.
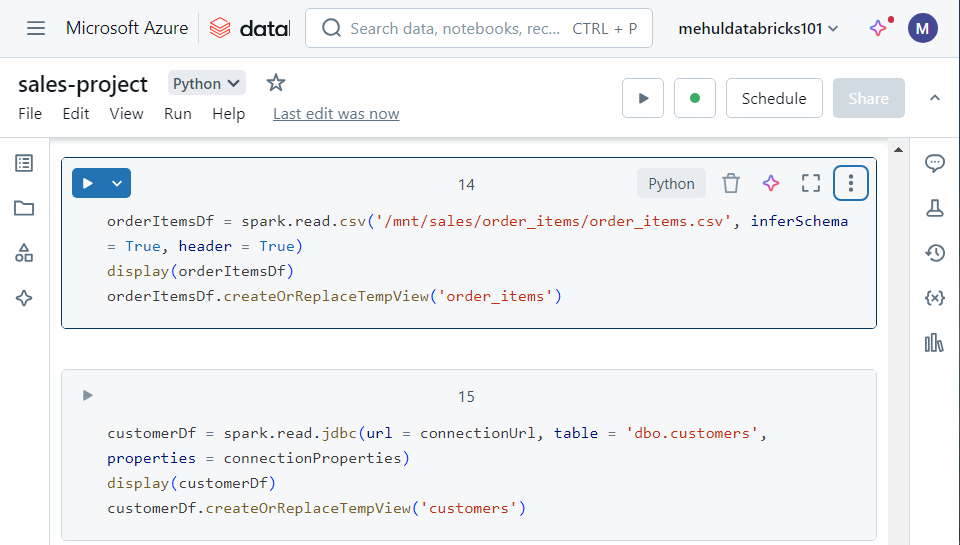
- In order to achieve the number of orders placed by each customer and the total amount spent by each customer, we execute the following SQL join query on the three Spark tables we have.
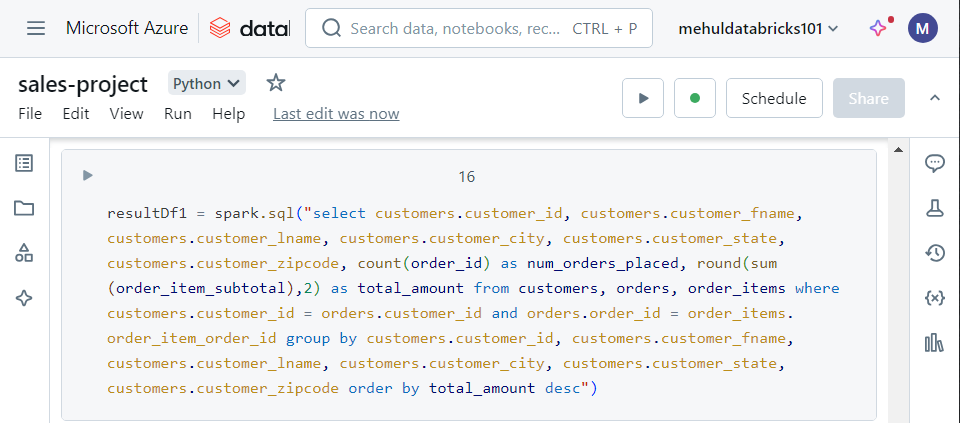
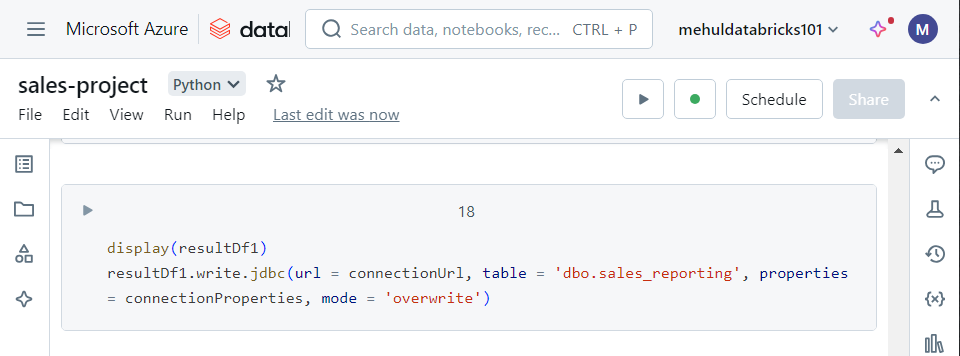
- As a final step in the notebook, we write the result of the join operation into a table ‘sales_reporting‘ inside our Azure SQL Database.
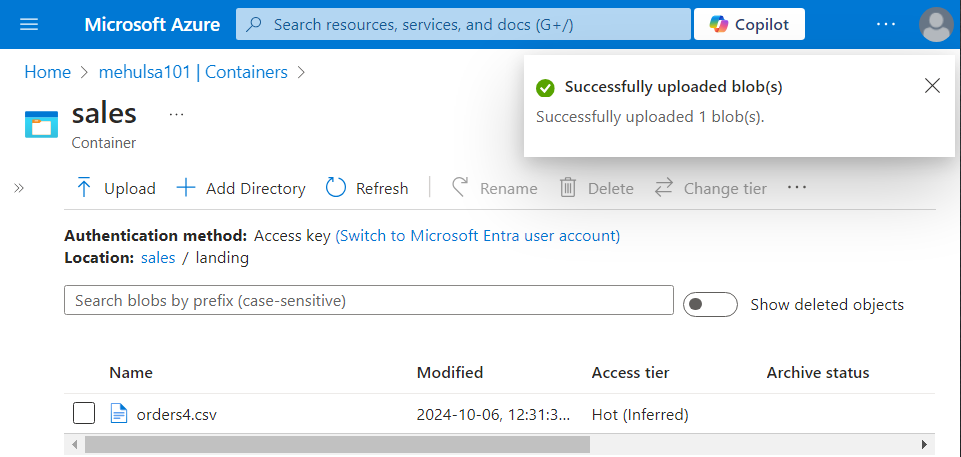
- As a final run, we upload the ‘orders4.csv‘ file into our ADLS Gen2 storage account, inside ‘sales‘ container’s ‘landing‘ folder.
- The pipeline gets triggered automatically and after the copy activity gets completed, the notebook runs successfully.
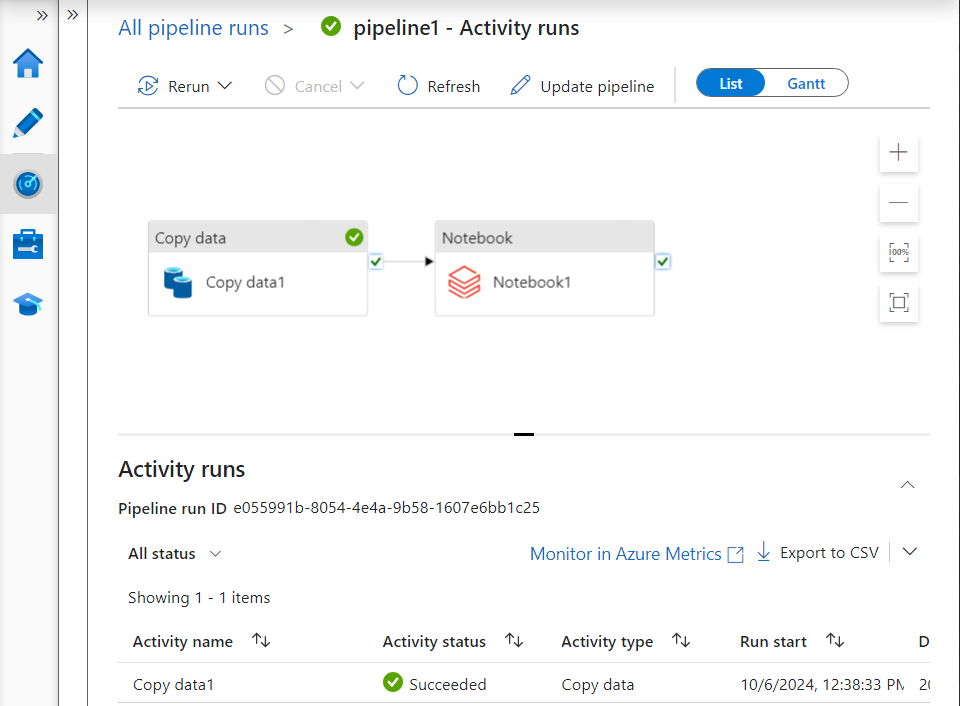
- Inside the notebook run, we can see that the final result gets displayed as required and it gets loaded into the Azure SQL Database successfully.
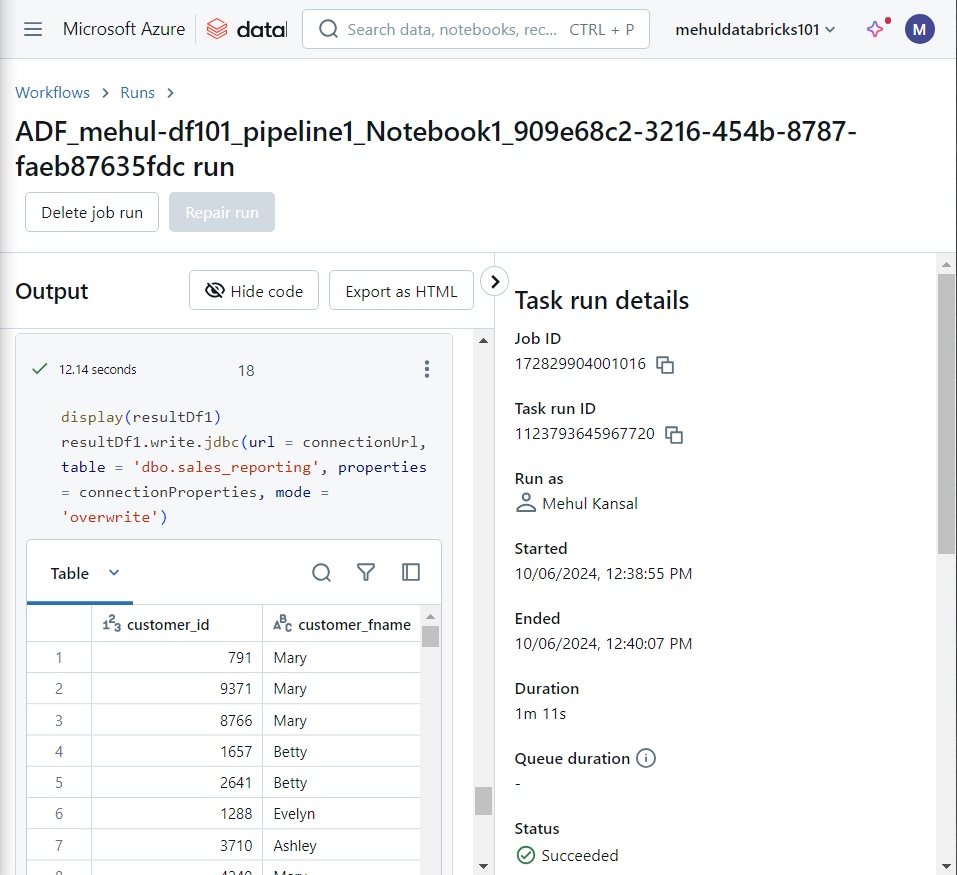
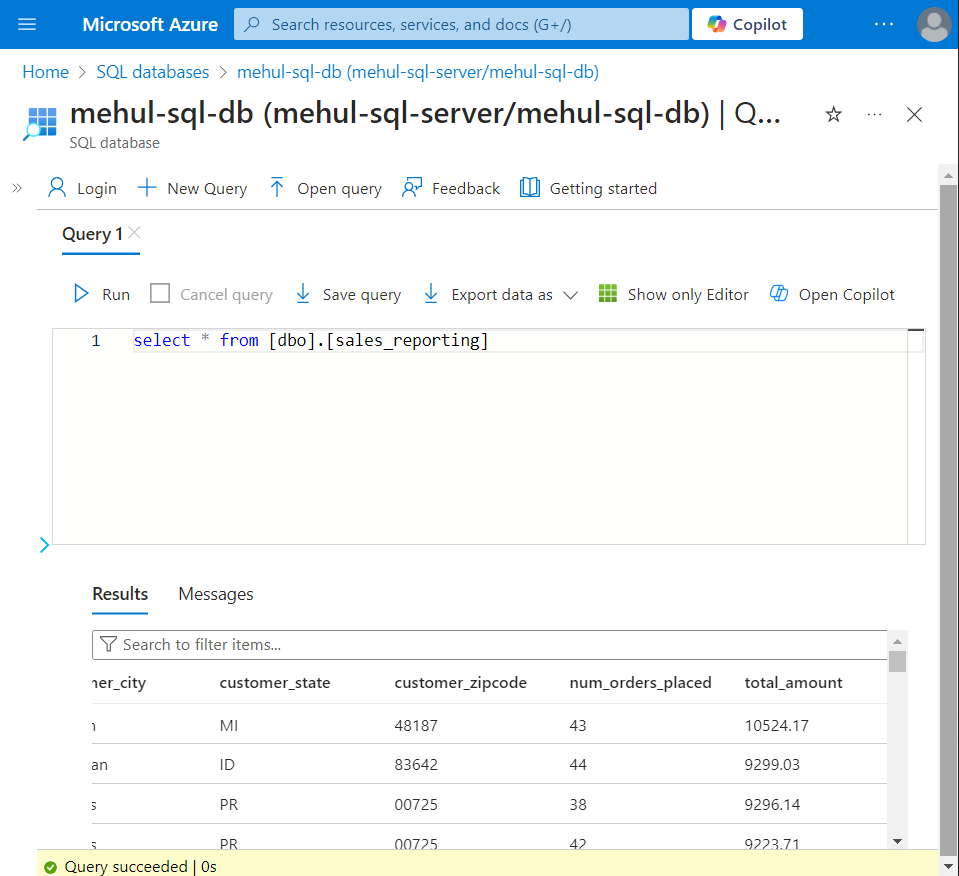
Finally, inside the Azure SQL Database, the table ‘sales_reporting‘ gets populated with the results as desired.
This table can be further used for reporting purposes.
Conclusion
The Azure Sales Data Pipeline Automation project successfully demonstrates the automation of data validation, transformation, and reporting using Azure's ecosystem. By leveraging services such as Databricks, Azure Data Factory, ADLS Gen2, Amazon S3 and Azure SQL Database, we ensure seamless data processing with minimal manual intervention.
Stay tuned!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by