Optimizing Performance with Caching: A System Design Approach
 Ritik Singh
Ritik Singh
In this article, we are going to discuss the following things
Cache and its types
Writing policies in the cache
Replacement policies
Cache and its types
The cache is the temporary storage that stores the part of the database in our memory.
Benefits
Getting data from in-memory storage is much faster, so it reduces response time.
It helps to reduce database load if data exists in the cache we can directly send it from the cache no need to request directly to the database.
Let's say you are hitting a request on the server and there is no cache existing right now so the overall time and order of requests will look like this
100 ms (client to server)
10 ms(server to DB)
10 ms (DB to server)
100 ms (server to client)
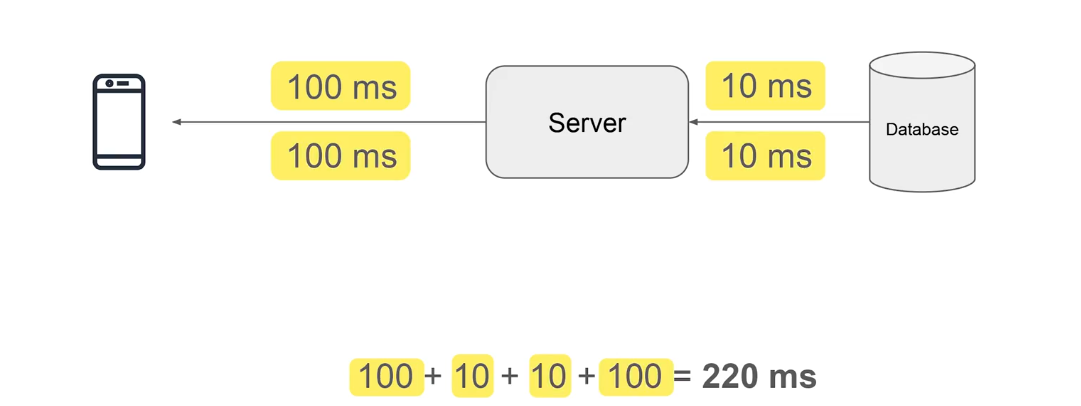
So, the overall time =220ms
Let's implement a cache in this, so the order will look like
100ms (Client to Server)
Server check in cache (1ms) and return it from cache
100ms (Server to Client)
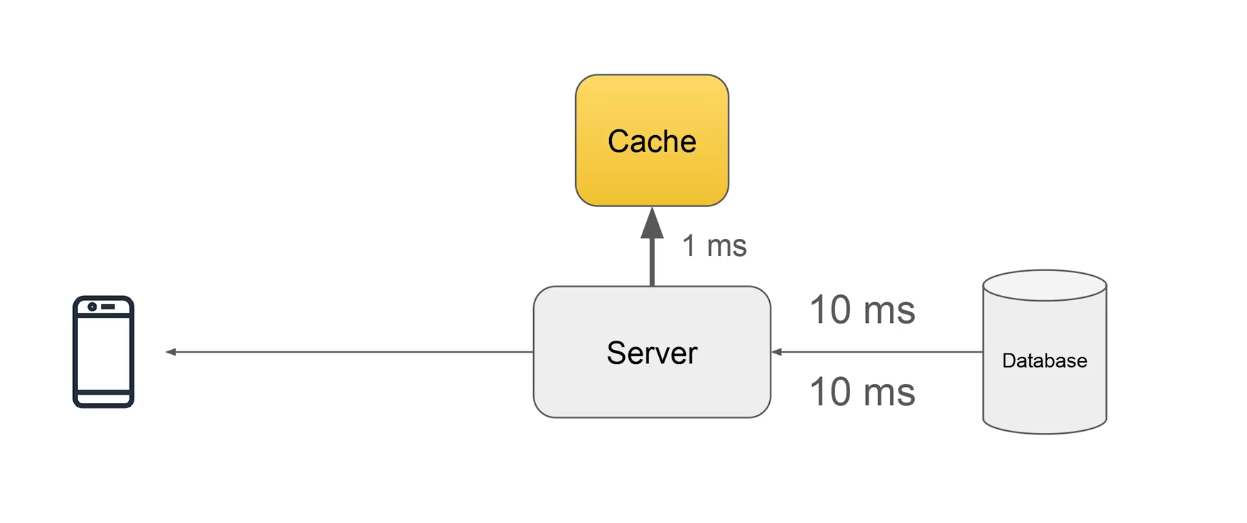
So, overall time = 200ms+ 1ms x 2= 202ms
So time save by cache=202/220= ~10% saving
But there are drawbacks
If the data client is requesting does not exist in the database then we will have to query the data to the database it will increase our time like first checking into cache then not exist we will again check in the database.
What if there is a written request in our database and at the same time there is a read request so, our cache and database are not consistent cache will return previously stored value which is incorrect. So to solve this problem we will be going to Cache Write Policies.
What if our cache is full and there are some new requests? So to solve this problem, we will be going to see Replacement Policies
Type of cache
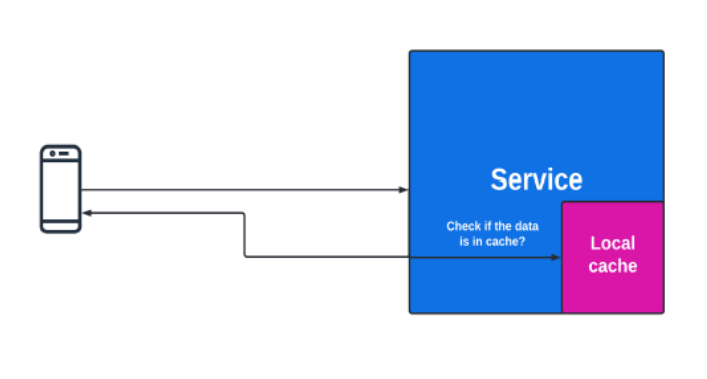
Local Cache: A local cache keeps data in the service's memory, speeding up access since no network calls are needed. But this can cause a fanout issue—if there are multiple servers, updating data like a user profile means sending requests to each server. To fix this, we can split the data across servers using a load-balancing method like consistent hashing. However, if a server fails, replicating data to other servers can help but may cause data inconsistency. In short, local caches boost speed but can reduce data consistency.
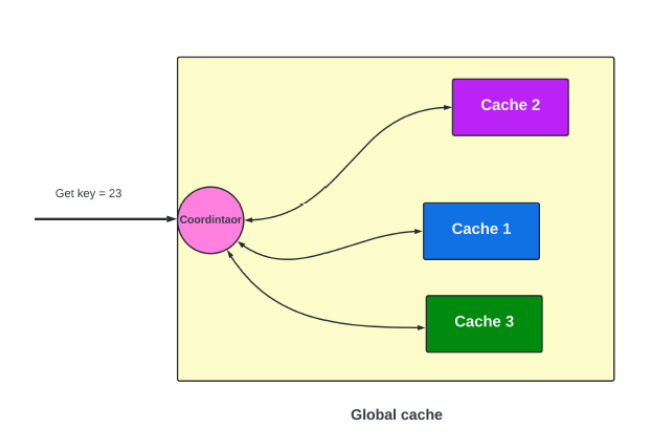
Global Cache: It stores all key-value data in a central location instead of having each server keep its own copy. This setup improves data consistency since there's only one source of truth, but it slows down response times because every request has to go through a network call to access the central cache.
Writing policies in the cache
Write-Back Policy: In this policy, if there is a write request we will update it in our cache without immediately updating the database as long as the cache is alive, the user will get consistent data. If cache go down data becomes stale.
To Solve this problem we can use the following mechanism.
Timeout-Based Persistence: In this we will stored the TTL (time to live of each entry in our cache) if the TTL is greater than current timestamp we will evict that key from cache and update the value of it in our database it helps to gain eventual consistency
Event-Based Write Back: In this we basically keeping the event based trigger for example if the count of updates for a particular key if it is greater than 5 or something else we persist it in the database.
Replacement Write Back: For each entry in the cache, we have an attribute that tells us if the entry is updated or not. When we want to evict the entry we update the entry in the database if the entry was updated in the cache.
This policy is efficient. It is especially useful when we want efficient querying in our cache and we are fine with persistence not being 100%.
Write-Through Policy: In this policy, we basically update the cache and database together if there is any write request coming.
But by doing this we can fall into the problem for example Initially,
we have X = 10
There is a write request for X = 20
There is a read request for X, but the write request is not updated yet. So the read request returns X = 10. So it can cause inconsistency
To avoid such problems, we can lock the data which is to be written and only unlock the data after the update operation is completed.
This policy is useful
When we need a high level of consistency
When we need a high level of persistence
However, it is less efficient compared to the write-back policy.
Write-Around Policy: In this policy, when we get a write request, instead of updating the entry in the cache, we update the entry in the database.
Now when we get a read request, we will send the stale value from the cache. And we will be getting stale value until the entry is evicted from the cache.
This policy is useful
When we need a high level of efficiency
When we need a high level of persistence
However, it makes our system eventually consistent
Replacement Policies
When cache storage runs out, we need to decide which data to remove to make room for new data. This is where replacement policies like LRU, LFU, and Memcached come in.
LRU (Least Recently Used): This policy evicts the data that hasn't been used for the longest time. It works well for most applications where recently accessed data is more likely to be reused.
LFU (Least Frequently Used): LFU removes the data that has been accessed the least number of times. It’s useful when some data is more frequently needed than others over a long period.
Memcached: Memcached uses two data stores, The cold region (for less frequently accessed data) and the hot region (for more frequently accessed data). Both regions follow the Least Recently Used (LRU) policy for eviction. Let’s break it down with a simple example:
Cache Setup:
Both the hot and cold regions can hold 2 entries.
Initially, the cache is empty.
Example:
Read request for key 1 at timestamp 20
Cache miss (key 1 isn’t in the cache).
Add
{1, 56, 20}to the cold region.
Read request for key 1 at timestamp 21
Key 1 is in the cold region, so it’s promoted to the hot region.
Add
{1, 56, 21}to the hot region and remove it from the cold region.
Read request for key 1 at timestamp 22
- Key 1 is in the hot region, so it's a cache hit.
Read request for key 4 at timestamp 23
Cache miss for key 4.
Add
{4, 64, 23}to the cold region.
Read request for key 5 at timestamp 24
Cache miss for key 5.
Add
{5, 65, 24}to the cold region. Now, the cold region is full.
Read request for key 2 at timestamp 25
Cache miss for key 2, and the cold region is full.
Evict key 4 (the least recently used entry) from the cold region.
Add
{2, 67, 25}to the cold region.
Read request for key 2 at timestamp 26
Key 2 is in the cold region, so it’s promoted to the hot region.
Add
{2, 67, 26}to the hot region and remove it from the cold region.
Current Cache State:
Hot region:
{1, 56, 21}{2, 67, 26}
Cold region:
{5, 65, 24}
Read request for key 5 at timestamp 27
Key 5 is in the cold region, so it’s promoted to the hot region.
The hot region is full, so we evict the least recently used entry (key 1) and move it to the cold region.
Add
{5, 65, 27}to the hot region and remove it from the cold region.
Final Cache State:
Hot region:
{2, 67, 26}{5, 65, 27}
Cold region:
{1, 56, 27}
Key Takeaways:
The more frequently an entry is accessed, the more likely it will be promoted to the hot region.
Evictions are based on the Last Used timestamp using the LRU policy.
Memcached uses this approach, known as Segmented LRU, to keep frequently accessed data in the hot region and push less-used data to the cold region.
Subscribe to my newsletter
Read articles from Ritik Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by