What the hell is this LLM thing?
 vedant jumle
vedant jumle
What’s the Big Deal About Large Language Models Anyway?
So, you’ve probably heard about Large Language Models (LLMs)—those AI systems that magically generate text, answer your questions, and even pretend to understand what you mean. Sounds impressive, right? Basically, they’re just advanced versions of autocorrect that somehow got way too smart.
These algorithms are designed to predict the next word in a sentence. “Not that impressive, even I can do that,” you say. Well, this simple approach to programmatically understanding language has been directly responsible for basically most tech startups since 2021. Hence, your boss rambling about “We need to get this LLM thing for ourselves”, is kind of justified.
In this post, we’ll break down what LLMs are, why they’re everywhere, and what’s so special about them. Whether you're here out of genuine curiosity or just to impress someone at a party, we’ve got you covered. Let's get started—before these models take over your job too!
What Are Large Language Models?
Alright, so what exactly are these Large Language Models everyone is talking about? Imagine a computer that reads all the text on the internet (yes, including your bad git commit messages), then tries to string together sentences that sound like they were written by a human. Sounds straightforward, right? Well, it is—if you think memorizing an entire library is “straightforward.”
LLMs, like GPT, Llama, and Claude, are trained to predict the next word in a sentence. So if you type “I can’t believe it’s not…” it might suggest “butter.” Yay, Groundbreaking! But seriously, these models can do a lot more: summarize text, translate languages, write your thesis, and even write code (because of course they can).
In short, LLMs are your overachieving classmate who not only does the reading, but somehow understands everything. And now, they’re popping up in every industry. We’re just here trying to keep up.
A Quick History of LLMs
Believe it or not, LLMs didn’t just appear out of thin air. We started with basic language models that were about as clever as a fortune cookie. Then came Word2Vec, which gave us a little more context, and finally, the big game-changer: Transformers.
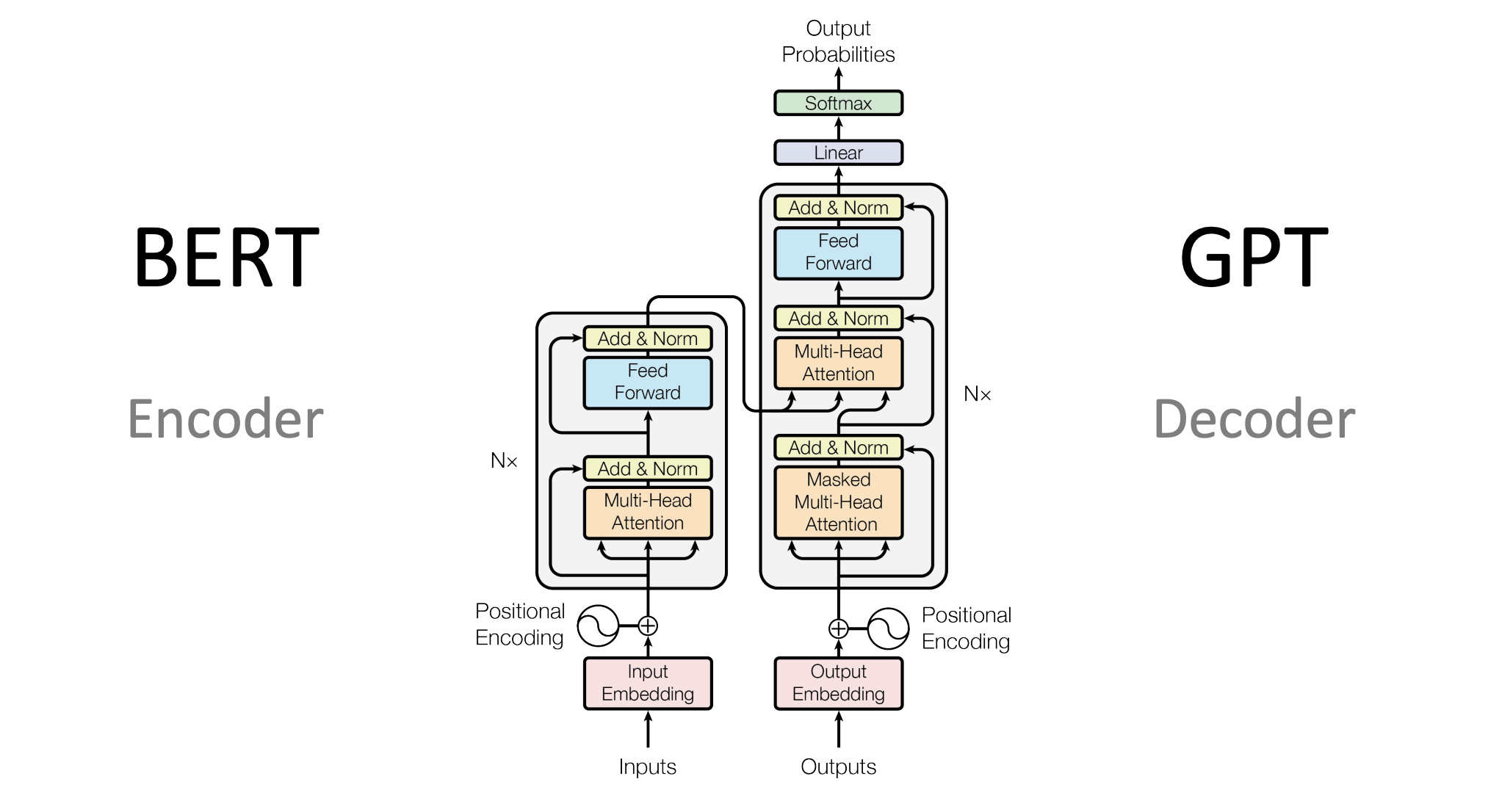
With the Transformer architecture (not the robots, unfortunately), models like BERT and GPT took off. Suddenly, AI could read and write better than most of us—scary, right? Now, LLMs are everywhere, from chatbots to text generators. So yeah, they’ve come a long way from just predicting random words.
How LLMs work: key concept
Alright, now let’s pull back the curtain on how Large Language Models (LLMs) work. Spoiler: it's not black magic—it just looks that way.
Transformers: The Secret Sauce
The backbone of all modern LLMs is the Transformer architecture, which sounds cool because it is. Unlike earlier models that processed words one by one (slow and tedious, right?), Transformers look at the entire sentence simultaneously. This allows the model to understand the context better. For example, in the sentence "I went to the bank," the knows know whether you're talking about a financial institution or a riverbank based on the surrounding words. So, it’s not just predicting the next word—they’re getting a feel for the whole vibe.
At the heart of this is the self-attention mechanism, which is the Transformer’s way of figuring out which words in a sentence are important. Think of it like a spotlight shining on certain words, helping the model focus on what's relevant while ignoring the background noise. Consider the following example:
For the sentence: "He (i)_____ the (ii)_____ book."
Assign the words 'red' and 'read' to the appropriate blanks.
You would discern that the first blank should be read while the second blank should be red . But how did you do that…?
Well, you probably saw the word ‘book’ and its relative position against the first blank, and understood that the first blank should be the verb read. Similarly, you discerned that the second blank should be red, because it is an adjective that describes the book. Congratulations, you are Shakespeare.
Similarly, LLMs utilize the attention mechanism to build context to predict the next correct word reliably.
Tokenization
LLMs don’t read words like we do. Instead, they break everything down into tokens, which can be whole words, parts of words, or even individual characters. This process, called tokenization, allows the model to process and understand language more efficiently. But it gets even smarter with subword tokenization—where words are split into smaller pieces if they’re uncommon. So, if you type “unbelievable,” the model might break that into tokens like “un,” “believe,” and “able.” When you type “I love pizza,” it might break it into tokens like “I,” “love,” and “pizza,” and then predict what comes next (probably "cheese" if it’s doing its job).
Embeddings
Embeddings are like the cheat code that helps machines "get" language. Instead of treating words as isolated blobs, embeddings turn them into dense vectors where similar words hang out together in a magical multi-dimensional space. So, “king” and “queen” are buddies, but “king” and “pizza” are not. Thanks to embeddings, AI models can pretend they understand context, which is why your chatbot doesn't sound like it's playing a terrible game of word salad (most of the time).
Training the LLM: Turning Raw Data into Smart AI
Training a Large Language Model (LLM) is like putting it through an intense language boot camp—only instead of learning one language, it learns all the languages (or at least, all the languages in its training data). Let’s break down how this process works.
Step 1: Collecting Massive Amounts of Data
First things first, you need a lot of data. We're talking billions of words. This data usually comes from a mix of sources—books, websites, articles, social media posts, and even code repositories. Essentially, anything that’s text-based is fair game. The broader and more diverse the dataset, the better the model’s general language understanding will be. Imagine reading everything ever written on the internet (minus the cat memes), and that’s pretty much what an LLM does during training.
Step 2: Tokenization – Breaking it Down
Before the model can start learning, the text needs to be tokenized. LLMs don't read whole words—they read tokens. Tokens are chunks of text that can be entire words, parts of words, or even individual characters. For example, "Understanding" might be tokenized into "Under," "stand," and "ing." By breaking text into tokens, the model can process language in a more manageable way, especially when dealing with complex or unfamiliar words.
Step 3: Pretraining – Learning the Basics
The pretraining phase is where the real fun begins. During this stage, the LLM learns to predict the next token in a sequence. Think of this as an incredibly advanced game of “fill in the blanks.” The model sees part of a sentence and has to guess what comes next. Over time, by processing billions of sentences, the LLM starts getting really good at this game. This is where the LLM builds a general understanding of how language works, from basic grammar to more nuanced things like idioms and metaphors.
During pretraining, the model's objective is usually something like masked language modeling (used in BERT) or causal language modeling (used in GPT). In masked language modeling, the model learns by trying to predict missing words in sentences. In causal modeling, it predicts the next word in a sequence based on previous ones.
Step 4: Fine-tuning – Getting Specific
After pretraining, the model has learned the "basics" of language, but it’s still a generalist. To make it useful for specific tasks, it needs to be fine-tuned. This is a much more focused process where the model is trained on a smaller, task-specific dataset. Fine-tuning could be for anything: answering questions, summarizing text, generating code, or any other task that requires specialized knowledge.
For instance, a model fine-tuned on medical data would become an expert at answering questions related to healthcare. This is where LLMs can be adapted for specific industries or applications, giving them the ability to provide highly relevant and accurate responses in specialized domains.
Step 5: Adjusting Weights – The Learning Process
Throughout both pretraining and fine-tuning, the model constantly adjusts its internal parameters, or "weights." After each prediction, the model checks how close its guess was to the correct answer. It then tweaks its weights to improve the next prediction. This process, known as backpropagation, is repeated billions of times until the model becomes extremely accurate at predicting the next token or word in any given sentence.
Step 6: Validation – Making Sure It’s Not Just Memorizing
Just like humans need to test their knowledge, LLMs go through a validation process to ensure they aren’t just memorizing text but actually learning patterns. The model is tested on unseen data (called the validation set) to evaluate its performance. If it’s overfitting—meaning it’s just parroting the training data—the developers will adjust the model to improve its generalization skills.
Step 7: Deployment – Putting the Model to Work
Once trained and fine-tuned, the LLM is ready for deployment. It can be integrated into applications like chatbots, content generators, translation services, or even recommendation systems. And thanks to all that training, the model can handle tasks with near-human accuracy.
The Hardware Side of Training
It’s important to note that training LLMs is resource-intensive. It requires massive amounts of computational power—think high-performance GPUs running for weeks or even months. That’s why training these models is typically done by large tech companies with deep pockets. Once trained, though, these models can be fine-tuned more easily on smaller machines for specific use cases.

So, there you have it—LLMs, the text-generating, question-answering, all-knowing wizards of the digital age. They’ve come a long way from playing glorified guessing games with words to now pretending to be your personal assistant. Sure, they’re not perfect (biases, anyone?), and they require an absurd amount of computing power, but hey, who’s counting when you’ve got near-infinite knowledge at your fingertips?
Love them or fear them, LLMs aren’t going anywhere. They’re here to make sure you never have to write another email or answer a question without AI backup. So buckle up, because this is just the beginning—soon, they might even be reading this conclusion for you!
Subscribe to my newsletter
Read articles from vedant jumle directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by