Understanding Indexing in a practical way (with postgres)
 Amardeep Ranjan
Amardeep Ranjan
Hi there, in this blog we will try to understand how indexing works in databases. For this article we are using postgress as the database. Prequiste to follow with this article is docker if you don’t have postgress installed in your pc.
I’ll be writing some commands which you can directly paste in your terminal and see yourself how things are going.
Let’s start
First step is having postgres either you can install or run this docker command.
docker run -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d postgres
This will install postgres in your pc.
Next step :-
docker exec -it container_id /bin/bash
psql -U postgres
This will connect to the postgres server and now you can run postgres commands into it. Let’s add a schema and also the dummy data to it.
CREATE TABLE users (
user_id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
password VARCHAR(255) NOT NULL,
name VARCHAR(255)
);
CREATE TABLE posts (
post_id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
title VARCHAR(255) NOT NULL,
description TEXT,
image VARCHAR(255),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
DO $$
DECLARE
returned_user_id INT;
BEGIN
-- Insert 5 users
FOR i IN 1..5 LOOP
INSERT INTO users (email, password, name) VALUES
('@example.com">user'||i||'@example.com', 'pass'||i, 'User '||i)
RETURNING user_id INTO returned_user_id;
FOR j IN 1..500000 LOOP
INSERT INTO posts (user_id, title, description)
VALUES (returned_user_id, 'Title '||j, 'Description for post '||j);
END LOOP;
END LOOP;
END $$;
This above psql command will add 5 user with 5 Lakh post for each user.
Now let’s try running a query.
EXPLAIN ANALYSE SELECT * FROM posts WHERE user_id=1 LIMIT 5;
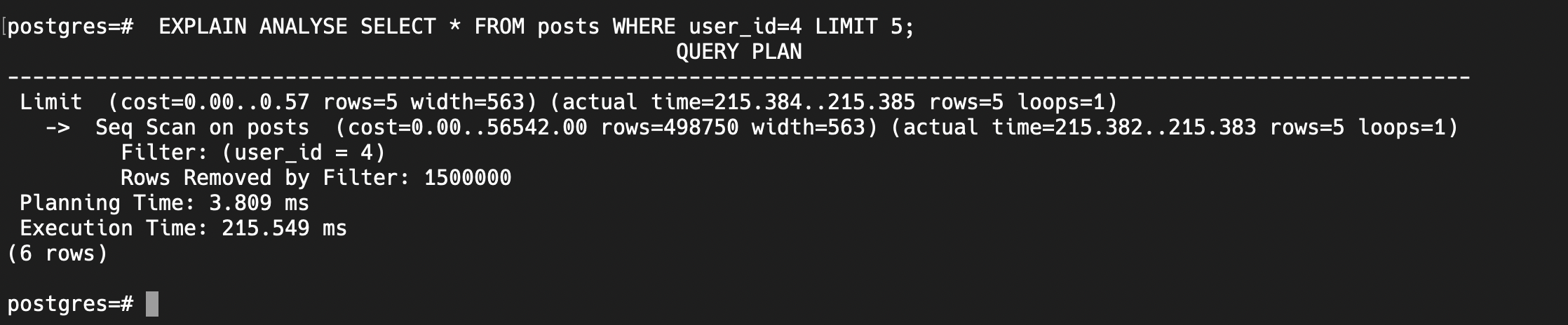
You can see the execution time for this query is 215 ms which is huge and it can make the api calls slower. We need to make it shorter. So what we can do now is do indexing.
CREATE INDEX idx_user_id ON posts (user_id);

Now the index is created. Again we run the same command but with different user id as the previous one is already in the memory.

Notice the execution time now. It is reduced so much. So with the help of indexing we can reduce the query execution time.
Now let’s understand how things are working behind the scene.
When we create an index on a field, a new data structure (usually B-tree) is created that stores the mapping from the index column to the location of the record in the original table.
The searching operation of this column is log(n)
Once the index is created, whenever a query searches for data using the indexed column, the database doesn’t have to scan the entire table (which would take O(n) time, where
nis the number of rows).Instead, it can use the B-tree index to perform the search in O(log n) time. This is much faster, as it only requires traversing the B-tree, reducing the number of comparisons needed to locate the data.
In the B-tree, nodes are organized such that each comparison eliminates half of the remaining search space, which is why the search time is logarithmic.
Once the index finds the value in the B-tree, it refers to the row in the table where the actual data is stored. This is a quick lookup since the B-tree stores the reference (often the row ID or address in memory).
So this is it. Hope you like this article if then a thumbs-up and a follow would be highly appreciated.
Do follow me on X @Amardeep885
Subscribe to my newsletter
Read articles from Amardeep Ranjan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by