The Art of API Traffic Control: A Deep Dive into Rate Limiting
 Rahul R
Rahul R
In today’s digital landscape, managing the flow of requests to web services and APIs is essential for ensuring system stability, security, and fairness. Rate limiting has emerged as a key technique to address these challenges. This article explores the concept of rate limiting, its significance, various implementation strategies, and best practices for developers and system architects.
Summary:
What is Rate Limiting
Why is Rate Limiting required
How does Rate Limiting work
Implementing Rate Limiting
Managing Rate Limiting in Distributed Systems
What is Rate Limiting?
In simple terms, Rate Limiting restricts access to a resource or the number of requests processed in a certain amount of time. This technique controls the incoming and outgoing requests in a network. Rate limiting will restrict the access for an actor (a user, browser, IP, device, etc. ) from the resource (server, API, etc. ). It is a requisite in large-scale systems, where rate limiting is implemented for security and performance improvement.
Rate limiting can be implemented in many ways. For example, an IP address can be restricted to 10 requests in 5 minutes/ 1 request every minute. If the limit is exceeded, the system will throw an error and not process the request.
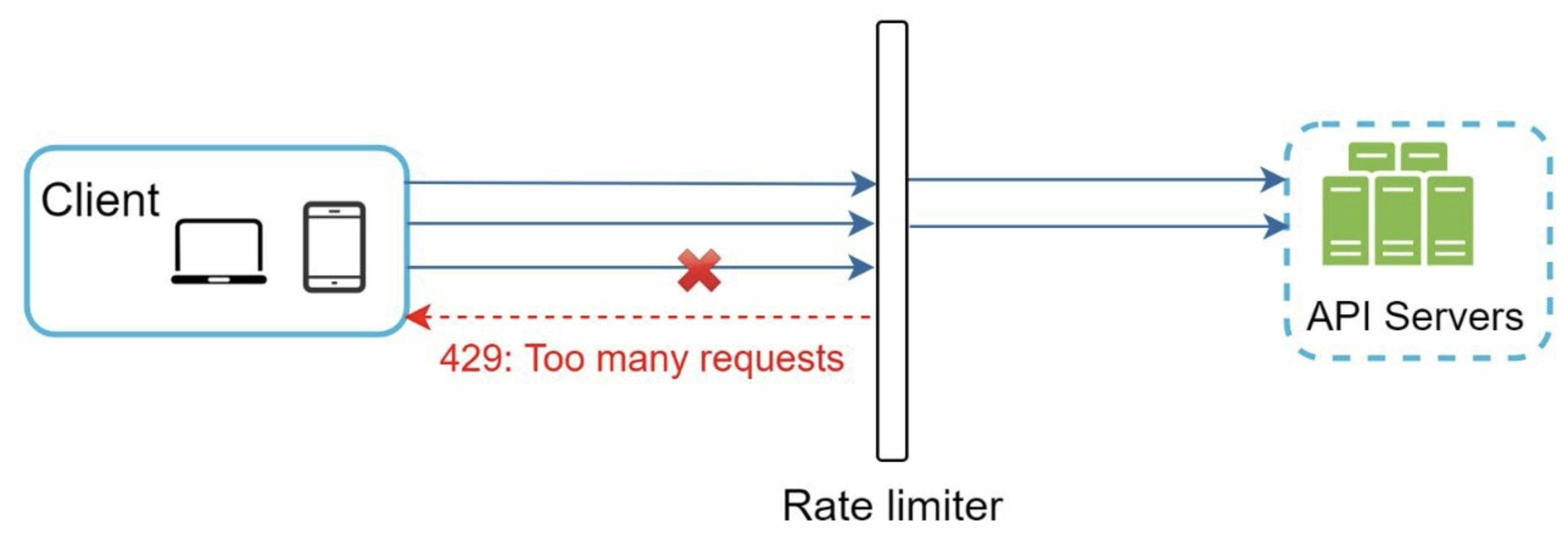
Why is Rate Limiting required?
Security
The system can be overloaded — a DOS (Denial of service) attack can be performed. Flooding the target with traffic prevents legitimate users from accessing resources.
Performance
When a resource is shared by traffic, it is best practice to set a limit for the user. Also, if a service takes a large payload, processing that request will take more resources and affect the system’s performance.
Business
Any operation performed will have a cost associated with it. So it is vital to restrict the usage of the service to be profitable. Users can be requested to move to a higher-paid plan according to the user’s requirements.
How does Rate Limiting work?
A limit is set for the number of operations processed by the system. Once that is exceeded, the system will not process any more requests. This limit can be for an IP, user, location, device, etc. When a request comes in, the rate limit implementation checks if the request exceeds the set limit. If it does, the system will block the request and not process it further.
Rate limit can be implemented on the client, middleware, and server side.
Client-Side:
Implementing rate limit logic in a browser is a client-side approach. However, this can be altered by malicious users, which makes the client side insecure.Middleware:
Rate limiting on the gateway (or proxy, etc.) restricts requests before they reach the servers. This approach helps avoid implementing rate limiting directly on the server.Server-Side:
Here the rate limit is performed on the server before processing the actual logic of that service.
Popular Rate Limiting Algorithms
Fixed window Counter
A fixed limit is set for a window time (Example: 100 requests/ 1 hour). Any request will be rejected after the limit is exceeded.
Example: A social media API that limits users to 100 posts/ hour.Sliding window logs
Here the user logs are stored with a time stamp, and when the logs exceed the limit, the requests are rejected.
Example: An e-commerce platform that tracks and limits the number of price checks a user can perform over a rolling 24-hour period.Sliding window counter
This method combines the fixed window counter and sliding window logs. A counter and logs determine whether to process a request. It is the best option for handling a large number of requests.
Example: A weather API that allows 1000 requests per day, with a maximum of 100 requests per hour.Token bucket
A bucket will be predefined with a limit and loaded with tokens. When a request comes in, a token is consumed from the bucket. If the token is consumed, the request will be processed. Otherwise, the request is rejected.
Example: A cloud storage service that allows users to upload files with a certain amount of bandwidth that replenishes over time.Leaky bucket
This method is based on the average processing of requests. A bucket is set with a limit. Requests are processed in a FIFO (First-in-First-out) manner. When the bucket reaches its queue limit, requests further will be rejected.
Example: A high-frequency trading platform that smooths out the rate of order submissions to prevent overwhelming the exchange.
Implementing Rate Limiting
Here is a simple implementation of rate limiting in Java and Python.
This Java implementation uses a token bucket algorithm. It allows a specified number of requests within a given time interval. The allowRequest() method returns true if a request is permitted and false when rate-limited.
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
public class RateLimiter {
private final int maxRequests;
private final long intervalInMillis;
private final AtomicInteger tokens;
private final AtomicLong lastRefillTime;
public RateLimiter(int maxRequests, long intervalInMillis) {
this.maxRequests = maxRequests;
this.intervalInMillis = intervalInMillis;
this.tokens = new AtomicInteger(maxRequests);
this.lastRefillTime = new AtomicLong(System.currentTimeMillis());
}
public boolean allowRequest() {
refillTokens();
return tokens.getAndDecrement() > 0;
}
private void refillTokens() {
long currentTime = System.currentTimeMillis();
long timeElapsed = currentTime - lastRefillTime.get();
if (timeElapsed > intervalInMillis) {
tokens.set(maxRequests);
lastRefillTime.set(currentTime);
}
}
public static void main(String[] args) {
RateLimiter limiter = new RateLimiter(5, 1000); // 5 requests per second
for (int i = 0; i < 10; i++) {
System.out.println("Request " + (i + 1) + " allowed: " + limiter.allowRequest());
}
}
}
This Python implementation also uses a token bucket algorithm. It’s similar to the Java version but uses Python’s built-in time module for timing.
import time
class RateLimiter:
def __init__(self, max_requests, interval):
self.max_requests = max_requests
self.interval = interval
self.tokens = max_requests
self.last_refill_time = time.time()
def allow_request(self):
self._refill_tokens()
if self.tokens > 0:
self.tokens -= 1
return True
return False
def _refill_tokens(self):
now = time.time()
time_elapsed = now - self.last_refill_time
if time_elapsed > self.interval:
self.tokens = self.max_requests
self.last_refill_time = now
if __name__ == "__main__":
limiter = RateLimiter(5, 1) # 5 requests per second
for i in range(10):
print(f"Request {i + 1} allowed: {limiter.allow_request()}")
time.sleep(0.2)
Both implementations create a rate limiter that allows 5 requests per second. When you run the program, you’ll see that the first 5 requests are allowed, and subsequent requests are denied until the token bucket refills.
These are basic implementations and don’t handle concurrency issues that might arise in a multi-threaded environment. For production use, you might want to use more robust libraries or implement additional features like distributed rate limiting for microservices architectures.
Managing Rate Limiting in Distributed Systems
In a distributed environment, there can be two instances of an application with the rate limit implementation setup on the server side. Every instance will act independently. For illustration, the first request is processed by the first instance, and the following request is sent to the second instance. The second instance doesn’t know about the older request and starts a fresh counter. This creates an inconsistency in the count of requests between instances. Distributed caching is used to solve this inconsistency. The data required for accounting requests will be cached and shared between instances. Hence all the applications will be in sync with the count of requests.

Subscribe to my newsletter
Read articles from Rahul R directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rahul R
Rahul R
🚀 Software Development Engineer | 🛠️ Microservices Enthusiast | 🤖 AI & ML Explorer As a founding engineer at a fast-paced startup, I’ve been building the future of scalable APIs and microservices - From turning complex workflows into simple solutions to optimizing performance. Let’s dive into the world of APIs and tech innovation, one post at a time! 🌟 👋 Let’s connect on LinkedIn https://www.linkedin.com/in/rahul-r-raghunathan/