From Information to Knowledge: Part 1 Knowledge Graph Databases
 Ali Yazdizadeh
Ali Yazdizadeh
What and Where vs How and Why: Information vs Knowledge
Since the start of the IT revolution, we've been storing data with the expectation that it will help us answer future questions. However, the types of questions we aim to answer have evolved over time. In the early days, most queries were transactional: "What did the customer purchase?" or "Where is this user located?" To answer these kinds of questions, we turned to relational or document-based databases, which excel at storing and retrieving structured records. These databases allowed organizations to quickly and efficiently access information and maintain a snapshot of the world as it exists at any given moment.
But as the complexity of business and technology has grown, so too have the kinds of questions we ask. Now, we want to understand deeper patterns: How do customers make decisions? Why is the supply of a product dwindling? These aren't just questions about "what" and "where"—they're questions that require insight into relationships and behaviors across multiple entities. Answering them requires “Knowledge”, not just information. And that’s where traditional databases begin to struggle.
The Era of Knowledge Graphs
The first concepts behind Knowledge Graphs (KGs) emerged from the need to understand more complex, interconnected data. While a company wiki or a standard database may store information, they do so in isolation, often siloed or without meaningful connections between data points. Knowledge Graphs, on the other hand, are designed to capture relationships and provide a more holistic view of how different pieces of information are related.
Knowledge Graphs first started gaining mainstream attention in the 2010s when companies like Google used them to enhance search results by better understanding the relationships between entities. Instead of simply returning web pages with matching keywords, Google could now recognize connections between people, places, and things—creating a more intuitive and rich search experience.
But Knowledge Graphs aren’t just for search engines. Their utility extends into any domain where understanding complex relationships is crucial—supply chains, energy grids, and customer interactions, to name just a few. In fact, Knowledge Graphs are becoming indispensable for modern organizations as they move from managing isolated data points to understanding how these points are connected in meaningful ways.
In this series of blog posts, we will cover three different aspects of Knowledge Graphs: Databases, Ontology, and finally, Query languages.
What is stored in a Knowledge Graph:
Imagine you want to store purchase orders for your business. In a typical database, you would need separate tables for persons, products, and orders, and store the relationships as columns in the order table. However, if you know the questions you’ll need to answer in the future, you can design the database to optimize for those queries. A graph database inherently stores these relationships, leading to simpler and more efficient query performance.
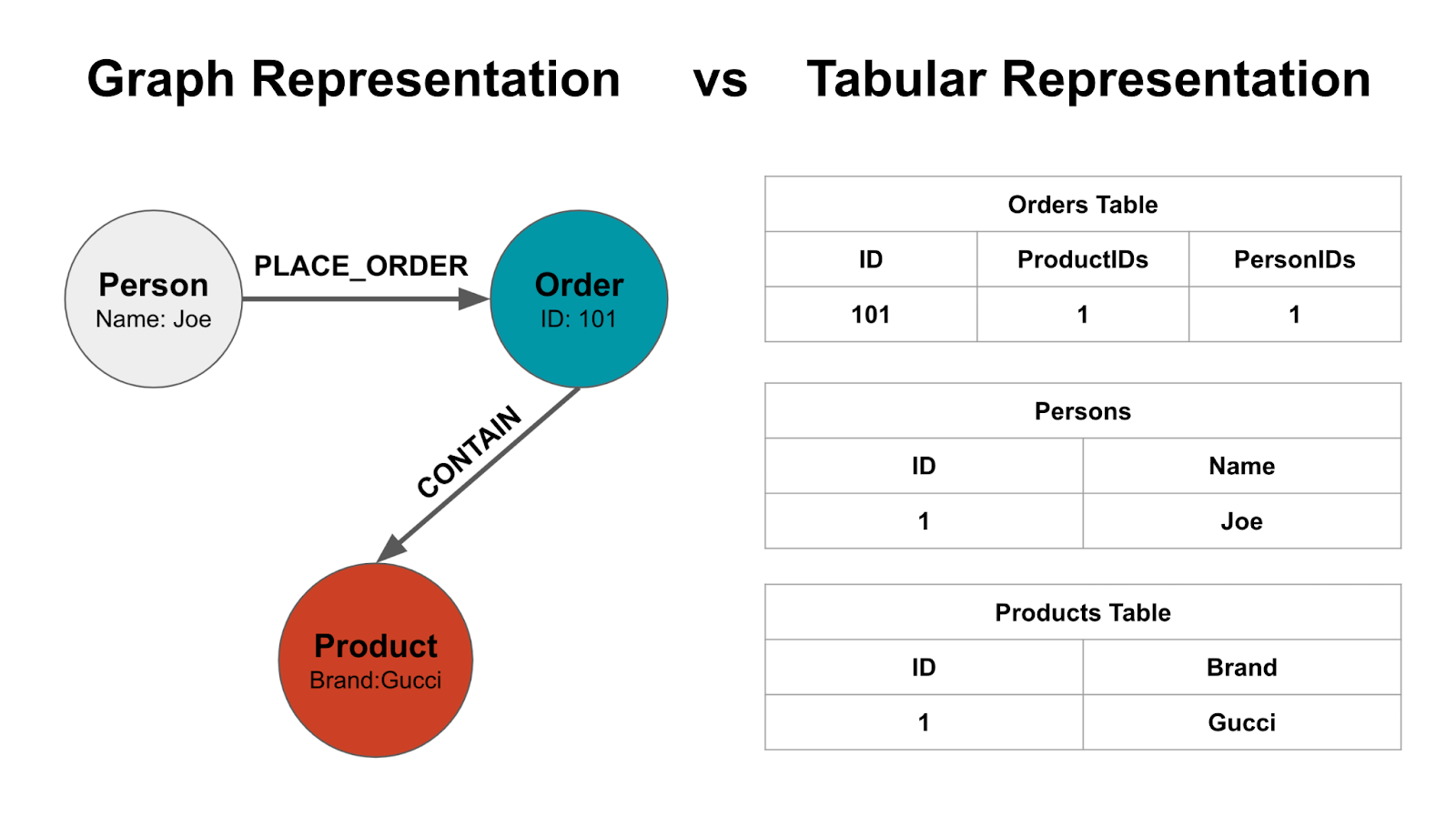
How to Store Data for Knowledge Graphs
Knowledge graphs represent information as a network of entities (aka nodes like Persons, Places, etc) and their relationship (edges like VISITED, ORDERED, etc). We therefore need a database that can efficiently store and retrieve such data. There are two primary approaches to storing data for knowledge graphs:
Property Graphs
Triple Stores (also known as RDF Stores)
Property Graphs
Property graphs are a data model where nodes and edges can have properties in the form of key-value pairs. This allows for rich and flexible representations of entities and their relationships. Here are some famous Property Graphs solutions:

Neo4j is one of the most popular graph databases using the property graph model. It offers a user-friendly query language called Cypher.
Advantages:
Ease of Use: Intuitive query language (Cypher) simplifies data retrieval.
Performance: Optimized for fast traversals and complex queries.
Community Support: Community Edition is open source and has a large user base and extensive documentation.
Disadvantages:
Scalability Limits: May require high Memory for very large datasets.
Cost: Commercial deployment needs enterprise edition which can be expensive.

Amazon Neptune is a fully managed graph database service by AWS that supports both the property graph and RDF models.
Advantages:
Flexibility: Supports multiple graph models (Property Graph and RDF).
Scalability: Easily scales with AWS infrastructure.
Integration: Seamless integration with other AWS services.
Disadvantages:
Cost: Pay-as-you-go model can become expensive over time.
Complexity: Requires familiarity with the AWS ecosystem.
Vendor Lock-in: Tied to AWS services.

OrientDB is a multi-model database that supports graph, document, key-value, and object models.
Advantages:
Versatility: Handles multiple data models in one system.
Open Source: Community edition is free to use.
ACID Compliance: Supports transactions for data integrity.
Disadvantages:
Learning Curve: Complexity due to multi-model capabilities.
Community Size: Smaller community compared to Neo4j.
Performance: May not match specialized databases in specific tasks.

Stardog is an enterprise knowledge graph platform that combines RDF and property graph features.
Advantages:
Hybrid Model: Supports both RDF and property graphs.
Advanced Features: Includes reasoning, inference, and data virtualization.
Enterprise-Ready: Scalable and secure for large applications.
Disadvantages:
Cost: Licensing fees can be high for enterprise features.
Complexity: Advanced features may require expert knowledge.
Resource Intensive: May require significant system resources.
Triple Store (aka RDF Store)
Triple stores are databases designed specifically for storing and retrieving RDF (Resource Description Framework) triples, which represent data in subject-predicate-object form. Here are some famous examples of RDF stores:
Blazegraph is an open-source graph database that supports RDF and SPARQL queries.
Advantages:
SPARQL Support: Fully supports SPARQL 1.1 query language.
Performance: Optimized for handling large RDF datasets.
Open Source: Free to use and modify.
Disadvantages:
Development Status: Amazon acquired the Blazegraph developers and the Blazegraph open-source development was essentially stopped in April 2018.
Community Support: Smaller user base may affect support.
Features: Lacks some advanced enterprise functionalities.

Apache Jena is a free and open-source Java framework for building semantic web and linked data applications.
Advantages:
Comprehensive Toolkit: Offers APIs for RDF, SPARQL, and OWL.
Reasoning Capabilities: Supports inference engines for advanced queries.
Active Community: Regular updates and extensive documentation.
Disadvantages:
Complexity: Requires significant setup and Java expertise.
Performance Tuning: May need optimization for large datasets.
Learning Curve: Steeper for those unfamiliar with semantic web technologies.
Alternative storage options for KGs in one view
| DB | RDF / Property Graph | Popularity | Open Source / Proprietary | Query Language | Actively Supported |
| Neo4j | Property Graph | Highly popular, especially for enterprise | Open Source (Community Edition) / Proprietary (Enterprise Edition) | Cypher | Yes |
| Amazon Neptune | Property Graph + RDF | Widely used in AWS ecosystem | Proprietary | Gremlin, SPARQL (for RDF), Cypher | Yes |
| OrientDB | Property Graph + Document, Key-Value, Object | Popular in multi-model database communities | Open Source (Community Edition) / Proprietary | SQL-like query language for Graphs | Yes |
| Stardog | Property Graph + RDF | Popular in enterprise settings | Proprietary | SPARQL, GraphQL, Cypher (through connectors) | Yes |
| Blazegraph | RDF | Popular in RDF community, though declining | Open Source | SPARQL | Limited (Open source support stopped in 2018) |
| Apache Jena | RDF | Widely used in academic and research fields | Open Source | SPARQL, RDQL | Yes |
Conclusion
When deciding where to store data for your knowledge graph, consider what kind of questions you need to answer. If your focus is on straightforward relationships and you require fast, complex traversals, a property graph database like Neo4j might be the optimal choice. Property graphs are excellent for applications where ease of use and performance are paramount, especially when dealing with richly connected data.
On the other hand, if your needs involve semantic queries, reasoning, and adhering to established data standards, an RDF store like Apache Jena could be more appropriate. Triple stores are designed to handle intricate semantic relationships and are better suited for applications that require inference and a higher level of data integration.
- Check out the next part, where we will discuss what Ontology is and why it’s the heart of a Knowledge Graph!
Subscribe to my newsletter
Read articles from Ali Yazdizadeh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by