Integrating Redshift & AWS Data Lake: A Comprehensive Guide
 Arpit Shrivastava
Arpit ShrivastavaTable of contents
- Understanding the Basics
- Importance of Integration
- Introduction to Key Tools and Services
- AWS Data Lake Setup
- Configuring Redshift for Data Lake Integration
- Data Lake Optimization Strategies
- Benefits of Integration
- Best Practices for Integration
- Security and Governance
- Summary of Integration Process
- Future Prospects
- References

Imagine having the power to access a pool of data that's not just vast but also secure and always ready for you.
That’s what happens when you integrate Amazon Redshift with AWS Data Lake. It’s truly a transformative experience in the realm of cloud database solutions.
You might wonder, does AWS really have a data lake? Absolutely, with over a million data lakes operational on AWS, and Amazon S3 standing out for its incredible durability, availability, and security.
Understanding the Basics
Integrating Amazon Redshift with AWS Data Lake unlocks a treasure trove of opportunities.
It’s all about leveraging big data to make smart choices. When Redshift connects with AWS Data Lake, it offers businesses a robust solution. Over 1,000,000 lakes on AWS S3 attest to its exceptional qualities.
Importance of Integration
Why go for Amazon Redshift instead of the traditional database? It's clear: faster data processing, dynamic scaling, and a lot more.
These integrations are powered by top-notch Amazon data integration tools, crafted to surpass the limits that traditional databases face.
Introduction to Key Tools and Services
When we talk about protocols, Amazon Redshift uses the Secure Sockets Layer (SSL) protocol. This ensures a seamless connection and safe data transactions.
The integration is solid on security thanks to Virtual Private Cloud and data encryption. Your data assets remain protected and secure.
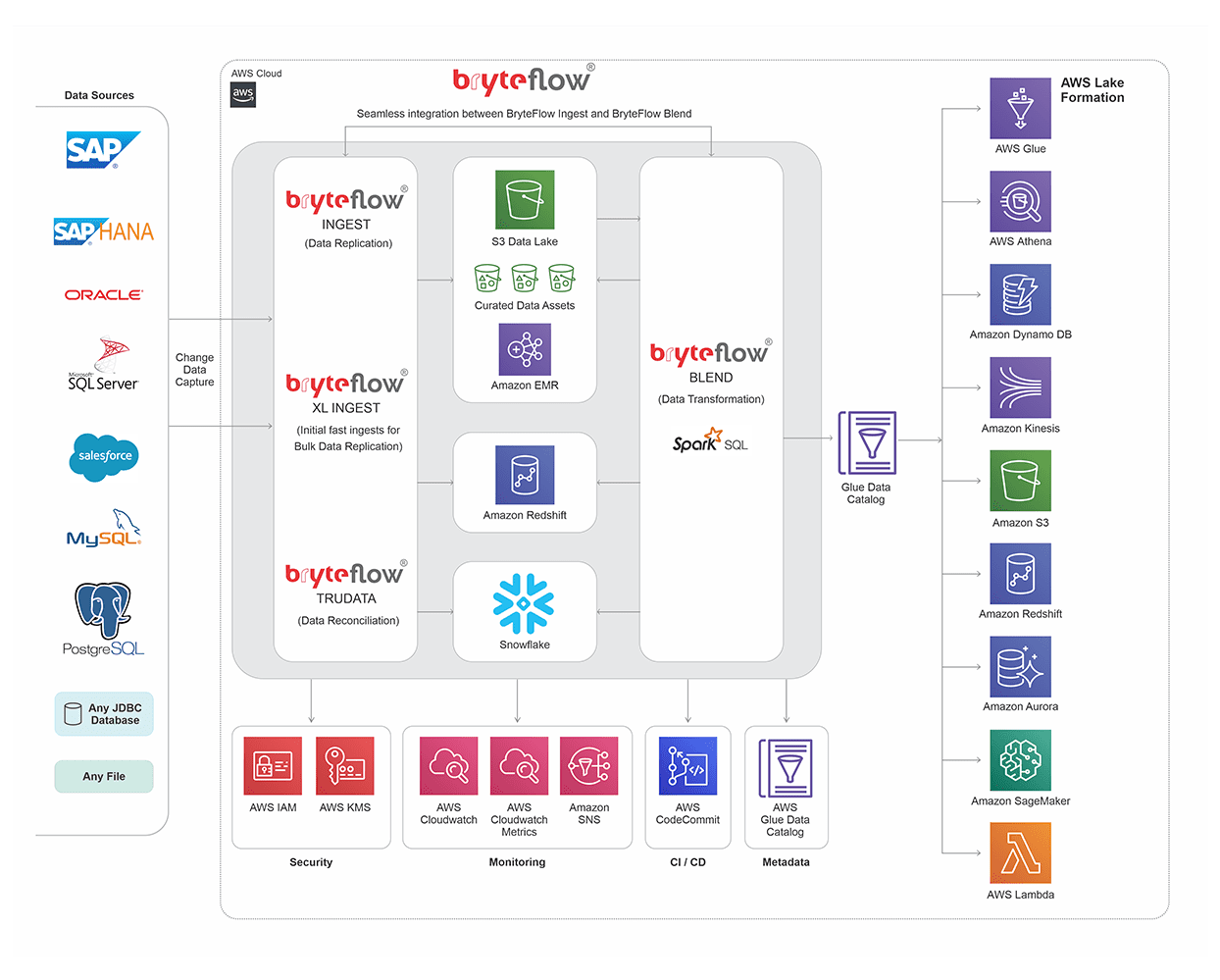
Let's dive into how you can effortlessly set up and optimize AWS Data Lake for your Amazon Redshift needs.
Trust me, your data storage strategy is about to get a whole lot smarter!
AWS Data Lake Setup
If you've ever wondered how to bridge the gap between Redshift and AWS Data Lake, you're in the right place. It all starts with a stellar AWS Data Lake setup.
Imagine it as building a foundation that supports your data analytics with ease. Create an S3 bucket to seamlessly store your CSV files.
Once you've done that, upload your CSV files into this S3 bucket using the AWS CLI or simply clicking the Upload button. How easy is that?
From there, the magic unfolds. You need a database within AWS Glue. Once your database is in place, integrate tables using AWS Glue's brilliant crawler feature.
This will scan your data and create metadata tables in Glue—easy peasy!
Configuring Redshift for Data Lake Integration
Moving on to the big leagues, let's chat about configuring Redshift for integration with your AWS Data Lake. Trust me, this part is where it gets exciting!
Begin by setting up your Redshift Cluster. It’s not as daunting as it sounds.
For those wondering about using AWS Data Pipeline to efficiently load CSV data into Redshift tables, I've got you covered in just a few steps.
First, follow steps one through five in the AWS Data Lake setup to prepare your data in S3 and Glue.
Then, with your data pipelines linked to Redshift, you can perform seamless data transformations and load operations. It's a game changer for boosting efficiency and keeping operations smooth.
Data Lake Optimization Strategies
Optimizing your data lake isn't just recommended; it's vital. So, what makes data lake optimization crucial? Simple tweaks bring profound advantages.
Ensure that your data storage strategies focus on cost efficiency, data accessibility, and security.
A frequently asked question is the difference between Redshift and Redshift Spectrum.
Here’s the scoop: Amazon Redshift Spectrum is an exciting extension allowing you to run queries against your data on Amazon S3 without moving the data into Redshift tables.
This means you save valuable time and resources! If you haven’t tried it yet, now might just be the right time.
Benefits of Integration
Imagine having a high-performance sports car in your data toolkit. That's what integrating Redshift with AWS Data Lake feels like. It's all about speed, efficiency, and smooth operation.
Redshift integrates wonderfully with other AWS services. Picture this: you can push data easily from Amazon S3 or tap into CloudWatch with ease. There are no bumps, just a smooth drive.
Redshift also works seamlessly with DynamoDB.
This gives you a powerful set of tools for all your data management needs. While Snowflake helps with Apache and BI tools like Qlik and Tableau, Redshift's close relationship with AWS really shines in some workflows.
Best Practices for Integration
Starting with data integration is exciting but needs smart planning. Think of it as tuning your engine for the best performance.
Ensure your data lake follows good governance principles. Using tools like data lake governance solutions can help. This isn’t just about security; it’s about setting up for future success.
Use AWS Glue Data Catalog for easy access.
Registering data with Lake Formation lets you efficiently query using Redshift Spectrum and other AWS services. Lake Formation provides excellent security, a must-have for any data engineer.
Security and Governance
Protect your data like it's Fort Knox. Data governance is essential for privacy and maintaining trustworthiness.
Lake Formation supports Redshift, adding another security layer over your data assets. It's crucial for compliance and brings peace of mind.
With governance solutions in your Redshift and AWS Data Lake setup, you stay compliant and strengthen your data defenses, guarding against potential breaches.
Summary of Integration Process
Have you ever thought about connecting Redshift to S3? Well, let me tell you, it's absolutely possible! Integrating Amazon Redshift with an AWS Data Lake, particularly Amazon S3, is a breeze.
Here's how it works: think of S3 as a handy staging area. You store your data there first, and then it journeys to Redshift.
It's super simple. You just drag and drop the database destination in your data pipeline designer.
Then, pick Amazon Redshift from the menu and pop in your credentials. Honestly, it's like magic when it all comes together!
By setting up this integration, you're creating a data ecosystem that's not only efficient but also ready to grow with you.
A Redshift cluster is created in one Availability Zone (AZ), providing a solid foundation for managing tricky datasets.
Future Prospects
Let's gaze into the future of AWS big data management. Redshift is a true powerhouse of flexibility and scalability.
Add high availability to the equation, and you've got a game-changer on your hands. It's especially useful for areas like financial services.
The thought of multi-AZ clusters adds a layer of security for operations. It's what makes Redshift adaptable as data demands change.
The big vision? Seamless integration and high availability everywhere. Envision your data setup working like a dream, with no glitches—just smooth operations.
Thanks to the Redshift and AWS Data Lake duo, this vision isn't just a dream—it's reality.
References
Subscribe to my newsletter
Read articles from Arpit Shrivastava directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arpit Shrivastava
Arpit Shrivastava
I'm Arpit, Co-Founder of ScroBits. I love talking about IoT, SaaS and Cloud DevOps. We make IT outsourcing fun and effective with our MERN stack expertise. When not in the tech world, I enjoy plogging, mountaineering, and working out. Ready to transform your business? Let's chat and make tech magic happen.