Spark 메모리 할당과 Databricks의 워커 노드 메모리 관리
 DOHEE KIM
DOHEE KIM시작하면서
매번 executor.memory 설정을 조정할 때마다 최대 메모리 할당 오류가 발생하여, 실제로 Databricks가 워커 노드의 메모리를 어떻게 할당하는지 기록해 두기로 했다. Spark에서의 메모리 관리와 Databricks에서 제공하는 추가적인 최적화 방식을 이해하면, 효율적인 클러스터 관리와 성능 최적화에 큰 도움이 될 것이다.
Spark에서 메모리 할당되는 기본 방식
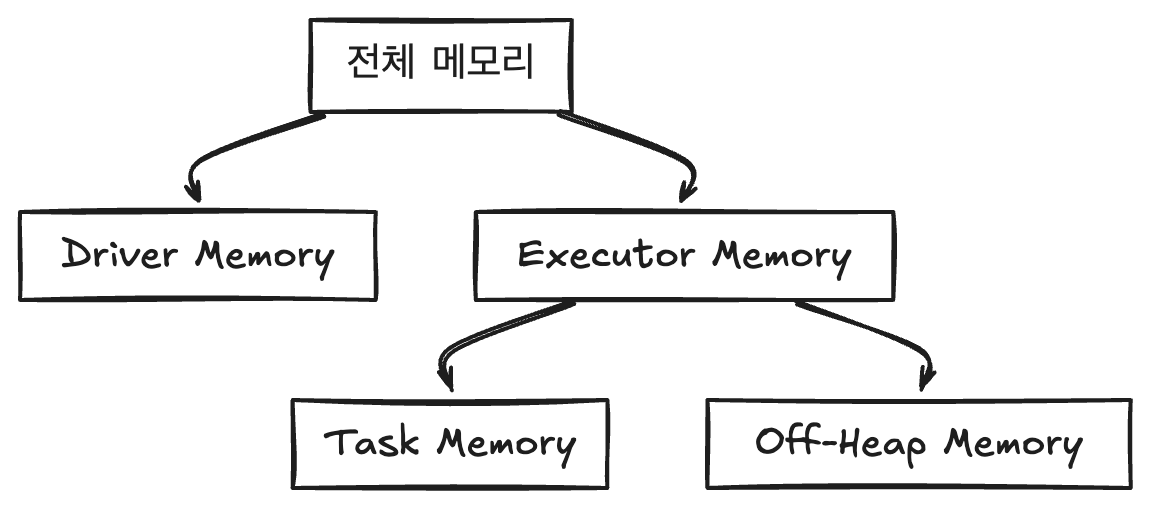
Spark에서 메모리는 여러 요소로 나뉘어 할당된다. 기본적으로 각 워커 노드에서 할당된 메모리는 다음과 같이 구분된다:
Executor Memory: 각 Executor가 작업을 수행할 때 사용하는 메모리이다. 이 메모리는 데이터 처리를 위한 Task가 사용하며, 과도한 메모리 사용 시 Out Of Memory(OOM) 오류가 발생할 수 있다.
Driver Memory: Spark Driver가 사용하는 메모리로, 클러스터와의 상호작용, 작업 스케줄링 및 작업 상태 관리를 담당한다.
Off-Heap Memory: JVM의 Heap 메모리 외부에서 사용되는 추가적인 메모리로, 필요에 따라 활성화할 수 있다. 이를 통해 Heap 사용량을 줄이고 안정적인 성능을 유지할 수 있다.
Databricks에서의 메모리 할당 방식
Databricks에서는 메모리 사용이 보다 세밀하게 관리되며, 효율성을 극대화하기 위한 추가적인 최적화가 이루어진다. Databricks에서 워커 노드의 메모리 할당은 다음과 같은 방식으로 이루어진다:
Kernel 메모리: 전체 인스턴스 메모리의 약 3%가 Kernel 용도로 예약된다. 이는 시스템 수준의 프로세스와 노드 운영을 위한 필수 메모리이다.
Node-Level Service: 노드 수준의 서비스에서 사용하는 메모리로, 약 4800MB가 할당된다. 이는 Databricks 플랫폼의 모니터링 및 관리 기능을 위해 사용된다.
사용 가능한 메모리:
할당 계산: 사용 가능한 메모리는
(전체 인스턴스 - (Kernel + Node-Level Service))로 계산된다.이 사용 가능한 메모리의 20%는 OOM 방지를 위해 LxC(Linux Container)에게 할당되고, 나머지 80%가 Spark Executor에 할당된다.
Photon 사용 시:
Off-Heap 메모리: Spark Executor 메모리의 75%가 Off-Heap 메모리로 사용된다. 이는 JVM의 Heap 부담을 줄여 안정성을 높인다.
Heap 메모리: 나머지 25%는 Heap 메모리로 사용되며, 이 안에는 Spark 예약 시스템 메모리 300MB가 포함된다.
예시로 살펴보기
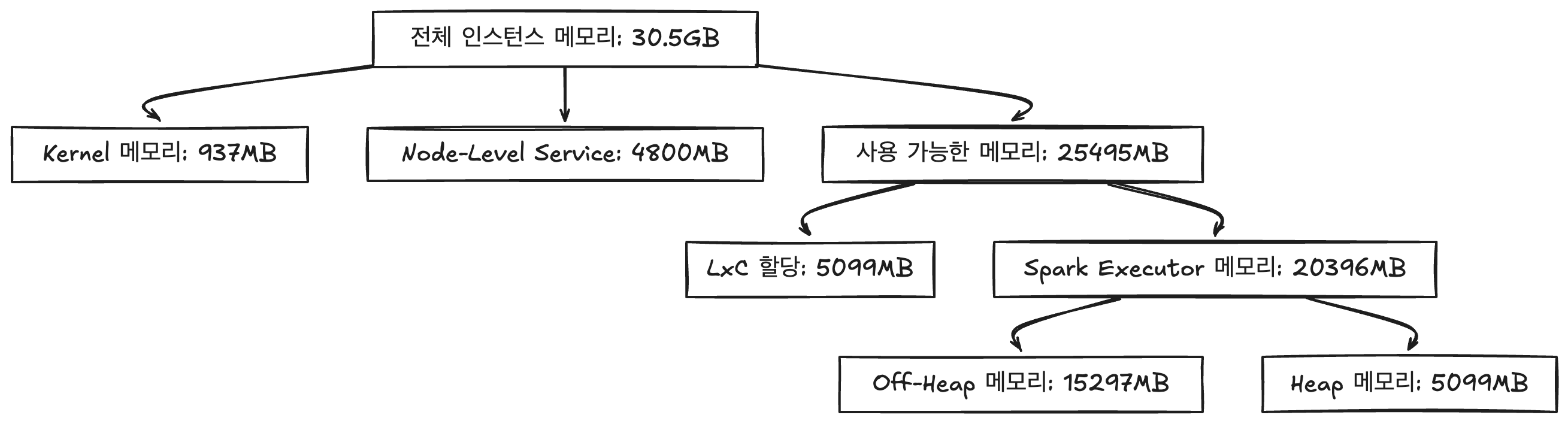
i3.xlarge 인스턴스
전체 인스턴스 메모리: 30.5GB (31232MB)
Kernel 메모리: 31232MB × 0.03 = 936.96MB (약 937MB)
Node-Level Service: 4800MB
사용 가능한 메모리: 31232MB - (937MB + 4800MB) = 25495MB
LxC 할당: 25495MB × 0.2 = 5099MB
Spark Executor 메모리: 25495MB × 0.8 = 20396MB
Photon 사용 시:
Off-Heap 메모리: 20396MB × 0.75 = 15297MB (약 15297MB)
Heap 메모리: 20396MB × 0.25 = 5099MB (약 5099MB, 여기에는 Spark 예약 시스템 메모리 300MB 포함)


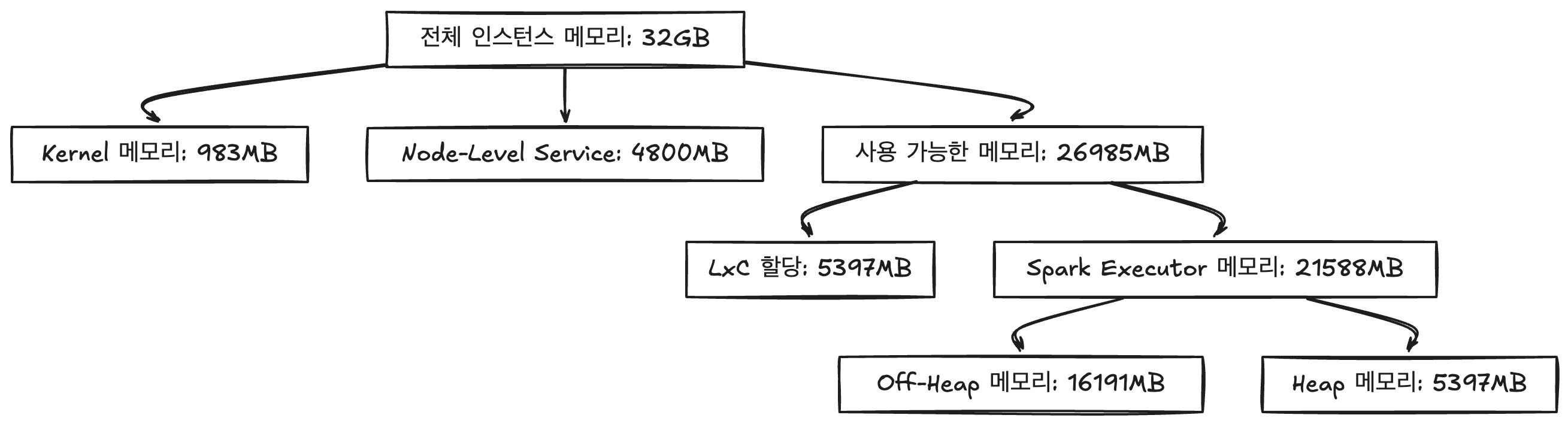
r6id.xlarge 인스턴스
전체 인스턴스 메모리: 32GB (32768MB)
Kernel 메모리: 32768MB × 0.03 = 983.04MB (약 983MB)
Node-Level Service: 4800MB
사용 가능한 메모리: 32768MB - (983MB + 4800MB) = 26985MB
LxC 할당: 26985MB × 0.2 = 5397MB
Spark Executor 메모리: 26985MB × 0.8 = 21588MB
Photon 사용 시:
Off-Heap 메모리: 21588MB × 0.75 = 16191MB (약 16191MB)
Heap 메모리: 21588MB × 0.25 = 5397MB (약 5397MB, 여기에는 Spark 예약 시스템 메모리 300MB 포함)


마무리하며
Databricks에서의 메모리 할당 방식을 이해하면, 각 작업의 메모리 요구 사항에 맞춰 Executor 메모리를 조정하고 효율적인 리소스 관리를 할 수 있다. 특히 Photon 사용 시 Off-Heap과 Heap 메모리의 비율을 이해하면, Spark 작업의 안정성을 높이고 성능을 극대화하는 데 도움이 된다. 이러한 메모리 관리 전략을 통해 클러스터 리소스를 최적화하고 작업 성능을 향상시킬 수 있을 것이다.
참고자료
https://kb.databricks.com/en_US/clusters/spark-shows-less-memory
Subscribe to my newsletter
Read articles from DOHEE KIM directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
DOHEE KIM
DOHEE KIM
재밌는 거 잘하고 싶은 개발자입니다