Large Language Model - Part 1
 Dharshini Sankar Raj
Dharshini Sankar RajAn LLM (Large Language Model) is a neural network designed to understand, generate, and respond to human-like text. These models are deep neural networks trained on massive amounts of text data, sometimes encompassing large portions of publicly available text on the internet.
Example: Let’s consider the spam classification task. In traditional machine learning, we might manually extract features from email text such as the frequency of certain trigger words (for example: “prize”, “win”, “free”, “cash prize”), the number of exclamation marks, use of all uppercase words, or the presence of suspicious links. In contrast to traditional machine learning, deep learning doesn’t require manual feature extraction. This means we do not need to identify and select the most relevant features for a deep learning model. (However, traditional machine learning and deep learning for spam classification still require the collection of labels, such as spam or non-spam, which need to be gathered by an expert or users).
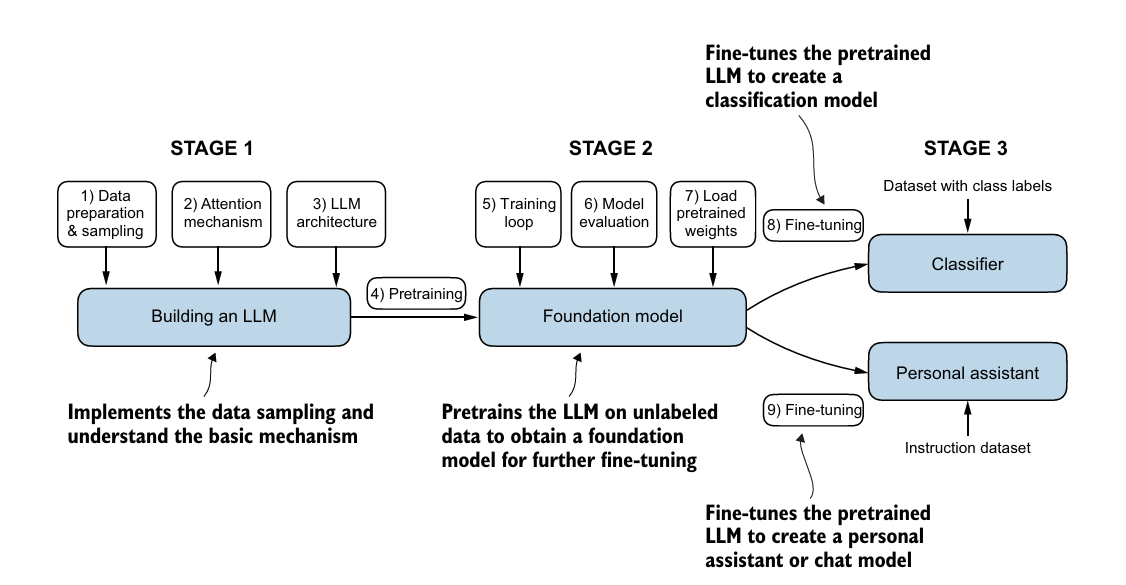
The three main stages of coding a large language model (LLM) are implementing the LLM architecture and data preparation process, pertaining an LLM to create a foundational model, and fine-tuning the foundational model to become a personal assistant-to-text classifier.
Imagine we want to create an LLM that can write movie reviews. In the pretraining stage, the model is trained on a large corpus of text such as movie scripts, articles, novels, social media posts, etc., These texts are unlabelled, meaning they are not categorized into specific tasks like positive or negative reviews. The model learns language patterns from the input, such as grammar, sentence structure, and word relationships. Think of this stage as a person reading thousands of books and articles to improve their overall understanding of language without focusing on any specific task. After this stage, the model can generate human-like text or complete a sentence.
Input: “The movie is so…”
Output: “The movie was so exciting and full of unexpected twists.”
After pretraining, we fine-tune the model on more specific, labelled data. Let’s discuss two types of fine-tuning with an example:
A. Instruction Fine-Tuning
For instruction fine-tuning, let’s say we want our LLM to become an expert at answering customer support queries. We fine-tune it using this tuning:
Input: “How can I reset my password"?”
Output: “You can reset your password by clicking on ‘Forgot Password’ and following these instructions”
The labelled dataset contains many such question-answer pairs that guide the LLM on how to respond to user interactions accurately. After fine-tuning, the model will understand how to follow specific instructions and provide useful, structured responses to user queries.
B. Classification Fine-Tuning
For classification fine tuning, suppose we want the LLM to identify spam emails. The model is trained on a labelled dataset where mails are marked as either ‘spam’ or ‘not spam’.
Email 1: “Congratulations, you have won $1 million” - Labelled as ‘spam’
Email 2: “ Your meeting is scheduled for 10 AM tomorrow” - Labelled as ‘not spam’.
After fine-tuning, the model can predict whether new emails are spam or not based on the content it has learned from the labelled examples.
Subscribe to my newsletter
Read articles from Dharshini Sankar Raj directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Dharshini Sankar Raj
Dharshini Sankar Raj
Driven by an intense desire to understand data and fueled by the opportunities presented during the COVID-19 pandemic, I enthusiastically ventured into the vast world of Python, Machine Learning, and Deep Learning. Through online courses and extensive self-learning, I immersed myself in these areas. This led me to pursue a Master's degree in Data Science. To enhance my skills, I actively engaged in data annotation while working at Biz-Tech Analytics during my college years. This experience deepened my understanding and solidified my commitment to this field.