What is Support Vector Machine (SVM)?
 Maen Alaraj
Maen Alaraj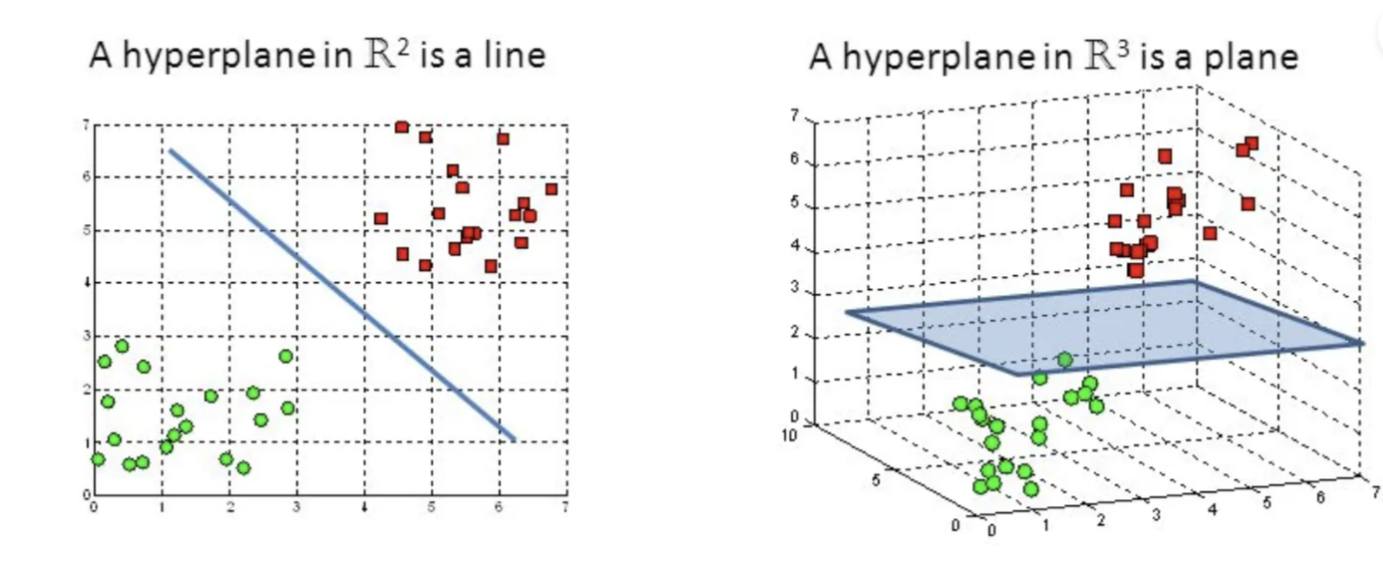
What is the meaning of the Support Vector Machine (SVM) algorithm in the field of Machine Learning (ML)? How can I improve the accuracy of SVM? What exactly is meant by the term "Hyperplane" used in this algorithm? Can we apply this algorithm in neuroscience-related fields such as Neuroinformatics and Computational Neuroscience?
SVM is one of the fundamental tools that every expert in the field of Machine Learning must master. This algorithm is widely used by specialists in data classification tasks.
In simple terms, SVM works by finding the best way to separate data into two or more groups by constructing a separating surface, known as a Hyperplane, between these groups. The "Support Vectors" are the data points closest to the Hyperplane, and these points are critical in the classification process. Any overlap between the data points requires recalculating the position of the Hyperplane. For example, when we need to separate two groups or categories of data, our goal is to find the Hyperplane that maximizes the margin between the two classes. Maximizing this distance facilitates higher accuracy in future data classification.
Therefore, we can conclude that the Hyperplane acts as the decision boundary that helps classify data. Data points should fall on either side of the Hyperplane, with each side corresponding to a specific group of data. But what if there is overlap between the data points, which often occurs in practical cases? If there is overlap between data points, it indicates that the features being used are insufficient to classify the data accurately. In such cases, additional features should be introduced to improve classification.
It is important to note that the dimensionality of the Hyperplane depends on the number of input features. If there are two features, the Hyperplane will be a line in two dimensions (x, y). If there are three features, it becomes a three-dimensional surface. However, it is preferable to keep the dimensions low to avoid the problem of overfitting. Overfitting means that while the SVM may perform well on the current dataset, it may not generalize well to future datasets.
For instance, in a research project published in 2013 (see link below), a method was developed to detect drowsiness levels in individuals aged 22 to 40 years. This method measured the complexity degree of brain waves (EEG signals) as the person begins to experience light drowsiness. Specifically, the more complex the brain waves in the occipital lobe (ranging from 8Hz to 13Hz, known as Alpha Waves), the stronger the indication of drowsiness. In this study, I used a two-dimensional Hyperplane based on the person's age and the complexity degree of their brain waves. The research results are currently used in Utsunomiya Hospital near Tokyo.
SVM has numerous applications, including sentiment analysis and handwritten digit recognition. In conclusion, tools such as SVM are extremely important in AI projects, especially for students seeking grants or funding. These projects often integrate multiple scientific disciplines to address specific problems, which is a key criterion for competitive project selection.
Subscribe to my newsletter
Read articles from Maen Alaraj directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Maen Alaraj
Maen Alaraj
I am a trilingual Research Scientist with extensive experience in Information Technology, specializing in Machine Learning applications in Brain-Computer Interface (BCI) and Robotics. Professionally, I have experience in both academia and industry, focusing on FinTech, AI, and Biomedical Engineering, particularly Computational Neuroscience in Japan. I have authored several publications in fields such as Computational Neuroscience, Machine Learning, Time Series Analysis, and FinTech. I am a SHARP-certified Robotics Developer, a member of IEEE, and part of the Research Association on Monetary Innovation and Community and Complementary Currency Systems (RAMICS).