A Beginner's Guide to Evaluating RAG Systems with LangSmith
 Manish Singh Parihar
Manish Singh Parihar
Retrieval-Augmented Generation (RAG) has become a cornerstone technique in leveraging large language models (LLMs) with proprietary or domain-specific data. This blog post will guide you through the process of integrating Langsmith evaluations into your RAG pipeline, providing a comprehensive approach to enhance your system's robustness and reliability.
Introduction to RAG
Retrieval-Augmented Generation (RAG) is a powerful technique that combines retrieval and generation to improve the quality of responses in natural language processing tasks. RAG systems consist of two main components:
Retriever: Retrieves relevant information needed to answer a query.
Generator: Generates the answer using the retrieved information.
RAG allows LLMs to access external knowledge sources, enabling them to generate more accurate and contextual answers while reducing hallucinations.
If you're interested in learning how to build both basic and advanced RAG systems, I recommend checking out Master RAG with LangChain: A Practical Guide for a detailed guide.
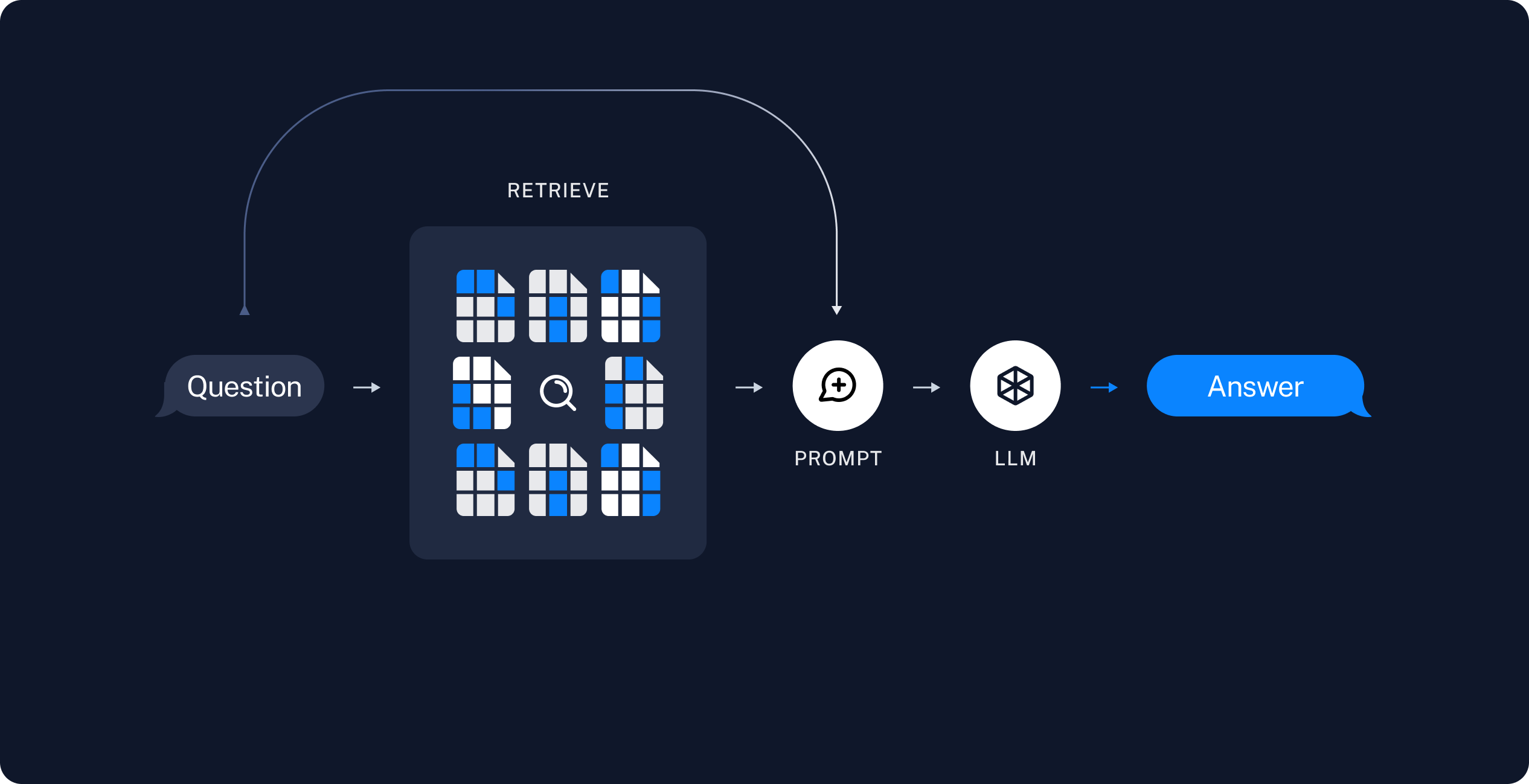
Image Source: LangChain Documentation
Why Use Langsmith Evaluations?
Langsmith provides a comprehensive platform for evaluating, monitoring, and improving RAG systems. By using Langsmith, you can:
Gain insights into the performance of your RAG components.
Identify areas for improvement.
Continuously monitor and enhance your system in production.
Apply various evaluation metrics to assess different aspects of your RAG pipeline.

Image Source: Langsmith
For a deeper dive into how Langsmith can enhance your RAG systems, check out the Guide to langsmith for expert insights and detailed examples.
Setting Up Your Environment
Before you begin, ensure you have the necessary prerequisites:
Install Required Packages
Before setting up your environment, make sure to install the necessary packages. If you're using a Google Colab notebook, you can run the following command in a cell:
!pip install -qU langsmith langchain-community langchain langchain_openai chromadb langchain-chroma
Set Up Environment Variables
Once the packages are installed, set up your environment variables:
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
_set_env("LANGCHAIN_API_KEY")
Building the RAG Pipeline
We'll use LangChain to create a retriever and a generator for our RAG pipeline. Here's how you can set it up:
Document Loading and Preparation
from bs4 import BeautifulSoup as Soup
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import RecursiveUrlLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Define the URL to load documents from
url = "https://python.langchain.com/v0.1/docs/expression_language/"
# Load documents using a recursive URL loader
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# Split documents into manageable chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Create a vector store from the document splits
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Set up the retriever from the vector store
retriever = vectorstore.as_retriever()
This section sets up the document loading and preparation process. It uses a RecursiveUrlLoader to fetch documents from a specified URL, then splits them into manageable chunks using a RecursiveCharacterTextSplitter. The split documents are then embedded and stored in a Chroma vector store, which is used to create a retriever for our RAG system.
For a more detailed explanation of Chroma DB, check out this informative YouTube video: Chroma DB: The AI-Native Open-Source Embedding Database. This video provides an in-depth look at Chroma DB's features.
RAG Bot Implementation
import openai
from langsmith import traceable
from langsmith.wrappers import wrap_openai
class RagBot:
def __init__(self, retriever, model: str = "gpt-4o-mini"):
self._retriever = retriever
# Wrap the OpenAI client for tracing
self._client = wrap_openai(openai.Client())
self._model = model
@traceable()
def retrieve_docs(self, question):
# Retrieve relevant documents for the given question
return self._retriever.invoke(question)
@traceable()
def invoke_llm(self, question, docs):
# Use the retrieved documents to generate a response
response = self._client.chat.completions.create(
model=self._model,
messages=[
{
"role": "system",
"content": "You are a helpful AI code assistant with expertise in LCEL."
" Use the following docs to produce a concise code solution to the user question.\n\n"
f"## Docs\n\n{docs}",
},
{"role": "user", "content": question},
],
)
return {
"answer": response.choices[0].message.content,
"contexts": [str(doc) for doc in docs],
}
@traceable()
def get_answer(self, question: str):
# Get the answer by retrieving documents and invoking the LLM
docs = self.retrieve_docs(question)
return self.invoke_llm(question, docs)
# Instantiate the RAG bot
rag_bot = RagBot(retriever)
# Get an answer to a sample question
response = rag_bot.get_answer("What is LCEL?")
# Print the first 150 characters of the answer
print(response["answer"][:150])
This section implements the RagBot class, which encapsulates the core functionality of our RAG system:
The
retrieve_docsmethod uses the retriever to fetch relevant documents for a given question.The
invoke_llmmethod generates a response using the OpenAI language model, incorporating the retrieved documents as context.The
get_answermethod combines document retrieval and LLM invocation to produce the final answer.
The @traceable() decorator is used to enable tracing with Langsmith, allowing for detailed performance monitoring and evaluation.
RAG System Overview
This setup creates a Retrieval-Augmented Generation (RAG) system that leverages LangChain for document retrieval and OpenAI's language model for response generation. The system is designed to handle questions related to the content of the loaded documents, such as "What is LCEL?" or any other query that can be answered using the provided documentation.
By combining efficient document retrieval with powerful language generation, this RAG system can provide accurate and contextually relevant answers to user queries, enhancing the overall quality and reliability of the responses.
Creating the Dataset for Evaluation
To effectively evaluate your RAG system, you need a high-quality dataset of question-answer pairs. This dataset serves as the foundation for assessing your system's performance. Let's walk through the process of creating such a dataset using Langsmith:
from langsmith import Client
# Define your QA pairs
inputs = [
"How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?",
"How can I make the output of my LCEL chain a string?",
"How can I apply a custom function to one of the inputs of an LCEL chain?",
]
outputs = [
"Use RunnablePassthrough. from langchain_core.runnables import RunnableParallel, RunnablePassthrough; from langchain_core.prompts import ChatPromptTemplate; from langchain_openai import ChatOpenAI; prompt = ChatPromptTemplate.from_template('Tell a joke about: {input}'); model = ChatOpenAI(); runnable = ({'input' : RunnablePassthrough()} | prompt | model); runnable.invoke('flowers')",
"Use StrOutputParser. from langchain_openai import ChatOpenAI; from langchain_core.prompts import ChatPromptTemplate; from langchain_core.output_parsers import StrOutputParser; prompt = ChatPromptTemplate.from_template('Tell me a short joke about {topic}'); model = ChatOpenAI(model='gpt-4o-mini') #gpt-4o or other LLMs can be used here; output_parser = StrOutputParser(); chain = prompt | model | output_parser",
"Use RunnableLambda with itemgetter to extract the relevant key. from operator import itemgetter; from langchain_core.prompts import ChatPromptTemplate; from langchain_core.runnables import RunnableLambda; from langchain_openai import ChatOpenAI; def length_function(text): return len(text); chain = ({'prompt_input': itemgetter('foo') | RunnableLambda(length_function),} | prompt | model); chain.invoke({'foo':'hello world'})",
]
# Create QA pairs
qa_pairs = [{"question": q, "answer": a} for q, a in zip(inputs, outputs)]
# Initialize Langsmith client
client = Client()
# Define dataset parameters
dataset_name = "RAG_test_LCEL"
dataset_description = "QA pairs about LCEL (LangChain Expression Language)."
# Create the dataset
dataset = client.create_dataset(
dataset_name=dataset_name,
description=dataset_description,
)
# Add examples to the dataset
client.create_examples(
inputs=[{"question": q} for q in inputs],
outputs=[{"answer": a} for a in outputs],
dataset_id=dataset.id,
)
Explanation of the Dataset Creation Process
Defining QA Pairs:
We start by defining lists of
inputs(questions) andoutputs(answers) related to LCEL (LangChain Expression Language).These pairs are carefully crafted to cover various aspects of LCEL, ensuring a comprehensive evaluation of our RAG system.
Creating QA Pairs:
We combine the questions and answers into a list of dictionaries using a list comprehension.
This step prepares the data in a format suitable for Langsmith.
Initializing Langsmith Client:
- We create an instance of the Langsmith
Clientto interact with the Langsmith API.
- We create an instance of the Langsmith
Defining Dataset Parameters:
We specify a name (
"RAG_test_LCEL") and description for our dataset.This metadata helps in organizing and identifying the dataset within Langsmith.
Creating the Dataset:
Using the Langsmith client, we create a new dataset with the specified name and description.
This step establishes a container for our QA pairs in the Langsmith platform.
Adding Examples to the Dataset:
We use the
create_examplesmethod to populate the dataset with our QA pairs.The method takes separate lists for inputs (questions) and outputs (answers), along with the dataset ID.
This structure allows Langsmith to properly associate each question with its corresponding answer.
Once created, you can view and manage your dataset through the Langsmith interface. Here's an example of how your dataset might look:
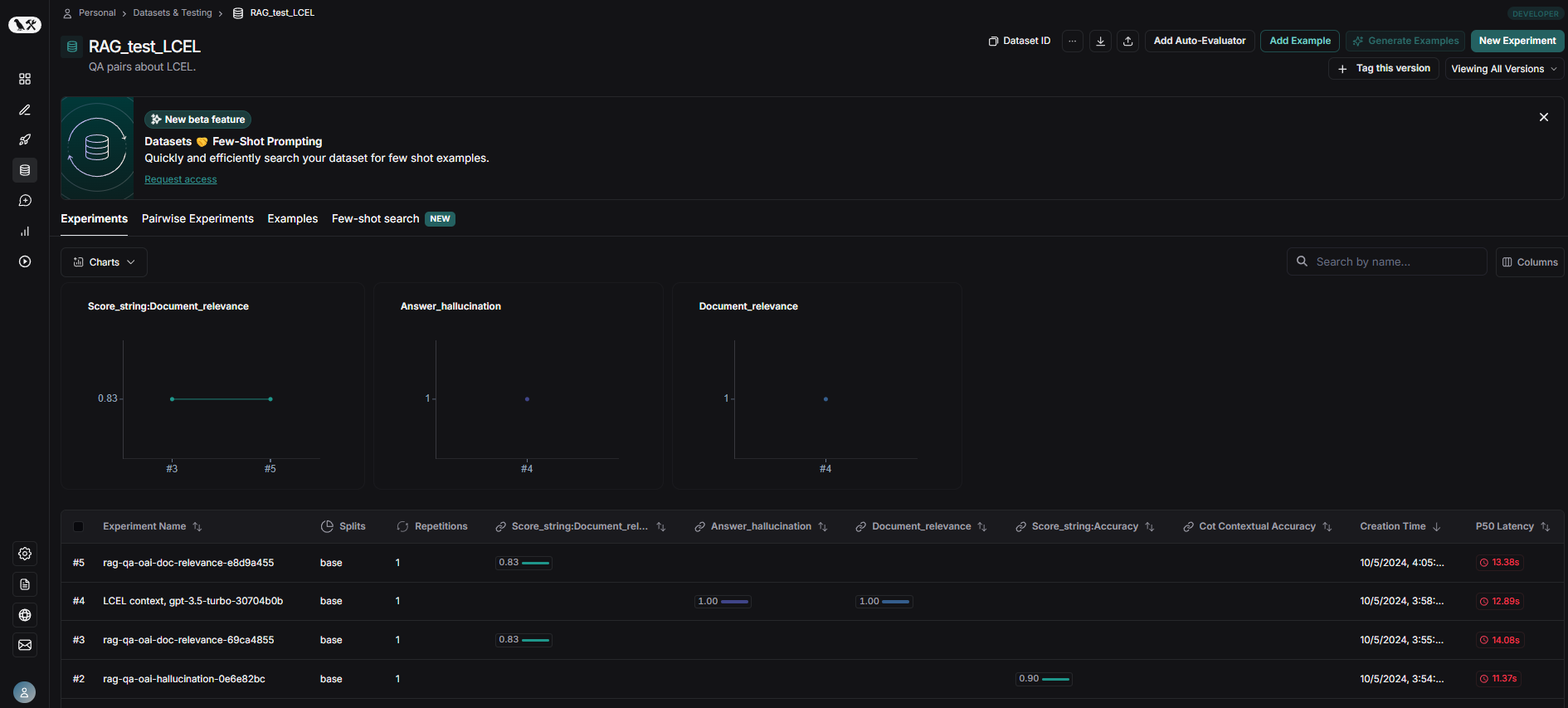
Image Source: Author
By creating a well-structured and comprehensive dataset, you set the foundation for a thorough evaluation of your RAG system. This dataset will be crucial in assessing various aspects of your system's performance, including accuracy, relevance, and contextual understanding.
Evaluating the RAG System
Effective evaluation of a Retrieval-Augmented Generation (RAG) system is crucial for ensuring its performance, accuracy, and reliability. Langsmith provides a comprehensive suite of evaluation metrics designed to thoroughly assess various aspects of your RAG system. These evaluations are essential for understanding how well your system performs in real-world scenarios and for identifying areas that require improvement.
In this blog, we'll focus on four primary types of RAG evaluation:
Response vs Reference Answer: This evaluation measures how similar or correct the RAG system's answer is compared to a ground-truth label. Metrics like correctness fall into this category, answering the question: "How accurate is the generated response relative to an expert-provided answer?"
Response vs Retrieved Documents: This evaluation focuses on the faithfulness of the response to the retrieved context and helps detect hallucinations. It answers the question: "To what extent does the generated response align with and accurately represent the information in the retrieved documents?"
Retrieved Documents vs Input: This evaluation measures the quality and relevance of the retrieved documents in relation to the input query. It assesses how effectively the system retrieves relevant information for a given query.
Hallucination Detection: This evaluation specifically targets the identification of information in the response that is not present in or supported by the retrieved documents. It helps answer the question: "Is the system generating information that isn't grounded in the provided context?"
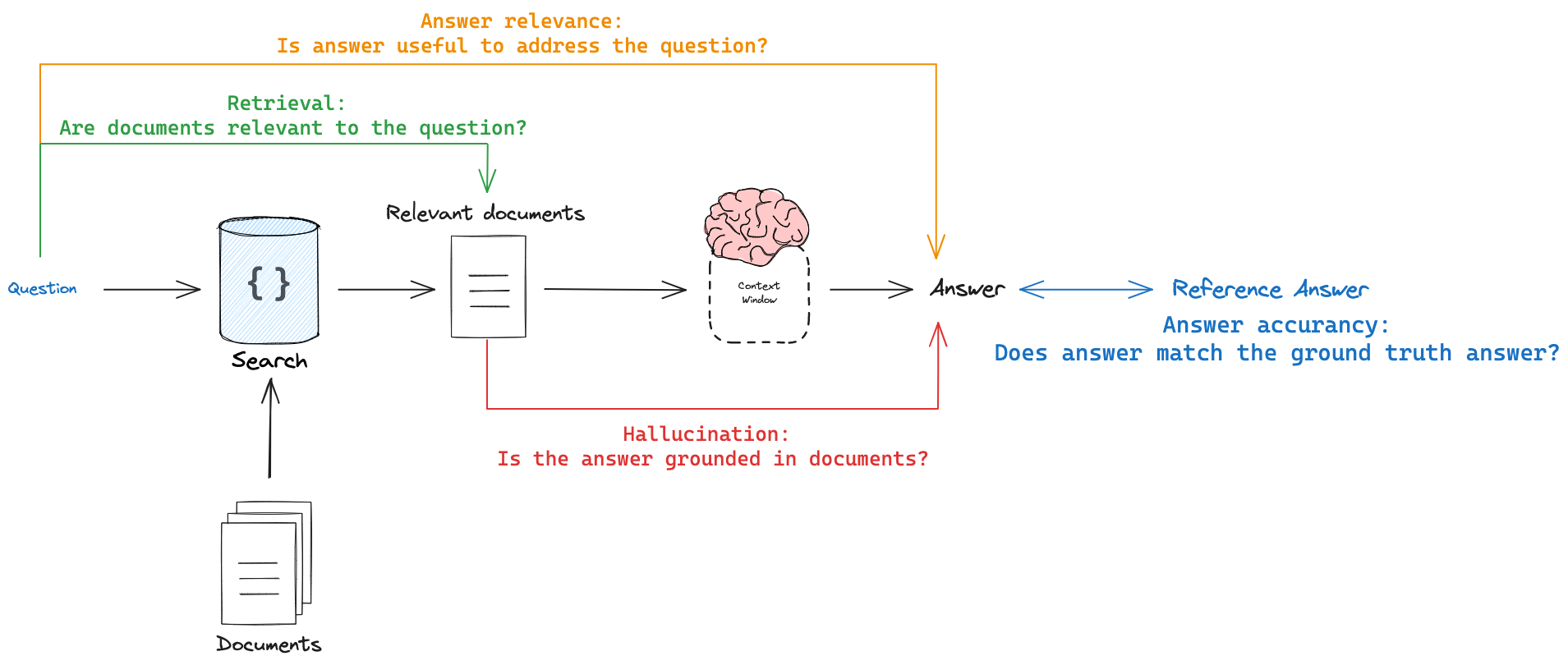
Image Source: LangChain Documentation
By implementing these three types of evaluation, you can gain a comprehensive understanding of your RAG system's performance across different dimensions:
Accuracy of responses
Faithfulness to source material
Effectiveness of document retrieval
Let's explore how Langsmith facilitates these evaluations, providing you with the tools to assess and improve your RAG pipeline systematically.
# RAG chain functions
def predict_rag_answer(example: dict):
"""Use this for answer evaluation"""
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"]}
def predict_rag_answer_with_context(example: dict):
"""Use this for evaluation of retrieved documents and hallucinations"""
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"], "contexts": response["contexts"]}
1. Response vs Reference Answer
This evaluation method compares the RAG system's generated answer to a pre-defined, expert-crafted reference answer. It's crucial for assessing the overall accuracy and quality of your system's outputs.
When to use: Implement this evaluation when you have a dataset of questions with known, high-quality answers. It's particularly valuable for:
Benchmarking your RAG system against human-level performance
Identifying systematic errors or biases in your model's outputs
Tracking improvements in answer quality over time as you refine your system
Key Metric: Correctness score, typically on a scale from 0 to 1, where 1 indicates a perfect match with the reference answer.
from langsmith.evaluation import LangChainStringEvaluator, evaluate
# Evaluator for comparing RAG answers to reference answers
qa_evaluator = [
LangChainStringEvaluator(
"cot_qa", # Using Chain-of-Thought QA evaluator
prepare_data=lambda run, example: {
"prediction": run.outputs["answer"], # RAG system's answer
"reference": example.outputs["answer"], # Ground truth answer
"input": example.inputs["question"], # Original question
},
)
]
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer,
data=dataset_name,
evaluators=qa_evaluator,
experiment_prefix="rag-qa-oai",
metadata={"variant": "LCEL context, gpt-4o-mini"},
)
2. Response vs Retrieved Docs (Hallucination Detection)
This evaluation assesses the faithfulness of the generated response to the information contained in the retrieved documents. It's essential for detecting and preventing hallucinations – instances where the model generates information not present in the source material.
When to use: Employ this method when:
Accuracy and reliability of information are paramount (e.g., in medical, legal, or financial applications)
You want to ensure your system isn't "making up" information
You need to maintain traceability between responses and source documents
Key Metric: Faithfulness score, typically on a scale from 0 to 1, where 1 indicates perfect alignment with the retrieved documents.
from langsmith.evaluation import LangChainStringEvaluator, evaluate
# Evaluator for detecting hallucinations
answer_hallucination_evaluator = LangChainStringEvaluator(
"labeled_score_string",
config={
"criteria": {
"accuracy": """Is the Assistant's Answer grounded in the Ground Truth documentation?
A score of [[1]] means the answer is not at all based on the documentation.
A score of [[5]] means the answer contains some information not in the documentation.
A score of [[10]] means the answer is fully based on the documentation."""
},
"normalize_by": 10, # Normalize scores to a 0-1 scale
},
prepare_data=lambda run, example: {
"prediction": run.outputs["answer"], # RAG system's answer
"reference": run.outputs["contexts"], # Retrieved documents
"input": example.inputs["question"], # Original question
},
)
experiment_results = evaluate(
predict_rag_answer_with_context,
data=dataset_name,
evaluators=[answer_hallucination_evaluator],
experiment_prefix="rag-qa-oai-hallucination",
metadata={"variant": "LCEL context, gpt-4o-mini"},
)
3. Retrieved Docs vs Input (Document Relevance)
This evaluation focuses on the quality and relevance of the documents retrieved by your system in response to a given query. It helps assess and optimize the retrieval component of your RAG pipeline.
When to use: This method is crucial when:
You have a large corpus of documents and need to ensure efficient retrieval
You want to improve the precision and recall of your document retrieval process
You're fine-tuning your retrieval model or adjusting retrieval parameters
Key Metrics:
Relevance score (e.g., on a scale from 0 to 1)
Other potential metrics: NDCG (Normalized Discounted Cumulative Gain), Mean Reciprocal Rank, or Precision@k
from langsmith.evaluation import LangChainStringEvaluator, evaluate
import textwrap
# Evaluator for assessing document relevance
docs_relevance_evaluator = LangChainStringEvaluator(
"score_string",
config={
"criteria": {
"document_relevance": textwrap.dedent(
"""Score the relevance of retrieved documents to the question:
[[1]]: No retrieved documents contain useful information.
[[5]]: Some documents partially answer the question.
[[10]]: The question can be fully answered using the first retrieved document(s)."""
)
},
"normalize_by": 10, # Normalize scores to a 0-1 scale
},
prepare_data=lambda run, example: {
"prediction": run.outputs["contexts"], # Retrieved documents
"input": example.inputs["question"], # Original question
},
)
experiment_results = evaluate(
predict_rag_answer_with_context,
data=dataset_name,
evaluators=[docs_relevance_evaluator],
experiment_prefix="rag-qa-oai-doc-relevance",
metadata={"variant": "LCEL context, gpt-4o-mini"},
)
4. Hallucination Detection
This evaluation specifically targets the identification of information in the response that is not present in or supported by the retrieved documents. It's crucial for ensuring the reliability and trustworthiness of your RAG system's outputs.
When to use: Implement this evaluation when:
You need to ensure high factual accuracy in your system's responses
You want to minimize the risk of generating false or unsupported information
You're fine-tuning your model or adjusting your RAG pipeline to reduce hallucinations
Key Metric: Binary hallucination score, where 1 indicates the answer is grounded in the retrieved facts, and 0 indicates potential hallucination.
from langchain_openai import ChatOpenAI
from langsmith.schemas import Example, Run
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
def answer_hallucination_grader(root_run: Run, example: Example) -> dict:
"""
A simple evaluator that checks if the answer is grounded in the documents
"""
# Get documents and answer
rag_pipeline_run = next(run for run in root_run.child_runs if run.name == "get_answer")
retrieve_run = next(run for run in rag_pipeline_run.child_runs if run.name == "retrieve_docs")
doc_txt = "\n\n".join(doc.page_content for doc in retrieve_run.outputs["output"])
generation = rag_pipeline_run.outputs["answer"]
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: int = Field(description="Answer is grounded in the facts, 1 or 0")
# LLM with function call
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 1 or 0, where 1 means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
score = hallucination_grader.invoke({"documents": doc_txt, "generation": generation})
return {"key": "answer_hallucination", "score": int(score.binary_score)}
from langsmith.evaluation import evaluate
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer,
data=dataset_name,
evaluators=[answer_hallucination_grader],
experiment_prefix="rag-qa-oai-hallucination",
metadata={"variant": "LCEL context, gpt-4o-mini"},
)
By implementing these four evaluation methods, you create a robust framework for assessing and improving your RAG system. Each method targets a different aspect of the RAG pipeline:
Response Accuracy: Ensures your system provides correct information compared to reference answers.
Response Faithfulness: Guarantees that responses are grounded in retrieved data and detects potential hallucinations.
Retrieval Quality: Optimizes the document retrieval process by assessing relevance to the input query.
Hallucination Detection: Specifically identifies and quantifies instances where the system generates information not supported by the retrieved documents.
Together, these evaluations provide a comprehensive view of your RAG system's performance, enabling data-driven improvements and ensuring that your system remains accurate, reliable, and relevant to user needs.
Remember to regularly review the evaluation results in the Langsmith interface, where you can visualize trends, compare different versions of your system, and make data-driven decisions to enhance your RAG pipeline's performance.
By continuously monitoring and optimizing these aspects, you can iteratively refine your RAG system, making it more robust, accurate, and suitable for real-world applications across various domains.
Conclusion
Integrating Langsmith evaluations into your RAG pipeline is a crucial step towards building a robust, reliable, and high-performing system ready for real-world applications. The comprehensive evaluation approach we've outlined empowers you to:
Assess the accuracy of your generated answers against reference responses.
Ensure faithfulness of responses to retrieved documents, mitigating hallucinations.
Evaluate the relevance and quality of your document retrieval mechanism.
By continuously monitoring these aspects, you can iteratively refine your RAG system, enhancing its ability to deliver accurate, contextually relevant, and trustworthy responses to user queries. Langsmith's powerful platform streamlines this process, making the development and optimization of RAG systems more efficient and data-driven.
Remember, evaluation is not a one-time task but an ongoing process. As you refine your system, introduce new data, or adapt to changing user needs, regular evaluation will help you maintain and improve performance over time.
Resources and References
Chroma DB: The AI-Native Open-Source Embedding Database (YouTube Video)
LangChain Documentation: RAG Evaluation
Langsmith Documentation: RAG Evaluation Cookbook
Google Research: RAGAS: Automated Evaluation of Retrieval Augmented Generation Systems
By exploring these resources, you can stay at the forefront of RAG technology and continue to improve your systems. Remember to check the Langsmith documentation regularly for updates and new features that can enhance your evaluation processes.
Next Steps: Bringing AI into Your Business
Whether you're looking to integrate cutting-edge NLP models or deploy multimodal AI systems, we're here to support your journey. Reach out to us at contact@futuresmart.ai to learn more about how we can help.
Don't forget to check out our futuresmart.ai/case-studies to see how we've successfully partnered with companies to implement transformative AI solutions.
Let us help you take the next step in your AI journey.
Subscribe to my newsletter
Read articles from Manish Singh Parihar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by