Building a Time-Based Movie Recommendation System with BERT4Rec
 Pranjal Chaubey
Pranjal Chaubey
Movie recommendation systems have become an essential part of everyday digital experiences. From helping us find our next favorite Netflix binge to discovering hidden gems on YouTube, recommendation algorithms play a pivotal role. Today, we're diving into one such system: BERT4Rec, a powerful Transformer-based architecture designed specifically for sequential recommendation tasks.
In this article, we’ll walk through what BERT4Rec is, how it works, and use a movie recommendation example to show you how it performs in action.
What is BERT4Rec?
Simply put, BERT4Rec is a model that uses Bidirectional Encoder Representations from Transformers (BERT) to recommend items based on a user's sequential history of interactions. Just like how BERT predicts missing words in a sentence, BERT4Rec predicts missing or future items (in our case, movies) from a user’s historical list of watched items.
Here’s the gist of how it works:
Input: A list of movies a user has watched in the past.
Masking: Some movies are replaced with a
[MASK]token.Prediction: The model tries to predict the correct movies for the masked positions.
Once trained, the model can recommend the next movie based on a user’s current viewing history.
Architecture of BERT4Rec
BERT4Rec follows the Transformer architecture similar to that used in natural language processing (NLP) tasks. Below is a simplified architecture diagram of BERT4Rec:

Input Embeddings: Movies are represented as embeddings, capturing both their identities and some semantic features.
Positional Encoding: Since the order of movies is crucial in a user’s history, positional encodings are added to the movie embeddings.
Transformer Layers: These layers allow the model to capture relationships between movies across long sequences, which is useful for understanding patterns like "if a user watched X, they’ll probably like Y."
Prediction: After passing through the Transformer layers, the model predicts the masked movie tokens.
The Data
For this example, I used the MovieLens-25m dataset, which includes over 60,000 movies and 25 million user interactions. The dataset provides time-sorted movie sequences for each user, making it perfect for training a recommendation system like BERT4Rec.
Real-Life Example
To illustrate how the model performs, let's look at a few examples. Below are some users' previously watched movies and the recommendations BERT4Rec provides:
| Actual Movie | Predicted Movie |
| Pulp Fiction (1994) - Drama/Crime/Thriller | All About My Mother (1999) - Drama |
| Eternal Sunshine of the Spotless Mind (2004) | Talk to Her (2002) - Drama/Romance |
| Naqoyqatsi (2002) - Documentary | Breathless (1960) - Crime/Drama/Romance |
| 2046 (2004) - Drama/Fantasy/Romance | Bad Education (2004) - Drama/Thriller |
| Taxi 2 (2000) - Action/Comedy | Before Sunset (2004) - Drama/Romance |
Notice how the recommendations capture similar genres or themes. For example, someone who watched 2046 got a recommendation for Bad Education, which falls within the same drama and thriller genres. Similarly, someone who watched Eternal Sunshine of the Spotless Mind was recommended Talk to Her, another deep and emotional drama.
How BERT4Rec Learns
The power of BERT4Rec lies in its ability to model the user's preferences by learning from past sequences of movies. Let’s break down what happens under the hood:
Movie Encoding: Every movie in a user’s watch history is encoded as a vector. This encoding is learned during training and is updated with the context of other movies in the sequence.
Self-Attention: The self-attention mechanism is where the magic happens. It allows the model to focus on important parts of the movie history when making a recommendation. If you liked movie A and B, the model might consider those two when predicting the next movie.
Position Embedding: Since the order of movies matters (e.g., the last movie you watched says more about your next choice than the one you watched a year ago), positional embeddings are added to each movie's vector.
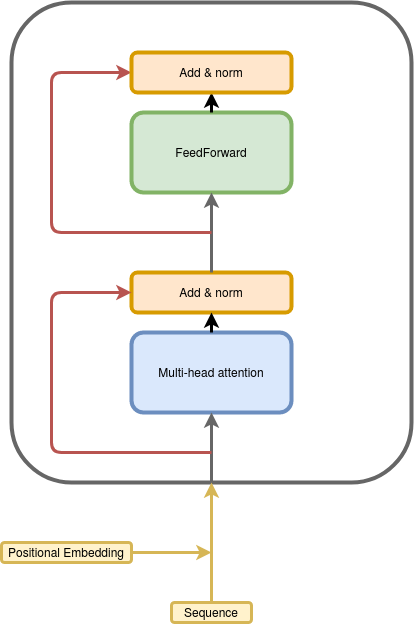
Image Credit
Image by Youness Mansar on Medium Article
Observations and Results
During testing, I noticed that the recommendations closely align with the user's taste. For example, one user who loves adventure and fantasy films received a recommendation for Pirates of the Caribbean, Avatar, and Harry Potter, all of which are spot-on choices for fans of that genre.
Here’s another example:
Scenario 1: Drama/Romance
User History:
Eternal Sunshine of the Spotless Mind (2004)
Lost in Translation (2003)
Model Recommendation:
Talk to Her (2002)
Before Sunset (2004)
These recommendations match the user's history of preference for deep, emotionally engaging stories.
Why BERT4Rec Stands Out
The strength of BERT4Rec lies in its ability to model long-term dependencies. Unlike traditional models that might focus only on the last few movies you watched, BERT4Rec considers the entire history. This is especially useful for nuanced recommendations where subtle preferences play a role.
Moreover, BERT4Rec's self-attention mechanism captures the relationships between movies across different points in time, making it more adaptive and precise in its predictions.
Evaluating the Model
To evaluate the model, I used standard metrics like nDCG@k (normalized discounted cumulative gain) and Precision@k. These metrics measure how well the model ranks the recommended items and how many of the recommendations are actually correct.
Here are the results:
nDCG@10: 0.34
This means the model is somewhat effective at ranking relevant items, but there’s still room for improvement in placing the best recommendations at the top.Hit Rate@10: 0.296
This suggests that 2 out of 10 recommended movies were correct.Precision@10: 0.2
Precision was a bit low, which means I might need to tweak the model further.
A Surprising Genre-Based Insight!
One of the coolest things I discovered was that even though the model wasn’t fed any genre-related information, it still did a pretty good job of recommending movies in related genres! Here’s the performance when I looked at genre-based recommendations:
Genre-Based Precision@10: 0.75
Genre NDCG@10: 0.6
This means the model was surprisingly good at suggesting movies in similar genres, even without explicit genre data. Pretty neat, right?
Conclusion
In the end, building a time-based movie recommendation system with BERT4Rec was both challenging and rewarding. While the model wasn’t perfect in predicting the exact next movie, it did a fantastic job of understanding broader patterns, especially in genre-based recommendations. By using a Transformer-based architecture, we can predict a user's next favorite movie with greater accuracy and flexibility. The model can handle large-scale datasets like MovieLens and deliver recommendations that align well with user preferences.
Want to dive deeper? Check out the research paper that introduced BERT4Rec and explore the world of sequential recommendations!
References
Sun, Fei, et al. "BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer." Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM 2019).
This research paper introduces BERT4Rec, which uses the Transformer architecture for sequential recommendation tasks.Mansar, Youness. "Build Your Own Movie Recommender System Using BERT4Rec." Towards Data Science, 2021.
A step-by-step guide on implementing a movie recommendation system using BERT4Rec with PyTorch.
Subscribe to my newsletter
Read articles from Pranjal Chaubey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pranjal Chaubey
Pranjal Chaubey
Hey! I'm Pranjal and I am currently doing my bachelors in CSE with Artificial Intelligence and Machine Learning. The purpose of these blogs is to help me share my machine-learning journey. I write articles about new things I learn and the projects I do.