Apache Hadoop Dora Metrics: Disorganized Workflow with Prolonged Lead Times
 Rajni Rethesh
Rajni Rethesh
From social media posts and sensor data on machinery to financial transactions, tax info, defense stats, public health updates, and medical records – there's a whole lot of data flying around in the online world. This data can come in all shapes and forms: structured, unstructured, or somewhere in between.
To make sense of it all, you need a place to store and process it. That’s where Apache Hadoop steps in. It’s an open-source platform built to handle and process massive amounts of both structured and unstructured data like a pro.
Since data is such a big deal today, and with Apache Hadoop playing a key role in processing massive datasets, I wanted to explore how efficiently they manage their own repository’s engineering pipeline.
We used Middleware OSS to get insights into their Dora Metrics. Dora metrics are a set of key performance indicators used to measure the efficiency and effectiveness of software development and DevOps teams, focusing on deployment frequency, lead time for changes, change failure rate, and time to restore service.

What’s Been Happening in Apache Hadoop: Feature Upgrades and Performance Boosts
Apache Hadoop predominantly focuses on feature enhancements and performance tweaks lately. Recent contributions include bug fixes, better testing, and some solid infrastructure upgrades—all thanks to over 15 active contributors including raphaelazzolini, zhengchenyu, pan3793, to name a few who have been actively working on the repo. Also, Highlights like multi-cloud storage support (HADOOP-19205) and encryption updates (HADOOP-19197) showcase the range of work being done.
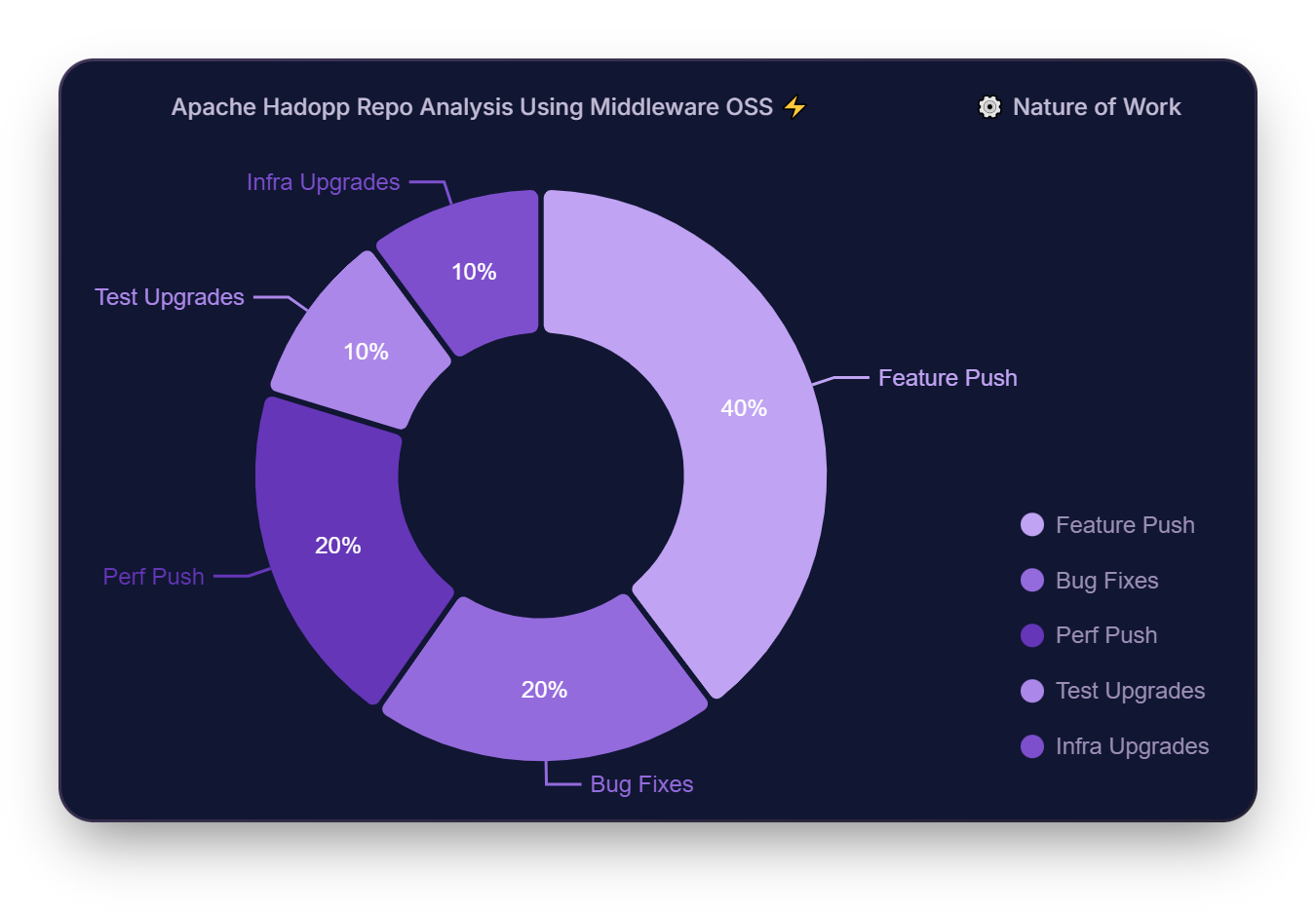
Apache Hadoop Dora Metrics: Disorganized Workflow with Prolonged Lead Times
The repository has a decent number of contributors, precisely speaking around 602. However, they couldn’t do justice to their lead time. Let’s see what their numbers say:
With a lead time of 342, 464, and 309 hours for July, August, and September 2024, Apache Hadoop painted a disappointing picture.
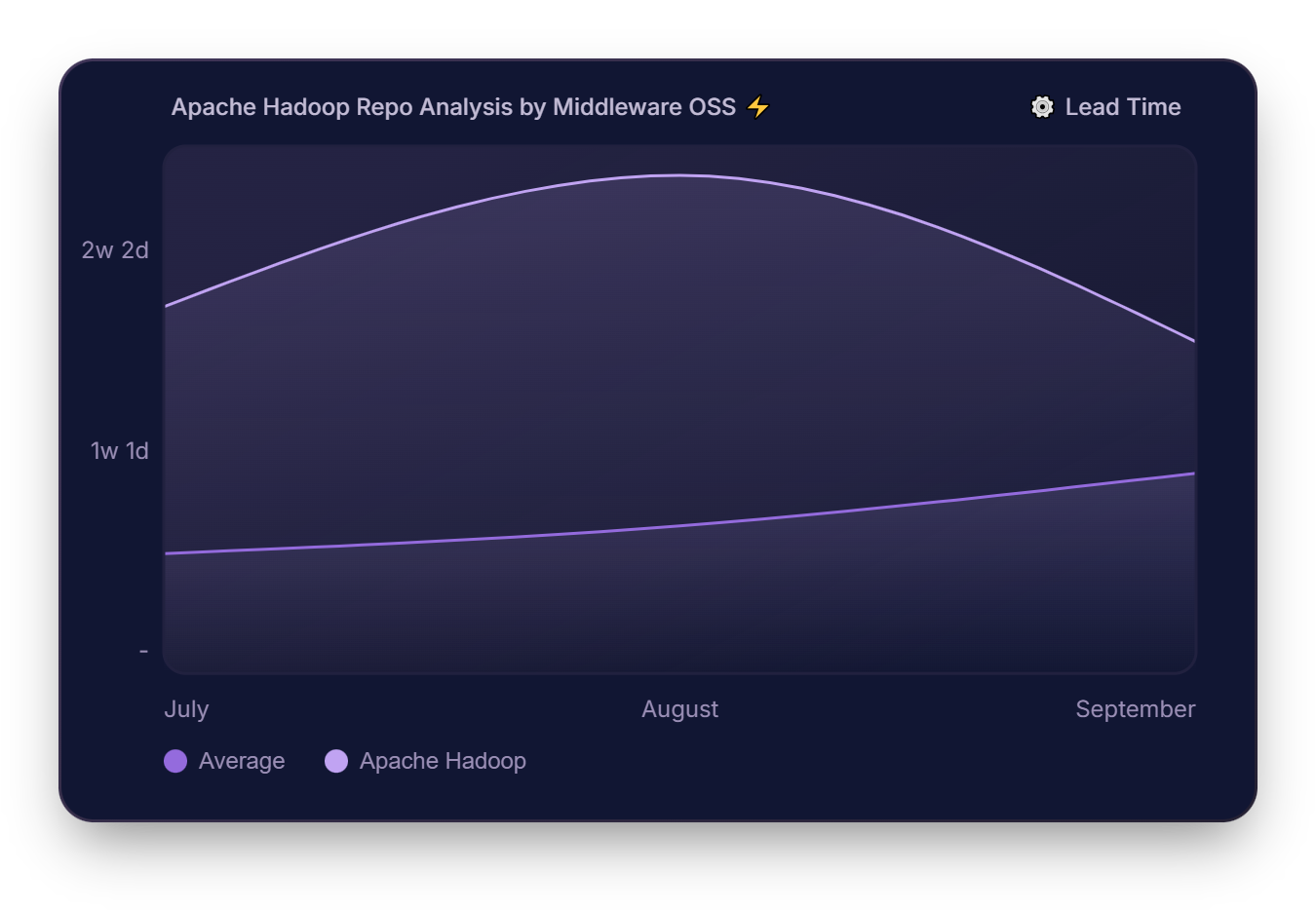
Long delays in first response, rework, and merge times were the main reasons for the extended cycle time, ultimately resulting in a poor lead time.
| Metrics (in hours) | July | August | September | August | September |
| First Response | 117 | 150 | 151 | ||
| Rework Time | 112 | 100 | 72 | ||
| Merge Time | 113 | 213 | 83 | ||
| Cycle Time | 41 | 461 | 307 |
The Apache Hadoop ecosystem is constantly evolving with new tools being developed to meet the demands of big data processing.
However, their contributor community remains relatively small, with only about 602 members.
Given their ambitious goals to stay ahead in the rapidly growing big data landscape, the pace of community growth is still slow and doesn't quite match up to their big aspirations. This leads to sluggishness in their engineering pipeline.
Tackling their Snail-pace
Inviting more contributors: They can invite more developers onboard, train, and encourage them to participate in the engineering efforts of the repository. They can learn a trick or two from Kubernetes. Kubernetes has established an excellent contributor experience with a comprehensive set of guidelines and resources, including a dedicated "Contributor Guide" to help newcomers navigate the project and get involved effectively.
Documentation: They aren’t dedicating enough time and effort to improve their documentation. In fact, 0% of their time has been spent updating documentation over the past three months, which is concerning, especially since they’re regularly introducing new features and investing significant resources in fixing bugs.
Must read: Key Metrics for Measuring Engineering Team Success
Apache Hadoop Dora Metrics: Sluggish Engineering Workflow
These are thrilling times as new technologies evolve every day. With all the buzz surrounding big data, Hadoop really needs to step up its game to manage data influx more effectively and efficiently.
If you find these learnings interesting, we’d really encourage you to give a shot at Dora Metrics using Middleware Open Source. You could follow this guide to analyze your team or write to our team at productivity@middlewarehq.com with your questions and we’ll be happy to generate a suggestion study for your repo — free!
Also, If you’re excited to explore these insights further and connect with fellow engineering leaders, come join us in The Middle Out Community and subscribe to the newsletter for exclusive case studies and more!
Did you know?
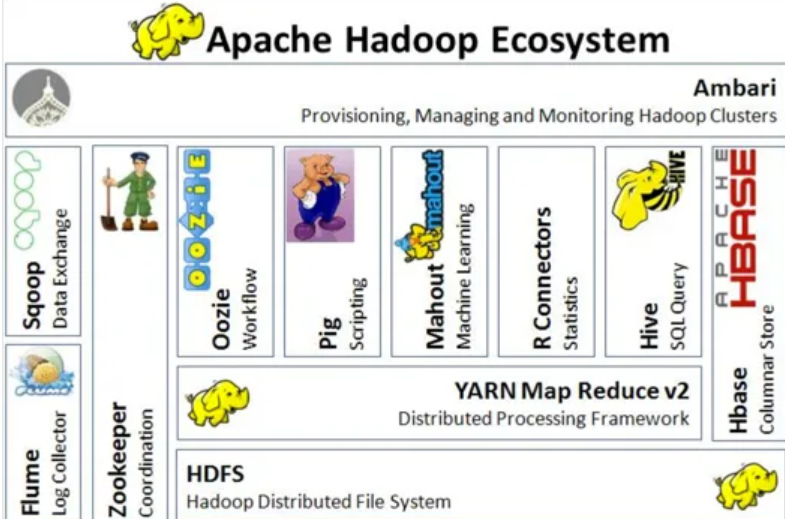
Hadoop is more than just a framework; it's an entire ecosystem that includes tools like HDFS (Hadoop Distributed File System), MapReduce, YARN (Yet Another Resource Negotiator), and additional projects like Hive, Pig, HBase, and Spark.
Further Resources
Subscribe to my newsletter
Read articles from Rajni Rethesh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rajni Rethesh
Rajni Rethesh
I'm a senior technical content writer with a knack for writing just about anything, but right now, I'm all about technical writing. I've been cranking out IT articles for the past decade, so I know my stuff. When I'm not geeking out over tech, you can catch me turning everyday folks into fictional characters or getting lost in a good book in my little fantasy bubble.