Kubernetes 101: Part 3
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulTable of contents
- Imperative and declarative approach
- Imperative commands
- Declarative command
- How Kubectl apply works?
- Kubernetes Namespace
- Scheduling
- Label and selectors
- How do we specify labels?
- Annotations
- Taints and Tolerations
- How to taint a node?
- Node Selectors
- Node affinity
- Resource limits
- Daemon Sets
- Static Pods
- Multiple Schedulers
Imperative and declarative approach
For example, you are going for Tom’s home and in imperative method, this is how you choose the path and direction (go right, or left etc)
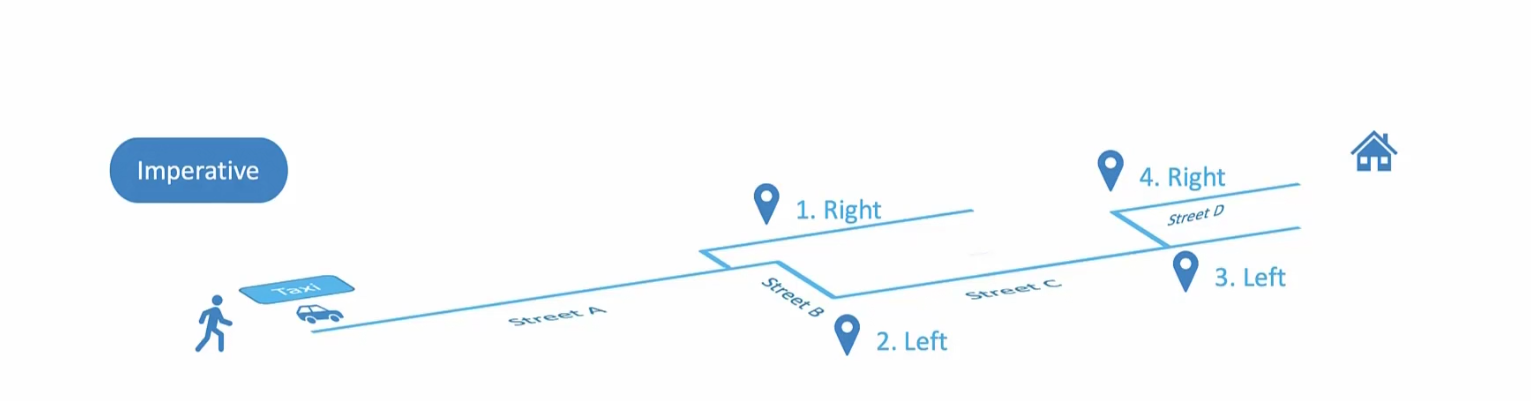
So, what to do and how to do is important in this approach.
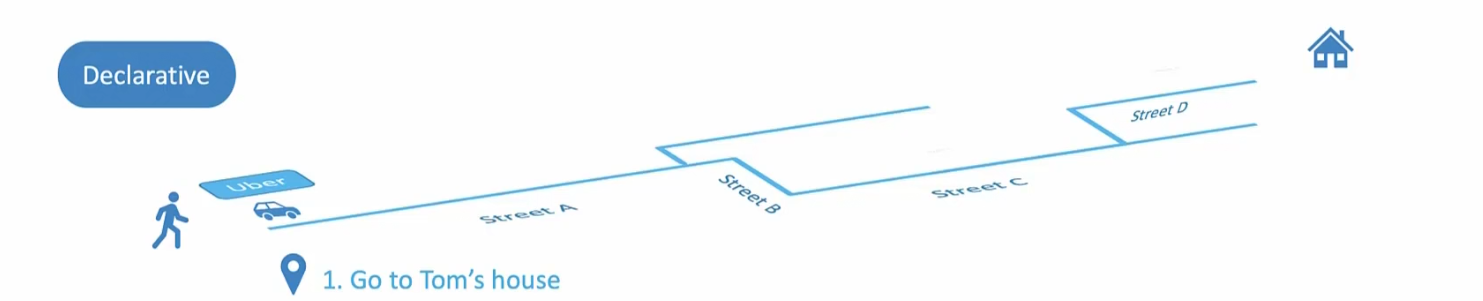
In declarative approach, you just mention you want to go to Tom’s house. And you are not bothered about which path to go and how.
In Infrastructure as a code, imperative approach would be a set of instructions

We specify what to do and how .
In declarative approach,

Here you just mentioned the name of the VM but you won’t provision it. It will be done by the software or system. Same goes for other instructions as well. You just mentioned what you require and the system is doing that for you. The system is clever enough to check if anything with the same name exists or not, if anything was done before or not etc.
Some tools that does this for you are Ansible, puppet, chef, Terraform
In Kubernetes, Imperative ways look like this

We specify manually what to do and what not to do.
In declarative approach,
You specify everything in a yaml file and apply that

Kubernetes then creates all of the things that you asked for in the yaml file.
Imperative commands
We generally use commands to create some file or modify it.

The problem with these commands are, although these commands do make changes but they don’t have any permanent changes to the yaml files etc.Meaning if we want to make changes to number of pods via these process, it’s not permanently saved in an yaml file. Where we had to make permanent changes in the yaml file to change conditions of pods in declarative method.
For example, we want to increase number of replica/pods from 3 to 6. Assume, currently we have defines 3 pods to be created through yaml file. So, we have 2 options. Modify the yaml file and change the replica from 3 to 6 or, we can use imperative way and use kubectl scale deployment nginx —replicas=6
Yes, we will now have 6 pods/replicas but , if we apply the nginx.yaml file again in another place or so, it will just create 3 replicas as yaml file was not changed.
Also, for example assume we want to change the image name from nginx to nginx:<new version>
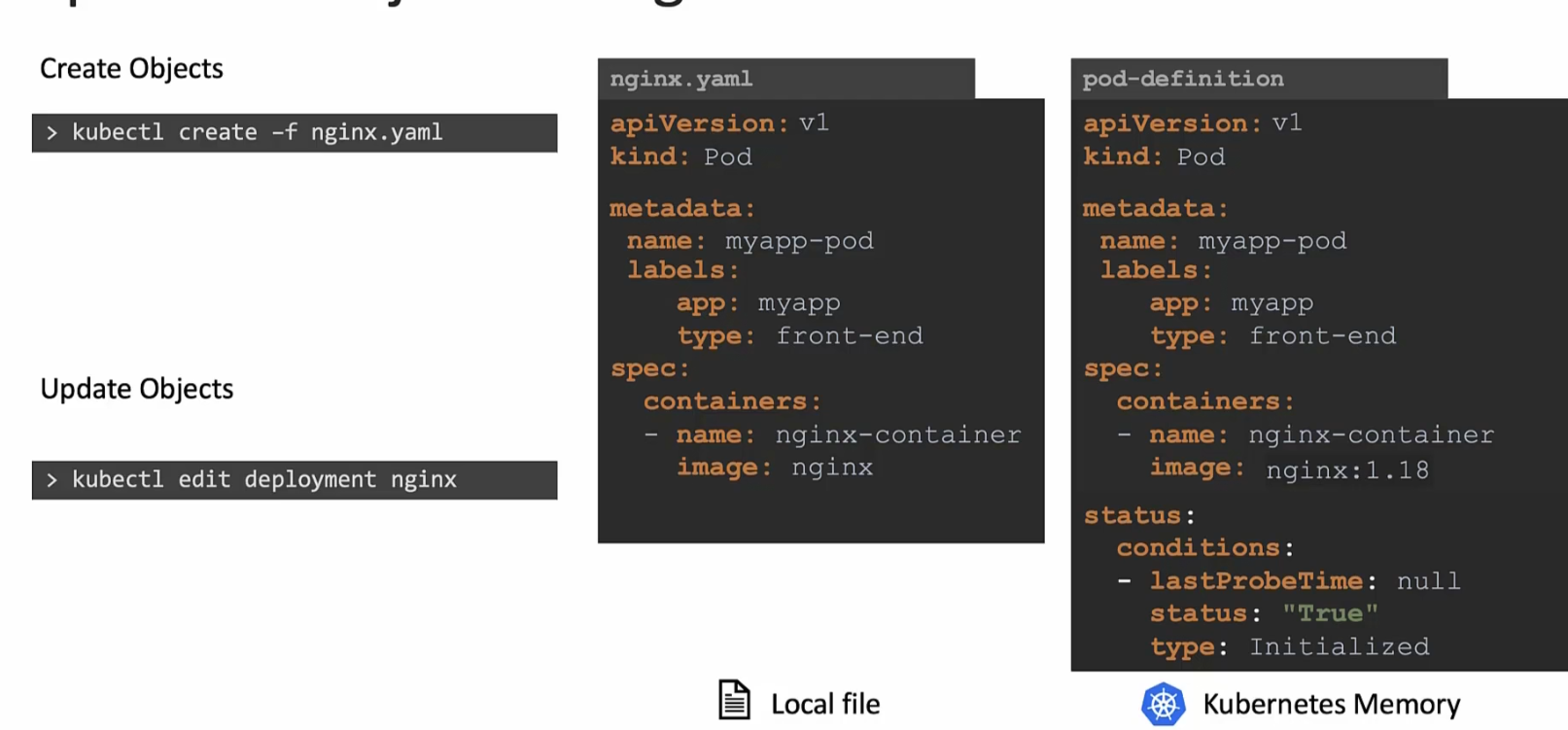
When we use the edit command, kubernetes create a definition file in its memory which is modified then. In this image, you can see that, nginx.yaml was our file to create an nginx pod (having container nginx-container with image nginx). Once we used the edit command to edit the pod, it showed pod-definition file which is something it created in memory.
We can update the file in it’s memory but the issue is , nginx.yaml file never gets impacted.

The image name is still the same in the local nginx.yaml file.
But still, if you want to make changes through imperative approach, you can use this

You may start editing and then replace the nginx image with new version and then use replace command. In this way, the nginx.yaml file will be updated via imperative method.
Also, if you have an existing container you want to run or, replace something that does not exist, it will show error

Declarative command
If you want to create a deployment or so, use apply command which is intelligent and manages things.

Also, when you need to update the image, you edit the file first using vim editor or so. Then apply the changes. For example, assuming we created an nginx.yaml file and later on, if we want to make any changes to our Pod file, we will edit the nginx.yaml file and then apply changes. There are no imperative commands used in terminals.

How Kubectl apply works?
When you use apply command for the first command,

if the object (we want to create) does not exist, it creates an object and an object configuration file in Kubernetes.

Here , it has additional field (status) to store the object.
But as we used kubectl apply , it does something more! It creates a json file in “Last applied configuration”.
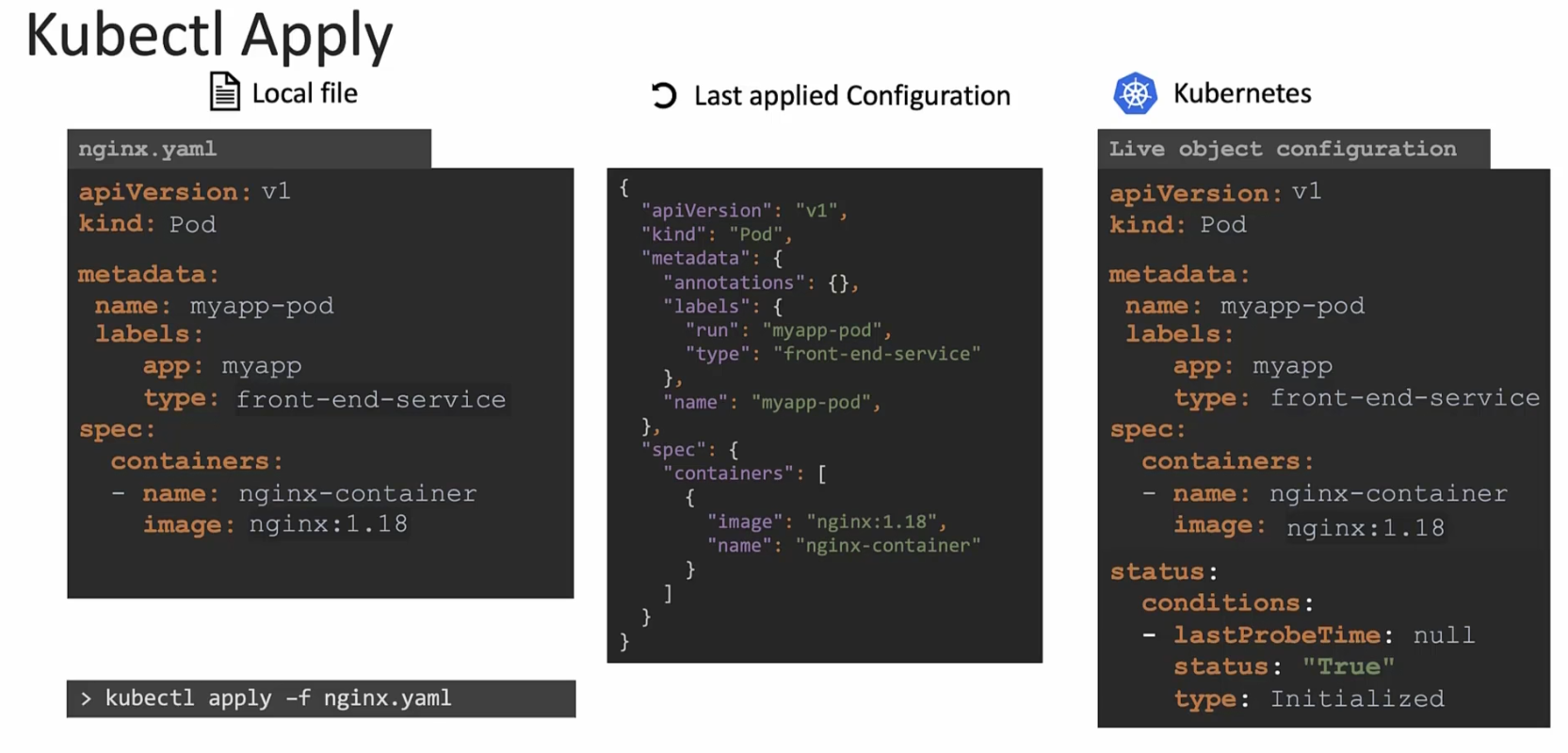
Now, in future whenever we make changes, 3 files are compared.
Assume now we have updated the yaml file and changed the image to nginx:1.19 and apply kubectl apply, this value is compared with the value in “Live object configuration”
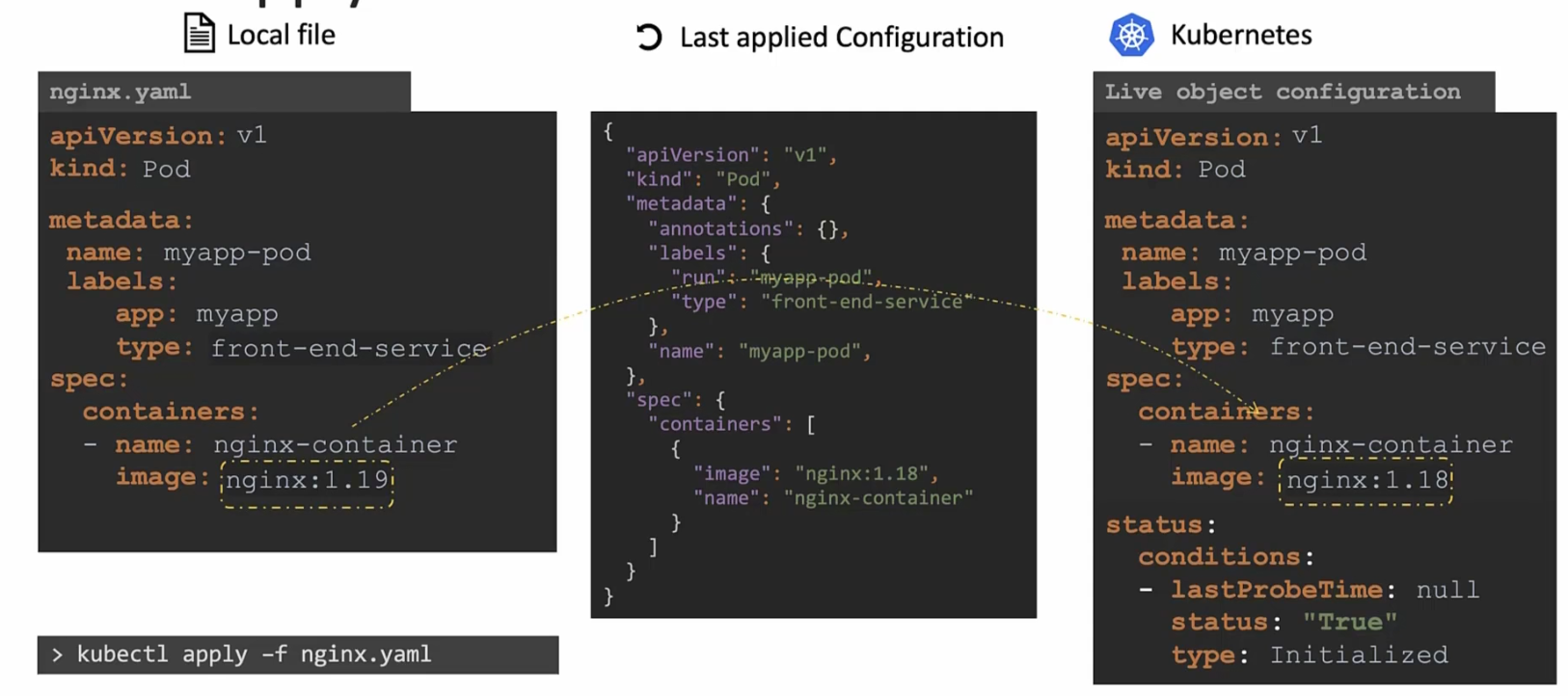
Once it finds out that the value is not same, it updates the value
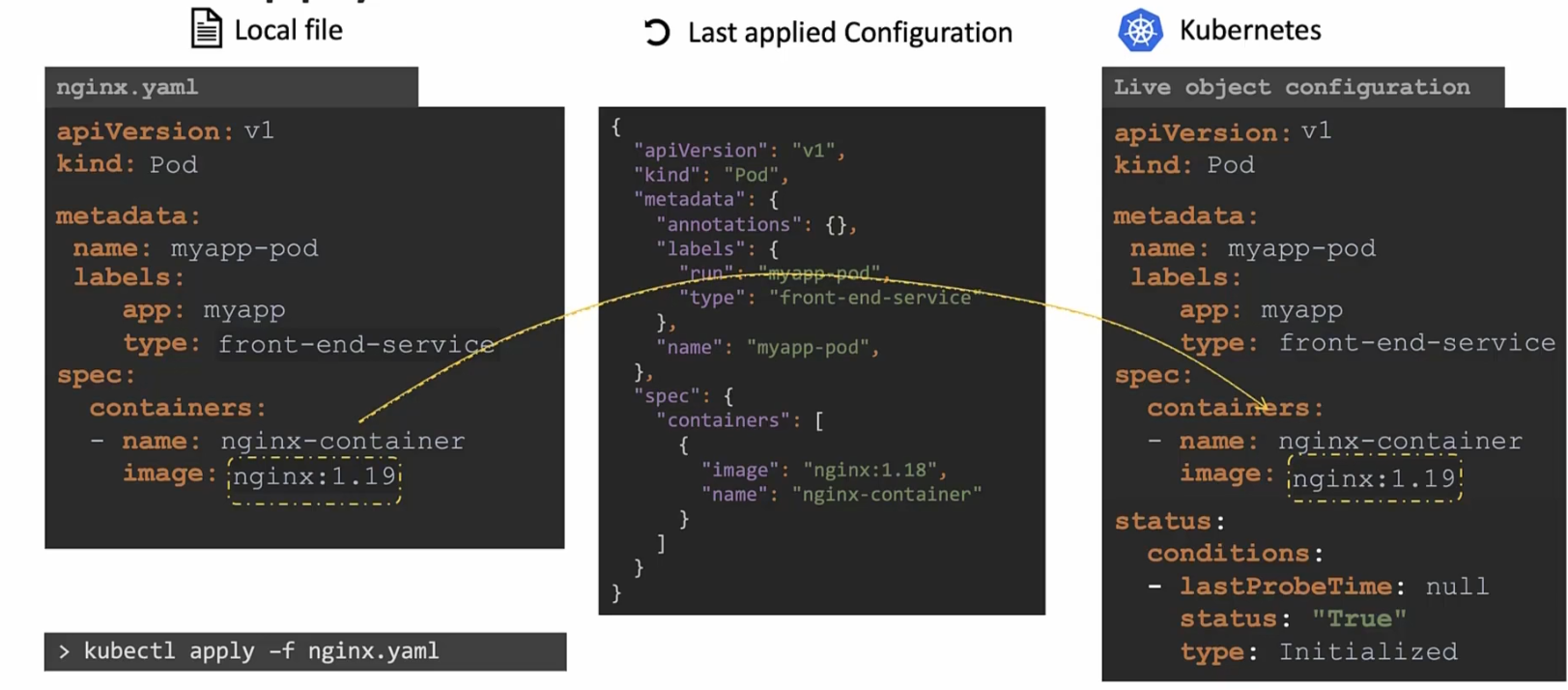
After that , “Last applied configuration” file gets updated
But what’s the use of “Last applied configuration”?
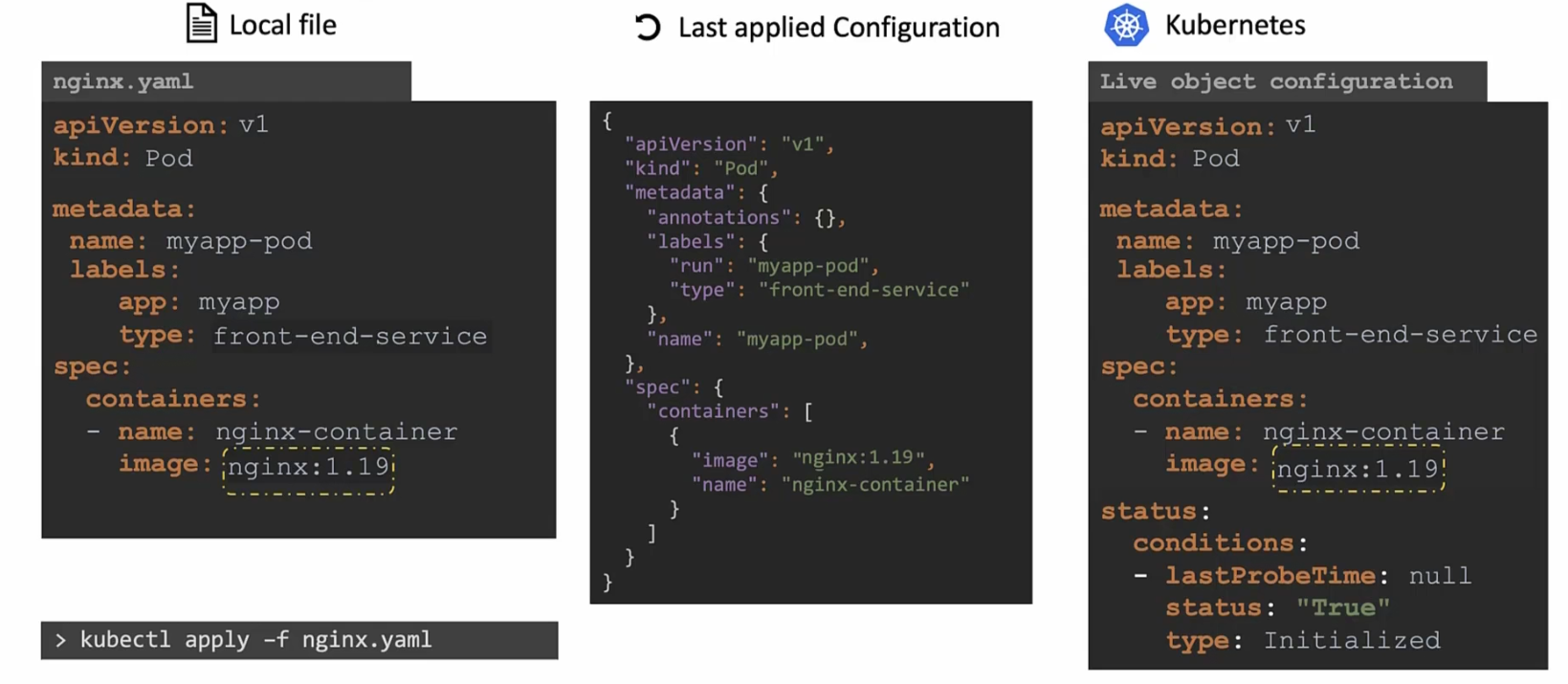
Assume that type label is deleted from the nginx.yaml file
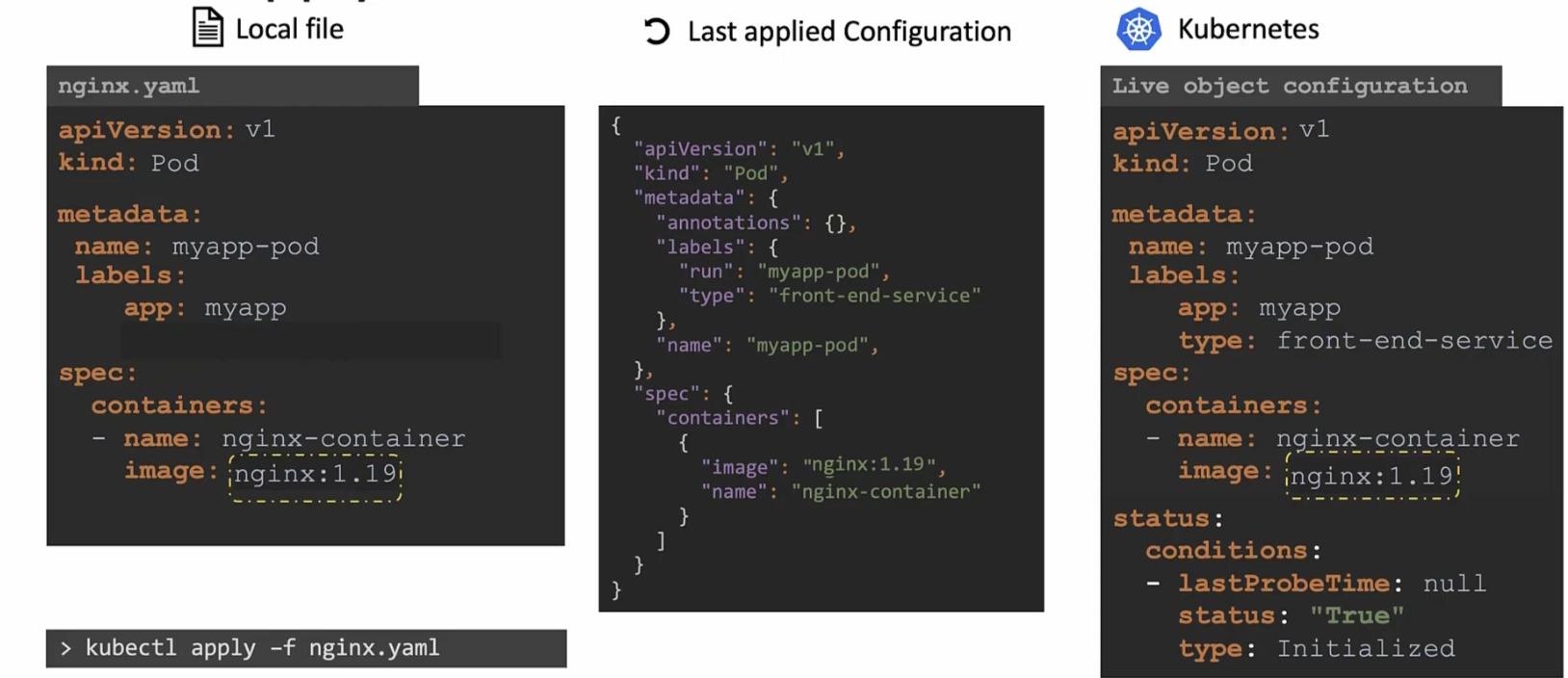
Then once you press apply command, it will check that the “Last applied configuration” file has the label but the nginx files does not have that.
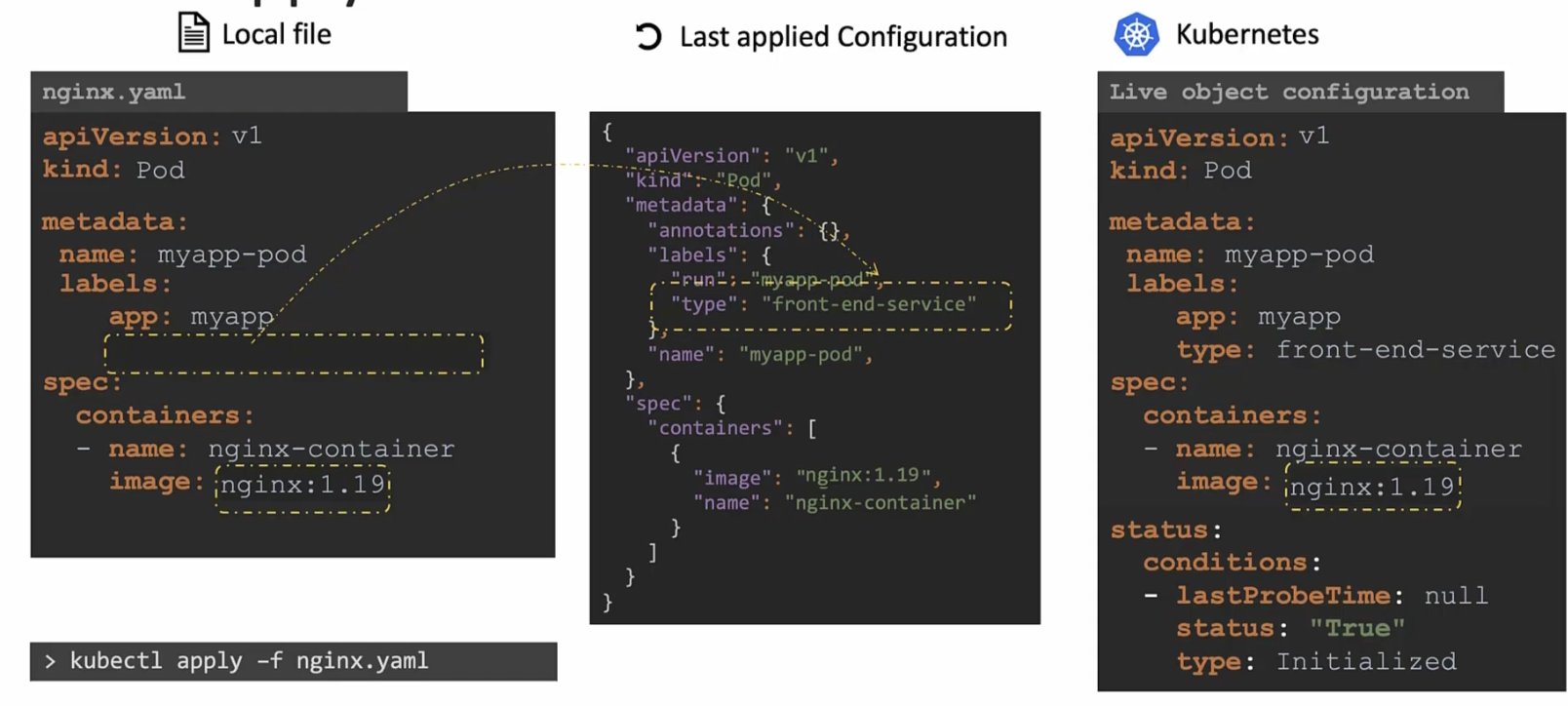
So, for this reason, the field will be removed from the live configuration file

So, in this way the “Last applied configuration” file helps us know what fields have been removed from the local file.
But now the question is, where is this “Last applied Configuration” file stored?
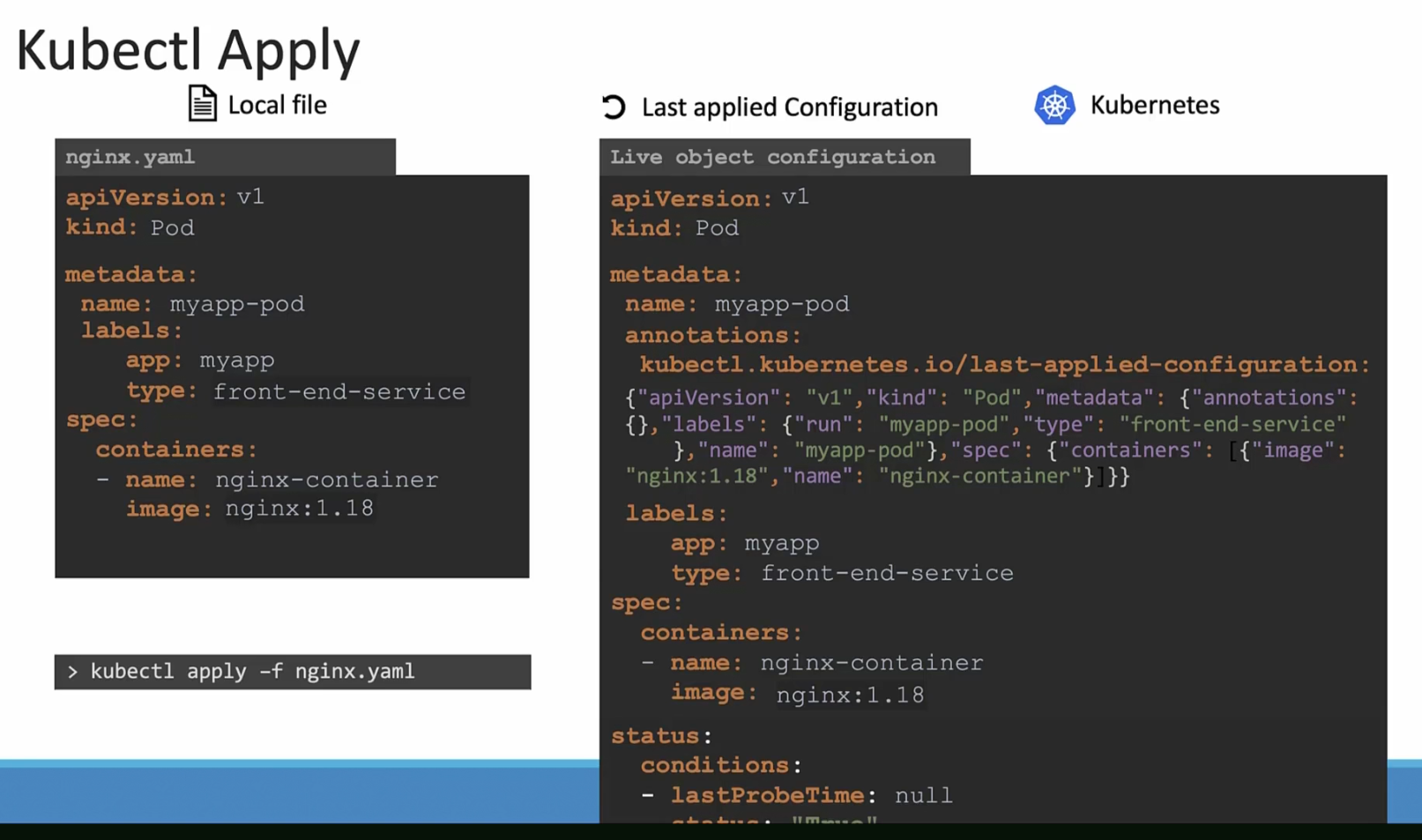
It’s actually stored in the “Live object configuration” file’s annotations sections!!!!
But remember, this thing gets created only when you use declarative commands.
Kubernetes Namespace
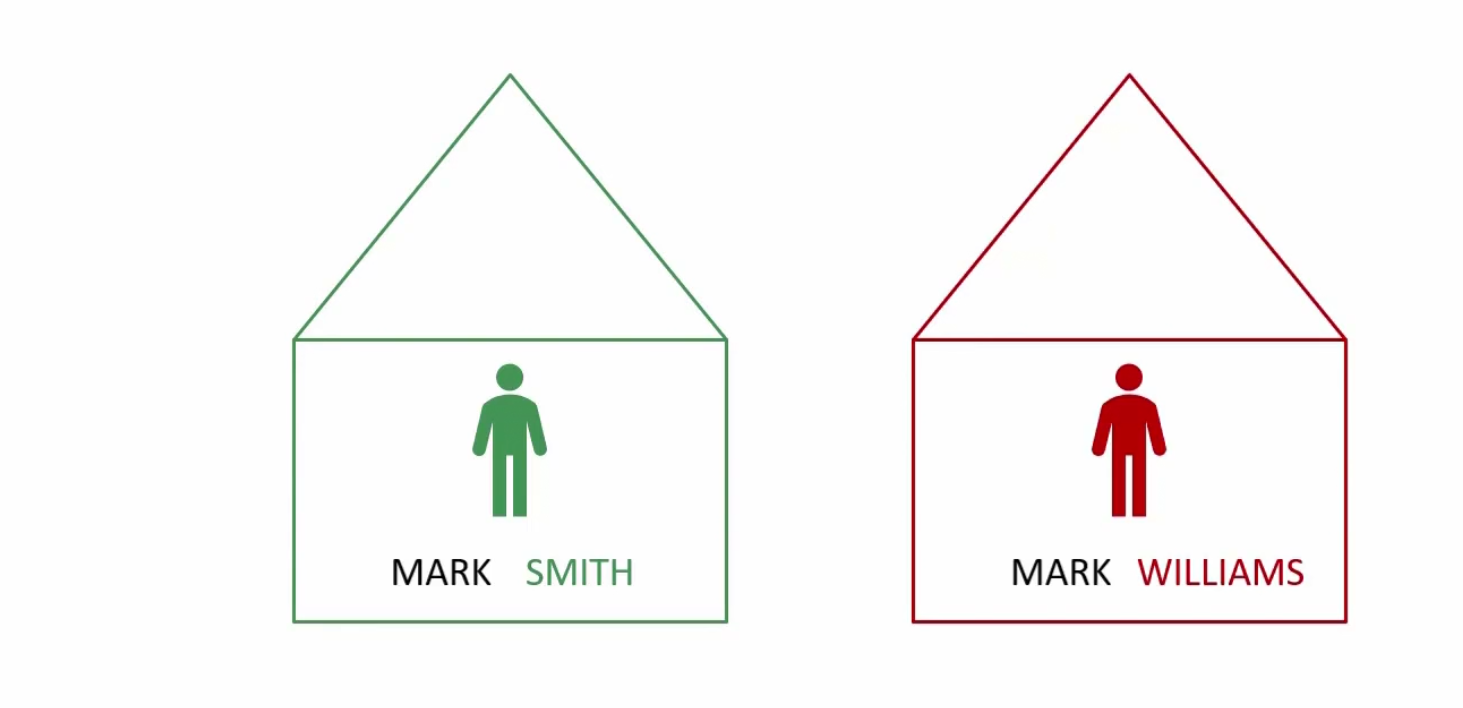
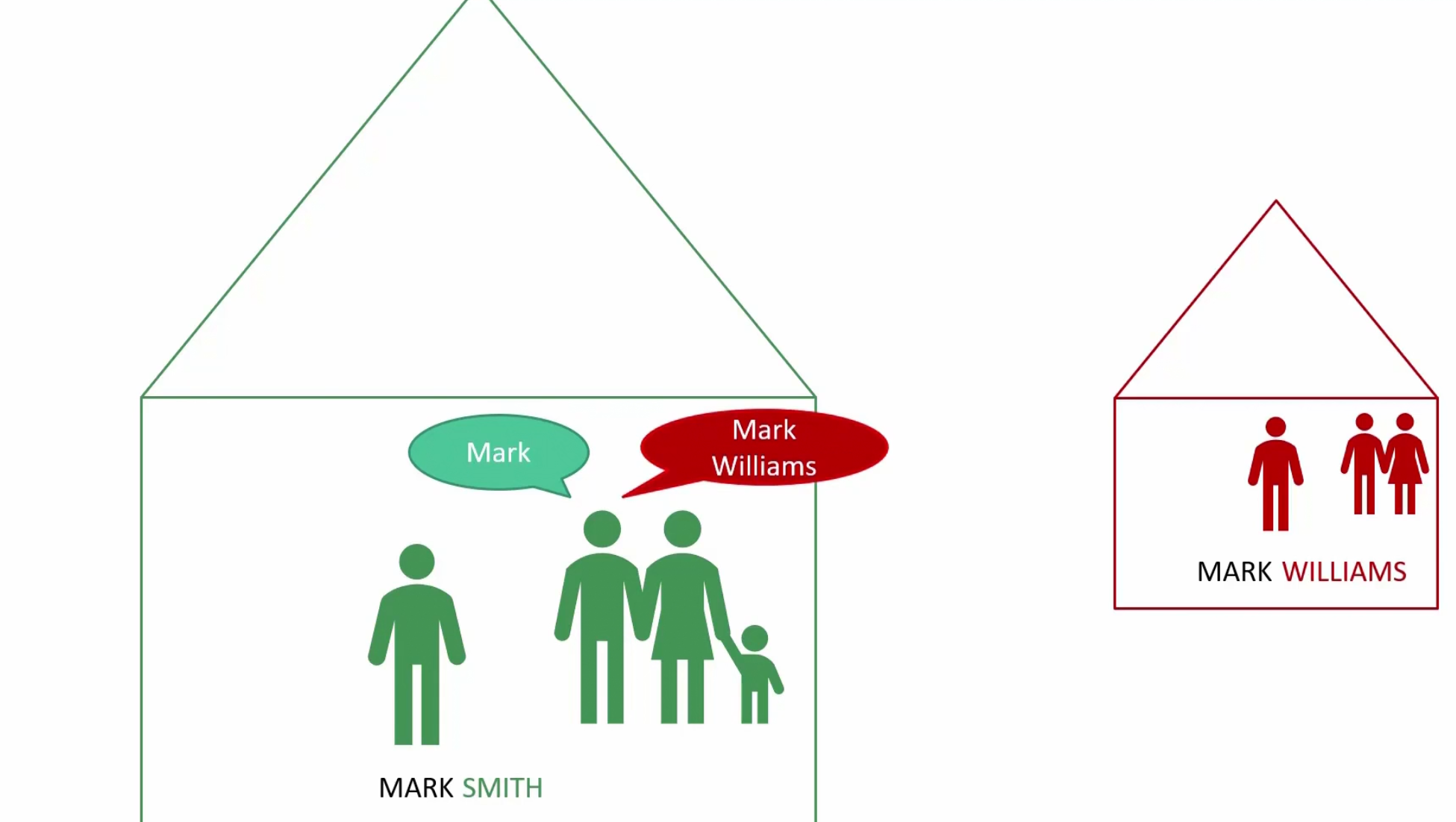
Assume that SMITH and WILLIAMS has their own house
Also, there are surely other members in their family
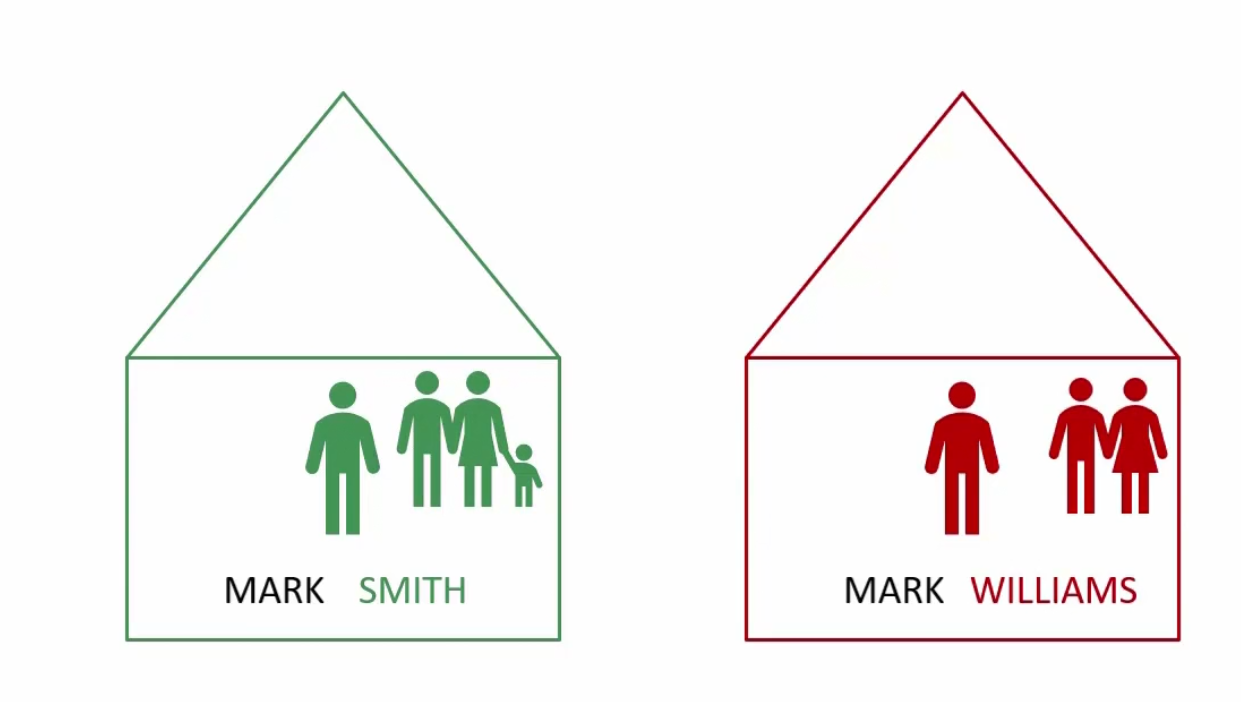
Now, assume if Mark smith’s father wants to call him , won’t he just use the first name “MARK”?
Yes!
But if Mark smith’s father wants to called MARK William, will he still use “MARK”? Or the family name as well?
Yes, he will use “MARK Williams” now
For kubernetes, these houses are something like namespaces
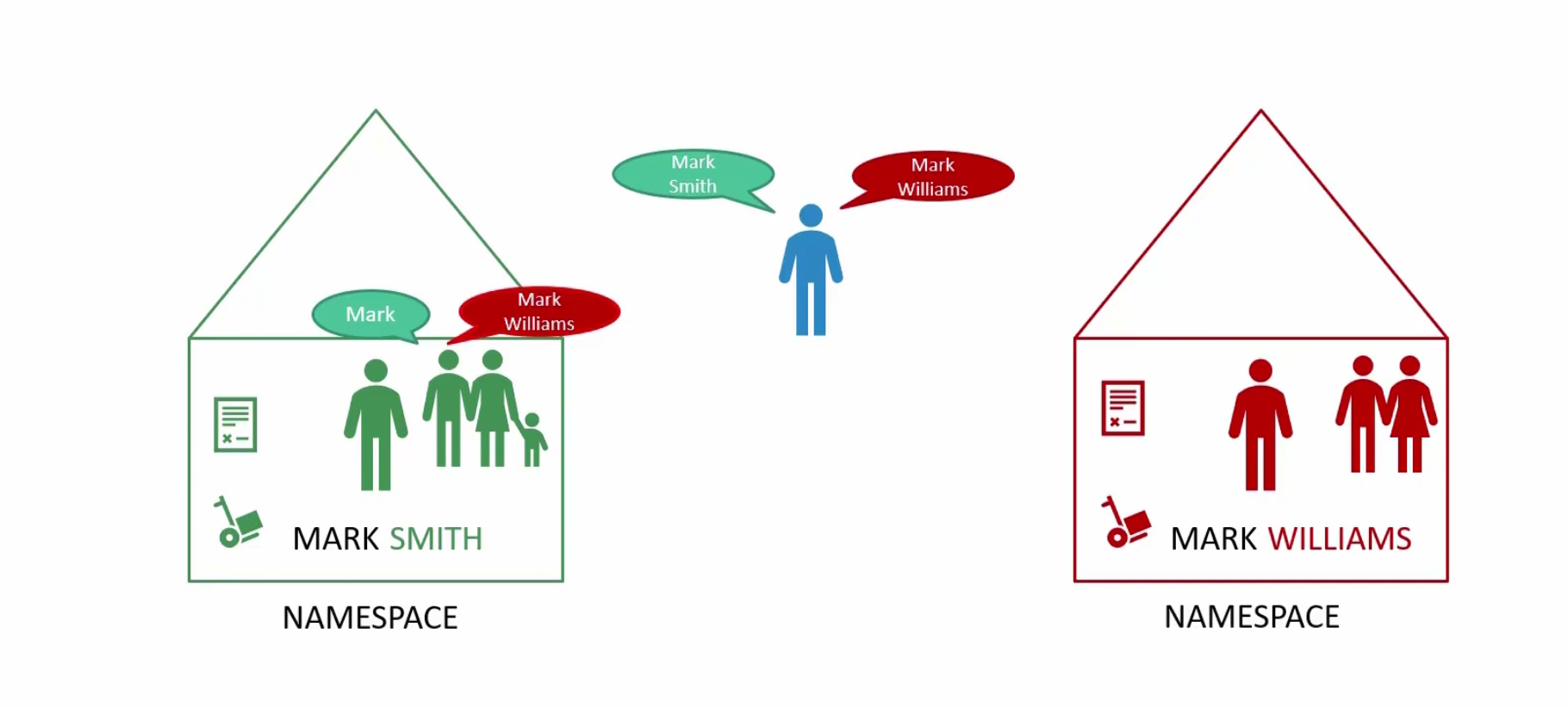
Each house/namespace use their own resource.
Till now, whatever we have done (creating pods, deployment, service etc), those were done basically in the default namespace
Kubernetes creates all files and clusters that’s necessary for it’s usage. It then keeps them in the kube-system namespace
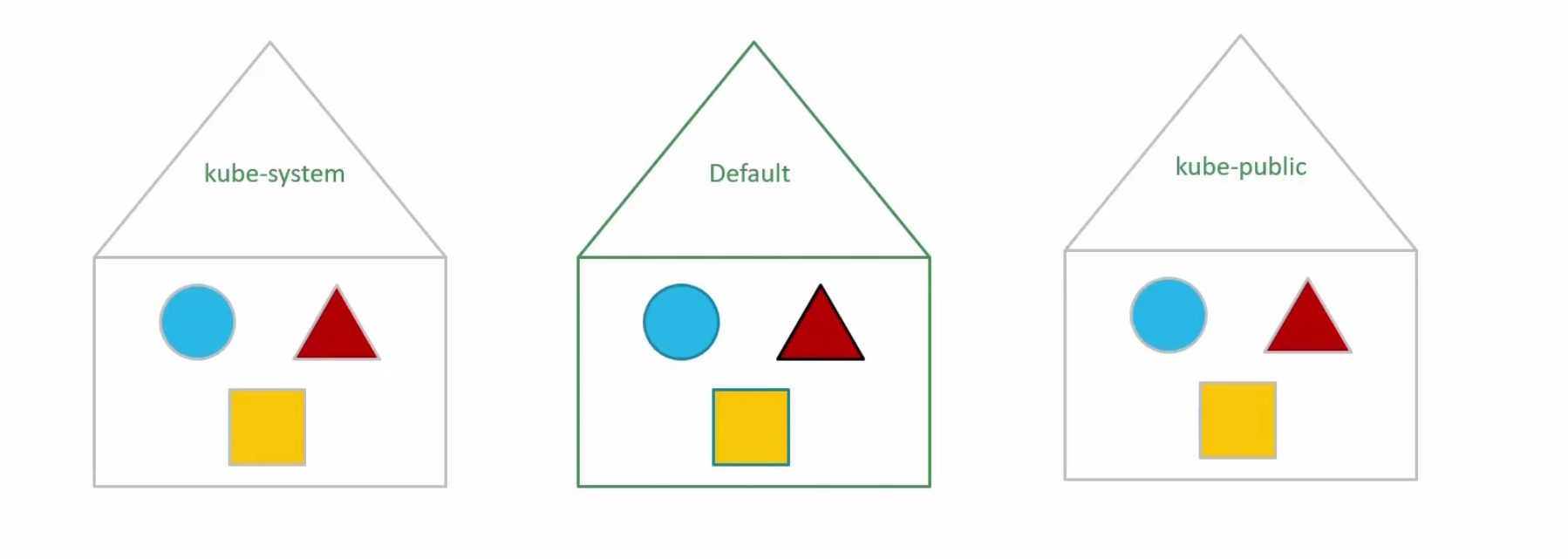
It also keeps all of the public resources which should be made available to other users in the kube-public namespace.
If you want to keep development pods and others separate from production pods and others, you can create different namespace for them (Dev, Prod)
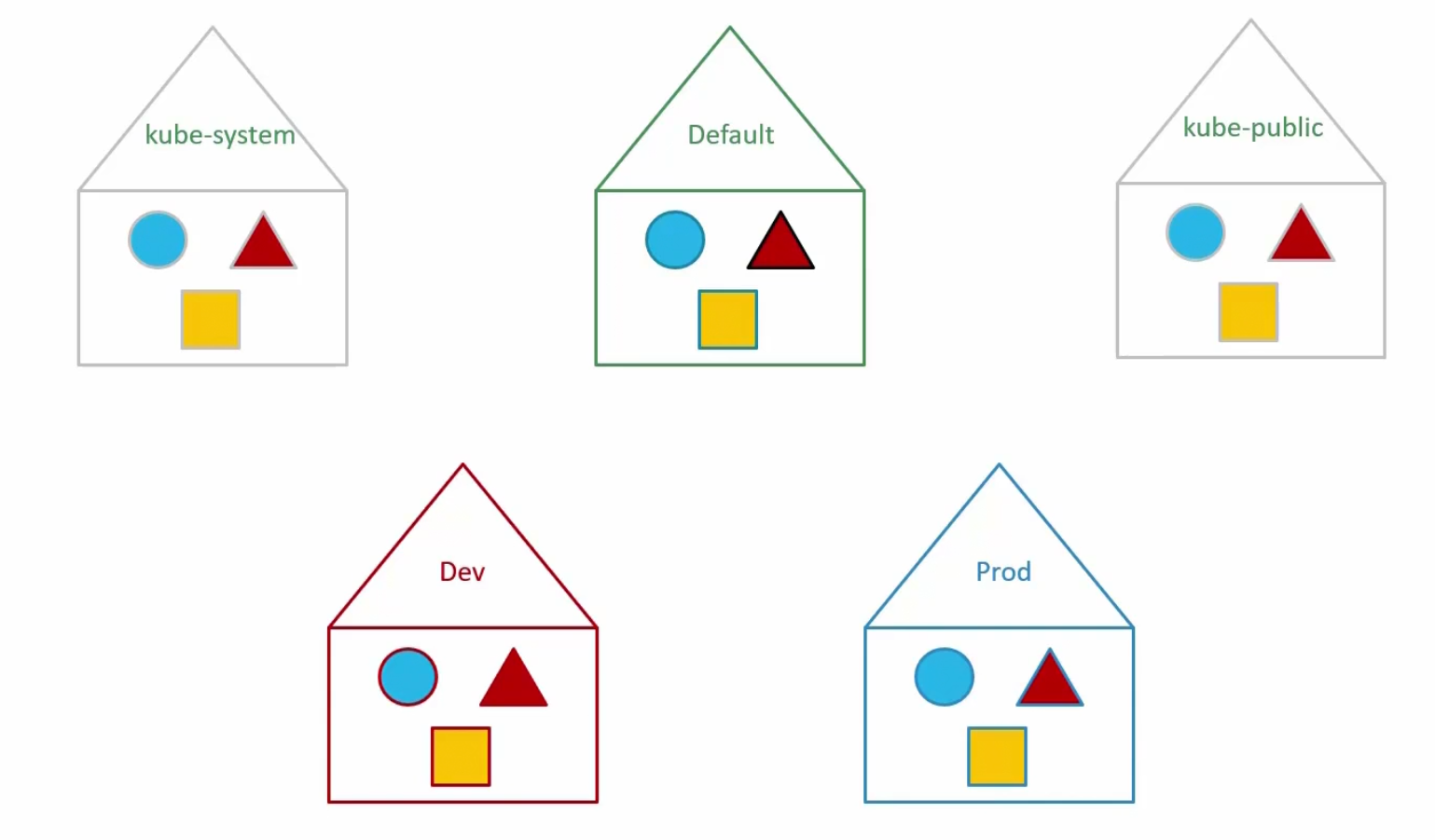
You can assign policies for each namespace, assign quotas to use certain tools or so.
Now, talking about the connection, when using the default namespace , if one resource wants to contact another resource kept in the default namespace, they can just use the name.

But if that (resource kept in default namespace) wants to contact another resource (db-service kept in dev namespace), it has to mention the whole path.
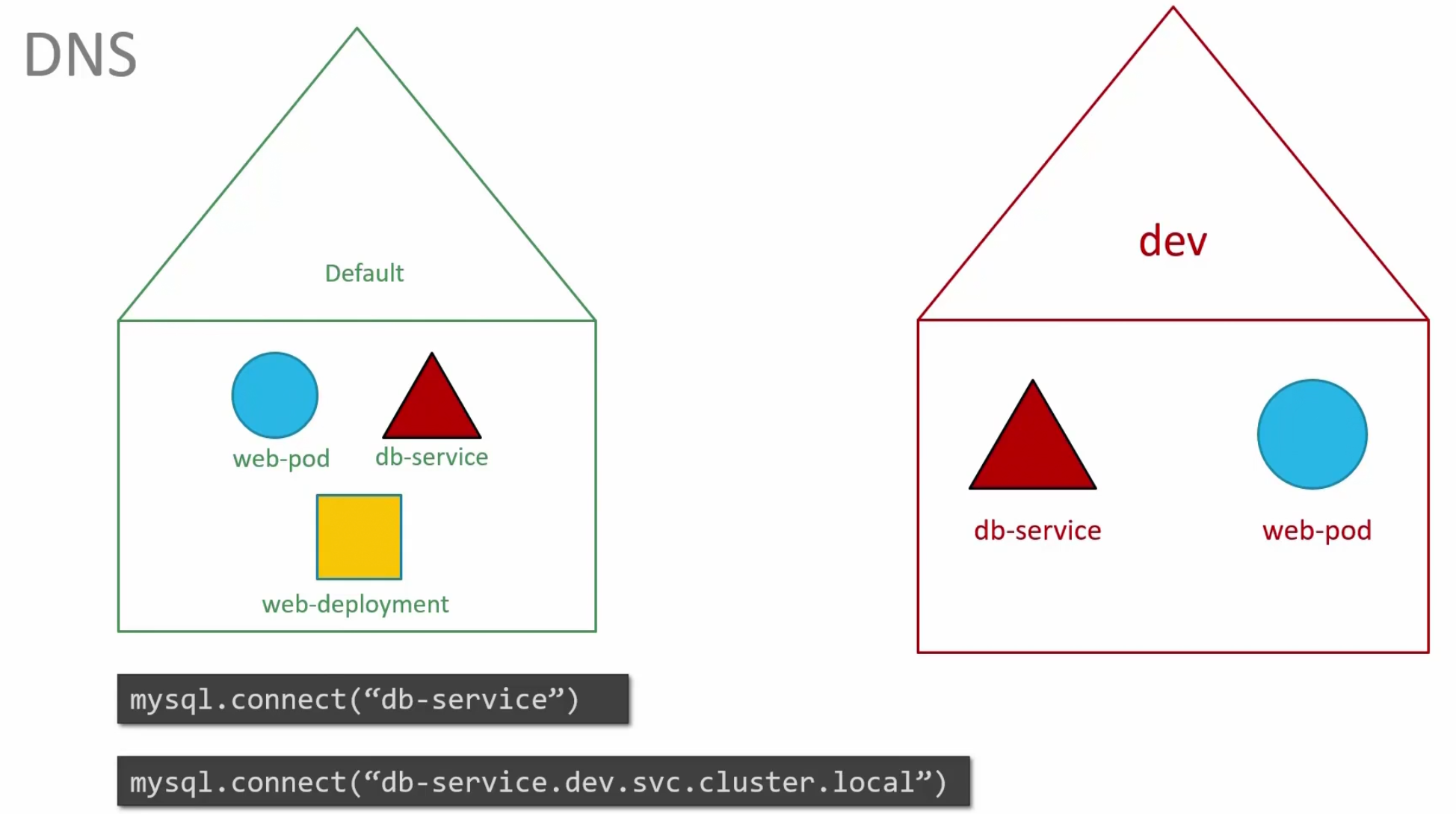
Here we had to specify, <resource-name>.<namespace-name>.<resource type>.cluster.local to contact the db-service kept in dev namespace whereas we used just the service name (db-service) for the one in our default namespace.

Let’s see the commands now!
When we want to see the pods within the default namespace, we say kubectl get pods
but when we want to see pods kept in another namespace, we do specify the —namespace=<namespace-name>
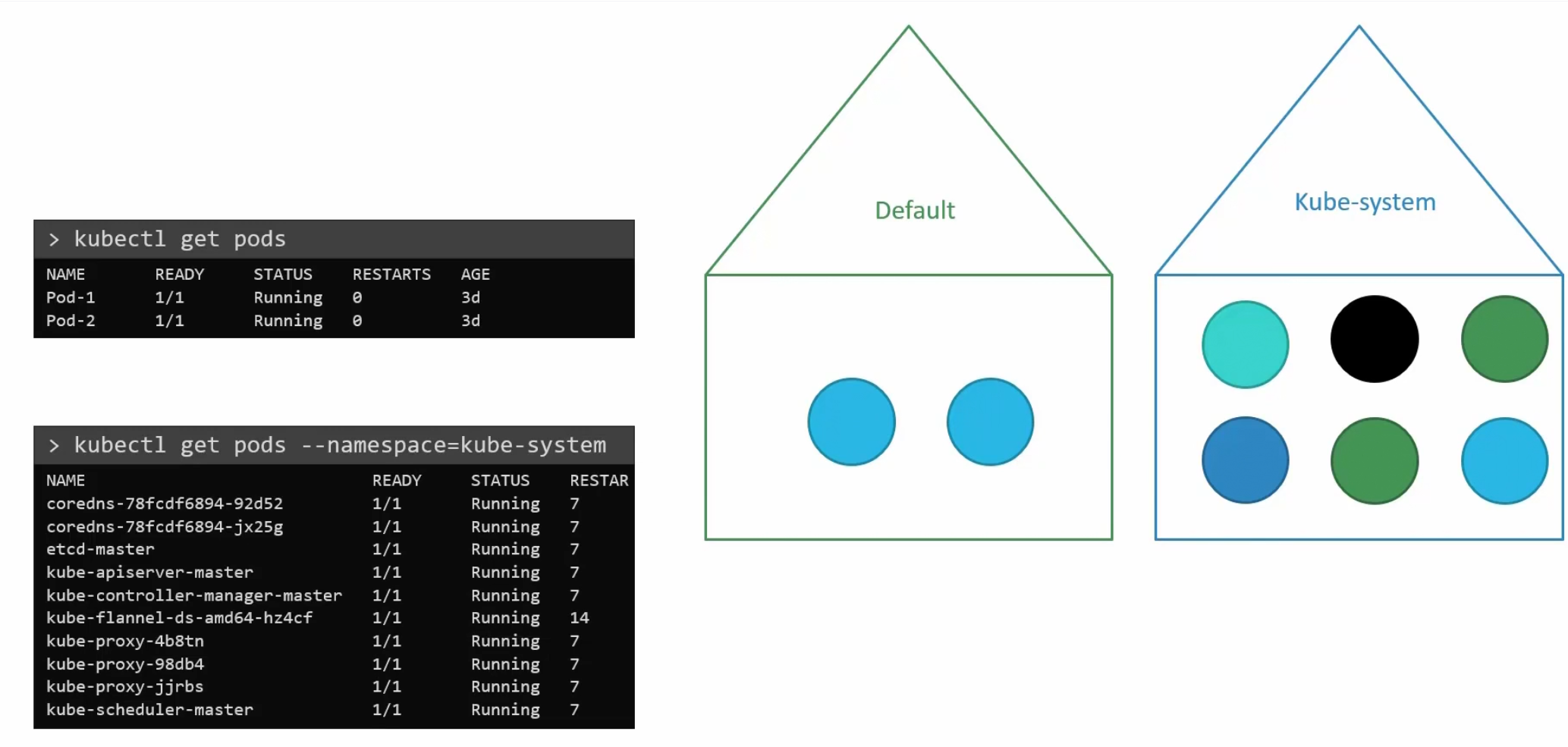
So,while creating a pod, if you don’t specify the namespace, it will be created in the default namespace. But if you mention the namespace, you will create the pod in that namespace.
or, you make changes in the yaml file and add namespace section under the metadata. This way, whenever this yaml file runs, it will be created only in that namespace. So, you have to be sure about it.
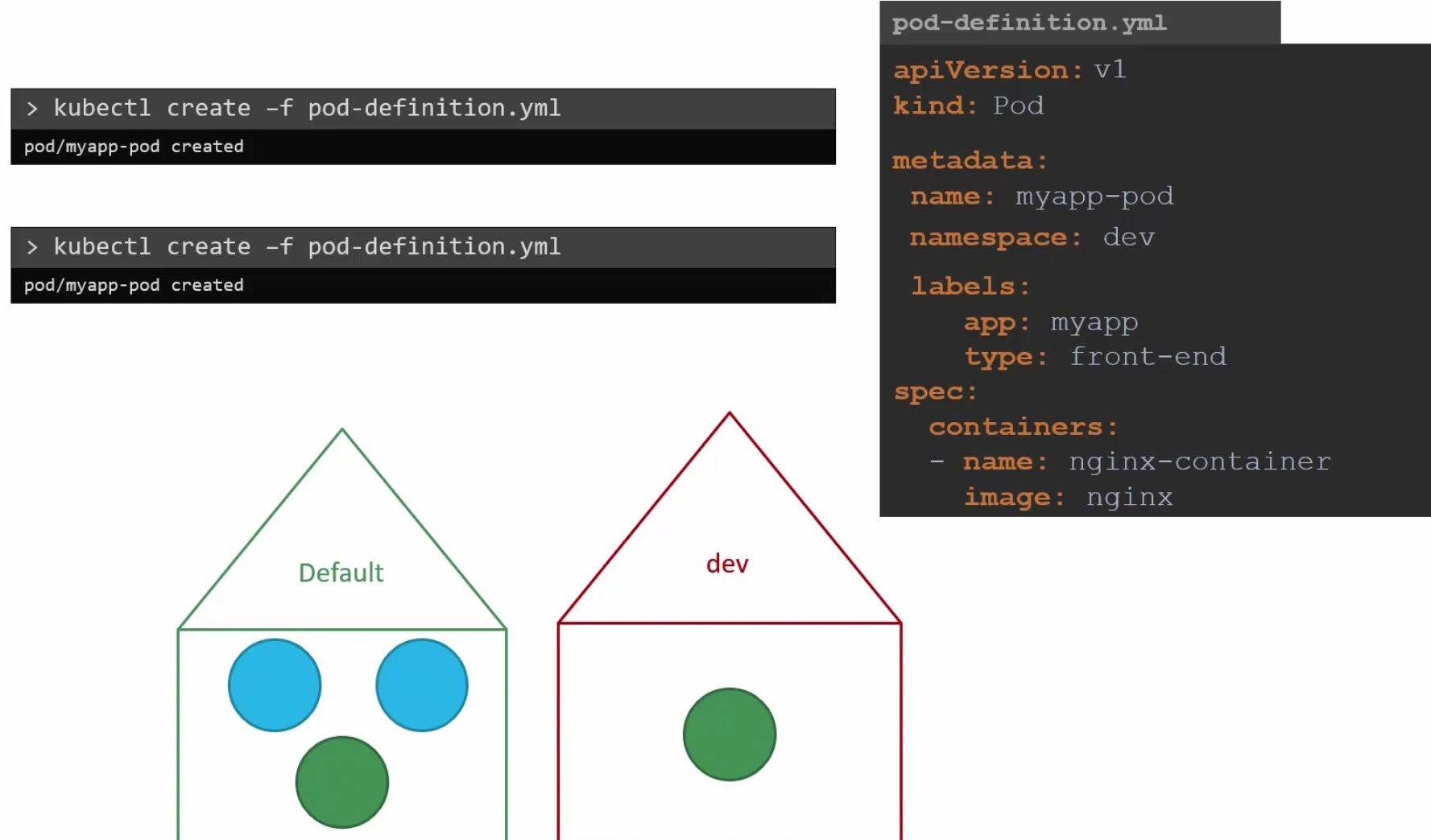
How to create a namespace?
You can create a yaml file and create it or, use kubectl create namespace <namespace-name>

You can also switch to a namespace so that you don’t need to mention the namespace when creating any pods there.
By default we are in the default namespace.
To switch to a namespace permanently (here to the dev namespace), use this:

Now, you are in the “dev” namespace and you can check pods within that and others too by mentioning their namespace (for default one and prod one)

If you want to see all of the pods kept in all of the namespace, use this

Finally, To limit quota or resources for a namespace , we can create a yaml file and mention the namespace , and spec there
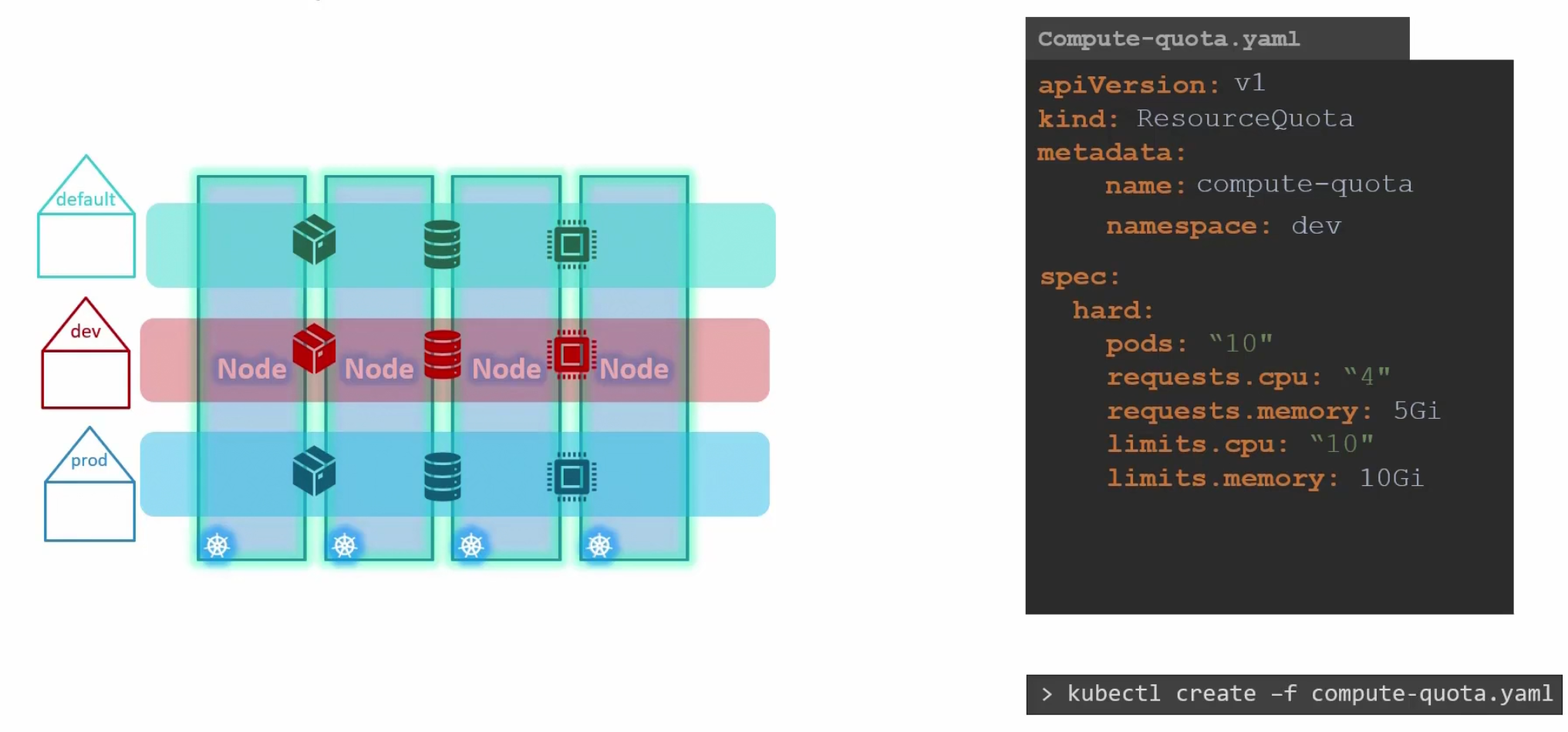
Here we did this for namespace dev
Scheduling
For pods, in the yaml file we have something called “nodeName” which is not set by default. Kubernetes looks through all the pods and finds out which does not have any nodeName specified.

Here, the 3rd one has no nodeName specified. It then takes that to schedule through an algorithm.
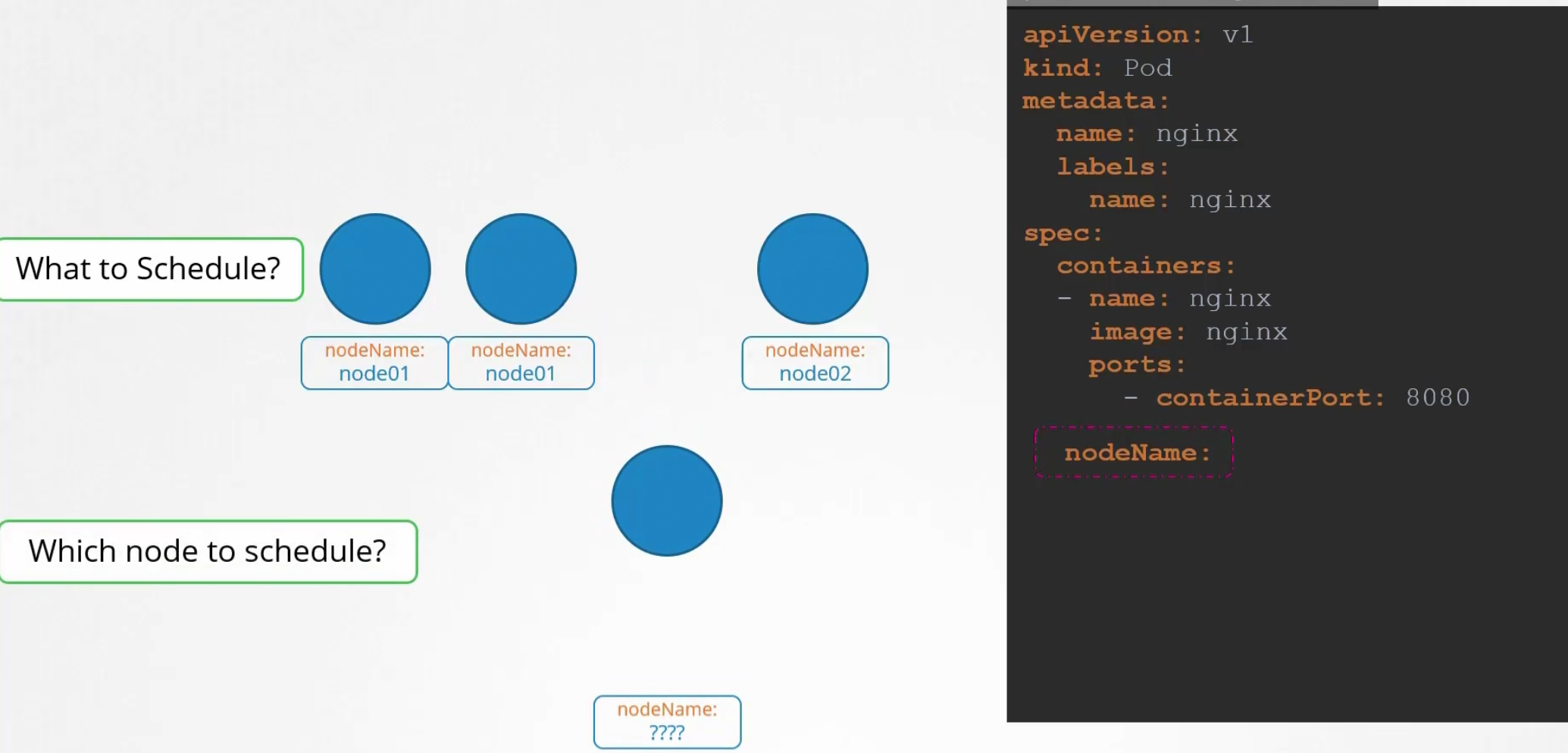
It then schedule the pod on a node and set the yaml file.
But if there is no scheduler to schedule a pod (which has no nodeName specified), what to do?
We then see those pods to be in the pending state.
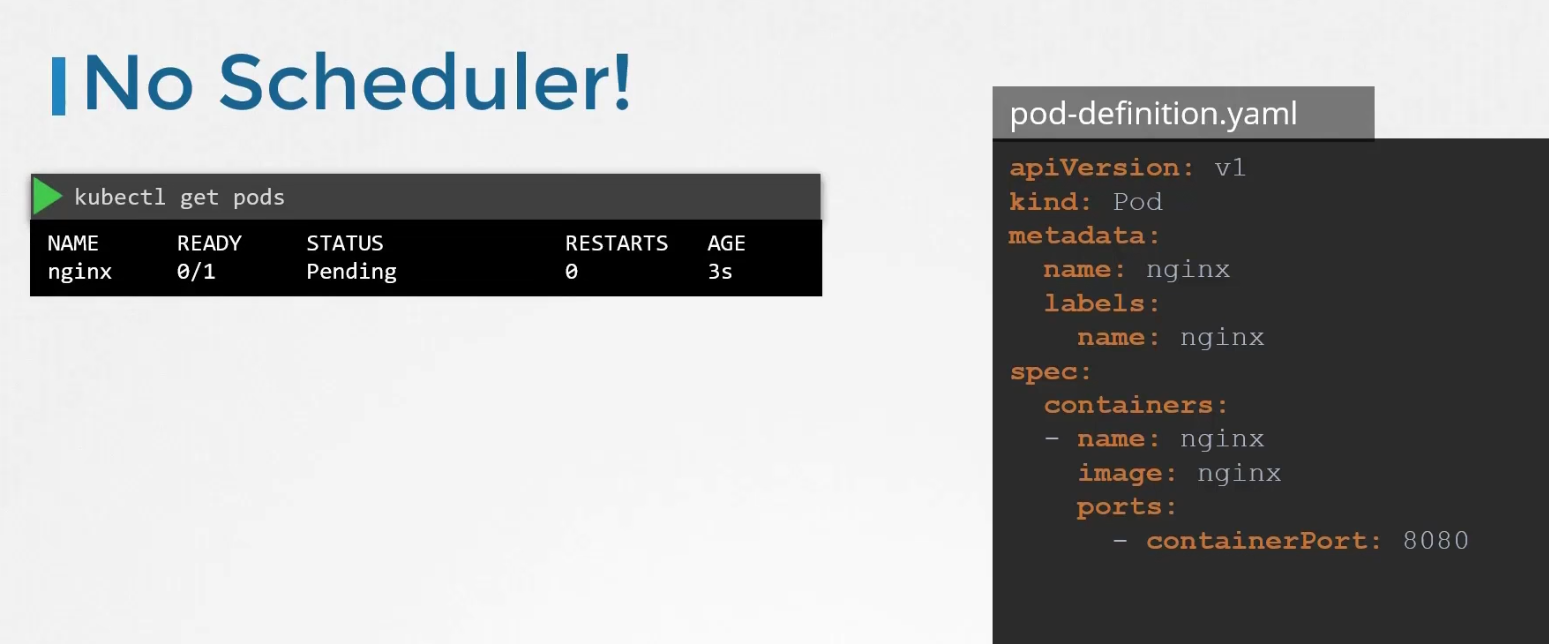
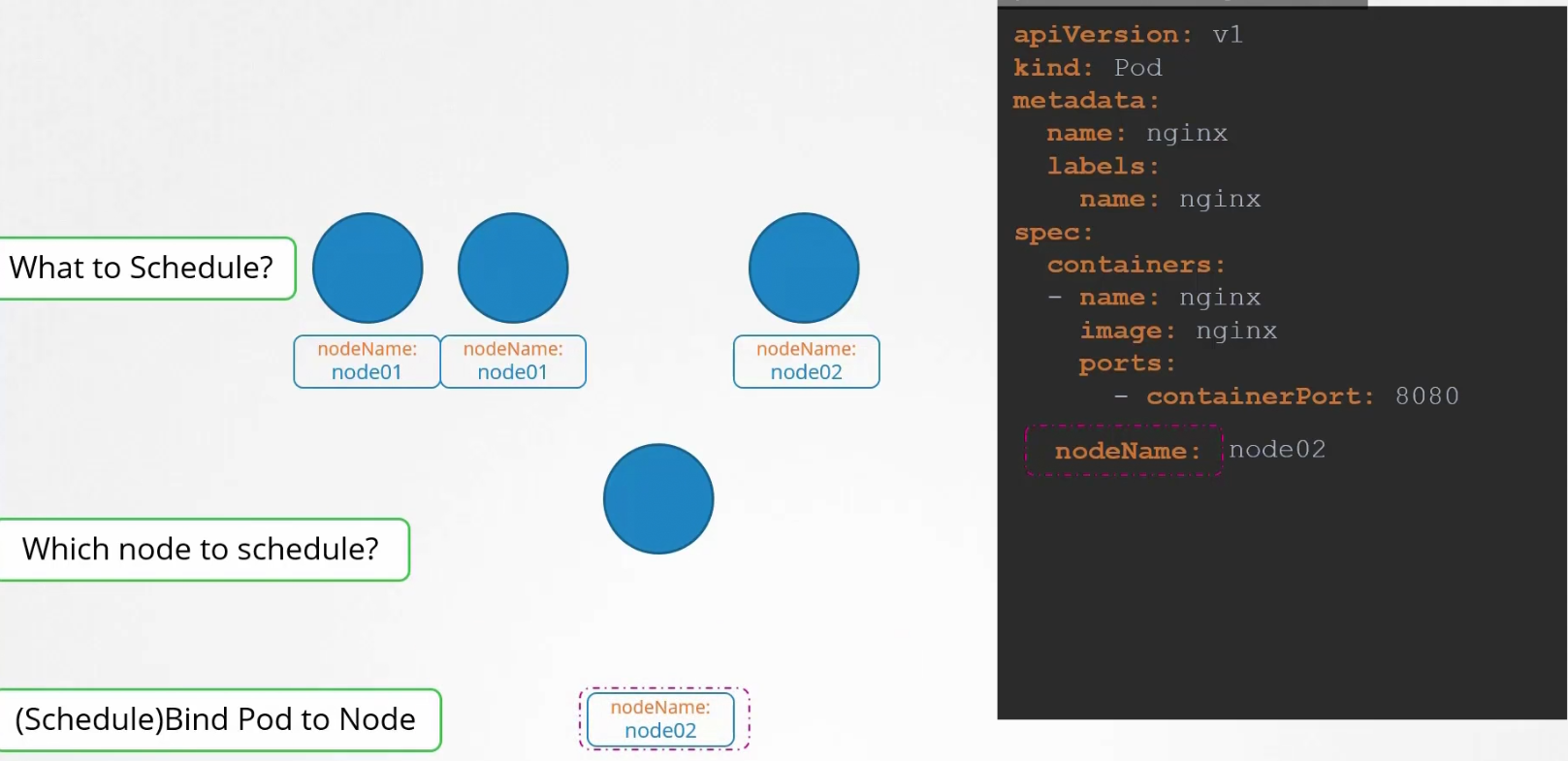
Surely, you can manually assign node to a pod. But that has to be done when the pod is getting created (can’t do it for an already created pod)

To set node for an existing pod, we need to create a binding object and send a post request to the pods binding API.

In the binding object, we specify a target node with the name of the node. Then send a post request to the pods binding API with data set to the binding object in JSON format
For example, Pod-bind-definition.yaml file has the content which we write in JSON format and pass via command line
This is how the JSON code looks like:
({“apiVersion”:”v1”,…..})
Label and selectors
To group different types of resources, we can use labels

Here, animals are taken for example.

In our case, we set our resources with labels like app, function,type etc
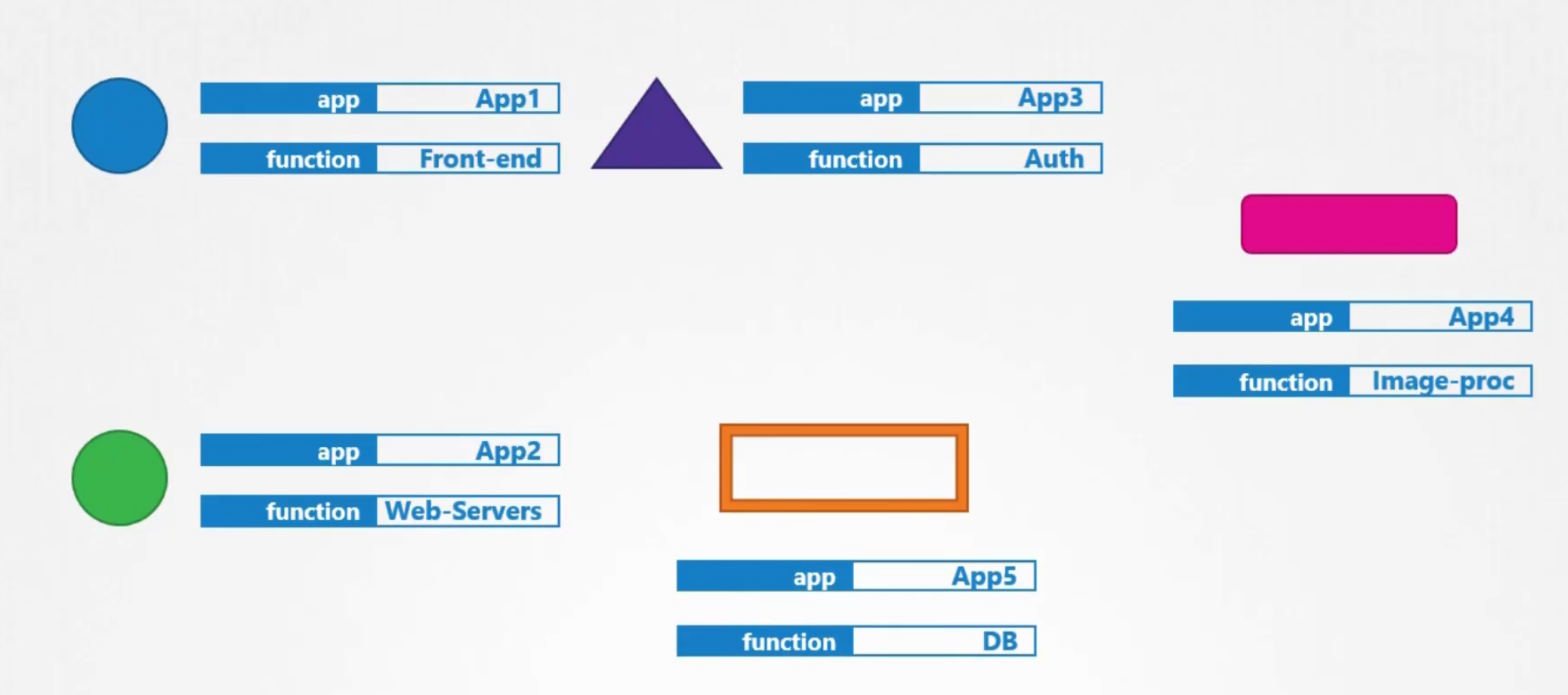
Then in the selectors, we can specify which labels to choose

How do we specify labels?
We write them down under the metadata section
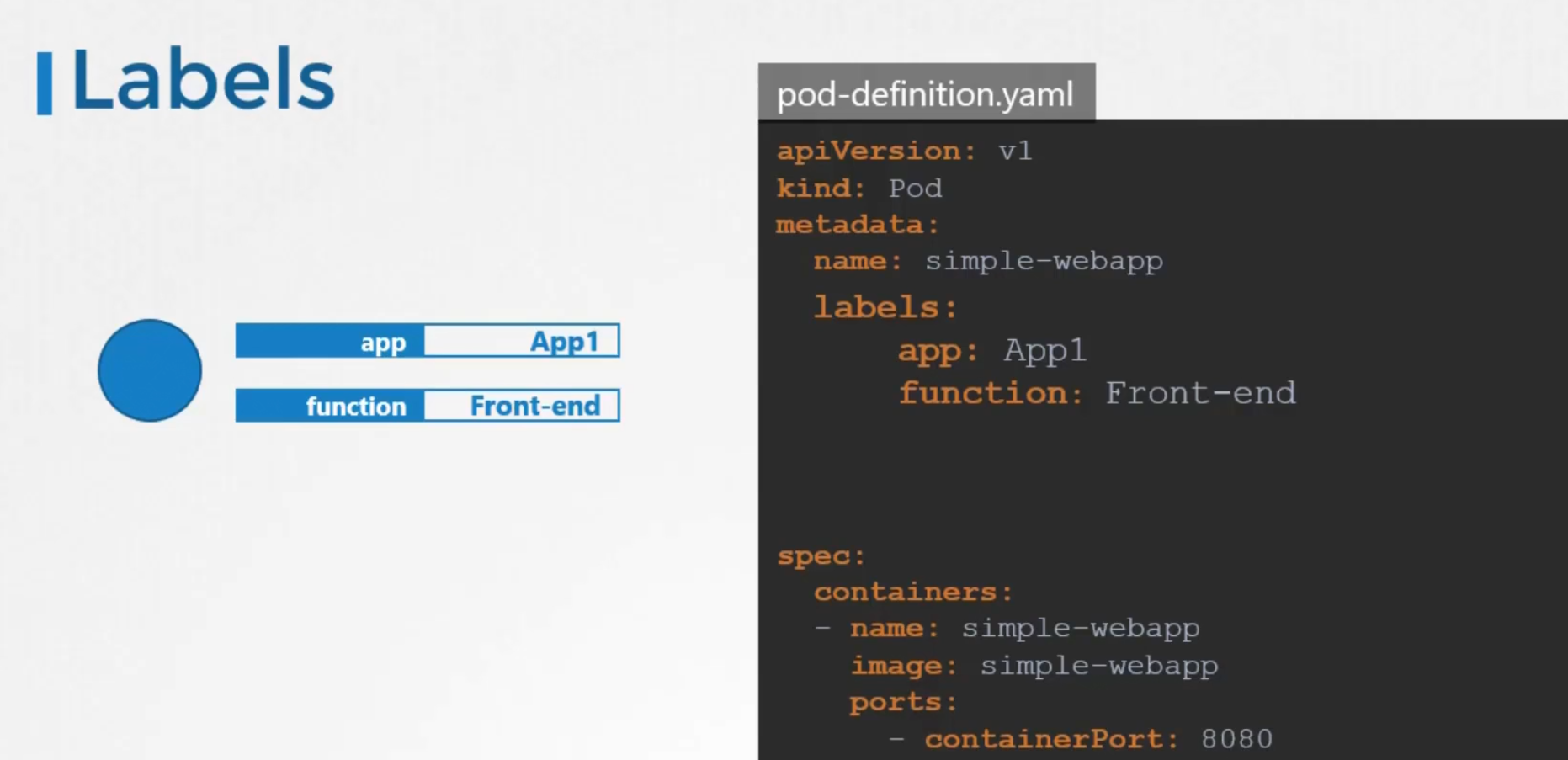
Once the pod is created, we can select them using —selector <label_name>=<label_value>

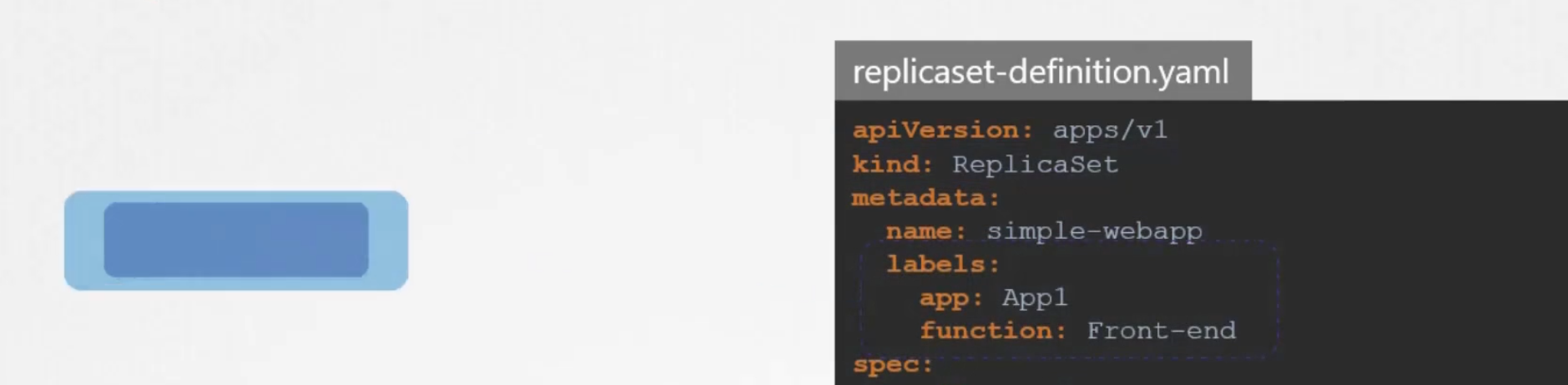
Kubernetes itself uses labels to group replica set
Here, labels defined in the last part (spec/metadata/labels) indicate the pods
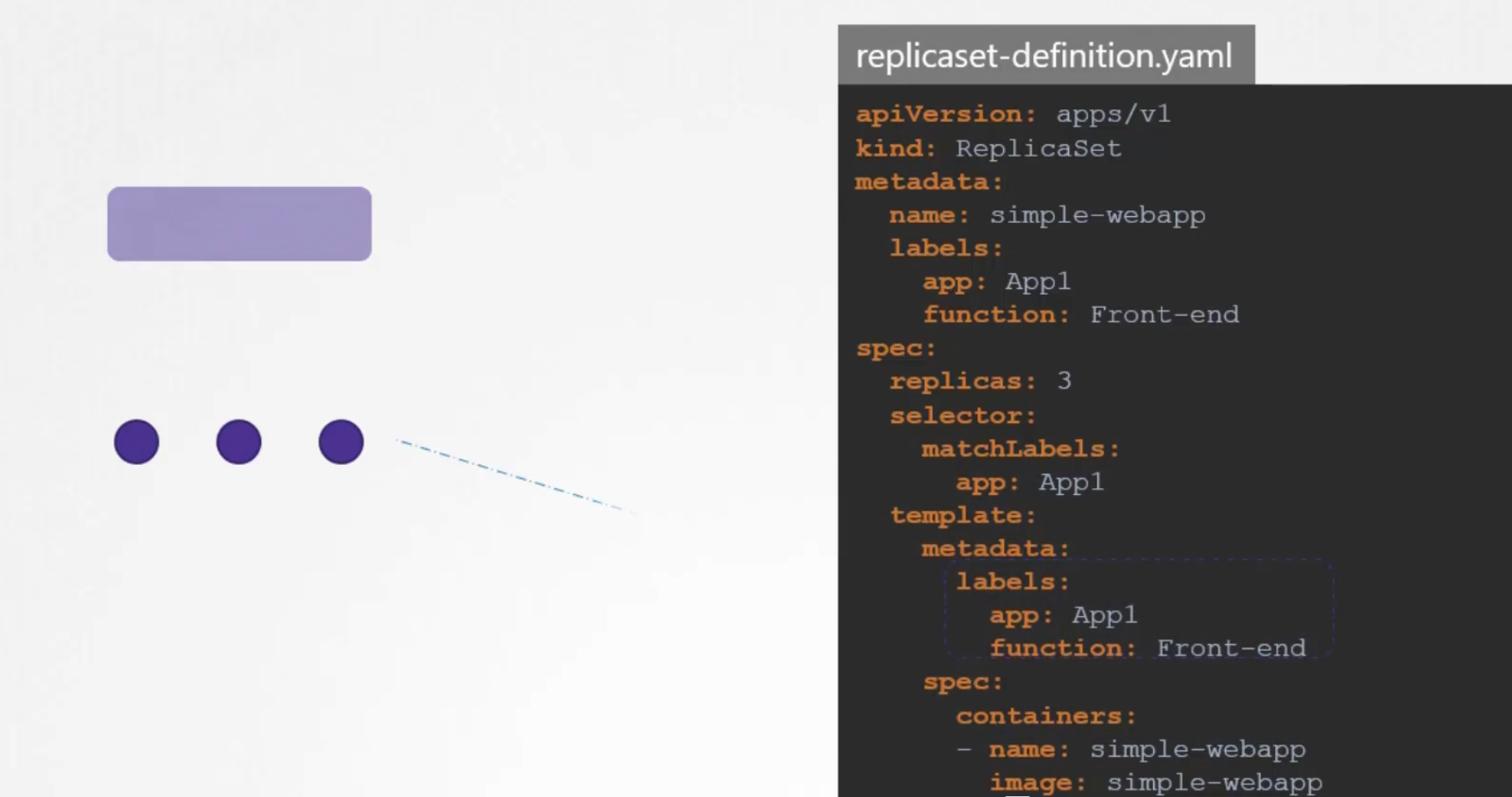
Labels in the top(metadata/labels) are the labels for replica set
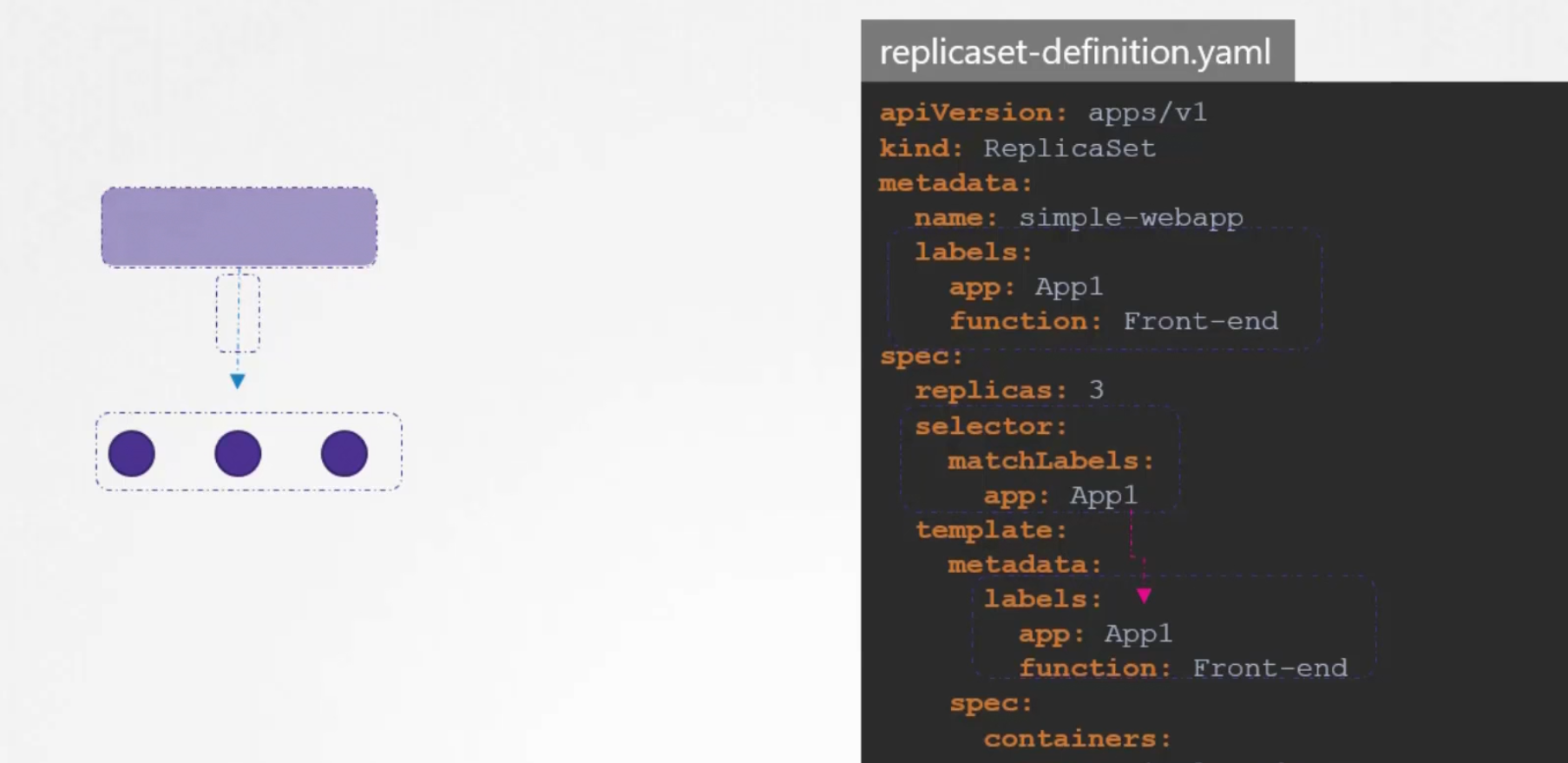
In order to connect replica set to the pods, we use the selector option and matchLabels within it’s yaml file (spec/selector/matchLabels)
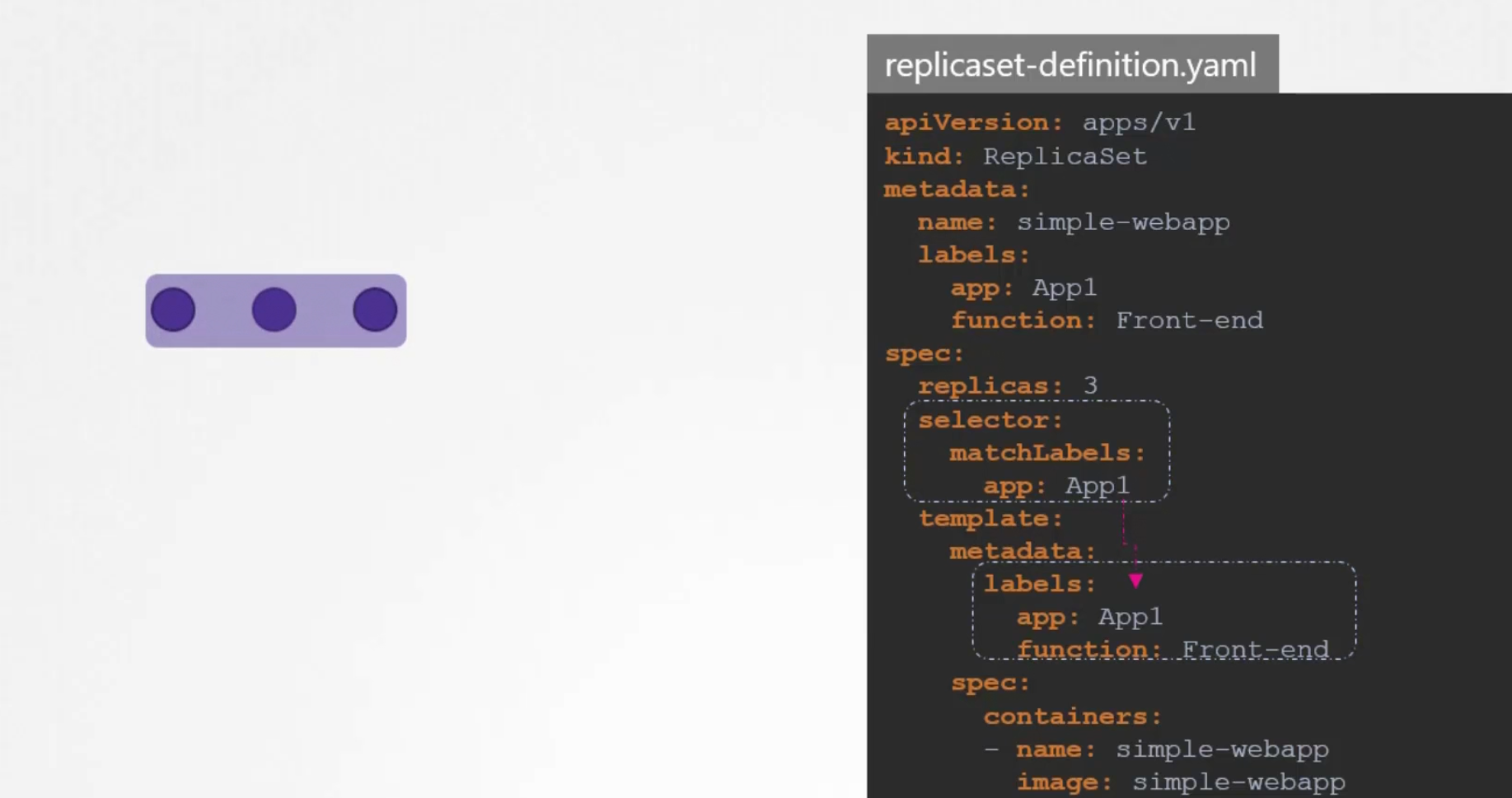
If the labels match, the replica set is created successfully
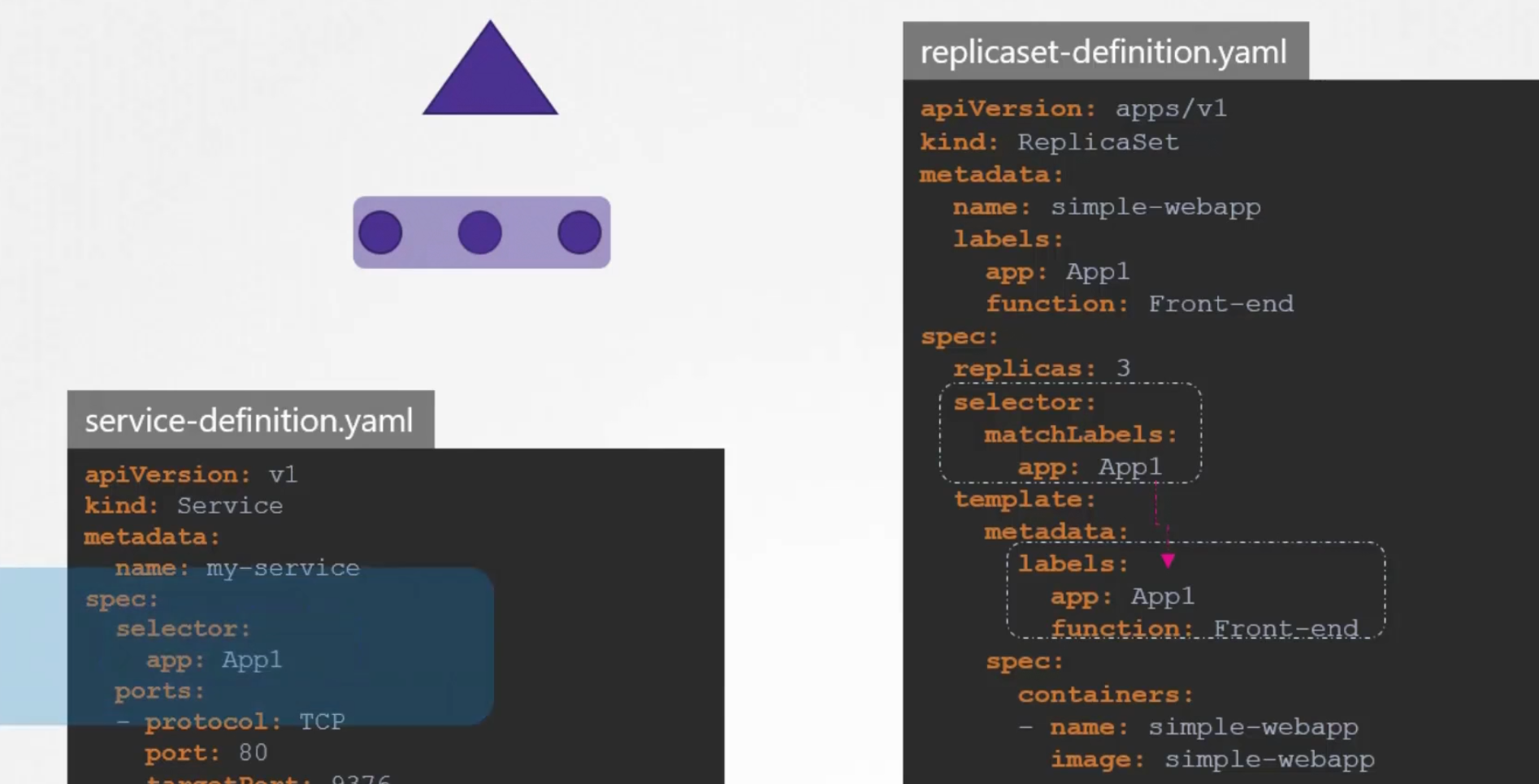
For services, it also looks for the labels in the pod (spec/selector)
Annotations
Annotations are used to keep extra information like buildversion, mail, contact number etc etc.

Taints and Tolerations
Assume that we don’t want this bug to sit on the person’s body. Therefore, we spray on the person with an anti bug spray.

We can call this spray as taint here
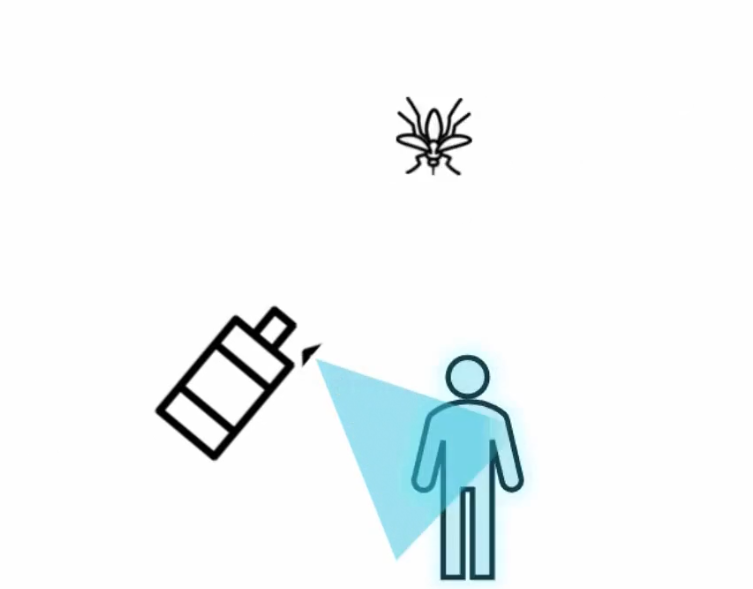
The bug is intolerance of the taint and therefore, can’t sit on the body

But there are other bugs which are tolerant of this taint and can sit on the body
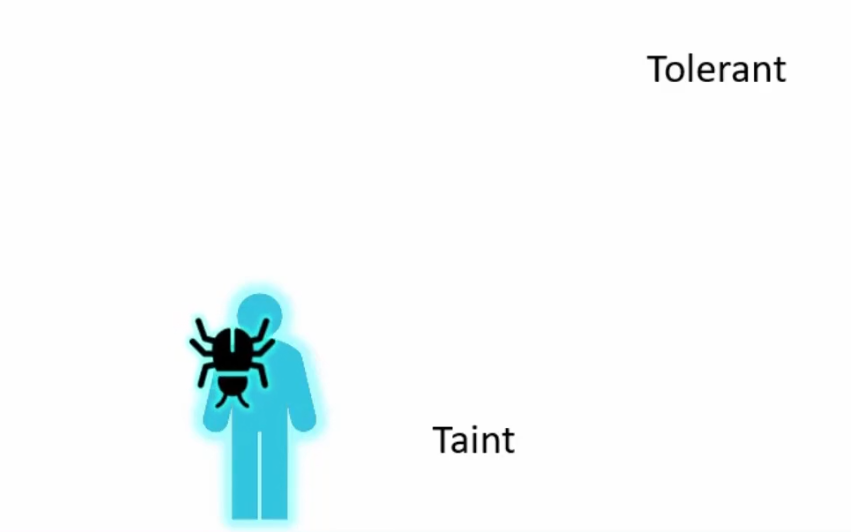
In Kubernetes, pods are bugs and humans are nodes
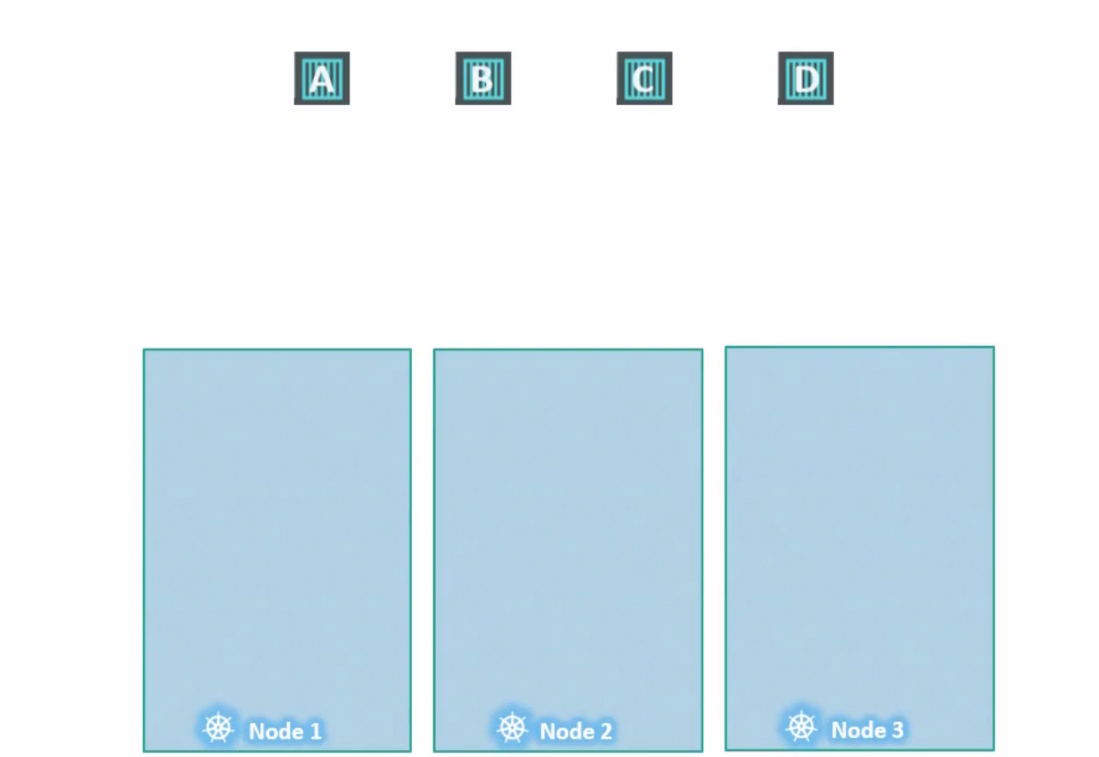
The scheduler distributes the pods in the nodes
Assuming there are no restrictions, it distributes pods in working nodes.
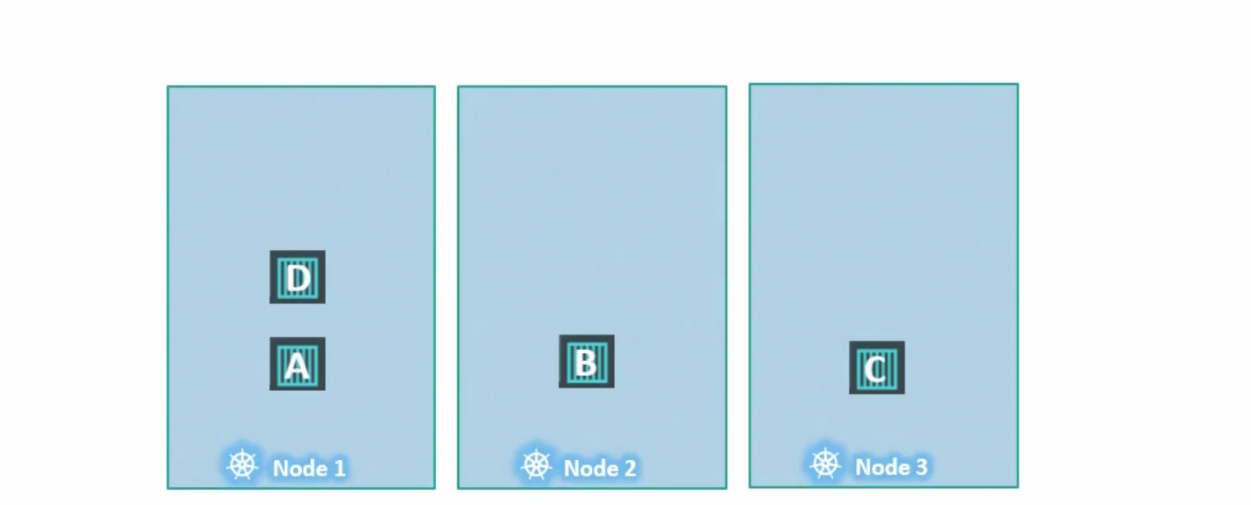
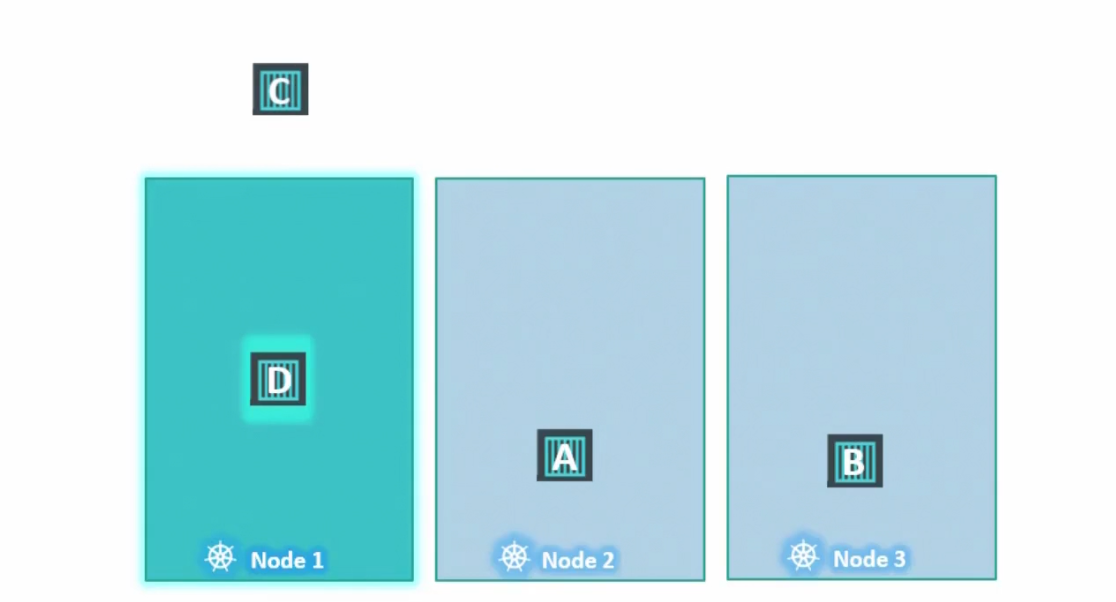
Now, assume that Node1 has some specific resources and we just need specific pods to be there.
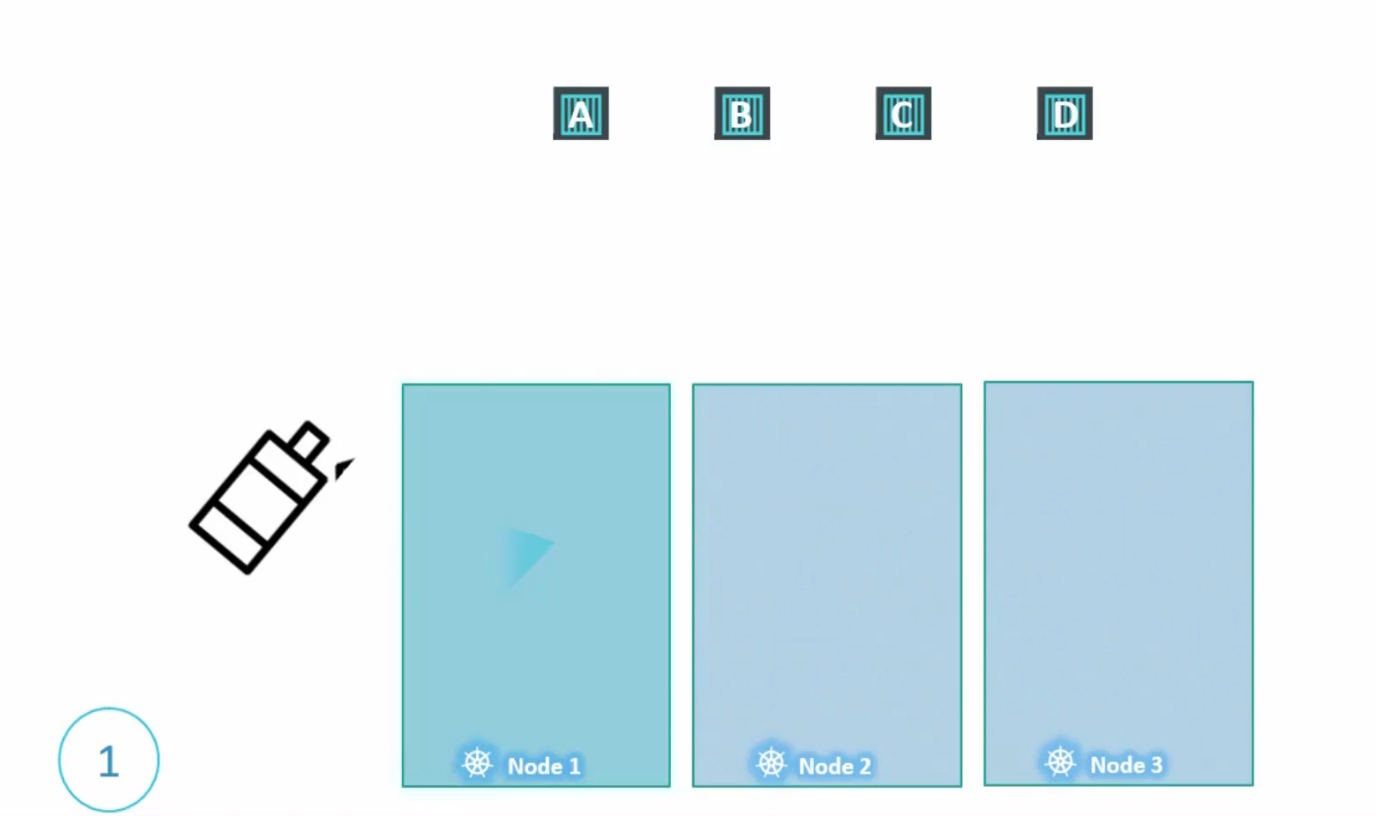
Let’s paint the Node1 with taint
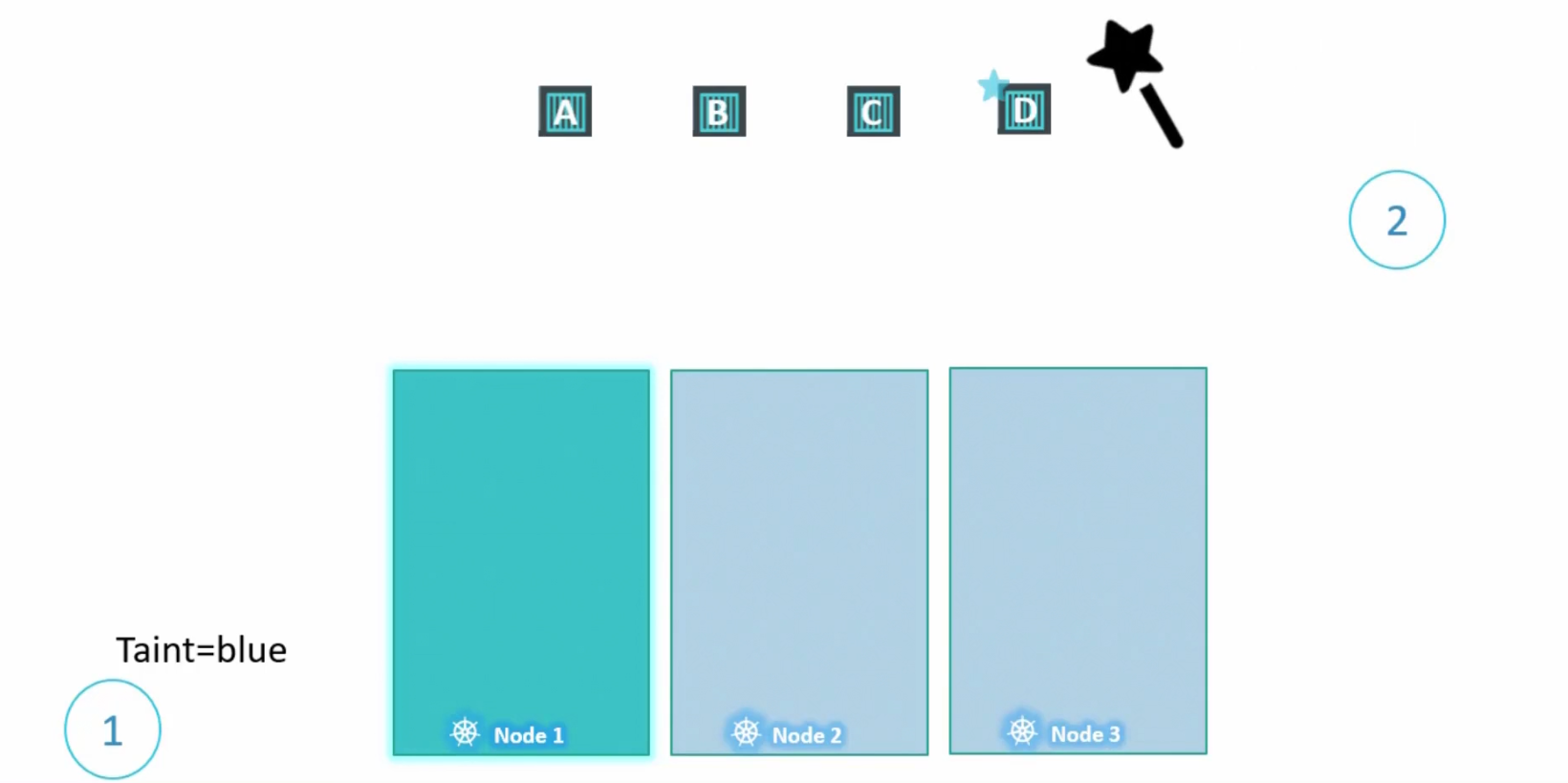
By default, none of the pods have any tolerance. Which means no pod can go within a node 1

But, we want pod D to be there in Node 1 and therefore, add toleration to it
Now, it can be allocated into Node 1

Here it is:
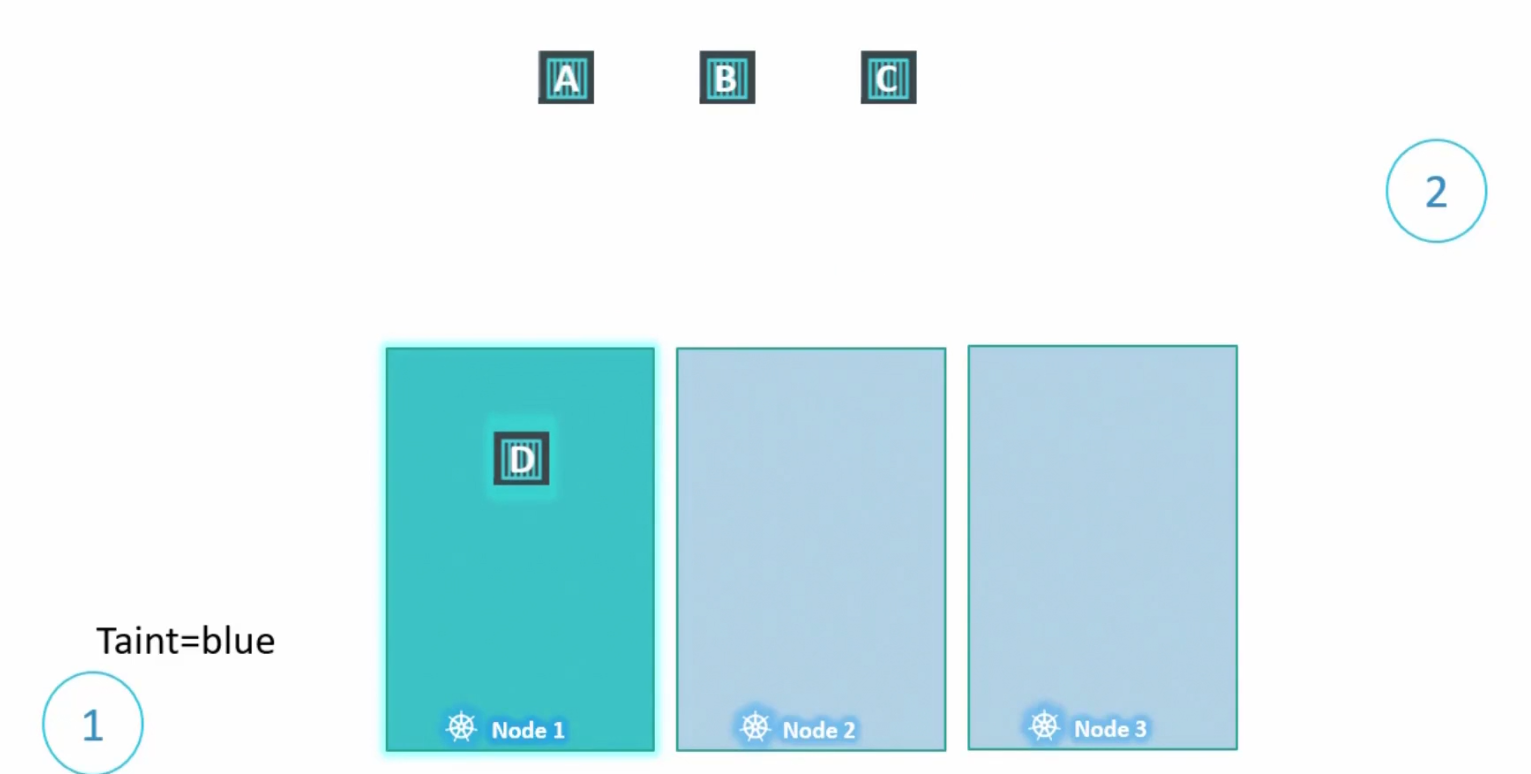
So, the scheduler can now put nodes in this manner
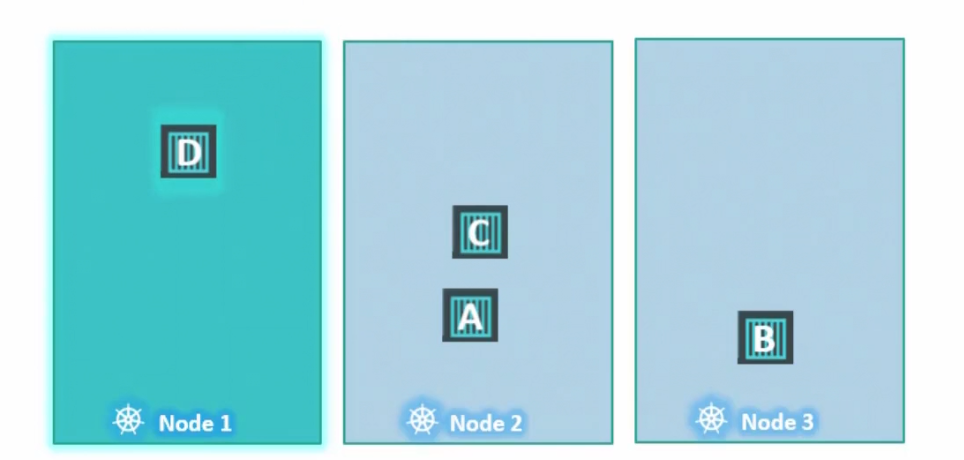
Surely, scheduler tries to keep pod A to Node 1 but can’t do it. Then puts it to Node 2. Then tries to keep pod B to Node 1 but can’t keep it.Then it puts it to Node 3 as Node 2 was already populated. Then it keeps pod C to Node 2 as Node 1 is not accessible by pod C.
Finally, Pod D is kept in Node 1 as it’s tolerant to the taint done on Node 1.
How to taint a node?
Here, We replace node-name with the Real node name and key=value as some value like “app=blue”

After that we use the effect (:taint-effect) applied to the intolerant pod.
This is an example:

For this particular example, if we want to give one pod some tolerance, that should be
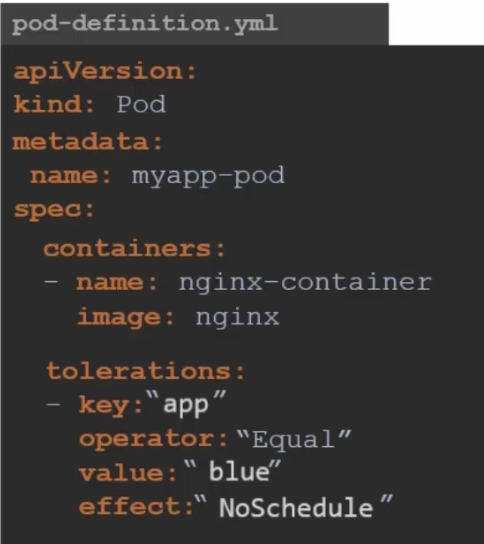
You can see everything in double quote and for app=blue:NoSchedule, we can see key: “app”, operator:”Equal”, value:”blue” and effect: “NoSchedule”
This means that only Pods with a toleration for app=blue will be able to run on that node. Pods without the matching toleration will not be scheduled on that node.
Now, talking about the NoExecute effect, assume 4 nodes are placed where no taints are applied to nodes and no tolerance are applied to pods

Now assume we add toleration to pod D for Node 1
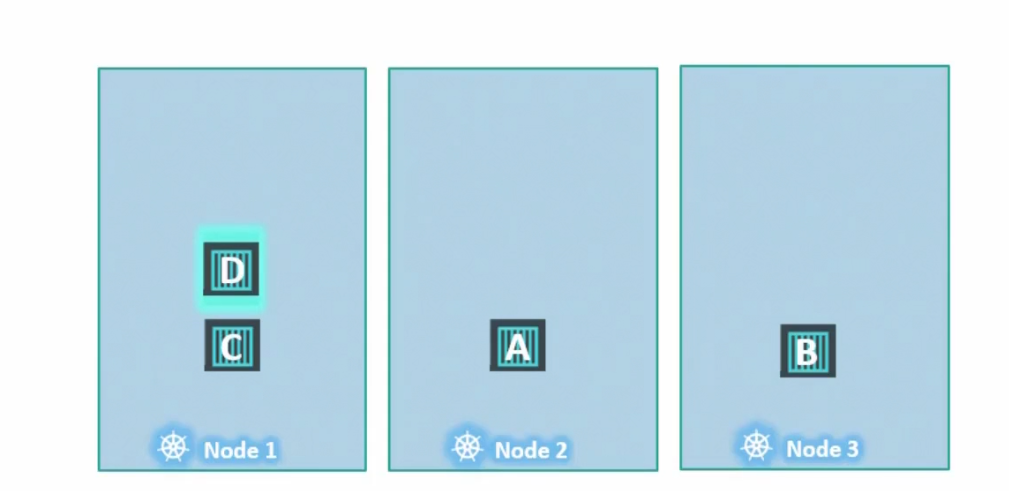
And add taint to Node 1
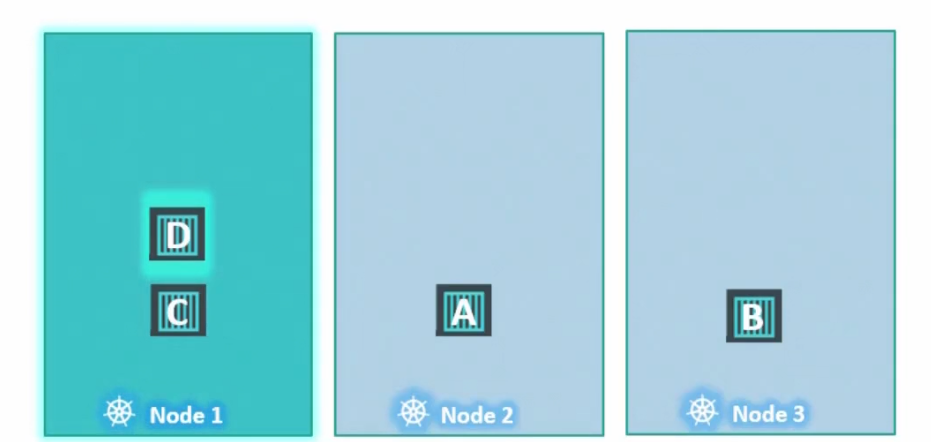
So, here pod D can tolerate Node 1 and it will remain here. But as pod C has no tolerance to Node 1, it will be out of the node and get terminated. So, it short, it will not be executed
Also, keep in mind that taint and tolerance does not guarantee that a pod will be there in a node. For example,
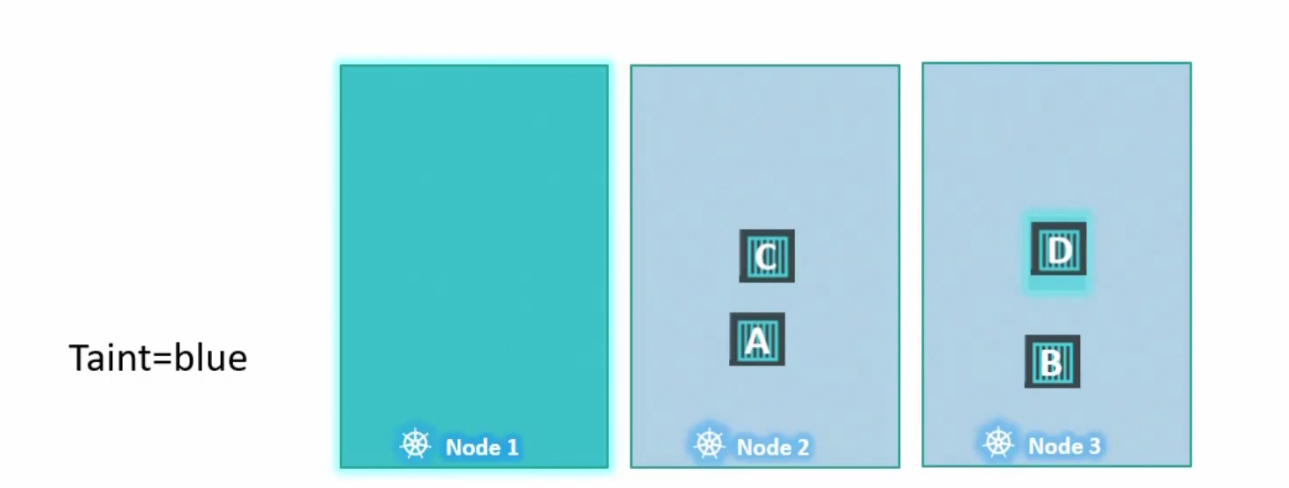
Here, pod D should have been in Node 1 because it has the tolerance to Node 1 but it also have access to Node 2 and Node 3. So, it can go to other nodes.
Note: Taints (Applied to nodes) and tolerances (applied to pods) are just a way to unlock the door of a house (node) by a human (pod). But there is no path defined that a human (pod) has to enter a specific house (node). If there are other house which are already unlocked, he/she can go there too.
Also, keep in mind that we also have master node which manages everything for us. We can’t schedule any pod there because Kubernetes already has done a taint on it
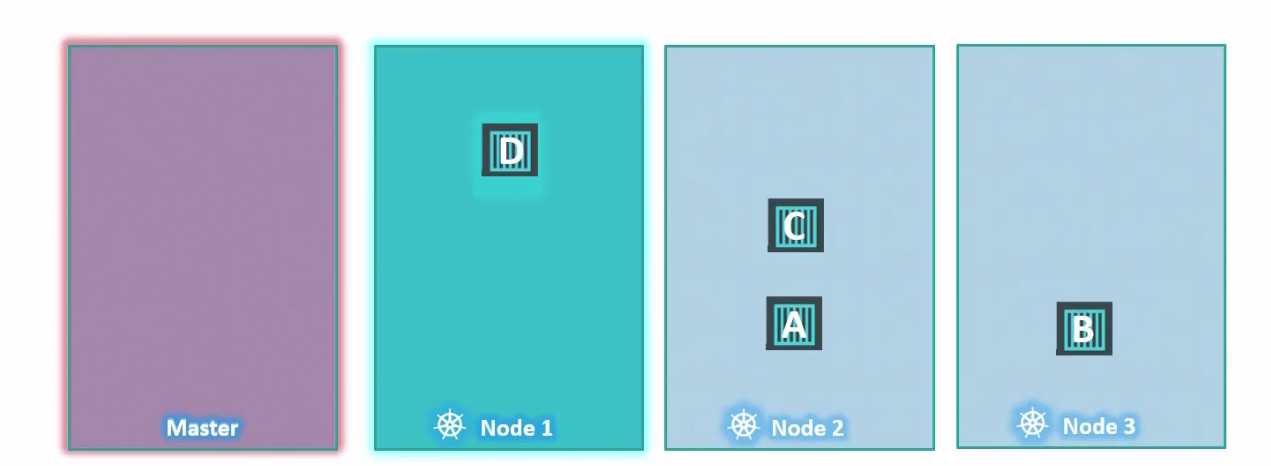
We can look that with this command
kubectl describe node kubemaster | grep Taint
Although I use minikube and it does not have a master node called kubemaster

Node Selectors
Assume that you have nodes with higher allocations and lower as well
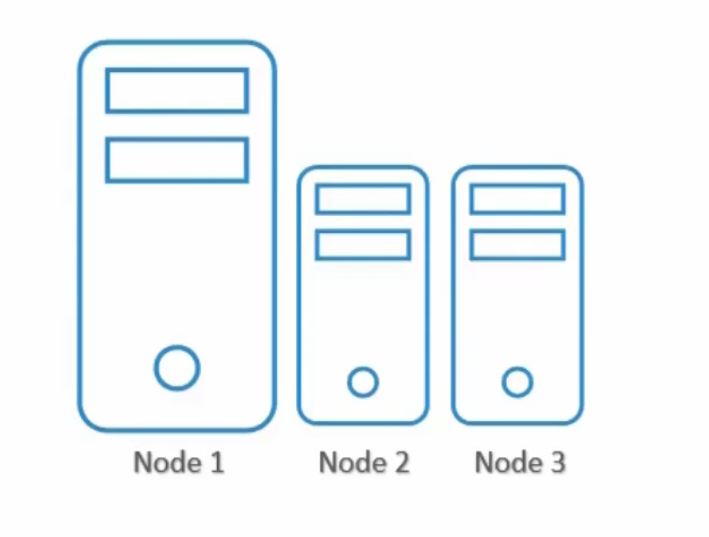
We also have pods which has different requirements of power or others
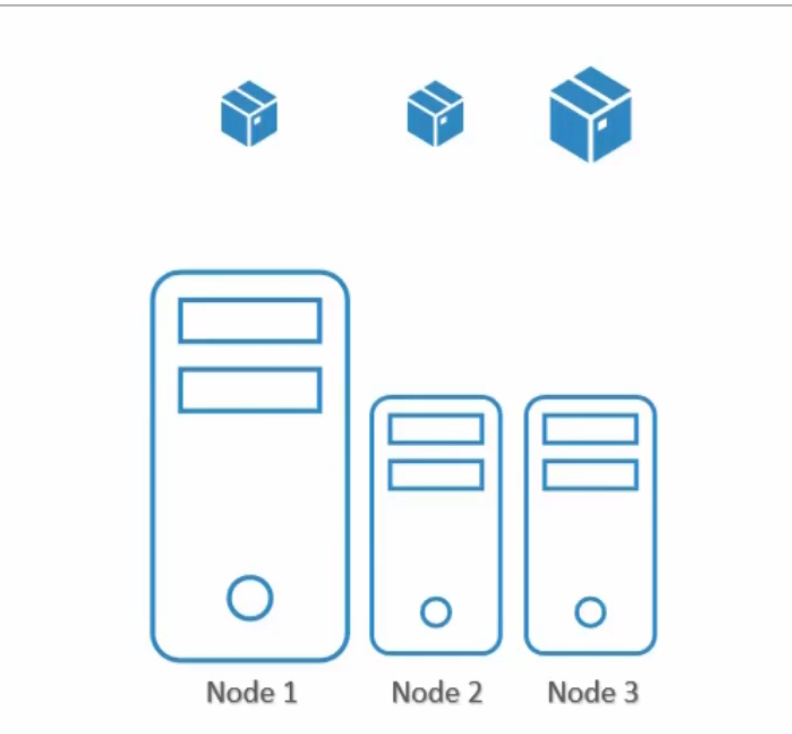
Now, if we don’t specify anything, pods will go into whatever node they wish to
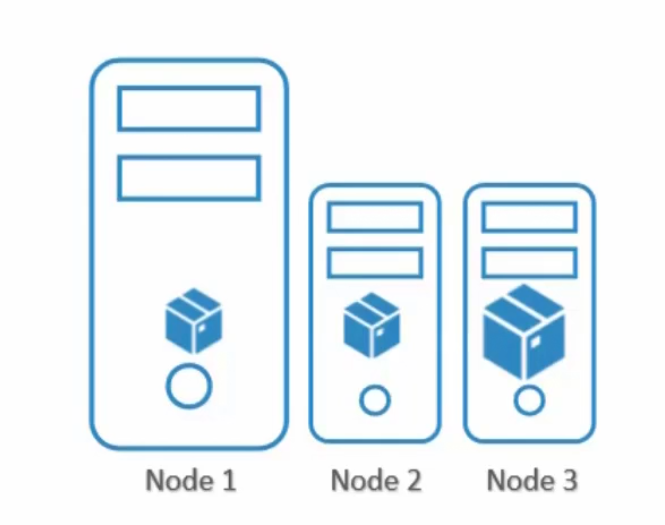
Surely, we can see Pod 3 needs to be in Node 1 as pod 3 requires more power which is there in Node 1.
To solve this issue, we can add nodeSelector in the pod’s yaml file

Here we did set label size to be Large for the pod. Also, we are expecting to add “size: Large” as a label for the node.
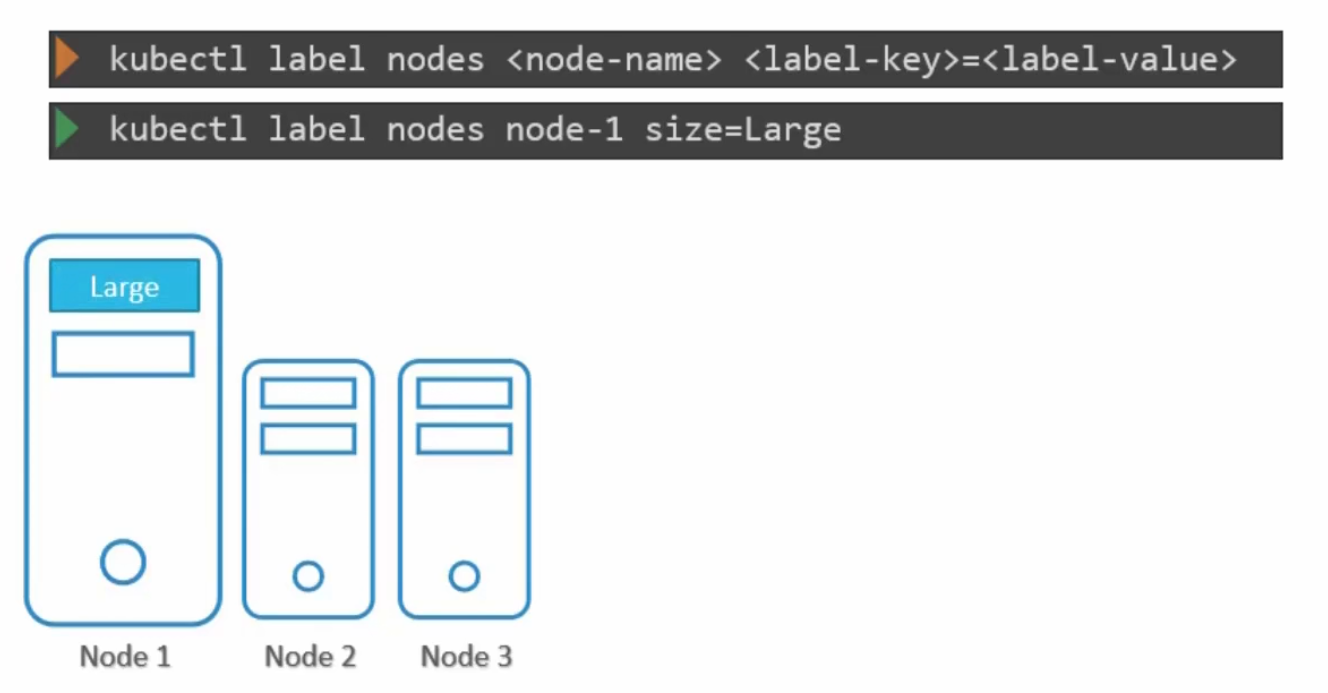
Note: We need to apply this label first to node and then create a pod with that nodeSelector option while having the same label as the node expected.
So, the pod can now know which node to go for once created.

Node affinity
While using node selectors, we couldn’t use OR, NOT small etc. We could exactly mention which node to go for. That’s it!!
Now, we can do the same task using node affinity

This time, we need to add a lot of things with affinity option
Here, in this image both of the yaml file has the same functionality. But let’s focus on the right one.
This time, if we want the pod to be in Large or Medium (labelled) node, we can add the values (check values section)
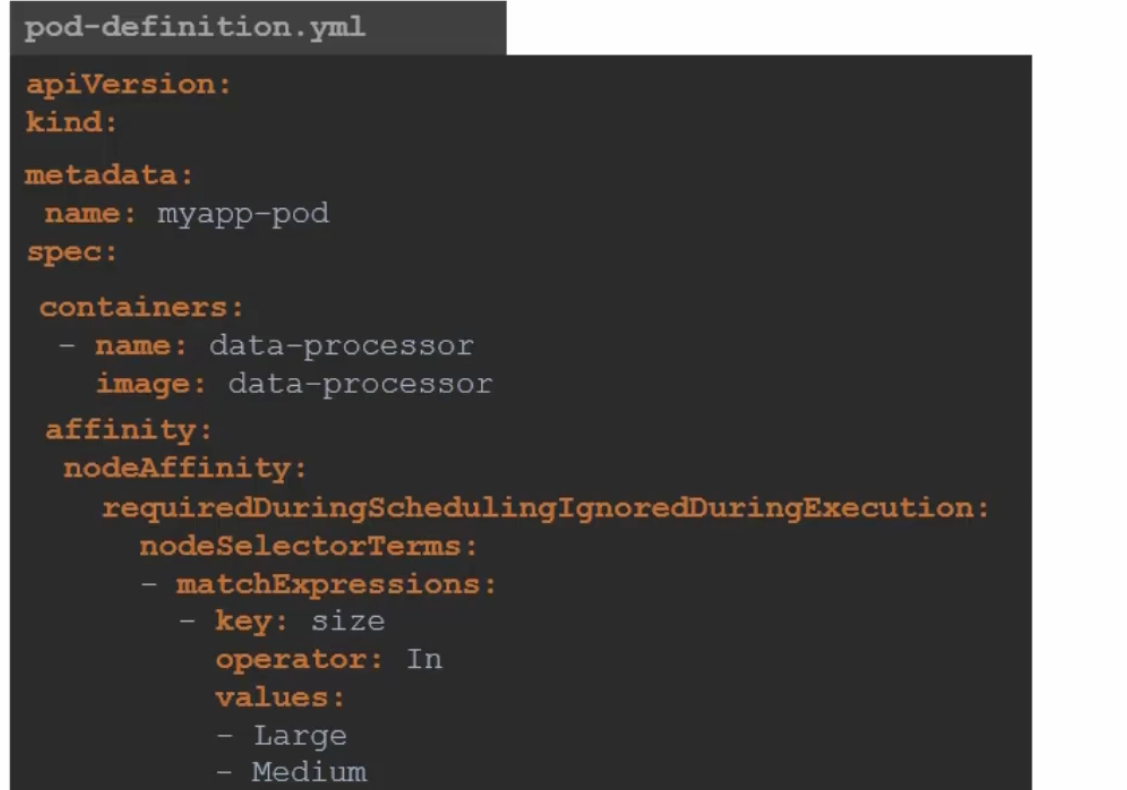
Or, if we want to specify that the pods should not go to a Node which has a small size (Operator: NotIn values:Small)
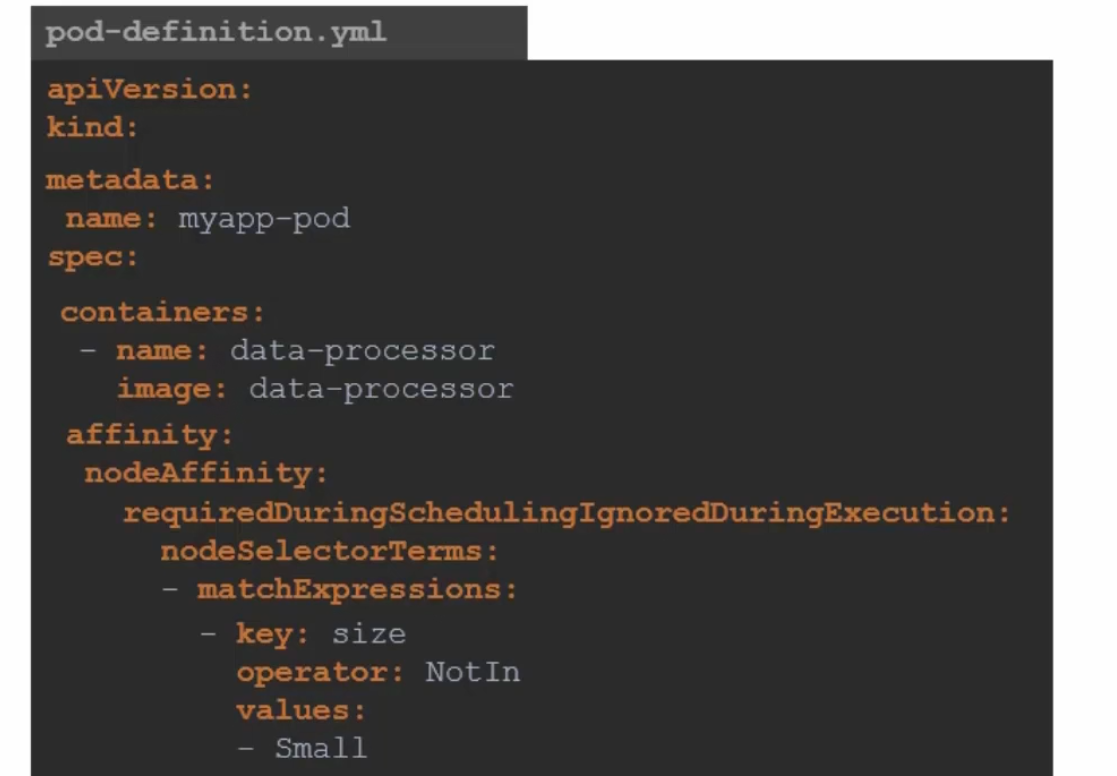
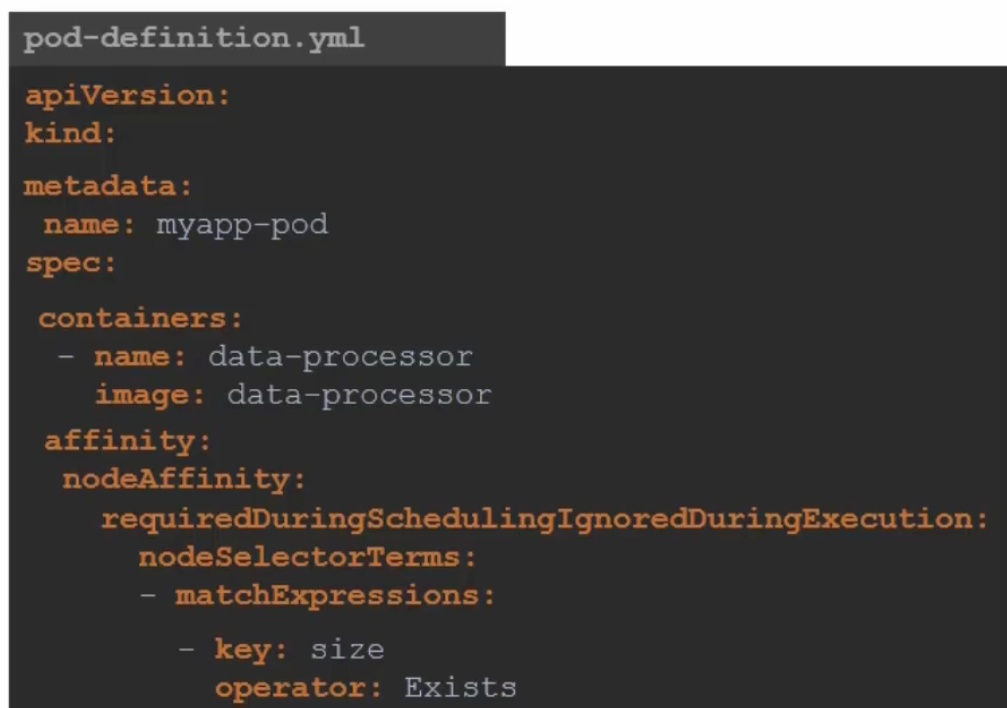
Operator can also look for Existing nodes
User case of affinity: What if one changes the labels of the nodes (Large, Medium etc.) in future?
This is why we have affinity type added
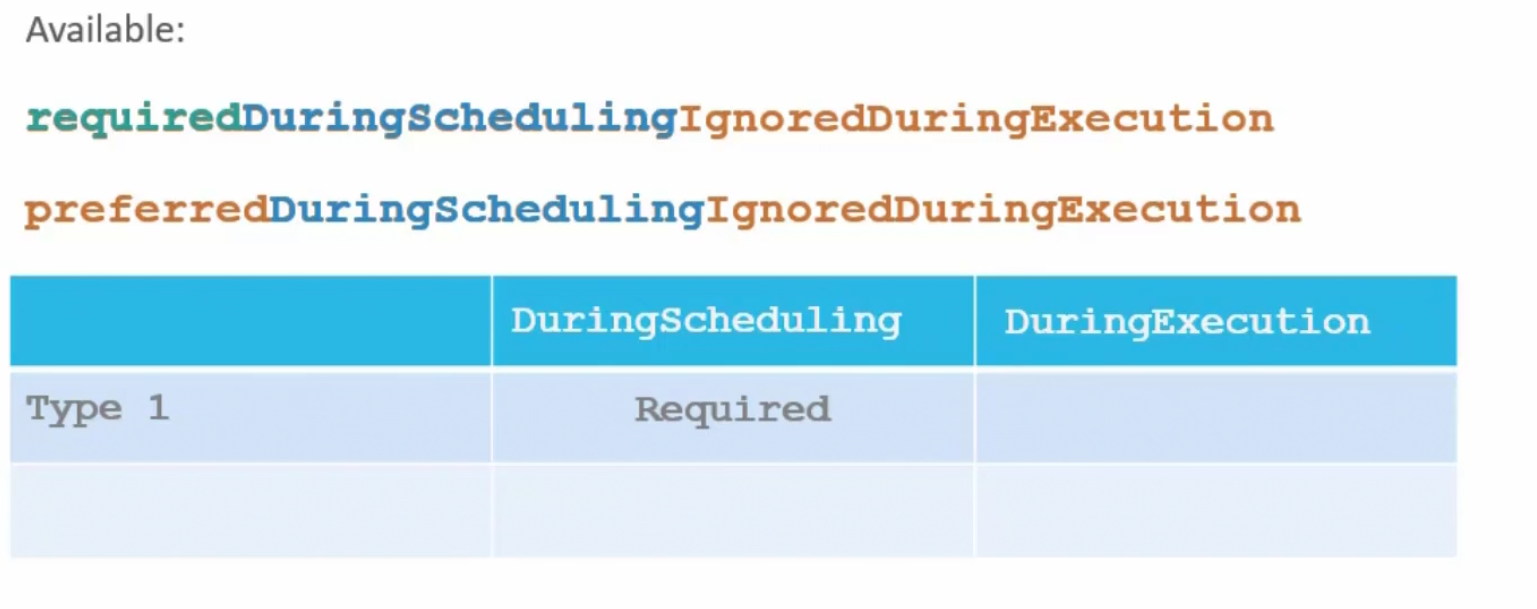
Also, we need to know about these concepts:

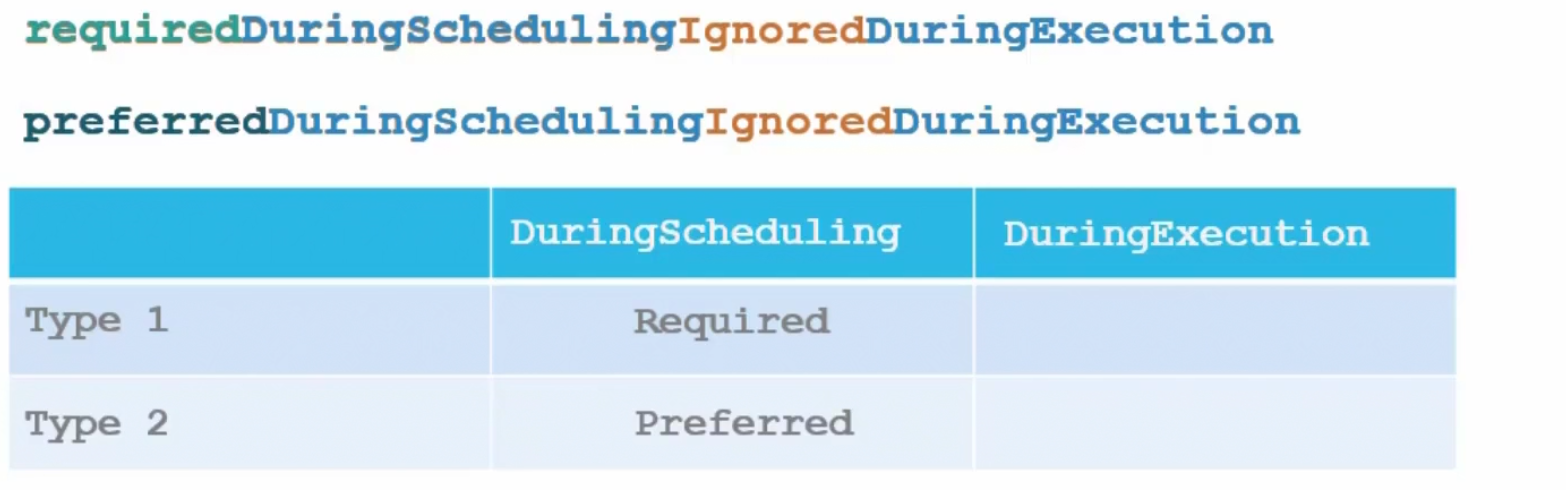
First 2 are available and planned 2 are planned to be included in kubernetes.
Let’s explore the available option:
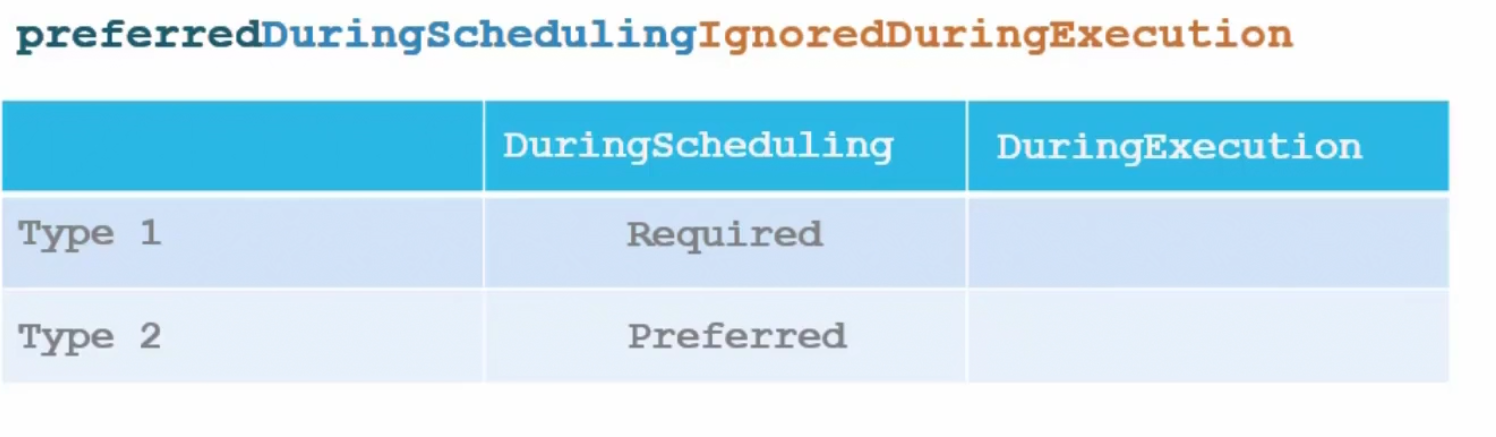
Here if we are launching a pod and use requiredDuringScheduling and it finds that our desired Label(Large, Medium) is not there , it won’t schedule the pod. Here, pod scheduling to specific Node is more important.
But if we use preferredDuringScheduling, the scheduler will look for our desired labels. If not found, still it will add this pod to an available node. Here, pod deployment is more important.
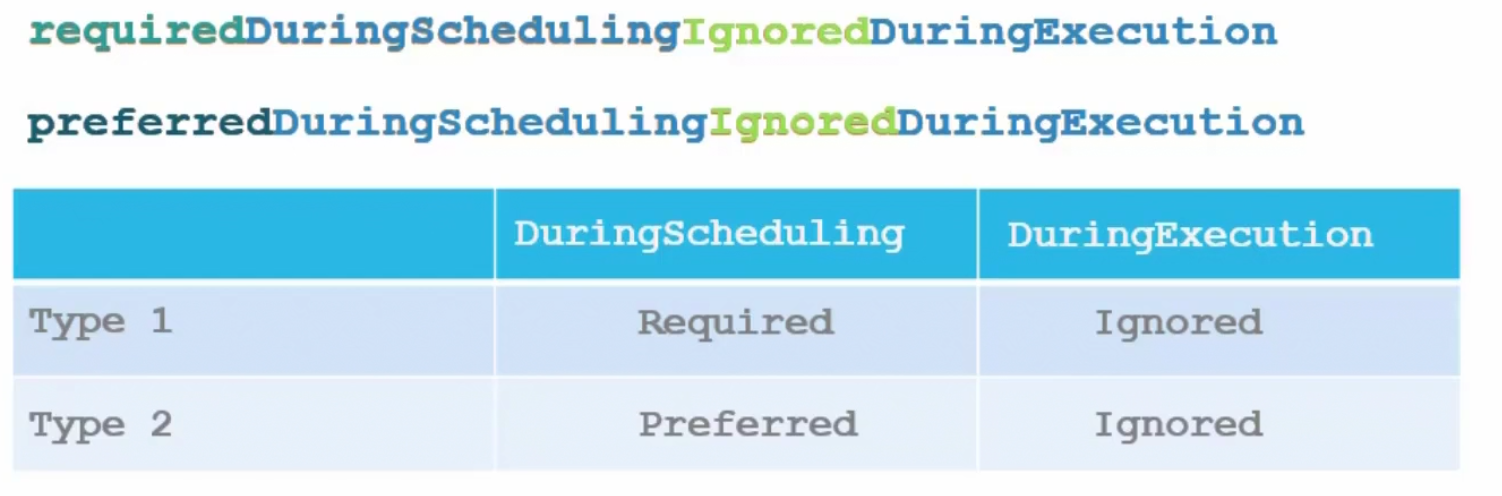
Now, assume the pod is up and running on a node.And you decided to change label of a node
If we have IgnoredDuringExecution, pods will still run on the nodes despite the labels for the nodes being replaced with newer ones.
So, to make the best use of taints and tolerance and node affinity, we use taints and tolerance first and then apply node affinity. Thus we can appoint pods to our desired node.
Resource limits
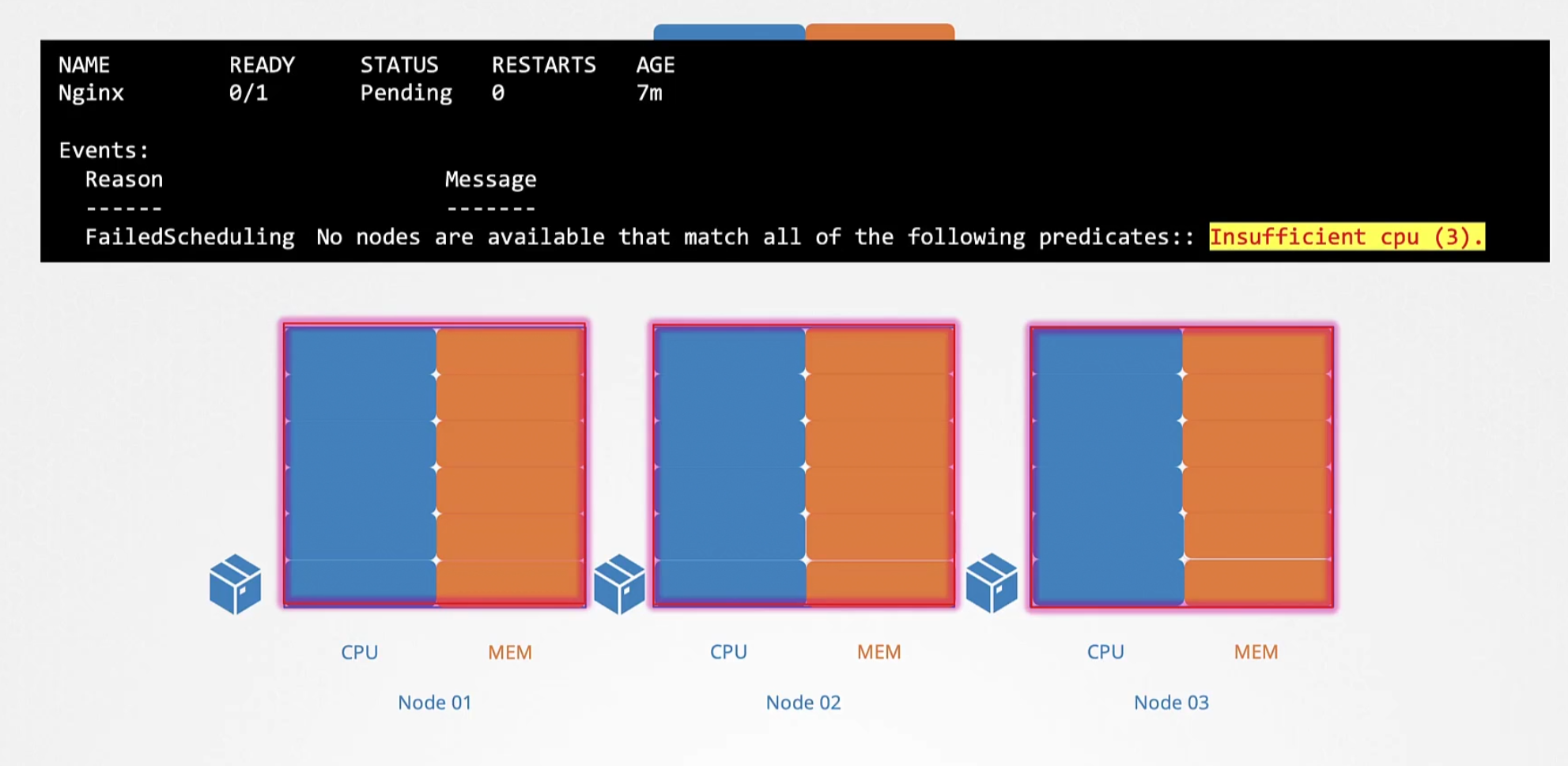
Scheduler assigns pods to a node depending on the free resource availability in nodes.
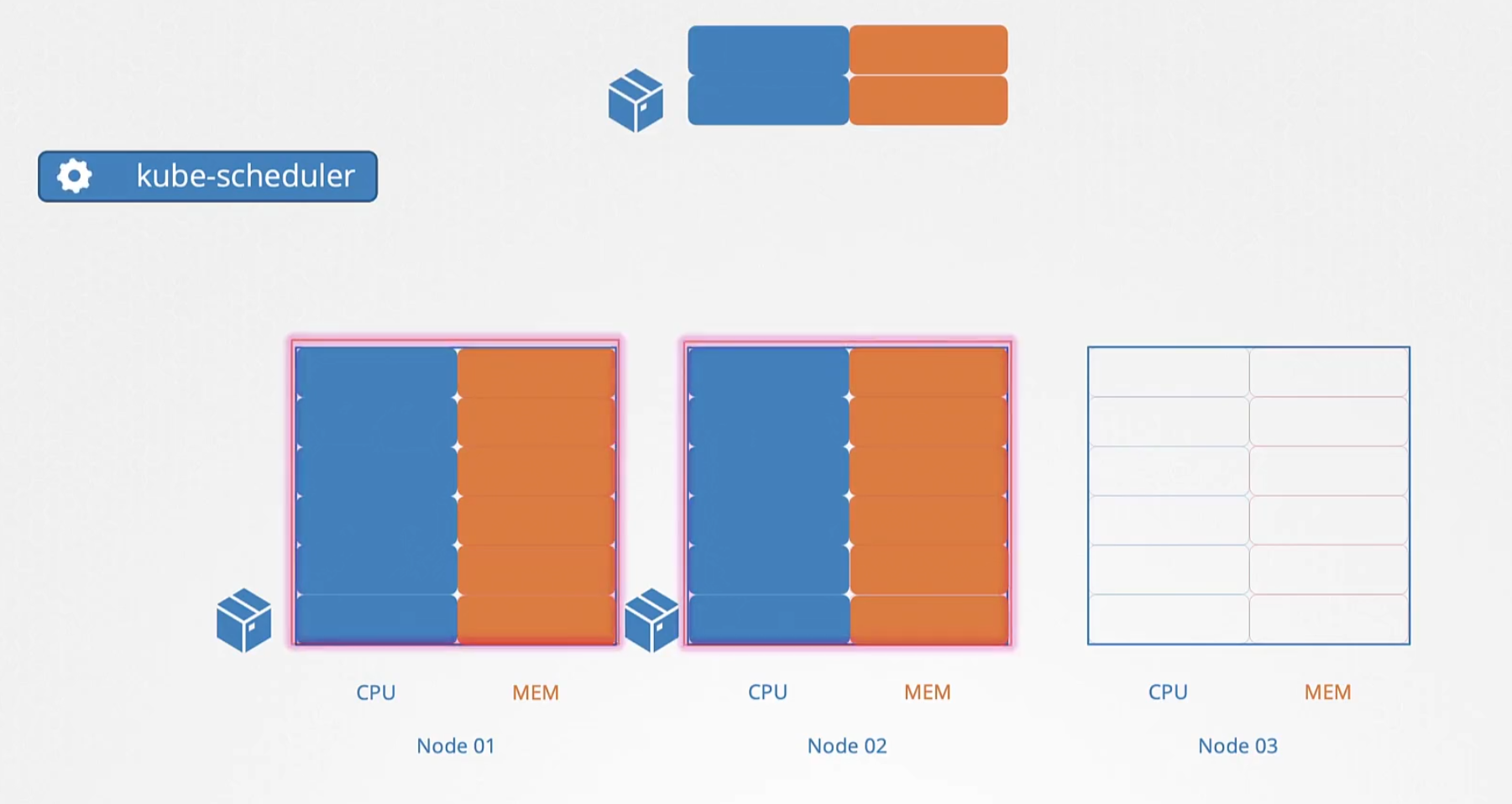
Here, we can see node 1 and node 2 has no resources (full of resources, therefore having no resounces) available and so, a new pod should be kept only in node 3
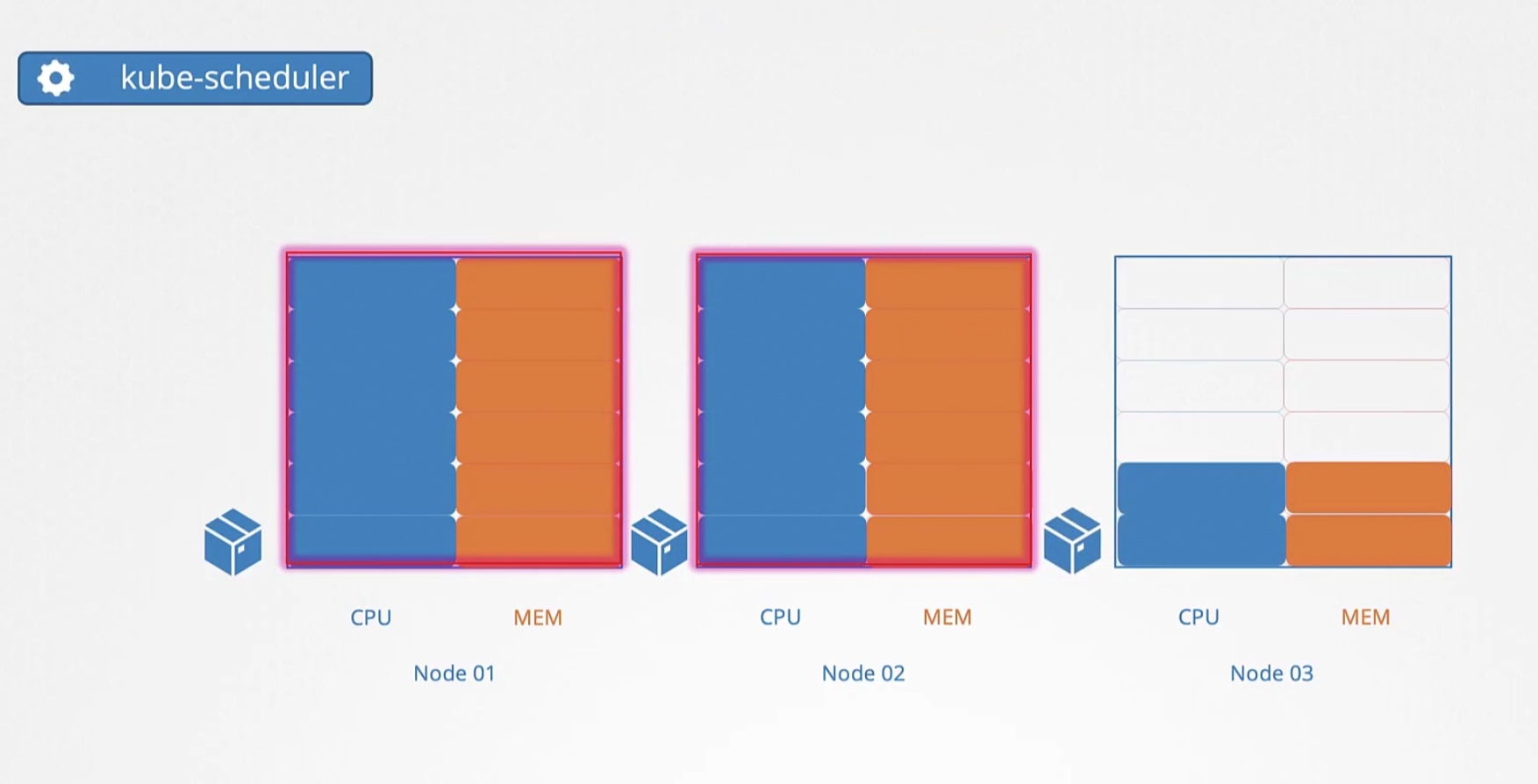
But if the resource limit is full in all nodes, you will see the pod is not assigned to any node and will be in pending state
So, how to set the resource requirement for a pod?
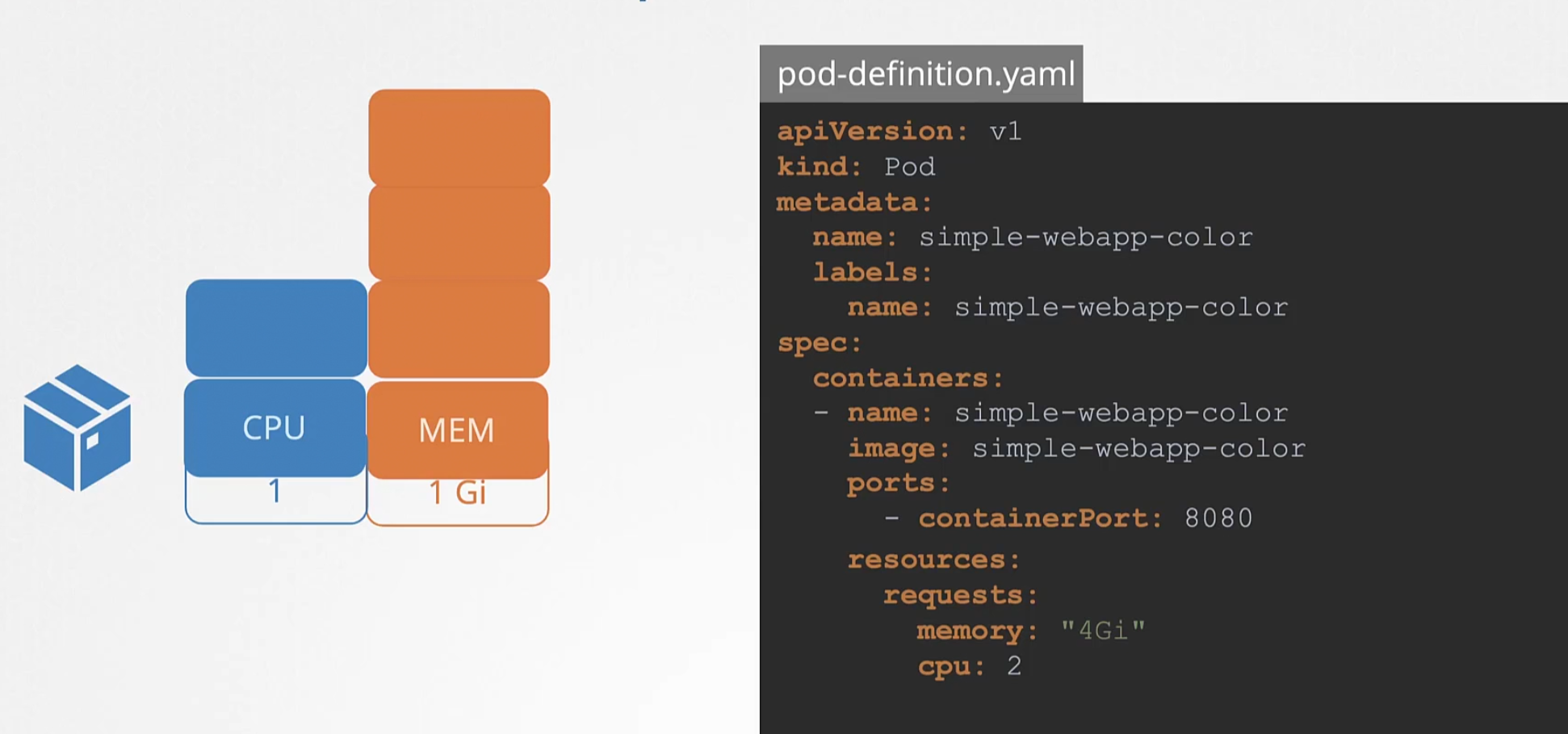
We do that in our yaml file while creating the pod. We add resources section(resources/requests) and mention that we need how much memory and cpus (4 Gibibyte of memory and 2 CPUs)
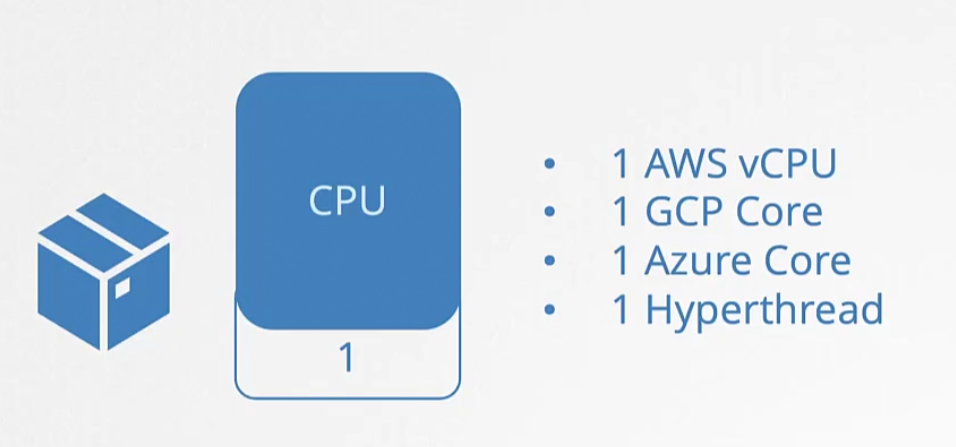
For CPU, the value 1 is equivalent to these
For memory, we use MEM. We can also mention the byte value here.

For pods, we can also specify resource limits
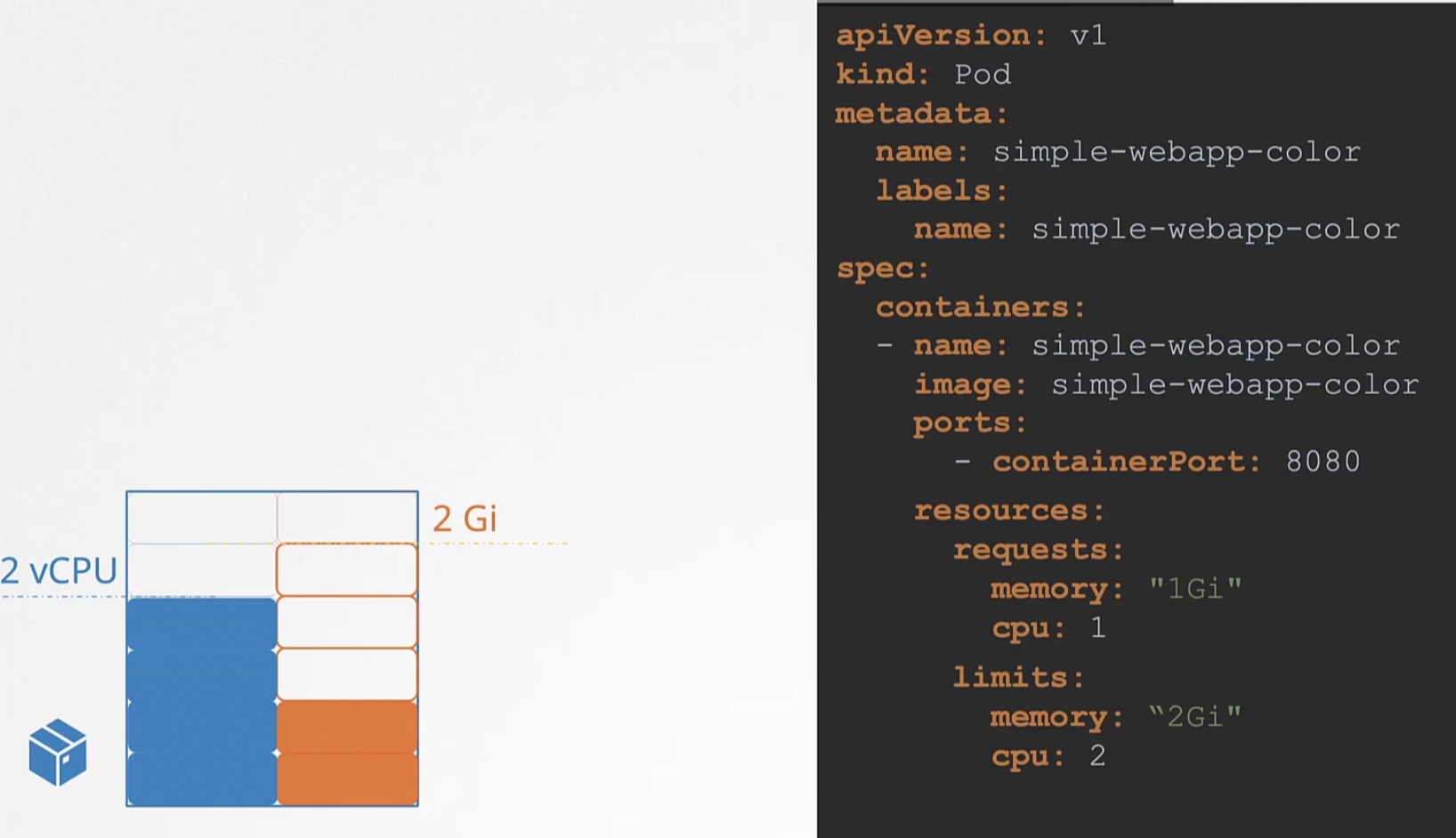
If a container tries to exceed the limit, for the case of CPU the pod “THROTTLE” the cpu.
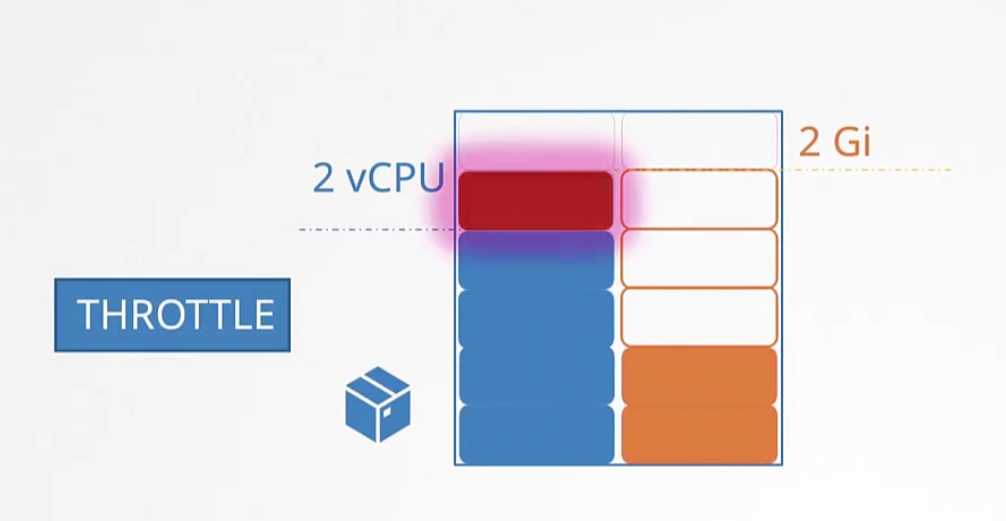
For memory, a container can use more memory than it’s limit. So, it can use the memory but then
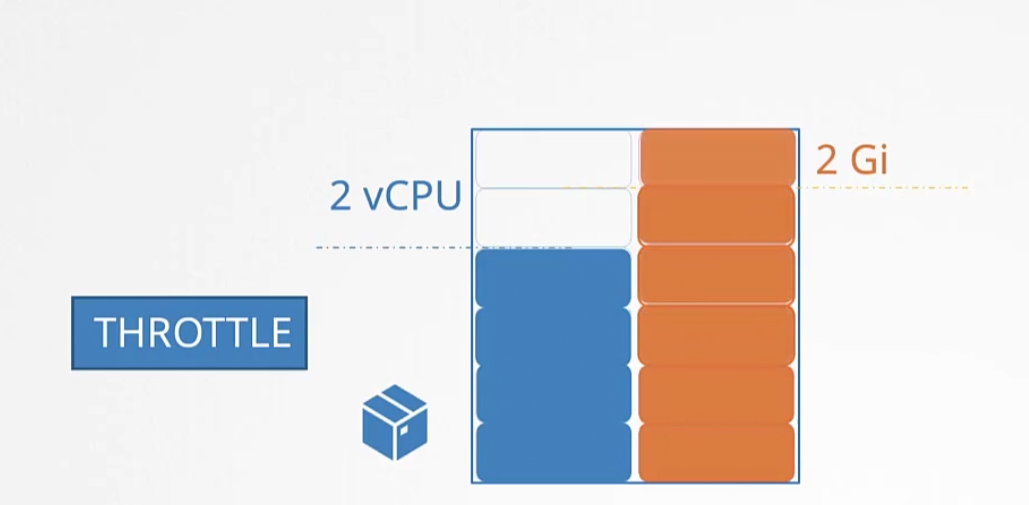
the pod will be terminated and will be shown “Out of Memory”
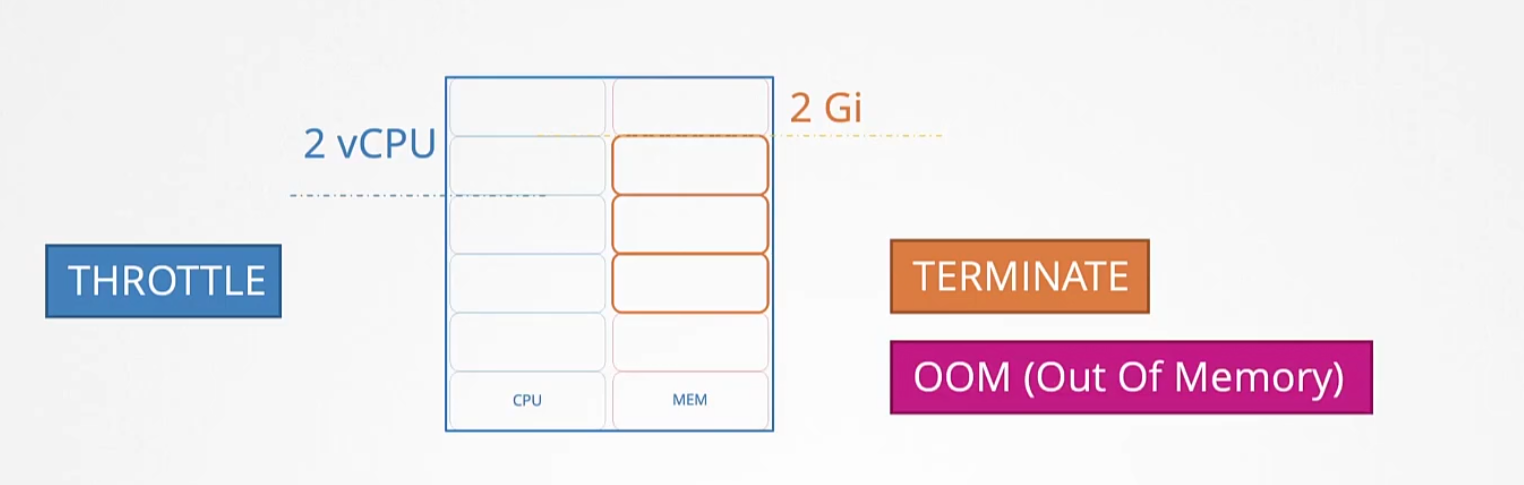
Note: By default there are no limits set and so, you need to set the limit for nodes and containers.
So, in general we have 4 cases for vCPUs . Starting with left (Case -1)
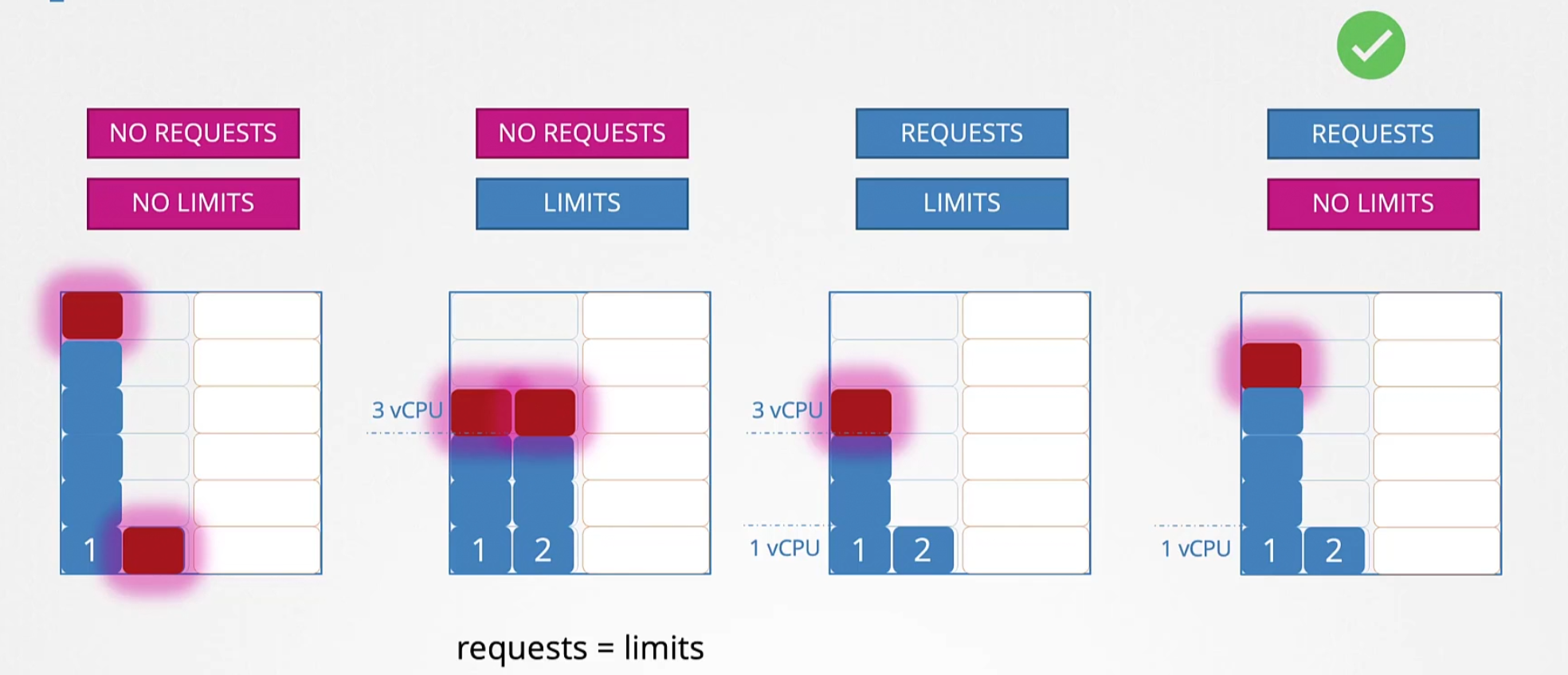
when no request (request is set in the yaml file for pods which is the minimum requirement of a pod) and limits are set, a pod (shown by number 1) can exceed the limit.
Case -2 : when no request is set but limits are set for pods. Here, limits work as a request and can’t exceed the limit. Here, pod 1 and 2 both could not exceed limit 3 vCPU.
Case -3: Here request and limits are set. For pod 1, request is set to 1vcpu and for pod 2 request is set to 1 vcpu. But the limit is 3 vcpu.So, pod 1 and 2 can’t exceed it.
Case -4 Here request is 1 vCPU for pod 1 and 2 but pods can use all of the cpu powers if they need. This is the ideal case.
Note: Requests are the minimum requirement for a pod and limit is the maximum number of vCPU one pod can use.
Again for the memory,

When no request and limit is set, pod 1 might take all the space and also prevent pod 2 to use its spaces.
For case -2 : When a limit is set for pod 1 and 2, they can’t exceed the limit
For case -3: when request and limit is set, again they can’t exceed the limit
For case -4: This is important. If no limit is set and there are free spaces, one pod might use the spaces . But if another pod wants to use those spaces in future, the whole pod has to be terminated. This is not what happens for vCPU because , it can throttle then. But for memory, we can’t do it and need real memory.
Note: Request memory is the minimum memory required for a pod whereas, limits are the max they can use. Although technically, they always can exceed the limit.
Now, we know that the limits and others are not set by default. But we can set the default limit by this yaml file
Here is an for the cpu limit range,
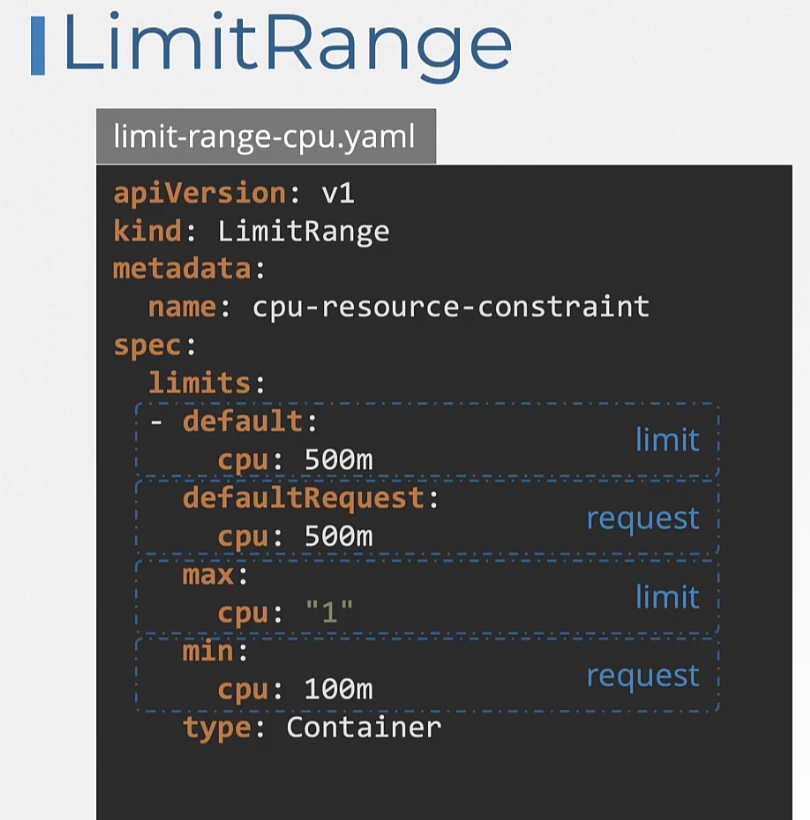
Here is one for memory,
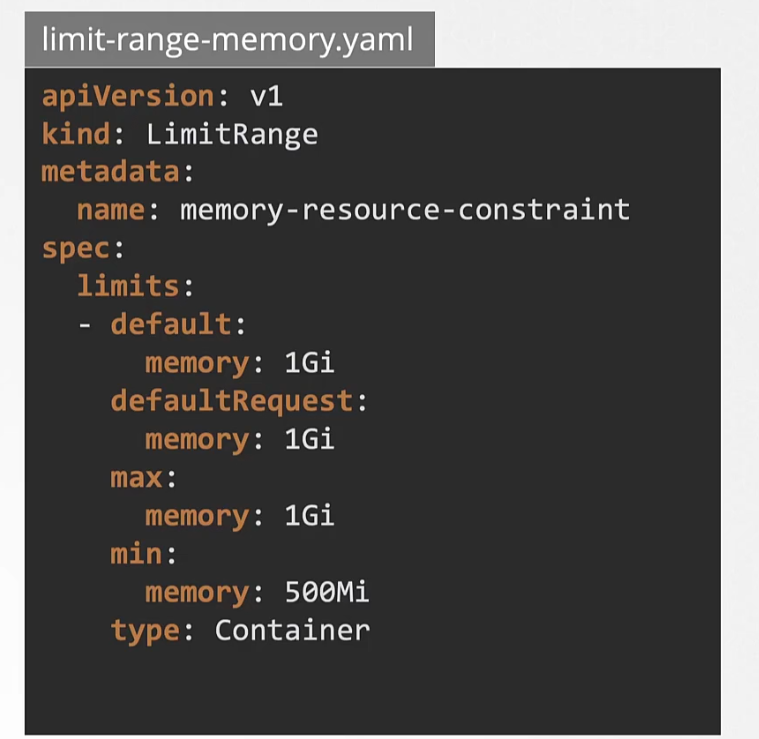
We can also set resource quotas so that, pods in total can’t exceed that

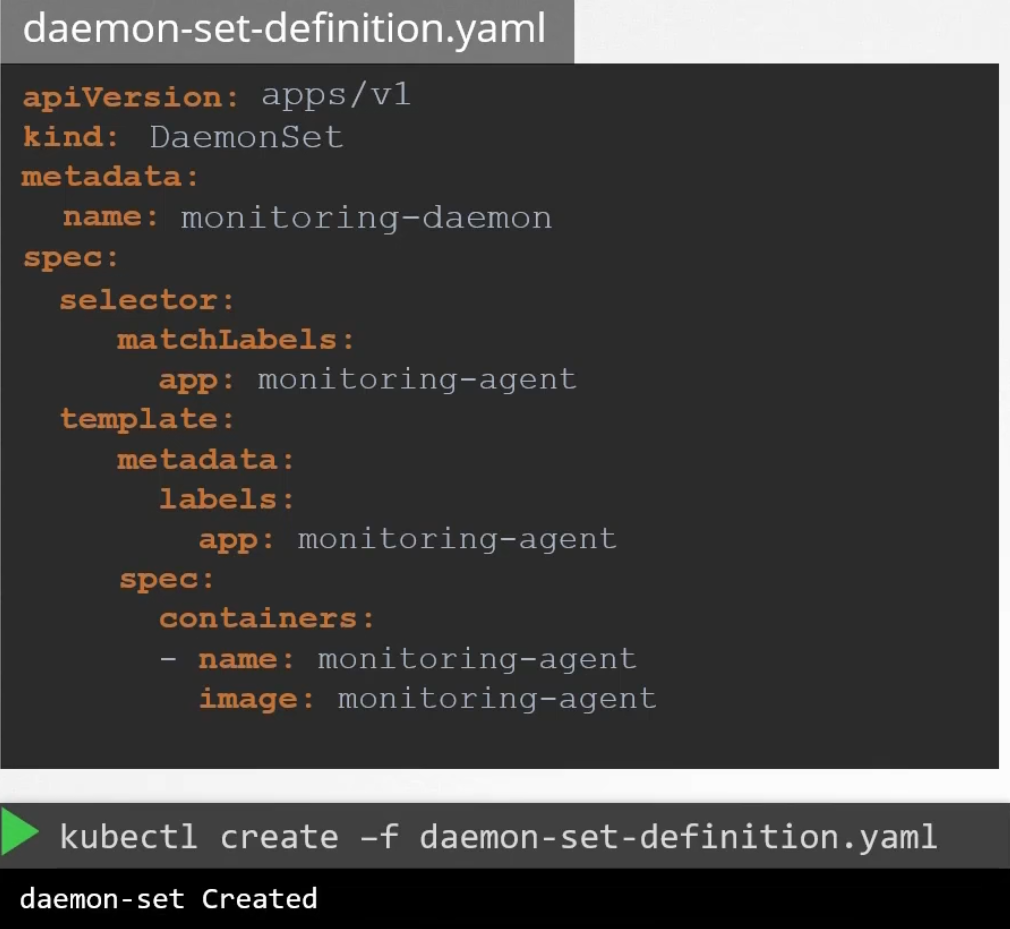
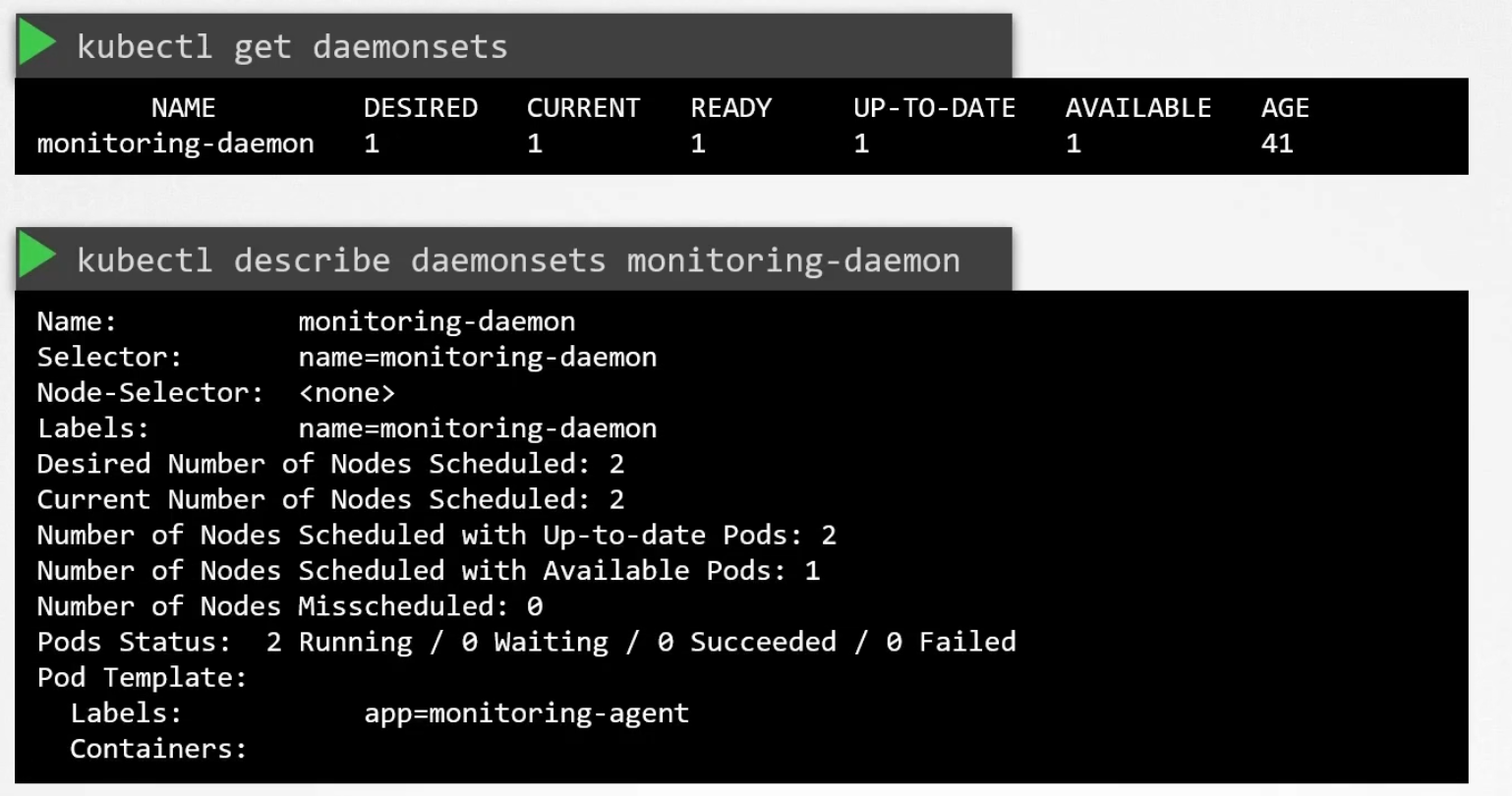
Daemon Sets
Daemon set created 1 copy of a pod in all nodes.
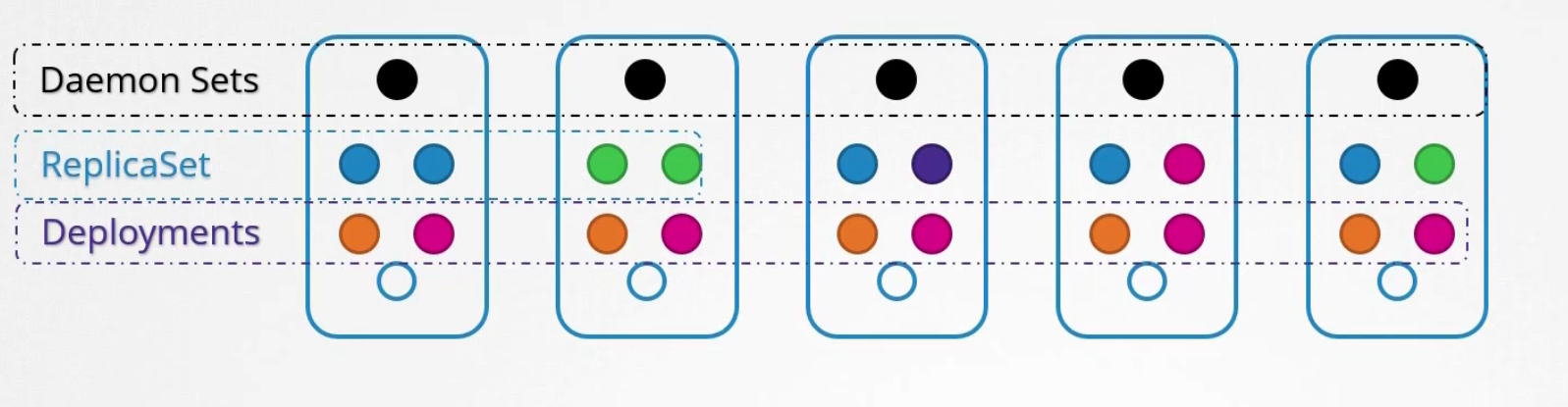
When a new node gets added to the cluster, it created a pod
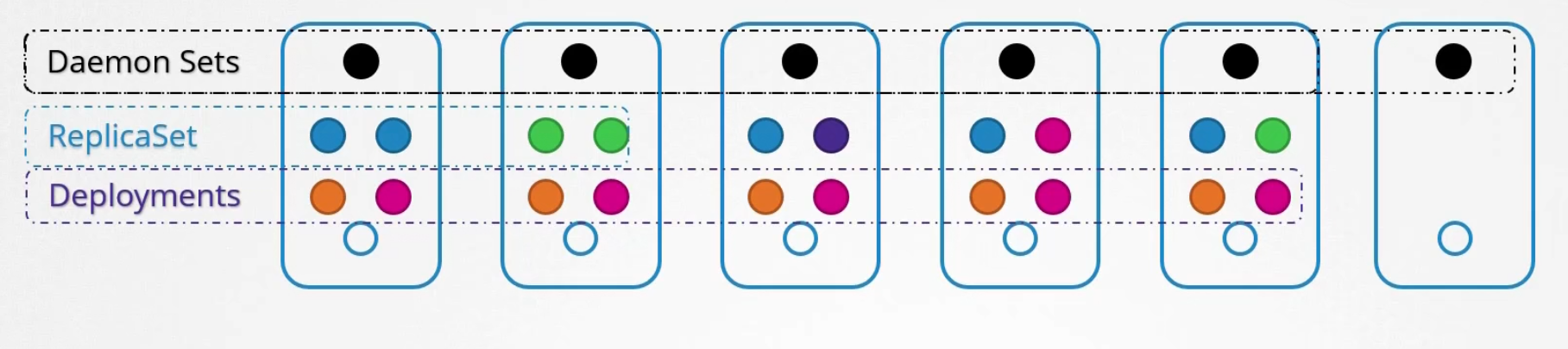
When the node is removed, the pod is removed as well
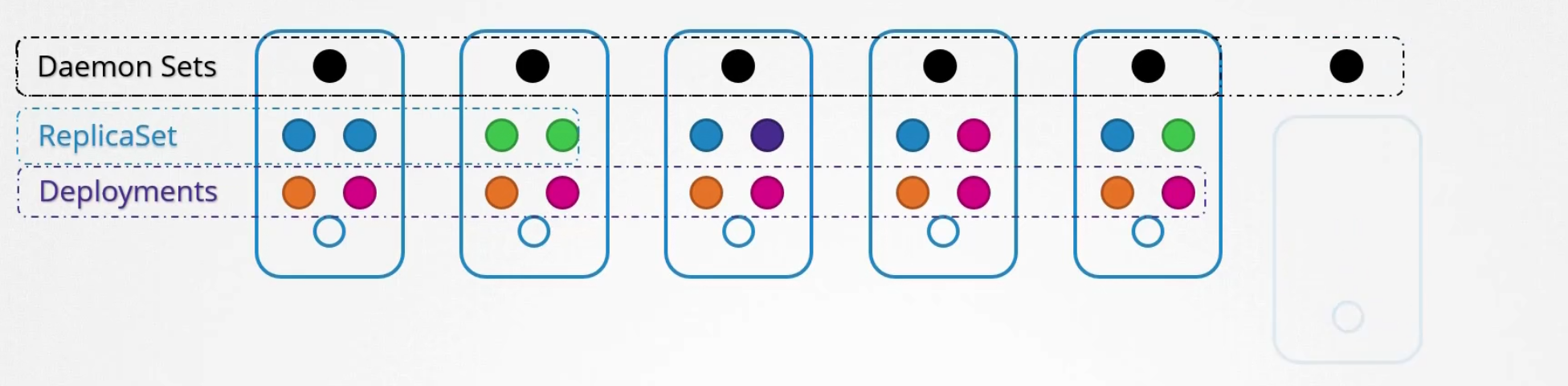
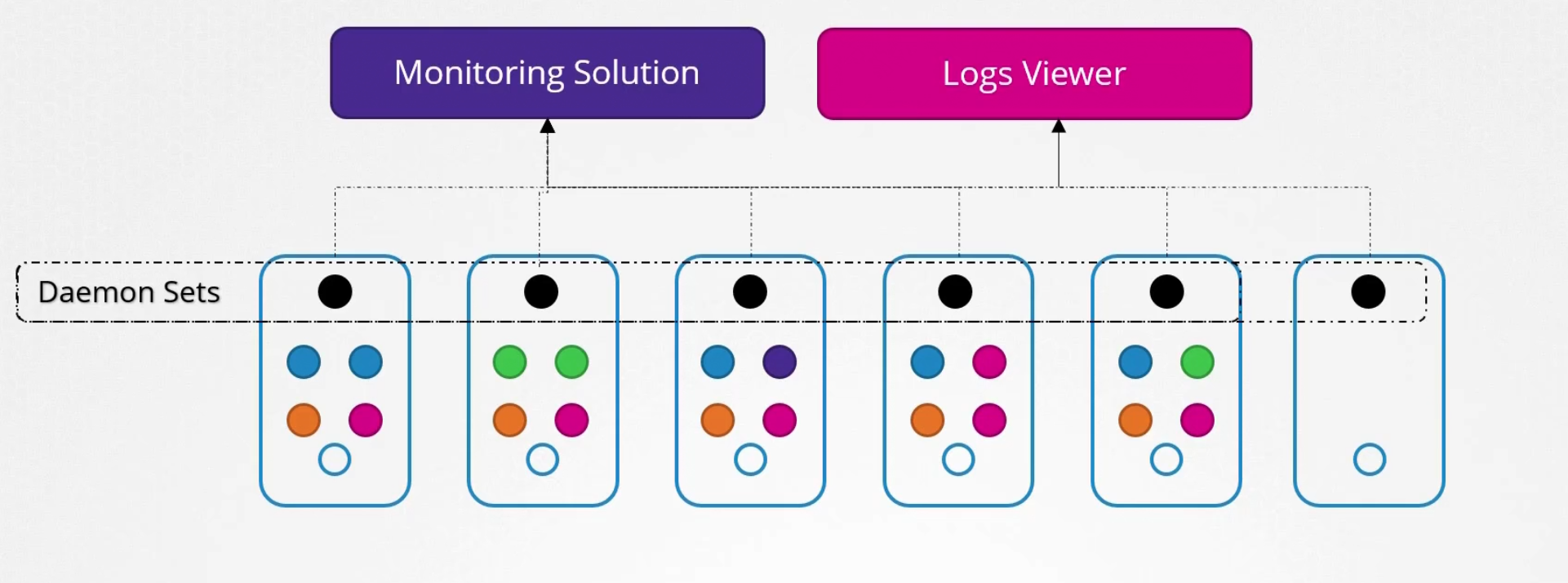
Use-case:
For monitoring or logs view, daemon set is perfect
Also, kube-proxy, weave-net etc can be deployed in daemon sets
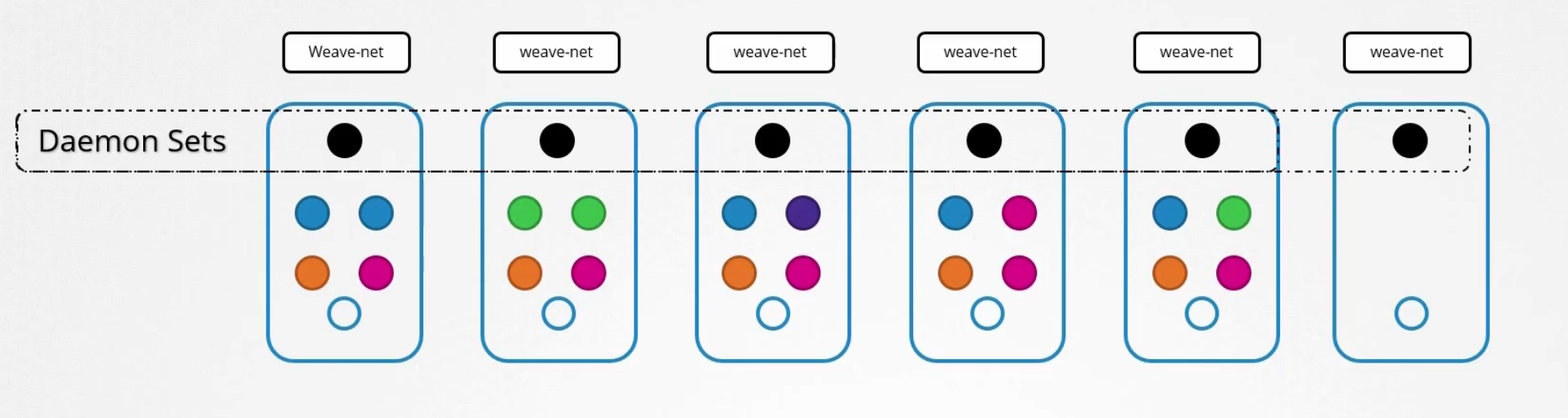
This is how we create a daemon set
Explore more about them
Static Pods
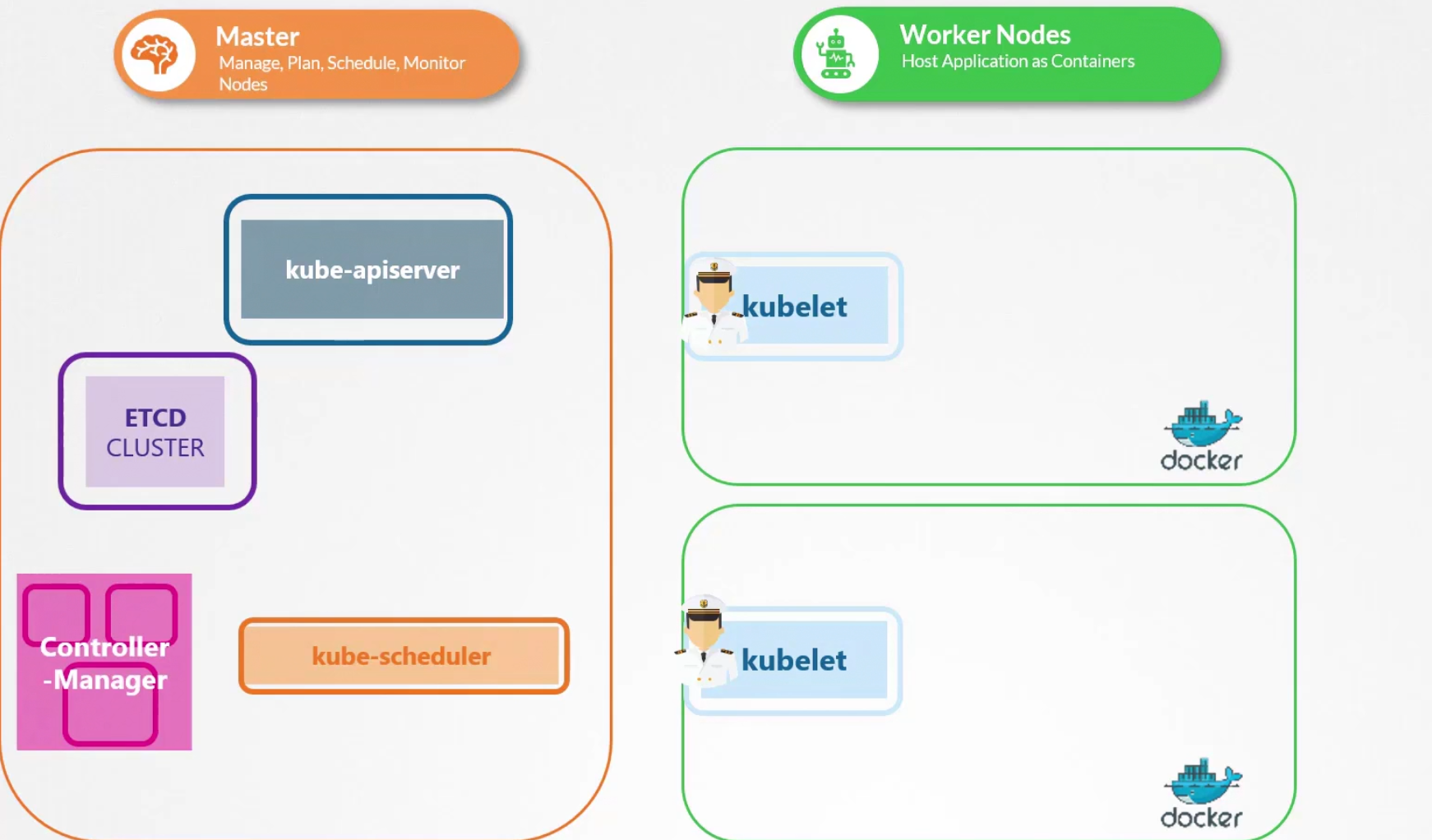
Here we have 3 nodes. First one is master node, and then two working node. Each working node has kubelet which contacts kube-apiserver. In the master node, we see etcd cluster, kube-scheduler, control-manager.
If we don’t have master node, what happens?
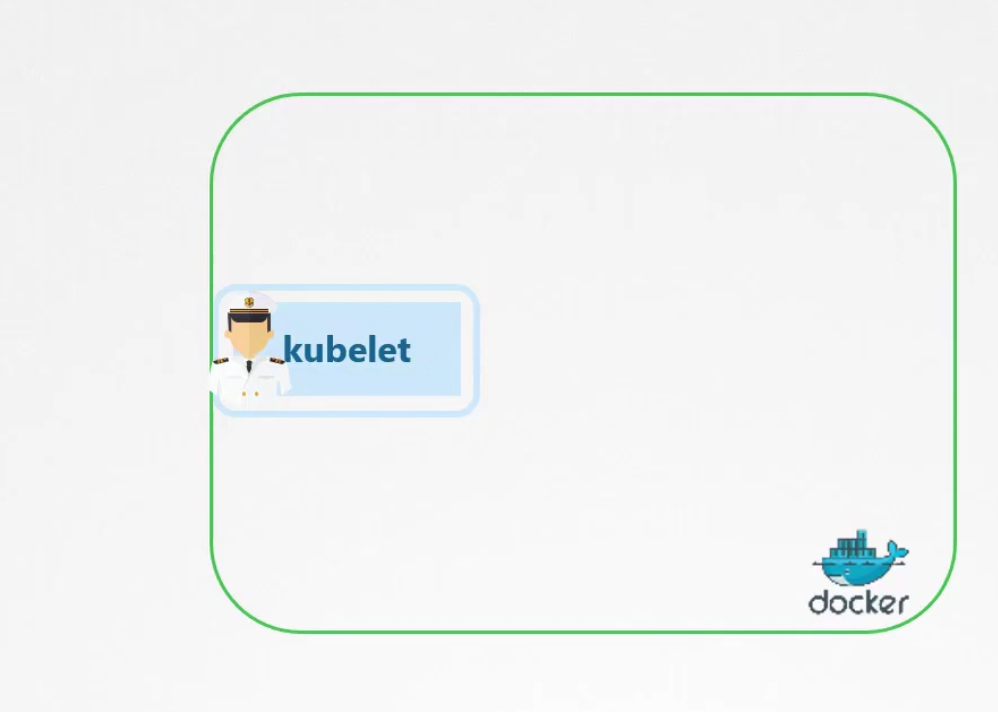
The worker-node still can manage things but this time we have no kube-api server or others.
You can keep the pod definition yaml files to the /etc/kubernetes/manifests folder

after reading those yaml file, kubelet can create pods and even restart if needed
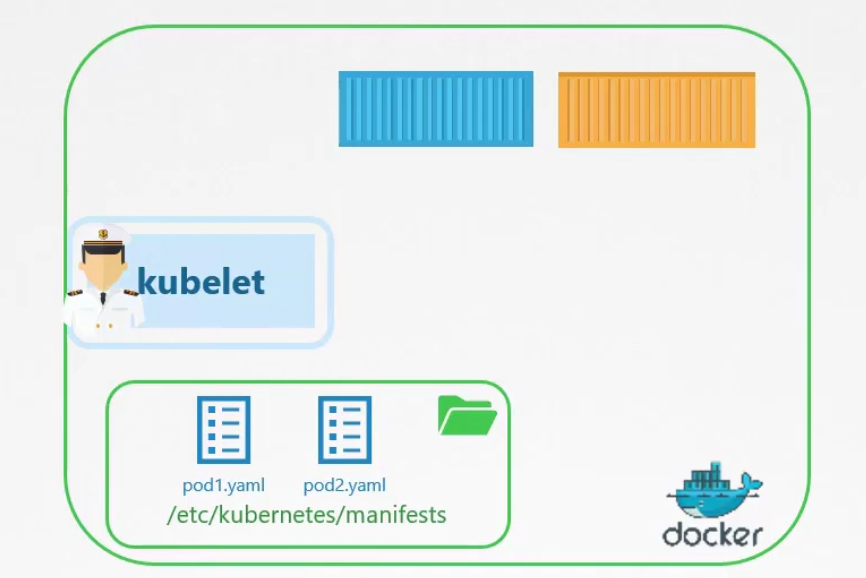
We can’t use replicaset, deployment etc in this way.
Use-Case:
To deploy control plane component as static pods.
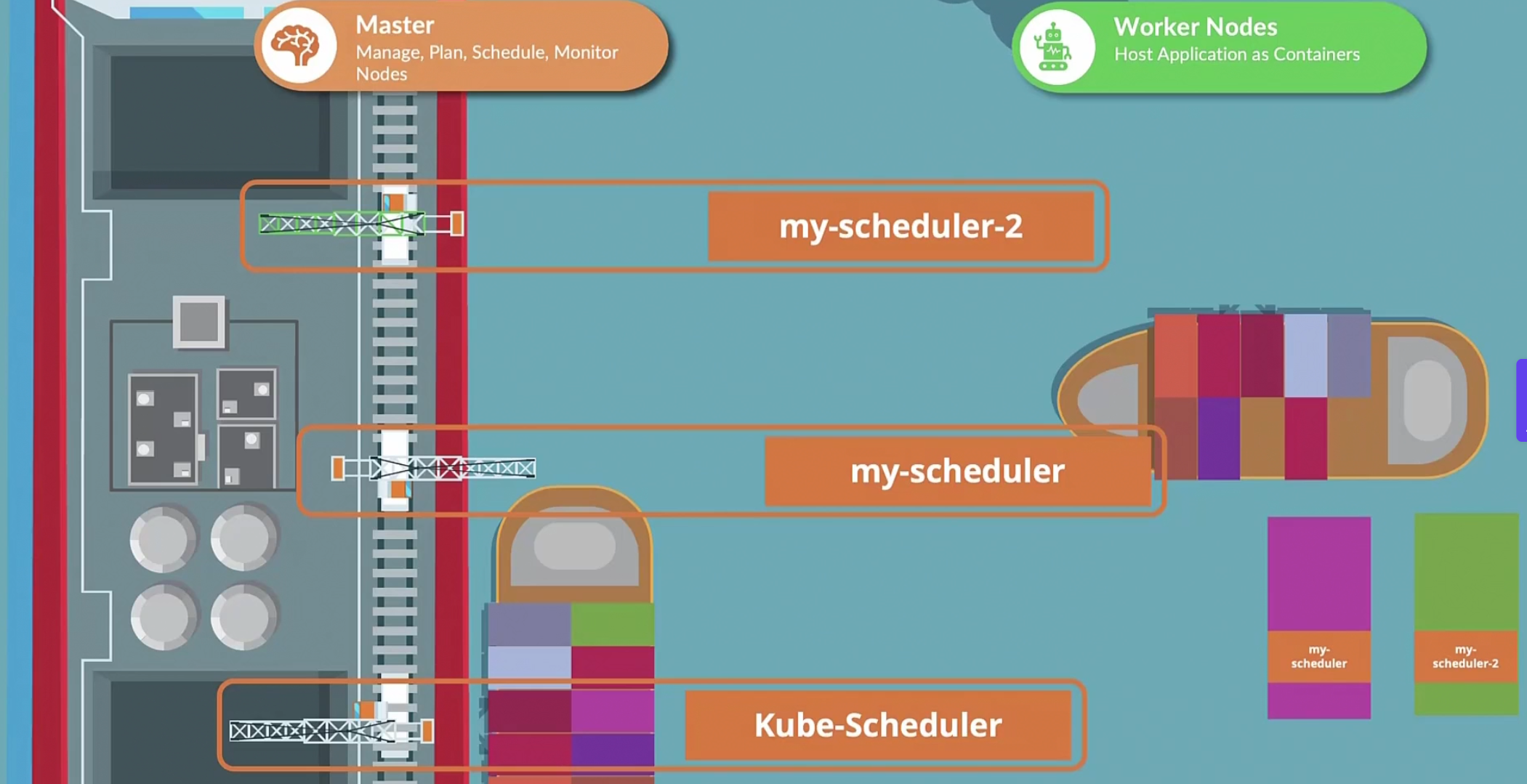
Multiple Schedulers
Assume this is a ship port and
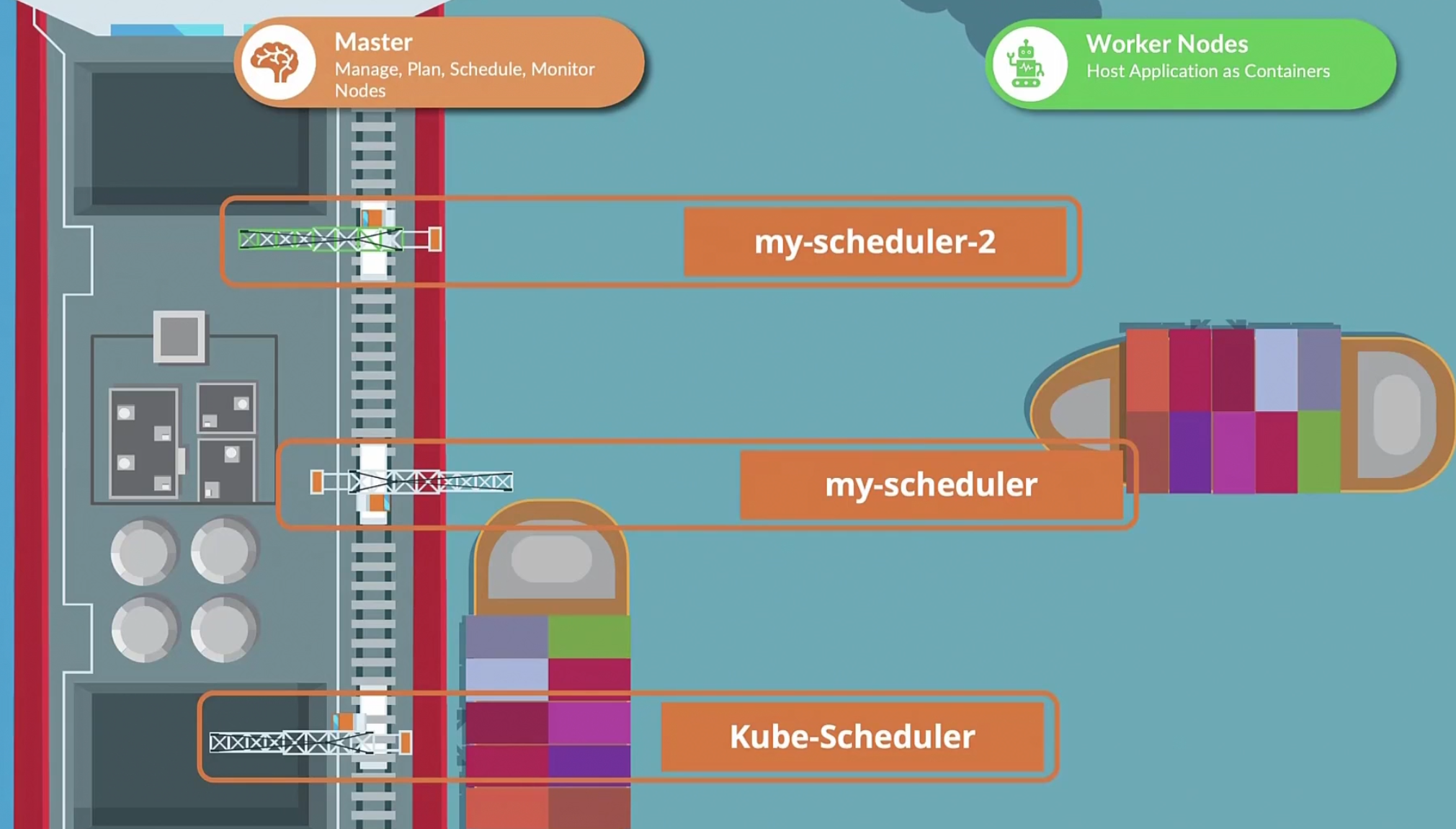
There is kube-scheduler which schedules pods but, you can create your own schedulers too.
When creating a pod, we can specify which scheduler to use for that pod
The default scheduler is called “default-scheduler”
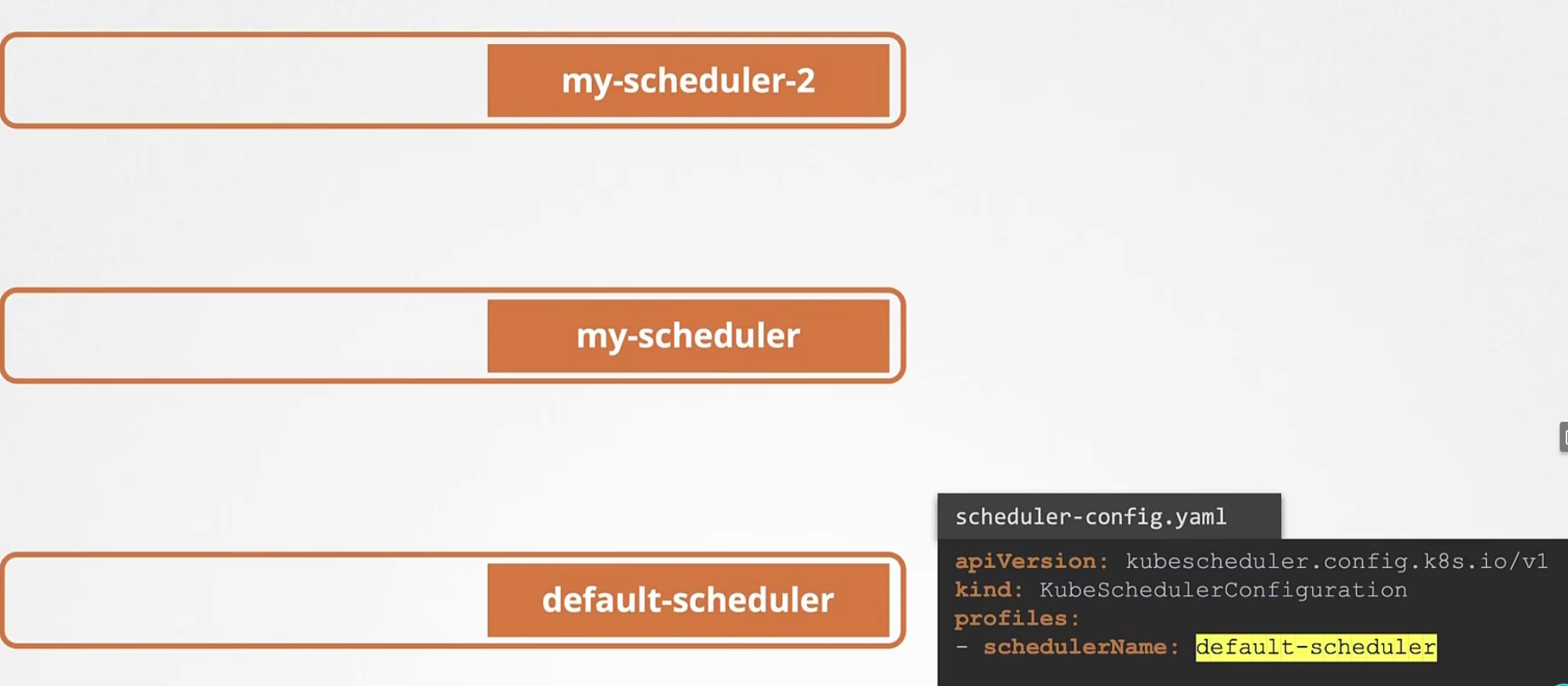
We can create ours by this

Then we download the kube-scheduler binary and we run our schedulers as a service.
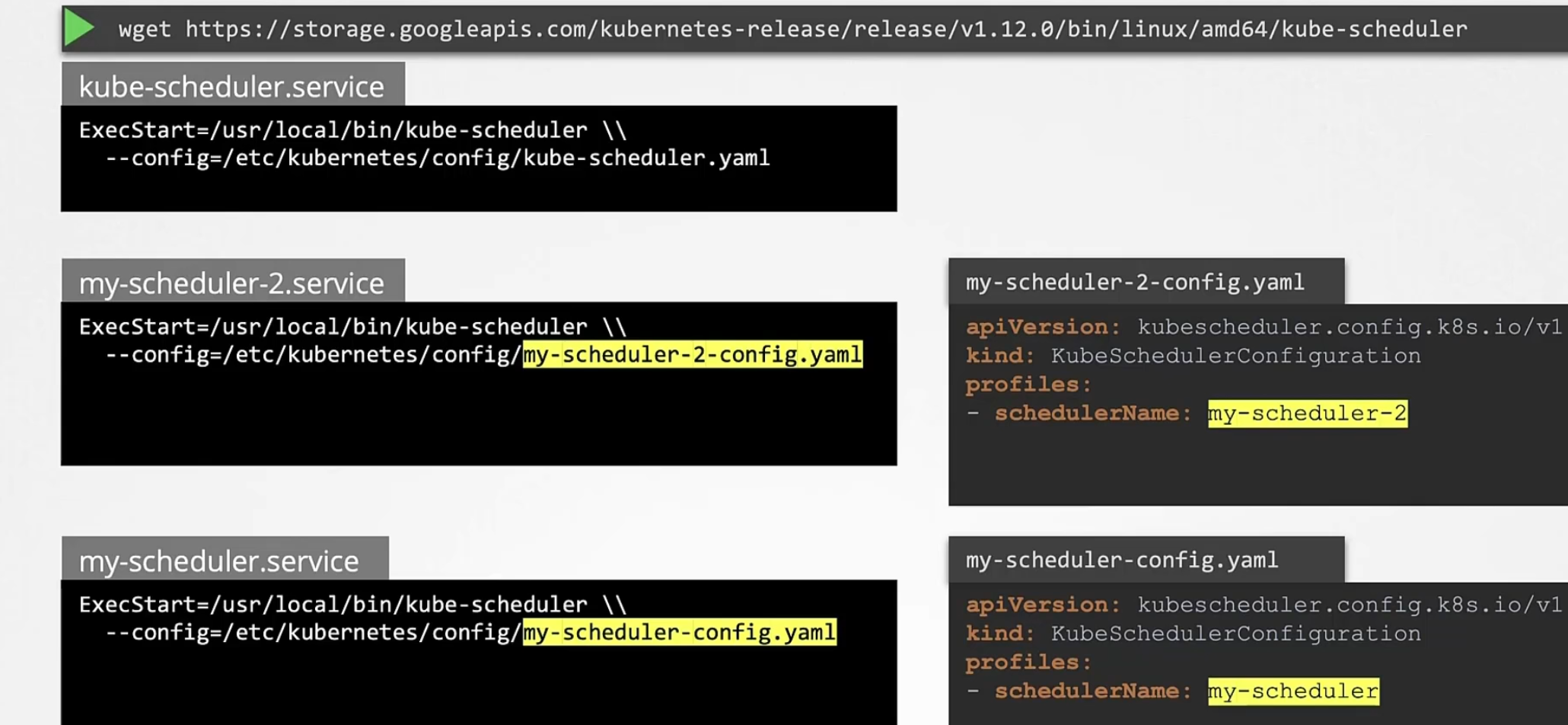
You can also deploy your scheduler as a pod
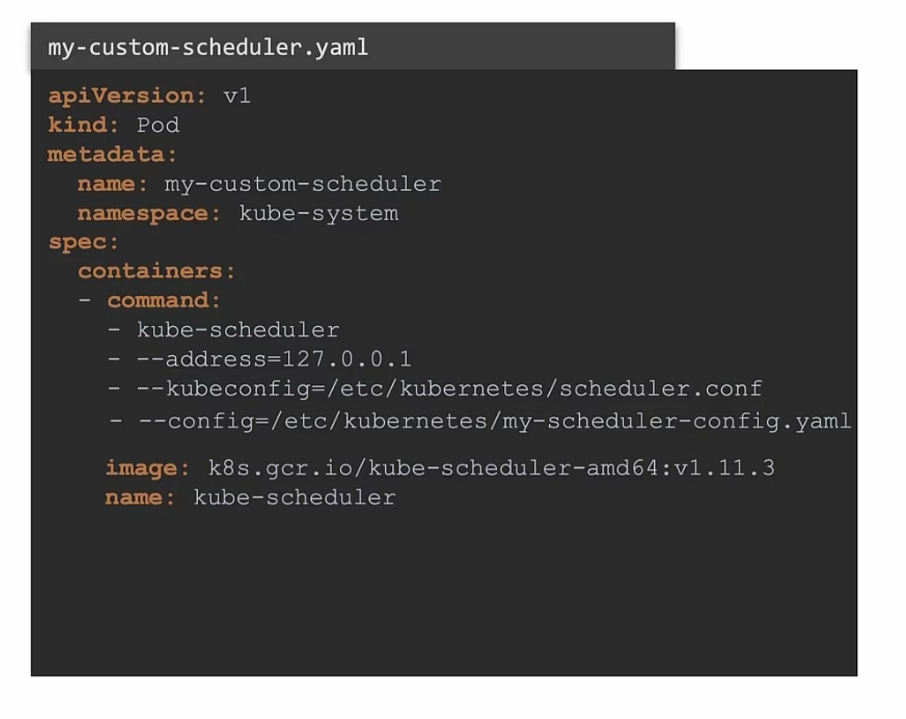
Now, as we have multiple schedulers of same spec, we can choose one the leader scheduler
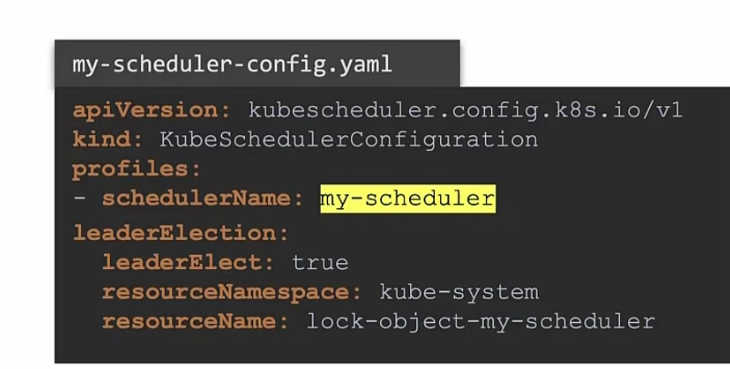
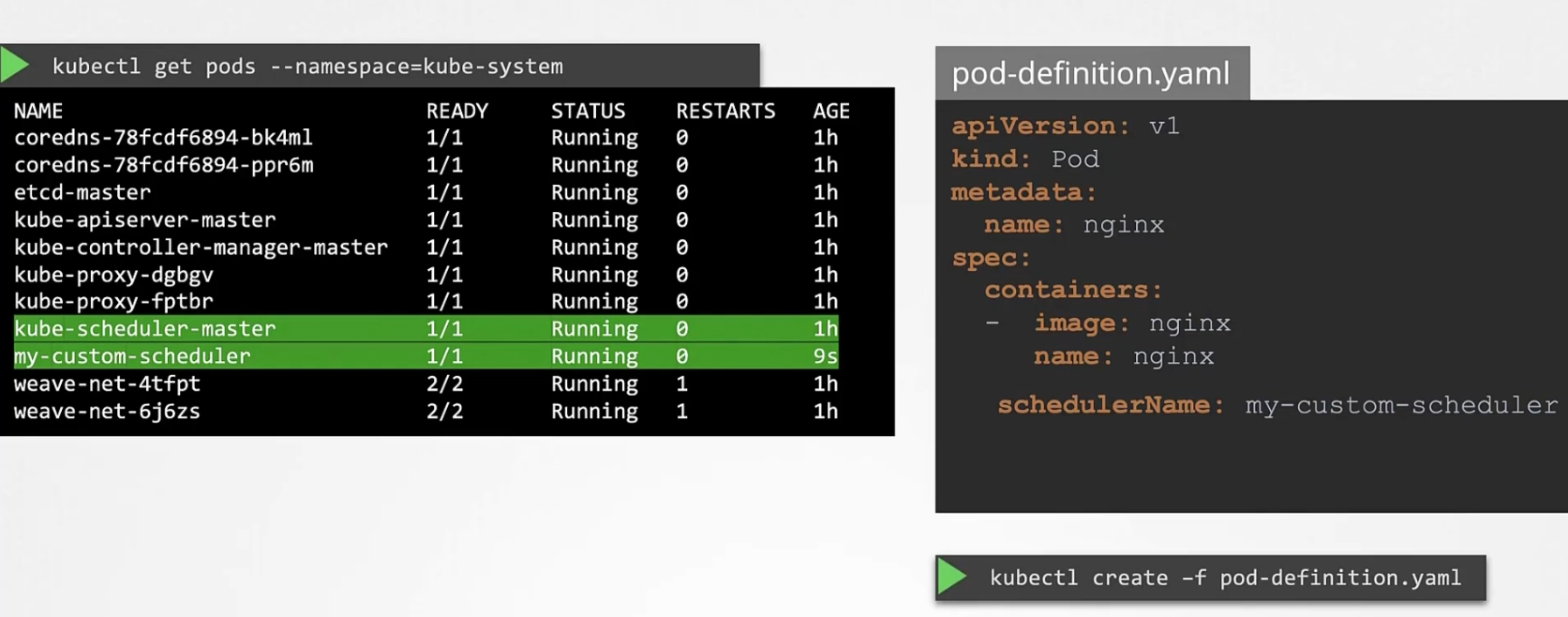
Now, as our scheduler is created, we can now create pod yaml files mentioning “schedulerName”
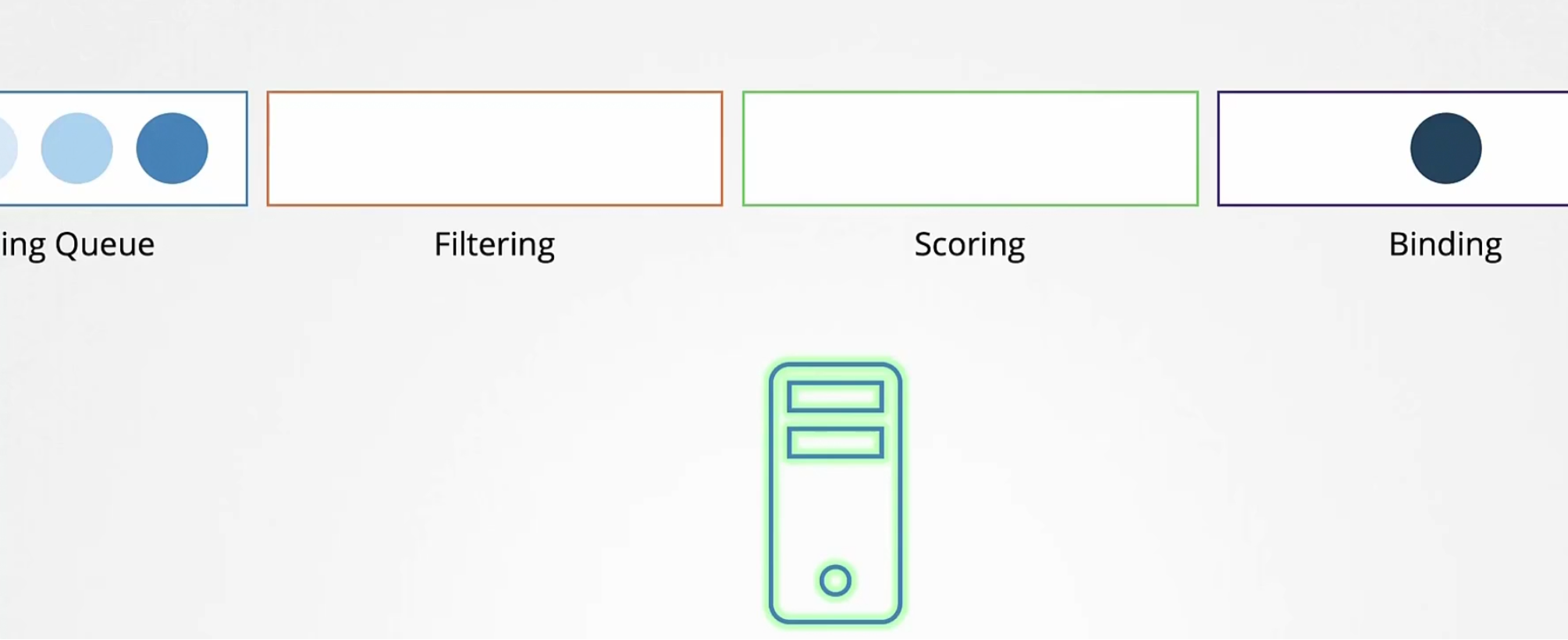
Let’s see how pods are scheduled:
assume this is a pod definition file and we created this pod

There are also other pods which has been created
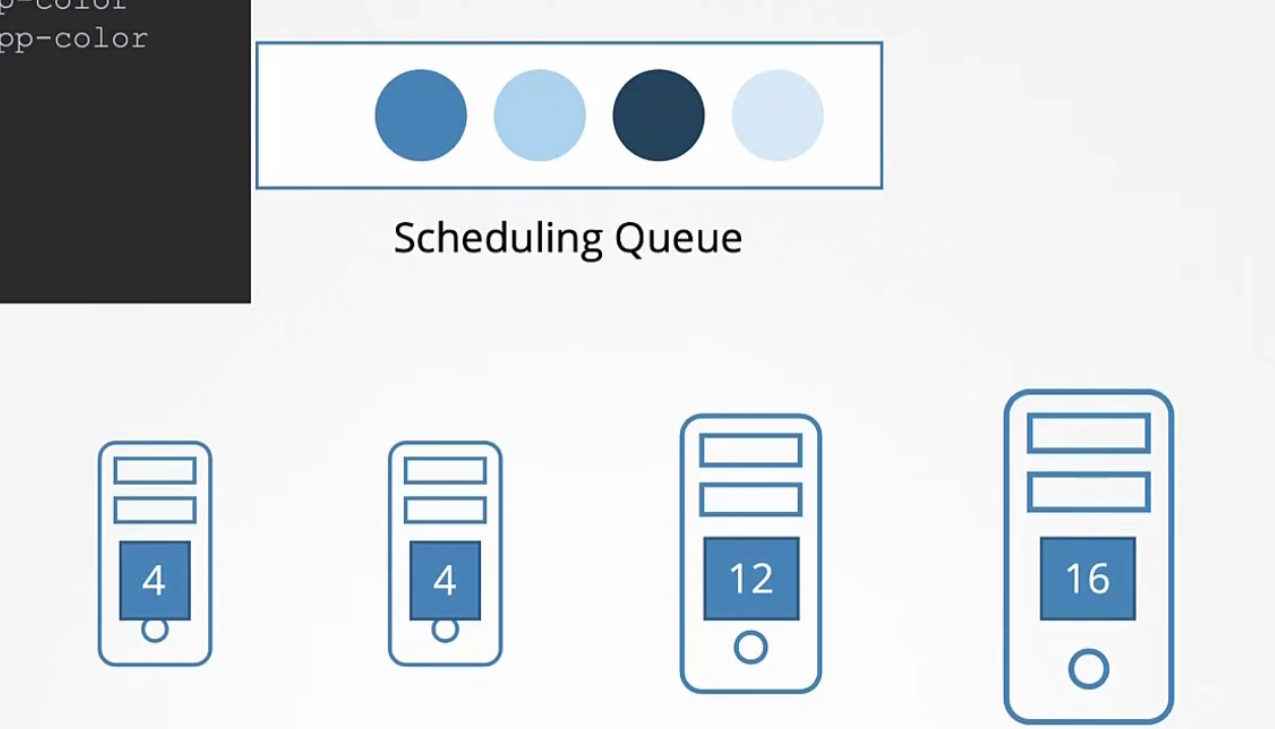
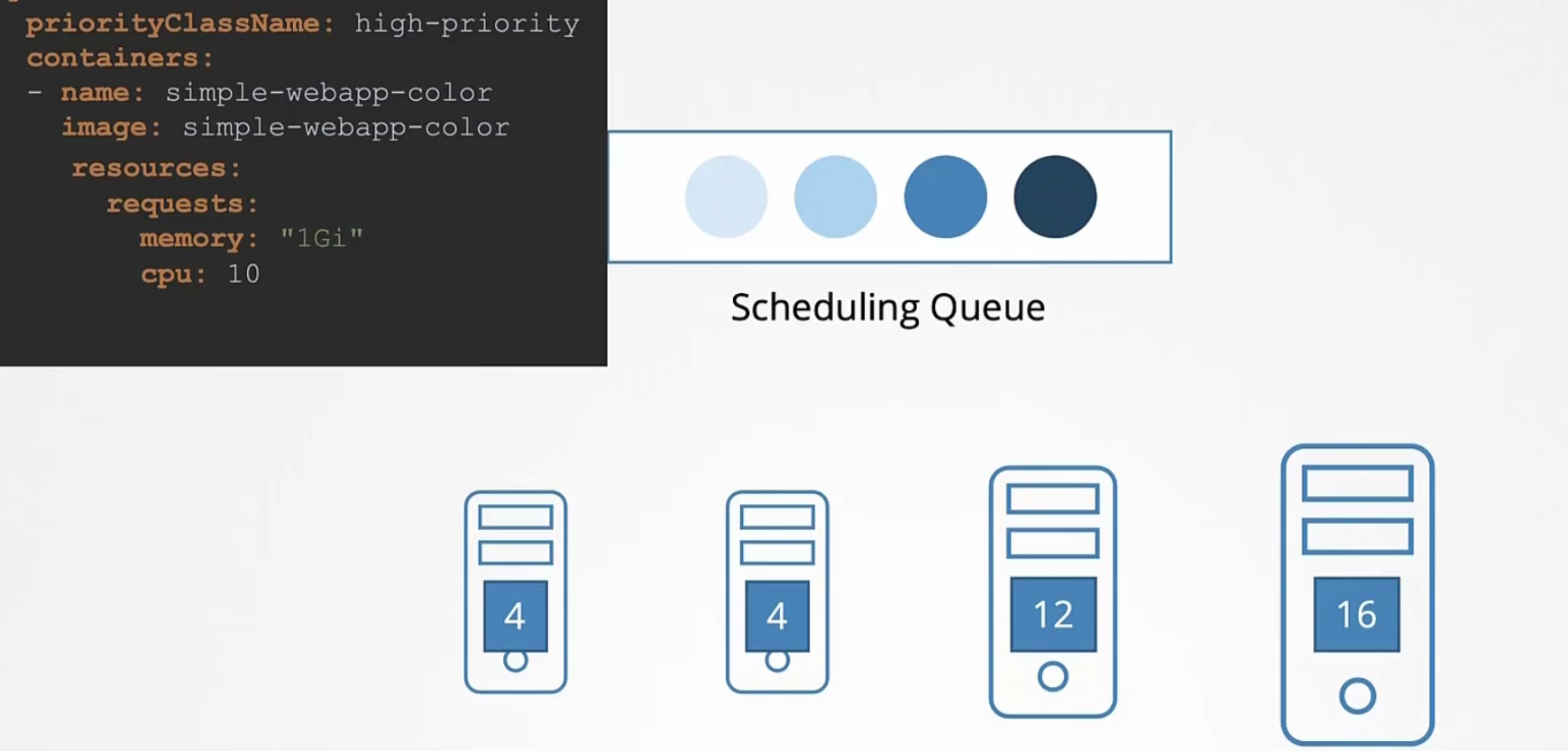
These pods are scheduled based on their priority set
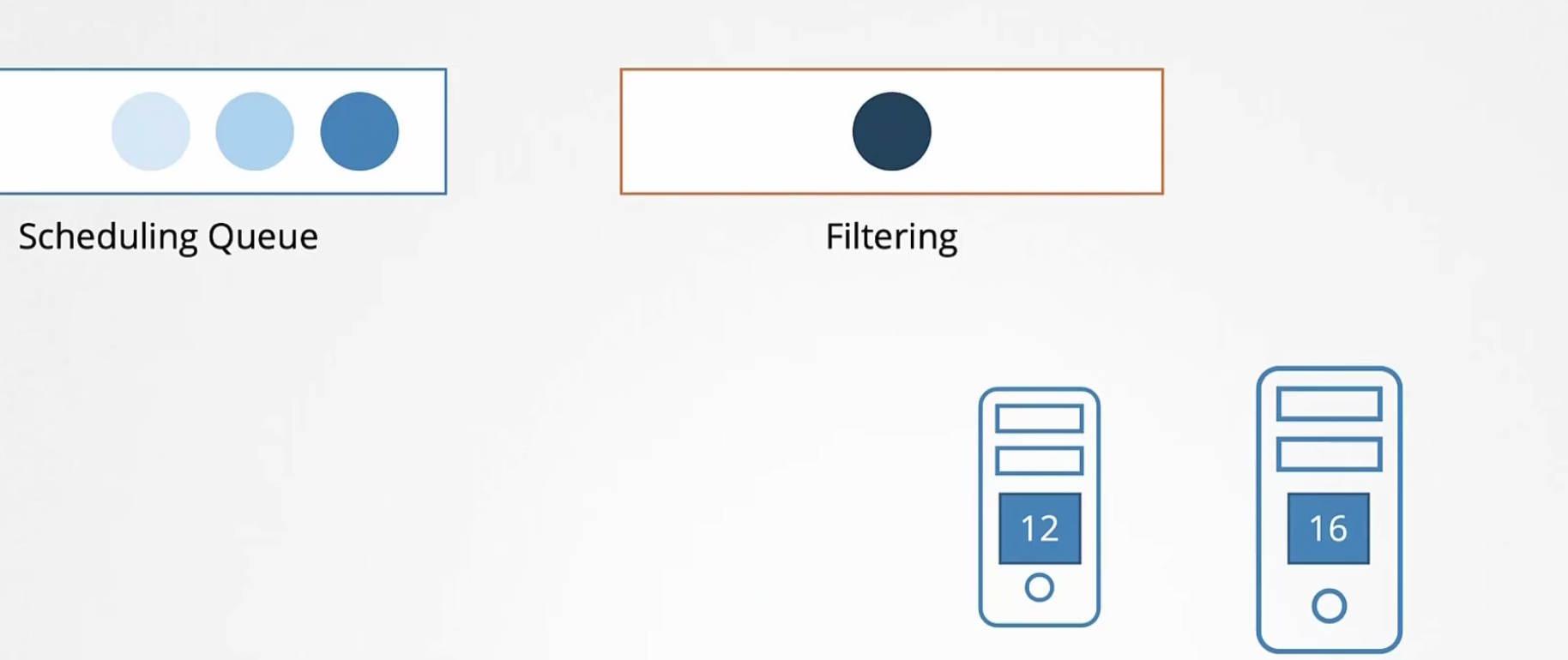
Now comes the filtering phase. The nodes which can’t hold pods are out
Our high priority pod has a need of 10 vCPU. Now, the nodes will minus this value and get a score which is 12-10=2 and 16-10=6
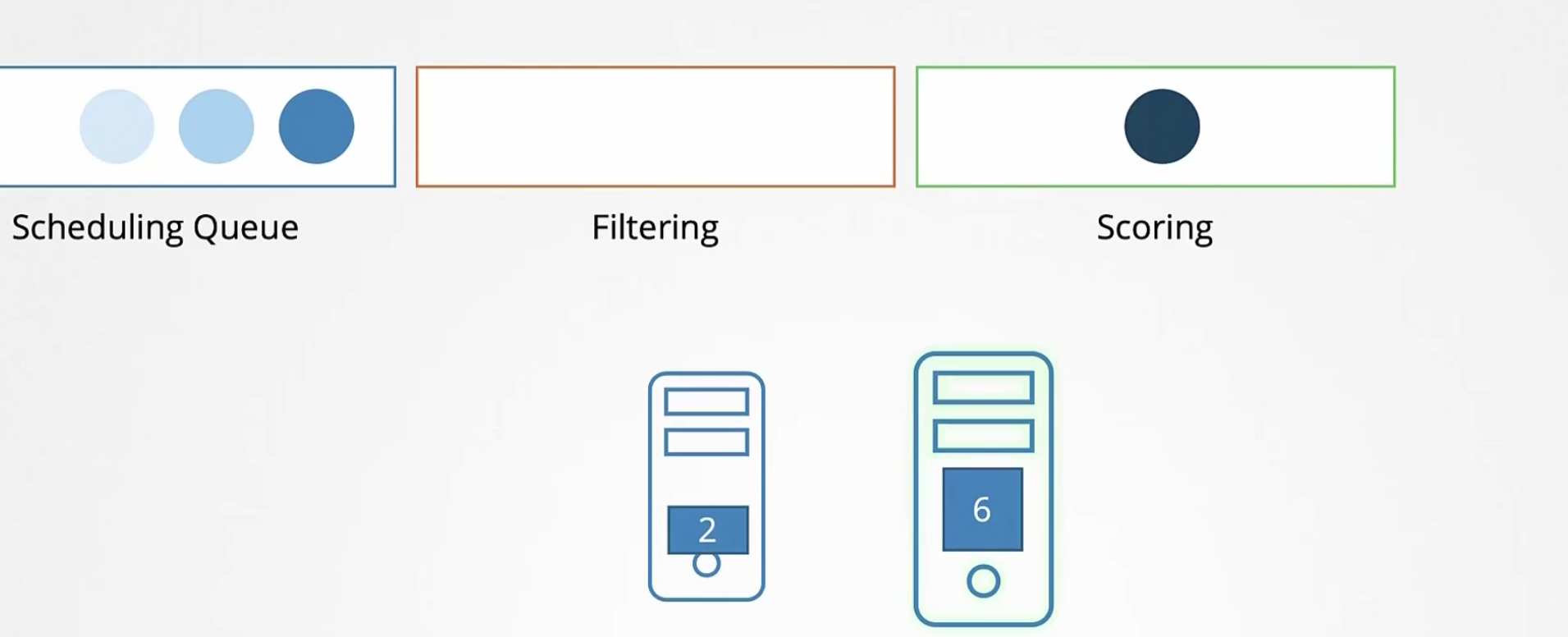
So, right most has the higher score.
Finally the binding phase where the current pod is binded with the top values node.
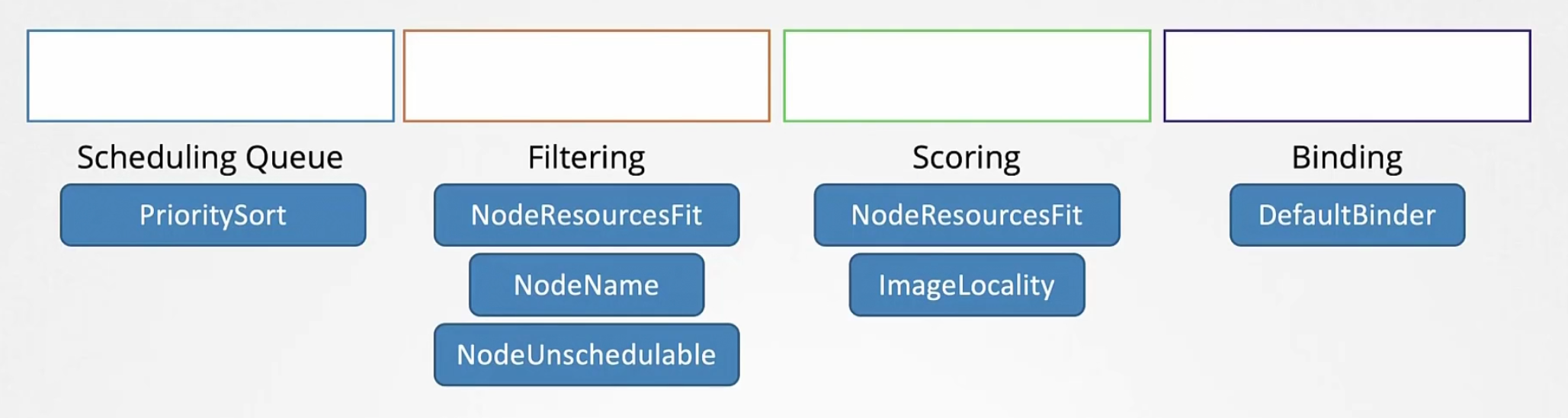
So, in each stages we have seen prioritysort, noderesourcefit, nodename, nodeUnschedule etc.
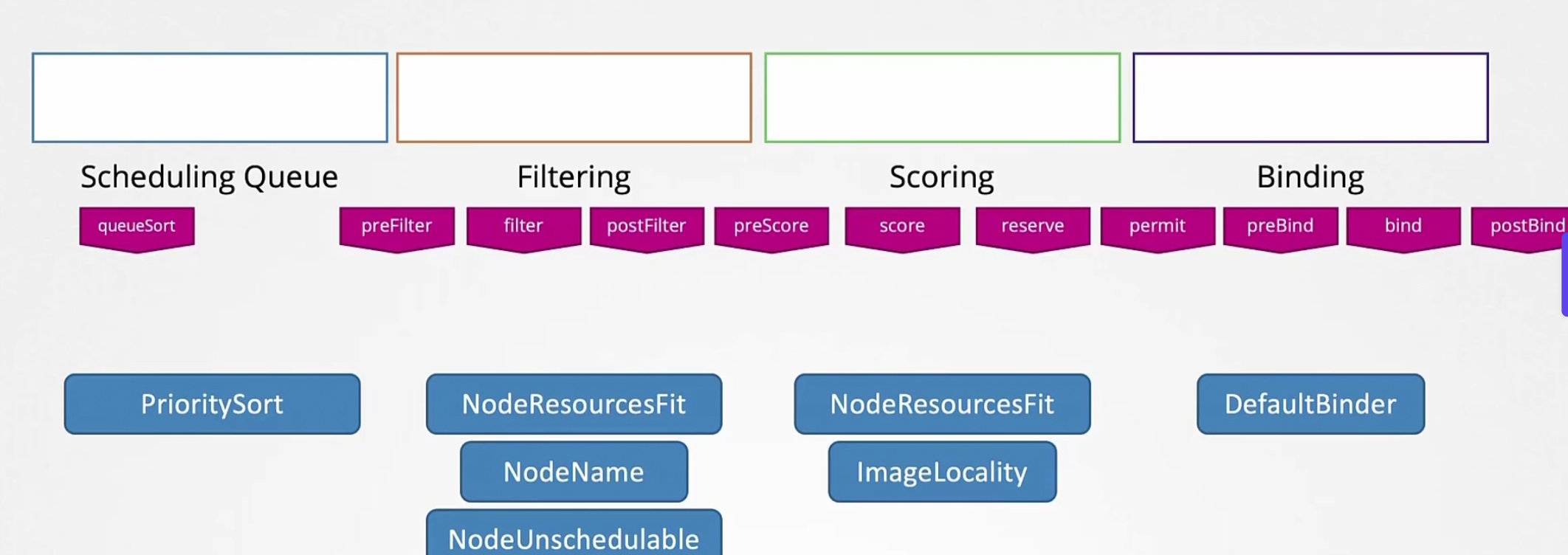
But we can add extensions
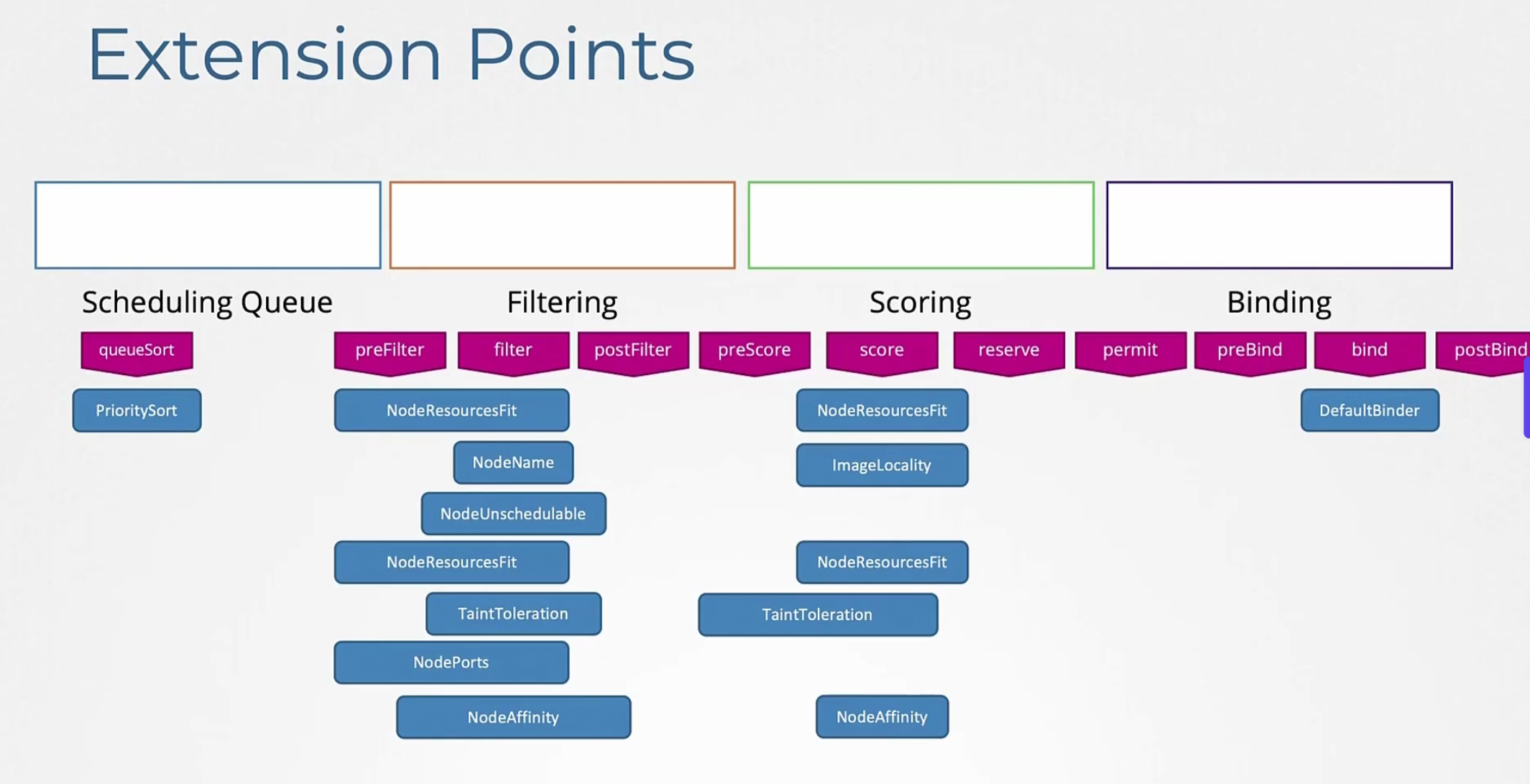
Previously, we created our 2 schedules including with the default one
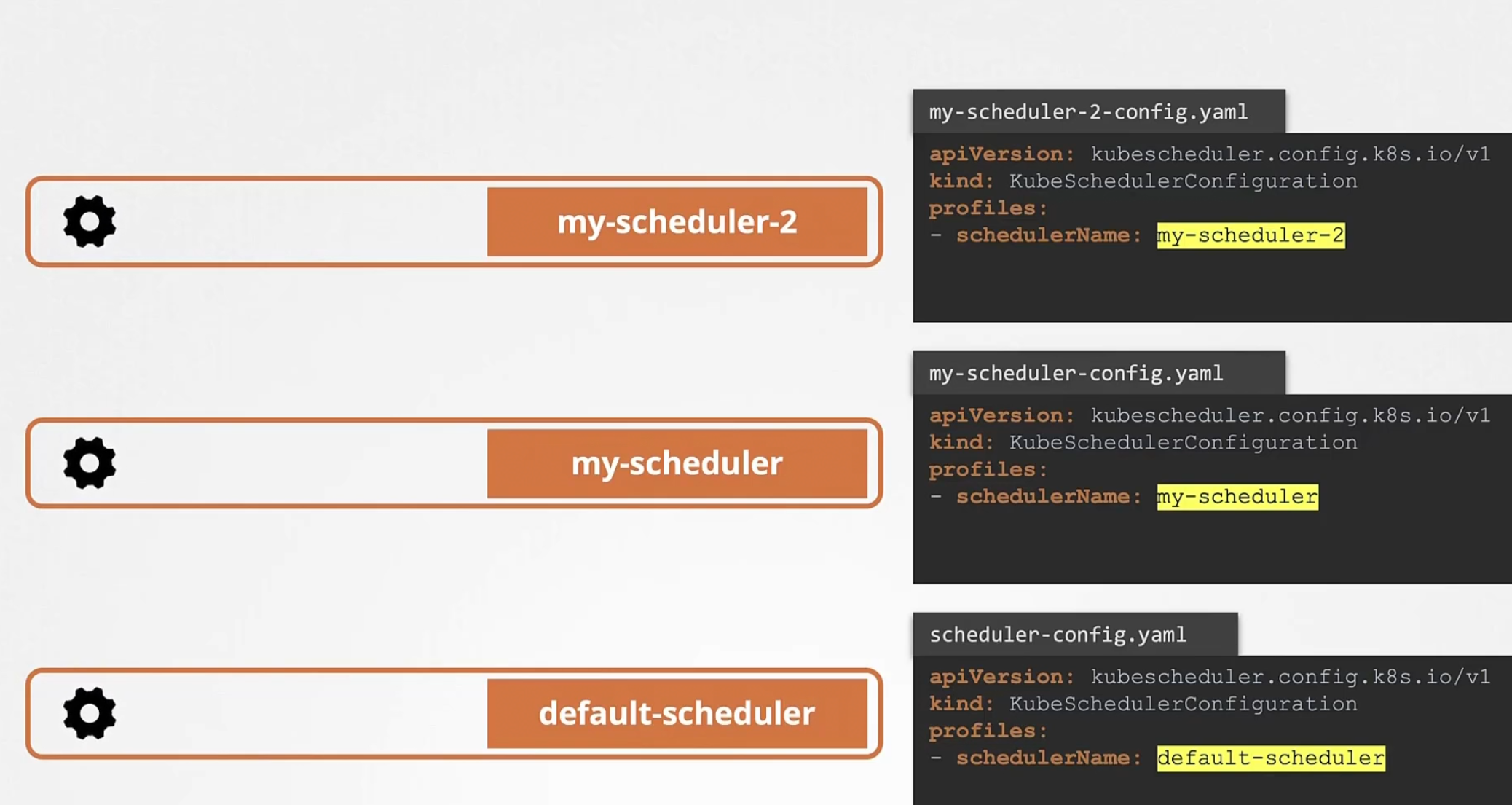
But from new update, we can use different profiles under a schedule

but to configure them to work differently?

In the yaml file, we can mention which extension to block and which to work etc for profiles!
Checkout the blog
Advanced scheduling in kubernetes
How does the kubernetes scheduler work?
That’s it!
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by