Building Predictive Models: How Data Analysts Can Dive Into Machine Learning
 Sai Sravanthi
Sai Sravanthi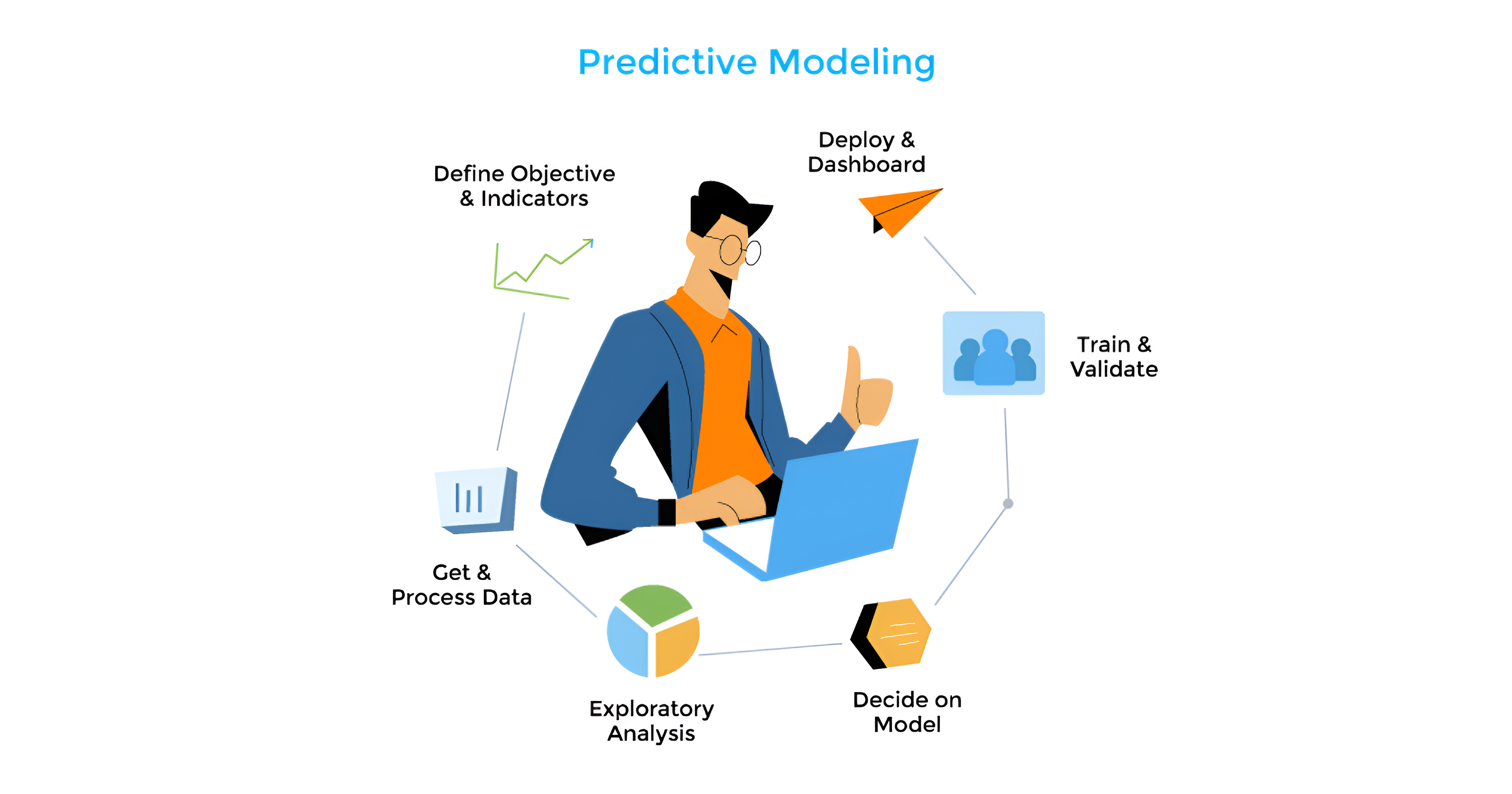
Predictive modeling, enhanced by machine learning, helps data analysts forecast future trends using historical data, and this guide explains key concepts and provides Python and Scikit-Learn code examples.
Key Concepts in Predictive Modeling
Supervised Learning
- In predictive modeling, supervised learning is the most common method, involving training a model on labeled data to predict future outcomes, such as forecasting customer churn based on historical data.
Feature Selection
- Features are the variables in your dataset that affect the outcome, and choosing the right ones is essential for an accurate model, like using square footage, number of bedrooms, and location in a housing price prediction model.
Model Training
- Training a model means providing it with data to learn the relationships between input features and the target, allowing it to find patterns for making predictions on new data.
Model Evaluation
- After training, it’s critical to evaluate the model’s performance using metrics like accuracy, precision, and recall. We split the data into a training set and a test set to assess how well the model generalizes to unseen data.
Overfitting and Underfitting
Overfitting happens when a model fits the training data too closely, capturing noise instead of the true pattern, which results in poor performance on new data.
Underfitting occurs when the model is too simple and fails to capture the relationships in the data.
Step-by-Step Code Walkthrough: Building a Predictive Model Using Python
We'll use Python with Pandas for data manipulation and Scikit-Learn for building the predictive model. The example below walks through building a simple linear regression model to predict housing prices.
1. Import Libraries
# Data manipulation and visualization
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Machine learning model and evaluation tools
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
2. Load and Explore the Dataset
We’ll use a dataset with housing prices. First, we need to load the data and explore it to understand the key features and target variable (the price).
# Load dataset
data = pd.read_csv('housing_data.csv')
# Display first few rows
print(data.head())
# Check for missing values
print(data.isnull().sum())
# Descriptive statistics
print(data.describe())
3. Data Preprocessing
Clean the data by handling missing values and converting categorical variables into numerical form.
# Handle missing values (example: fill missing values with the mean)
data.fillna(data.mean(), inplace=True)
# Convert categorical features (if any) to numeric (example: one-hot encoding)
data = pd.get_dummies(data, columns=['neighborhood'], drop_first=True)
4. Feature Selection
Identify the important features that will be used to build the model.
# Define features (X) and target (y)
X = data[['square_footage', 'bedrooms', 'bathrooms', 'lot_size']] # example features
y = data['price'] # target variable
5. Split the Data into Training and Test Sets
We’ll split the dataset into training (80%) and test sets (20%) to evaluate how well the model generalizes.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
6. Train the Model (Linear Regression Example)
We’ll use Linear Regression as the predictive model for this example.
# Initialize the model
model = LinearRegression()
# Train the model
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
7. Model Evaluation
Evaluate the model’s performance using metrics like Mean Squared Error (MSE) and R-squared (R²) to see how well the model fits the data.
# Calculate evaluation metrics
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
Key Factors to Understand for Predictive Modeling
Model Selection:
- Different problems require different algorithms. For regression tasks, linear regression works well for simple relationships, but if the data is more complex, consider models like Random Forest or Gradient Boosting.
Cross-Validation:
- This technique helps you assess the model’s performance by dividing the data into multiple subsets and training on each, which prevents overfitting and ensures the model generalizes well to unseen data.
from sklearn.model_selection import cross_val_score
cv_scores = cross_val_score(model, X_train, y_train, cv=5)
print(f'Cross-Validation Scores: {cv_scores}')
Hyperparameter Tuning:
- Models often have parameters that need fine-tuning to improve performance. Use techniques like GridSearchCV to find the best combination of parameters.
from sklearn.model_selection import GridSearchCV
param_grid = {'fit_intercept': [True, False], 'normalize': [True, False]}
grid_search = GridSearchCV(LinearRegression(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(f'Best Parameters: {grid_search.best_params_}')
Data Transformation:
- In many cases, scaling or normalizing data is necessary to enhance the performance of algorithms like Logistic Regression or Support Vector Machines (SVM).
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# Fit scaler on training data and transform both train and test sets
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Final Thoughts
Building predictive models is essential for Data Analysts, allowing them to gain insights and make data-based predictions. By understanding feature selection, model evaluation, and overfitting prevention, you can confidently use machine learning. Scikit-Learn provides a powerful environment in Python for creating and using predictive models. As you advance, experimenting with complex algorithms and refining models will enhance insights and prediction accuracy.
Your journey into predictive modeling starts now—BEST OF LUCK !!
Subscribe to my newsletter
Read articles from Sai Sravanthi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sai Sravanthi
Sai Sravanthi
A driven thinker on a mission to merge data insights with real-world impact.