Design Autocomplete for Search Engines
 Okoroafor Kelechi Divine
Okoroafor Kelechi DivineTable of contents
- Fun Fact About Autocomplete 🚀🚀🚀
- Goals of Designing Autocomplete for Search Engines
- Understanding User Behavior
- Design Principles of Autocomplete
- Data Handling for Autocomplete
- Ranking and Filtering Suggestions
- Scalability and Performance
- Handling Multilingual and Regional Queries
- Security and Privacy Concerns
- Conclusion

Autocomplete is a powerful feature that enhances the user experience by predicting and suggesting search queries as they type. This functionality speeds up the search process, reduces input errors, and helps users discover new search terms they may not have initially considered. Designing an efficient autocomplete system for search engines requires carefully considering user behaviour and performance. By understanding the principles behind autocomplete, developers can create a feature that is responsive, intuitive and capable of handling large datasets with minimal latency.
In this article, I will explore the key elements in designing autocomplete for search engines, from understanding user intent to implementing ranking algorithms for relevant suggestions.
Fun Fact About Autocomplete 🚀🚀🚀
Did you know that the concept of autocomplete originated in the 1970s, long before modern search engines? It was first used in early text editors and command-line interfaces, helping programmers and typists speed up their work by predicting commands or code snippets as they typed.
Goals of Designing Autocomplete for Search Engines
When designing an autocomplete system for search engines, several key goals must be considered to ensure it enhances the overall user experience and meets performance requirements:
Improving Search Efficiency
The primary goal of autocomplete is to make the search process faster and more convenient. By predicting queries such as user type, autocomplete reduces the amount of text users need to input. This helps them find what they are looking for with minimal effort, boosting efficiency, leading to quicker search completion and higher satisfaction.Enhancing User Experience
Autocomplete offers users suggestions that are often more accurate than their initial inputs. Intelligently predicting search terms helps users refine their searches or discover related topics they hadn’t considered. A well-designed system anticipates user needs, delivering suggestions that feel intuitive and tailored, improving overall usability.Handling Errors and Ambiguity
Users often misspell words or type incomplete queries. An effective autocomplete system must handle these situations gracefully, offering corrections or relevant suggestions even when the input is ambiguous. This helps users quickly recover from errors and find what they need without frustration.Personalization
Personalization is becoming increasingly important in modern search engines. Autocomplete can use previous search history, location, or user preferences to provide more relevant suggestions. This goal ensures the system adapts to individual users, offering a customized search experience that aligns with their needs and behaviour.Reducing Cognitive Load
Typing long queries can be burdensome for users, especially on mobile devices. One of the goals of designing autocomplete is to reduce the cognitive load by offering suggestions that minimize the amount of effort required.
Understanding User Behavior
A deep understanding of user behaviour is essential for designing an effective autocomplete system for search engines. Users interact with search engines in various ways, and their behaviours can range from concise to complex, requiring the autocomplete feature to adapt to their needs in real-time. Here are the key aspects of user behaviour that influence the design of autocomplete:
Identifying User Intent
Users come to a search engine with a specific goal or need, though they may not always express it clearly in their query. They often begin typing with just a rough idea of what they are looking for. As a result, autocomplete must anticipate and identify user intent early, offering suggestions that align with the possible queries they might have in mind. This involves understanding common patterns, query types, and the context in which searches are made.Common User Patterns in Search
People tend to exhibit specific patterns when searching. For instance, some users may type full sentences, while others rely on short, keyword-based queries. Additionally, search behaviours vary depending on the device being used. On mobile devices, users may prefer shorter queries due to limited typing comfort, whereas on desktop, they might enter more detailed queries. The autocomplete system should be flexible enough to handle these varying input styles and suggest appropriate results based on different search behaviours.Handling Misspelled Queries and Partial Inputs
Misspellings, typos, and incomplete phrases are common during searches. Users may stop typing after entering only part of a word, especially when they expect autocomplete to fill in the rest. To improve usability, the system needs to recognize common spelling errors and incomplete inputs, offering suggestions that are relevant even when the query isn’t fully clear. This can involve using fuzzy matching algorithms that handle minor inaccuracies or offer query corrections.Predictive Suggestions Based on Popularity
Users often look for what others have searched for before them. Predicting popular search terms based on previous queries can guide users toward common or trending topics. By suggesting popular search phrases early in the input, the system not only saves time but also helps users discover content they may not have initially considered. This is especially useful when users are unsure how to phrase their query.
Design Principles of Autocomplete
Designing an autocomplete system for search engines requires a balance between functionality, user experience, and performance. The system must provide relevant suggestions quickly while being simple and intuitive. Here are the key design principles to consider:
Responsiveness and Speed
One of the core principles of autocomplete is its need for real-time responsiveness. As users type, the system should instantly present relevant suggestions without noticeable delay. Even a slight lag in response time can frustrate users and disrupt the search flow. To achieve this, autocomplete systems rely on efficient algorithms, optimized indexing, and caching mechanisms. The goal is to reduce latency and ensure that users receive suggestions as soon as they start typing, keeping the interaction smooth and engaging.Simplicity and Clarity
Autocomplete suggestions should be simple, clear, and easy to scan. Presenting too many suggestions or overly complex choices can overwhelm users, defeating the purpose of autocomplete. The design should focus on delivering concise, relevant suggestions that guide the user toward completing their query. Additionally, the interface should avoid visual clutter, with a limited number of suggestions (usually 5 to 10) displayed in a clean, readable format to avoid overwhelming the user.Context-Aware Suggestions
A well-designed autocomplete system understands the context of the user’s input. For instance, if a user is searching for a particular category of information (such as “best smartphones”), the system should suggest related terms that refine the search (e.g., “best smartphones 2024” or “best budget smartphones”). Context-aware suggestions can also be influenced by time, location, or the user’s previous searches.Error Tolerance and Correction
Users frequently make typos or enter incomplete search terms. Autocomplete systems must be forgiving of such errors, offering suggestions that account for common misspellings, abbreviations, or partial queries. This can be achieved using fuzzy matching algorithms, which allow the system to recognize inputs that are close to the correct spelling and suggest alternatives. Error tolerance enhances usability by helping users find the right terms, even if they’ve made a mistake while typing.Scalability and Performance Optimization
An efficient autocomplete system must be designed to handle millions of search queries across vast datasets, especially for large search engines. Scalability is crucial to maintaining performance as the system grows in terms of users and search data. Caching, distributed computing, and optimized data structures are some of the techniques used to ensure that the system remains fast, even as demand increases. The backend design must be robust enough to handle high traffic while still delivering suggestions within milliseconds.
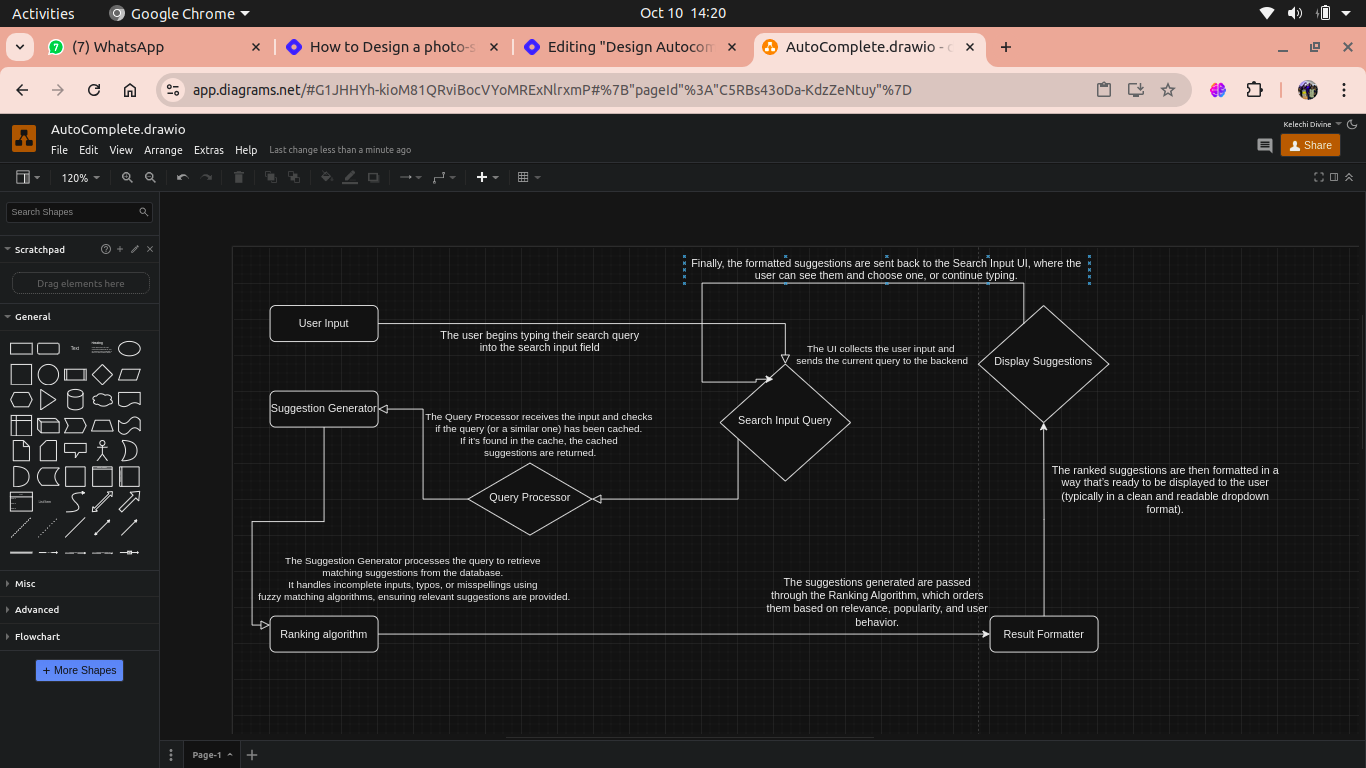
Data Handling for Autocomplete
Effective data handling is crucial for the performance and accuracy of an autocomplete system. The way data is managed, processed, and utilized directly impacts the relevance of suggestions provided to users. Below are the key aspects of data handling for an autocomplete system:
1. Data Collection
Data collection involves gathering relevant information that will be used to generate autocomplete suggestions. This data can come from various sources, including:
User Search History: Storing users' previous search queries helps understand individual user behaviour and preferences.
Popular Search Terms: Aggregating data on commonly searched queries allows the system to provide relevant suggestions based on trends.
2. Data Storage
Efficient data storage is essential for quick access and retrieval of suggestions including:
Database Design: Structuring the database to optimize for read operations is crucial. Normalization can help reduce redundancy while indexing frequently searched terms enhances query speed.
Caching Mechanisms: Implementing caching strategies to store frequently requested suggestions can significantly improve response times. For example, using in-memory databases (like Redis) can reduce the time taken to retrieve popular suggestions.
3. Data Processing
Processing the collected data to generate suggestions involves several steps:
Query Parsing: The system must parse user input to understand intent and context. This includes handling incomplete queries, identifying keywords, and applying fuzzy matching techniques to correct typos.
Suggestion Generation Algorithms: The core logic for generating suggestions should be efficient and accurate. This may involve:
Prefix Matching: Identifying suggestions that start with the user's input.
N-gram Models: Utilizing language models that consider sequences of words (n-grams) to suggest completions.
Machine Learning: Implementing machine learning models that can learn from user interactions over time, improving the relevance of suggestions based on patterns in the data.
4. Data Ranking
Once suggestions are generated, ranking them based on relevance is vital for user satisfaction:
Relevance Factors: Suggestions can be ranked based on various criteria, including:
Popularity: How frequently a suggestion has been searched.
Recency: Newer or trending suggestions may be prioritized.
Personalization: Adjusting suggestions based on individual user preference and history.
Dynamic Ranking: Implementing real-time ranking mechanisms ensures that the suggestions adapt quickly to changes in user behaviour and trends.
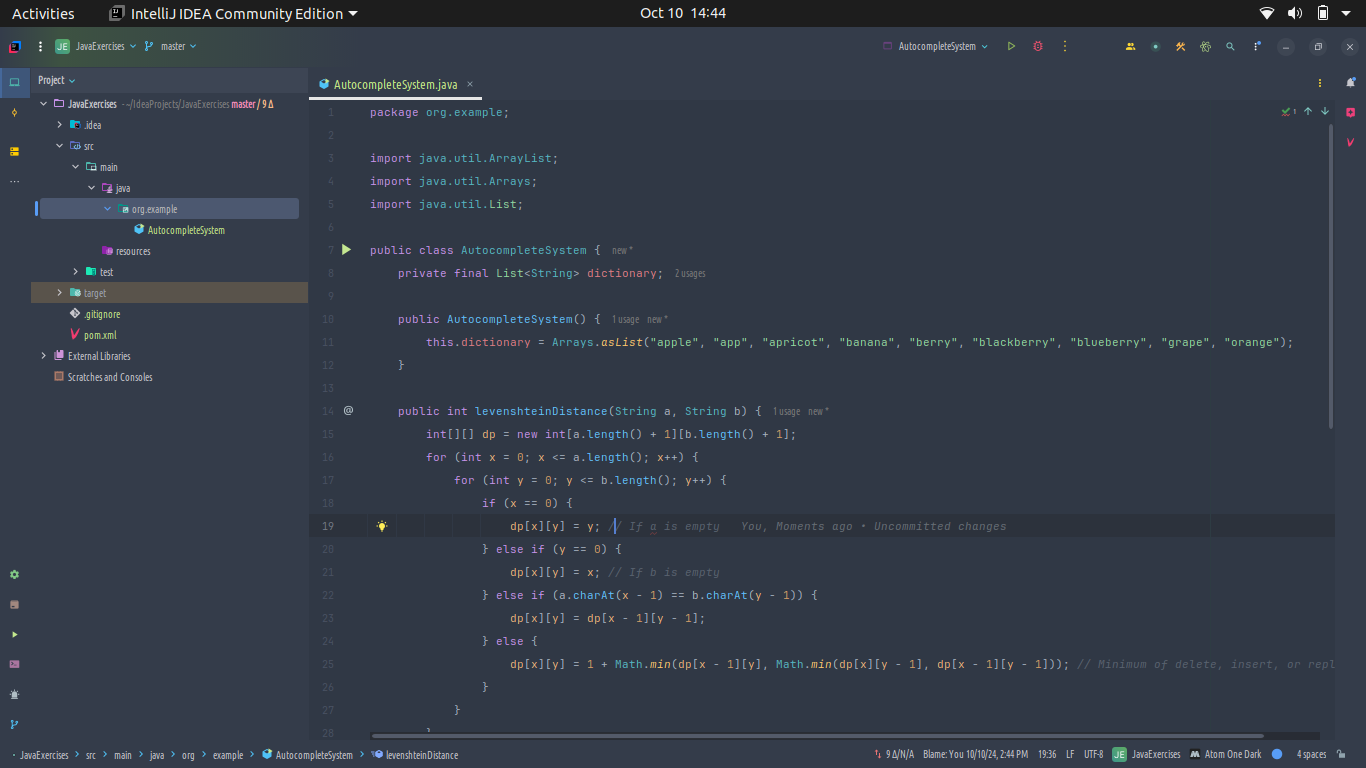
Below is a simple Java program that uses the Fuzzy String Matching algorithm to implement an autocomplete feature. This example utilizes the Levenshtein Distance algorithm, which measures how many single-character edits (insertions, deletions, or substitutions) are needed to change one word into another. You can view the complete source code here
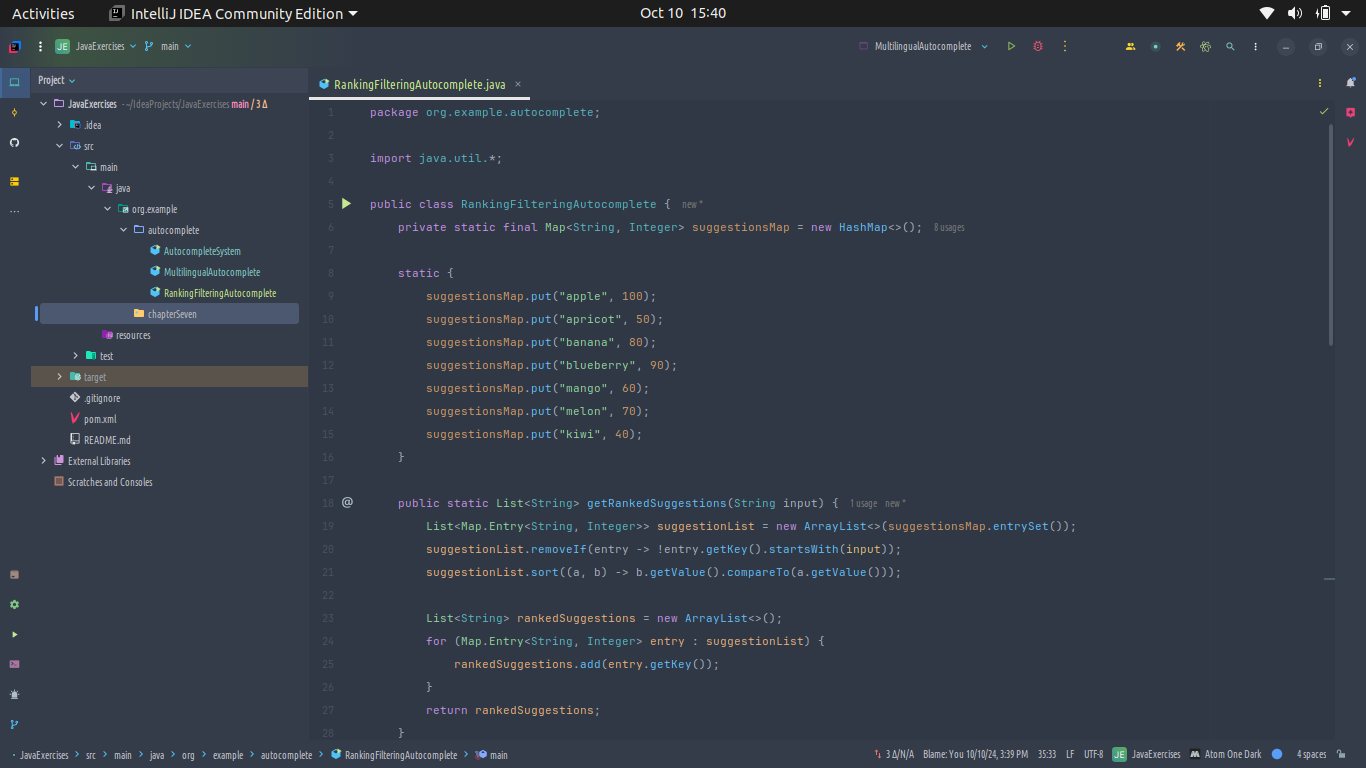
Ranking and Filtering Suggestions
Ranking and filtering suggestions are key steps in creating an effective autocomplete system. Here is a simple Java code example that demonstrates how to rank and filter autocomplete suggestions based on user input and certain criteria. The example will include basic filtering based on the length of the suggestion and a ranking mechanism that prioritizes suggestions based on popularity (for simplicity, we'll use a hardcoded popularity score). Check out the complete source code here
1. Understanding Relevance
When a user types a query, the autocomplete system should prioritize suggestions that are most relevant to what they might be looking for. Relevance can depend on several factors:
Popularity: Suggestions that are frequently searched by other users should rank higher.
User History: If the user has searched for specific terms before, those should be prioritized in their suggestions.
Context: The system can take into account the context of the search, like the current trends or seasonal searches.
2. Ranking Suggestions
After generating a list of potential suggestions, the system ranks them based on relevance. Here’s how I can approach ranking:
Score Calculation: Each suggestion can be assigned a score based on the factors mentioned above. For example:
Popularity score (how many times it’s been searched)
Recency score (how recently it was searched)
Personalization score (based on the user’s previous searches)
Sorting: Once each suggestion has a score, the list is sorted from highest to lowest score, ensuring the most relevant suggestions appear first.
3. Filtering Suggestions
Not all suggestions are appropriate for every situation. Filtering helps to refine the list of suggestions:
Length of Suggestions: If the user’s input is short, I may filter out longer suggestions that don’t fit well.
Character Matching: Ensure that suggestions start with the same characters just as the user’s input. For instance, if the user types "ap", suggestions like "apple" and "apricot" should appear, while "banana" should be filtered out.
Avoiding Duplicates: If a suggestion is already in the list, it shouldn’t appear again. This keeps the suggestions clean and varied.
4. User Interaction
The way users interact with suggestions can also help refine them:
Click Behavior: If users consistently select certain suggestions over others, the system can learn from this behaviour to improve future rankings.
Feedback Options: Providing users with options to give feedback on suggestions (like "not relevant" or "helpful") can guide the system to become smarter over time.
Scalability and Performance
Scalability and performance are critical aspects of designing an effective autocomplete system. As the number of users and the amount of data grow, the system must be able to handle increased loads without sacrificing speed or accuracy. Here’s how I can ensure the autocomplete system remains scalable and performs well:
1. Efficient Data Storage
Database Design: A well-structured database is essential. Using indexing can significantly speed up search queries. For example, indexing frequently searched fields allows the database to retrieve results faster.
NoSQL Databases: For large datasets, NoSQL databases (like MongoDB or Elasticsearch) can handle unstructured data efficiently and provide faster read times for autocomplete queries.
2. Caching Strategies
In-Memory Caching: Utilizing in-memory caching solutions like Redis can store popular search queries and their corresponding results. This allows the system to return suggestions almost instantly without hitting the database for frequently requested terms.
Cache Expiration: Implementing expiration policies for cache entries ensures that stale data is removed and replaced with fresh suggestions.
3. Load Balancing
Distributed Systems: As the number of users increases, I can use load balancing to distribute incoming requests across multiple servers. This prevents any single server from becoming overwhelmed and ensures that users receive quick responses.
Horizontal Scaling: Adding more servers (horizontal scaling) is often more effective than upgrading existing servers (vertical scaling). This allows the system to handle more users by simply adding additional resources.
4. Optimized Algorithms
Efficient Search Algorithms: Using optimized search algorithms can improve performance. For example, employing a Trie data structure can allow for fast prefix-based searches, which is ideal for autocomplete functionality.
Batch Processing: When processing large datasets, batch processing can be used to update suggestions or recalibrate rankings at set intervals instead of in real-time, reducing load on the system during peak times.
5. Real-Time Analytics
Monitoring Performance: Implementing monitoring tools to track response times, user interactions, and system load can help identify bottlenecks. Tools like Prometheus or Grafana can provide insights into system performance.
Scaling Based on Usage: Using real-time analytics allows for dynamic scaling of resources based on current user demand. This ensures that performance remains optimal even during traffic spikes.
Handling Multilingual and Regional Queries
As users come from diverse linguistic and cultural backgrounds, it’s essential for an autocomplete system to effectively handle multilingual and regional queries. Below is a simple Java code example that demonstrates handling multilingual and regional queries in an autocomplete system. This code includes basic language detection and provides localized suggestions based on the detected language. You can view the complete source code here
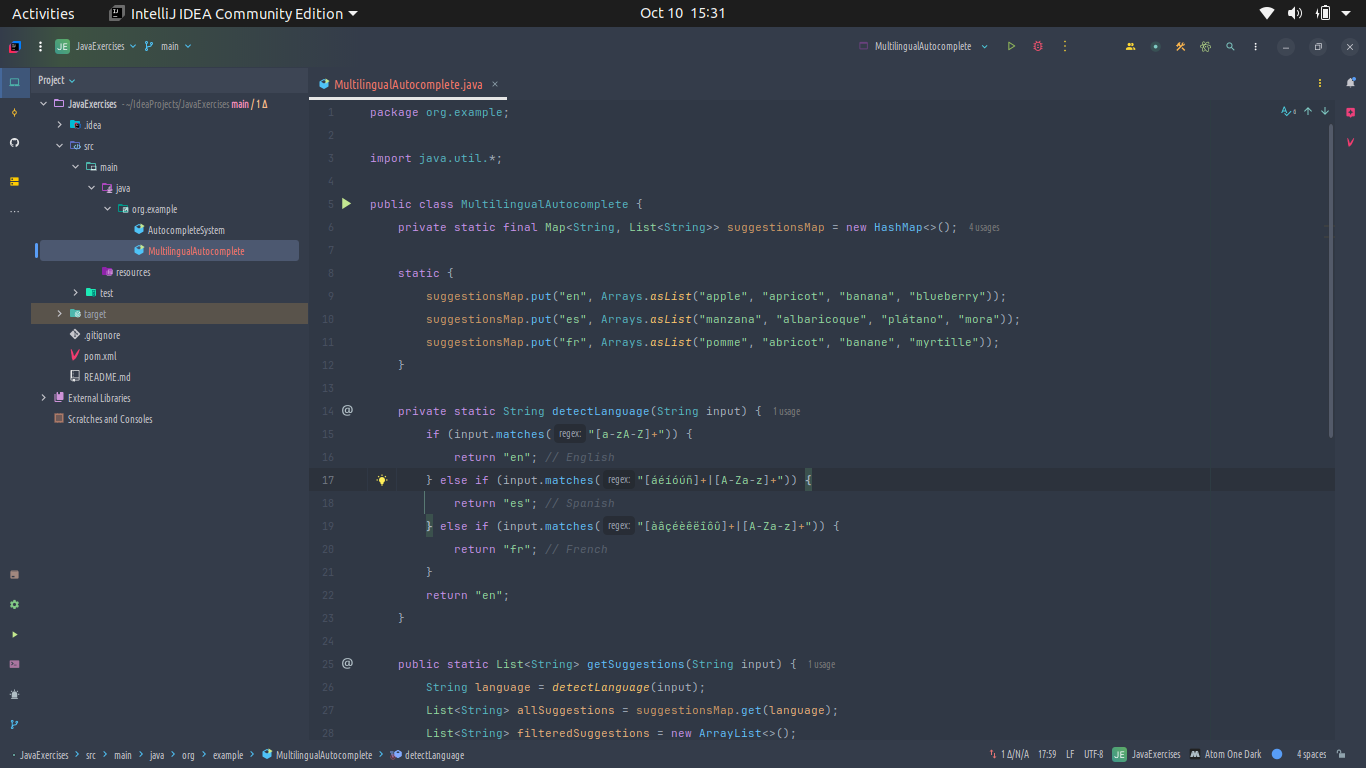
1. Language Detection
Automatic Language Detection: Implementing a language detection algorithm can help identify the language of the user’s input. This can be done using libraries such as Apache Tika or language-detection libraries that analyze the text and predict the language being used.
User Selection: Providing users with the option to manually select their preferred language can enhance the experience, especially if automatic detection isn’t accurate.
2. Localized Dictionaries
Language-Specific Dictionaries: Creating separate dictionaries for each supported language ensures that suggestions are relevant. This includes not only different languages but also regional variations (e.g., American English vs. British English).
Cultural Context: Recognizing cultural differences in terminology and phrases can help tailor suggestions. For example, using "elevator" in American English and "lift" in British English.
3. Handling Variations
Synonyms and Variants: Incorporating synonyms and common variants of words can help provide better suggestions. For example, recognizing that "color" in American English is "colour" in British English.
Dialect Recognition: Understanding regional dialects and variations can further refine suggestions. For instance, the word "pop" in some regions refers to carbonated beverages, while in others, it may not be commonly understood.
4. Character Encoding
Support for Non-Latin Scripts: The system should support various character sets and scripts (like Cyrillic, Arabic, or Mandarin). This ensures users can type and receive suggestions in their native script without issues.
Normalization: Implementing normalization techniques to handle characters with accents or diacritics can ensure that inputs like "café" and "cafe" are treated as equivalent.
5. Data Collection and Training
Diverse Datasets: Collecting data from users in different regions and languages helps train the autocomplete model to understand varied linguistic patterns.
User Feedback: Encouraging users to provide feedback on the relevance of suggestions can improve the system’s understanding of language and regional differences over time.
Security and Privacy Concerns
In developing an autocomplete system, addressing security and privacy concerns is essential to protect user data and maintain trust. Here is a simple Java code example demonstrating basic security practices for handling user input and storing sensitive data securely. This code includes features like input validation, hashing user passwords, and basic access control. View the complete source code here
1. Data Encryption
Transport Layer Security (TLS): Implementing TLS encrypts data in transit between the user’s device and the server. This prevents attackers from intercepting sensitive information, such as search queries.
Data At Rest Encryption: Storing sensitive user data, like search history, in an encrypted format on the server adds another layer of security.
2. User Data Anonymization
Anonymizing Search Queries: Removing personally identifiable information (PII) from search queries before storing them can help protect user identities. For example, hashing user IDs or using pseudonyms ensures that queries cannot be traced back to individual users.
Aggregated Data: Collecting data in an aggregated form allows for the analysis of search trends without exposing individual user information. This allows for insights to be generated without compromising privacy.
3. Access Control
User Authentication: Implementing strong authentication mechanisms, such as multi-factor authentication (MFA), helps ensure that only authorized users can access sensitive parts of the system.
Role-Based Access Control (RBAC): Ensuring that only authorized personnel can access specific user data based on their roles minimizes the risk of data breaches.
4. Compliance with Regulations
Data Protection Regulations: Adhering to regulations such as the General Data Protection Regulation (GDPR) ensures that user rights are respected and protected. This includes providing users with the option to opt out of data collection or to delete their data upon request.
Transparency: Communicating how user data is collected, used, and stored helps build trust. Providing users with a privacy policy outlining these practices is essential.
5. User Control and Preferences
Opt-In and Opt-Out Options: Allowing users to choose whether to participate in data collection or to receive personalized suggestions based on their history ensures that they have control over their data.
Feedback Mechanism: Implementing a feedback mechanism that lets users report any security concerns or suggest improvements enhances the users’ confidence in the system.
6. Monitoring and Incident Response
Continuous Monitoring: Regular monitoring for unusual activity can help detect potential breaches or attacks. Implementing logging mechanisms allows for tracking access to sensitive data.
Incident Response Plan: Having a clear plan in place for responding to data breaches or security incidents can help mitigate damage. This includes notifying affected users promptly and outlining steps taken to resolve the issue.
7. Regular Security Audits
Vulnerability Assessments: Conducting regular security audits and vulnerability assessments helps identify potential weaknesses in the system. This proactive approach allows for addressing security gaps before they can be exploited.
Penetration Testing: Engaging in penetration testing by security professionals can help uncover vulnerabilities that may not be evident through standard testing methods.
Conclusion
When designing an effective autocomplete system for search engines, it must include various critical considerations, like user behaviour, data handling, ranking, filtering, and security. If you understand user behaviour and implement design principles that prioritize usability and efficiency, you will create a seamless experience that meets your users’ expectations.
Ultimately, as technology continues to evolve, I must remain adaptable and innovative, exploring new techniques and methodologies to improve the autocomplete functionality, ensuring it remains effective and relevant in meeting user needs.
Subscribe to my newsletter
Read articles from Okoroafor Kelechi Divine directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Okoroafor Kelechi Divine
Okoroafor Kelechi Divine
I am Okoroafor Kelechi Divine, In 2020 I decided to help solve many problems in the world through innovation and modern-day designs with software engineering and technical writing as my tool.