How Generative Adversarial Networks create Images
 Alexis VANNSON
Alexis VANNSON
This article explains how Generative Adversarial Networks (GANs) create images. It covers the basic adversarial setup and how transposed convolutions turn noise into realistic images through feedback. This article explores the inner workings of Deep Convolutional GAN (DCGAN) architecture as outlined in the original research paper, and highlights its ability to generate lifelike visuals, drawing inspiration from projects like "This Person Does Not Exist."
To begin with, GAN stands for Generative Adversarial Network, a powerful framework in which two neural networks compete against each other during training.
This means that we have a first network (the Generator) generating images by modifying noise trying to deceive a second network (the Discriminator) tasked with distinguishing real images from generated ones.
We get a workflow like this:
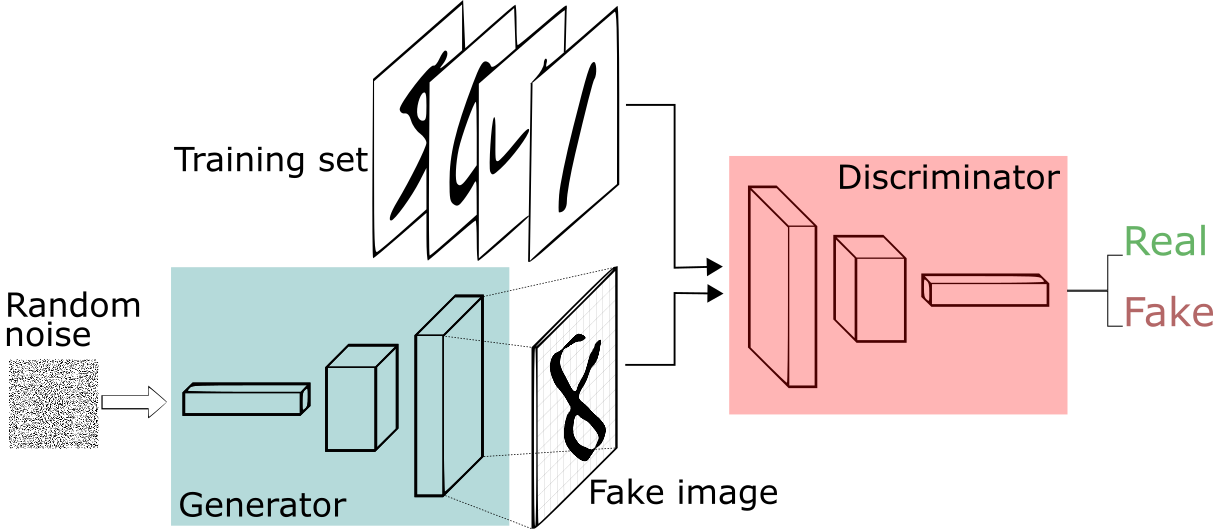
This process begins with the weights being randomly initialized from a Normal distribution with mean=0, stdev=0.02 (according to the DCGAN paper) for both the generator and discriminator. Then their training alternates using two distinct loss functions, maintaining a balance between the generator's and Discriminator's capabilities. This means that we will start to train the Generator's ability to fool the discriminator for a bit, then train the Discriminator's ability to differentiate fake from real images.
We do this over multiple iteratiosn to improve bath models.
I quite like the image of counterfeiting to illustrate this. We can visualize the Generator as a counterfeit money-creating machine and the Discriminator as some young police agent in charge of identifying fake money.

The police agent starts with no experience and is easy to fool, but learns and the money-creating machine has to improve to pass the agent. That’s how, with time, we end up with some high-quality images.
The Architecture
Typically, the goal of the generative network is to learn to map from a latent space to a data distribution of interest, meaning that we want to transform the noise (randomly initialised matrices) to fit the characteristics of the training set. For example, in the case of generating faces, there are some common characteristics faces have like eyes, ears noses, and so on.
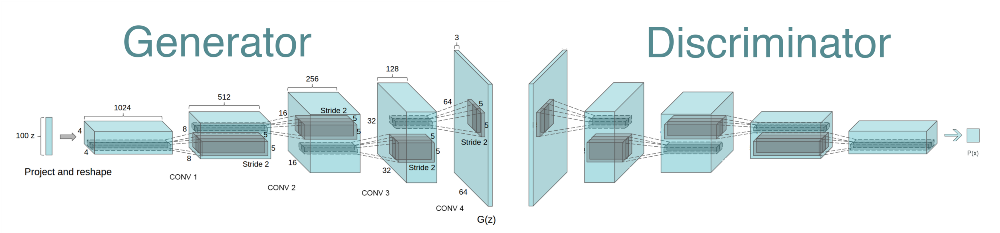
This process involves the Generator taking random noise and applying Transposed Convolutions to it, progressively upscaling and refining the noise to real images as shown above.
This iterative process helps the Generator improve its ability to produce realistic images over time.
Transposed Convolution
A transposed convolution is essentially a convolution operation in reverse. Instead of reducing the spatial dimensions of the input (like standard convolutions do), it increases them. How does it work?
In transposed convolution, the input is expanded by inserting zeros between the original values, creating a larger "empty" space for the convolution operation to fill. A filter then slides over this expanded input, computing the dot product over the regions filled with the original values and inserting output values into the newly created zeros. This process effectively fills in the spatial gaps, resulting in an upscaled image. Similar to standard convolution, the stride determines how far the filter moves across the input. For transposed convolution, using a stride greater than 1 further increases the output size.
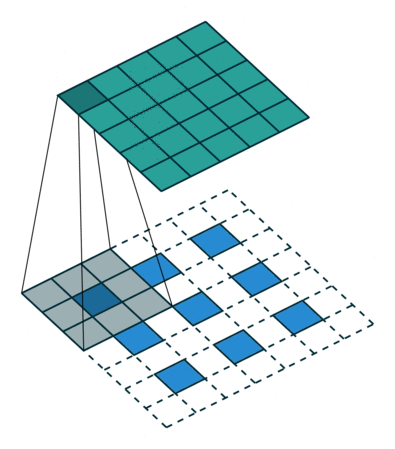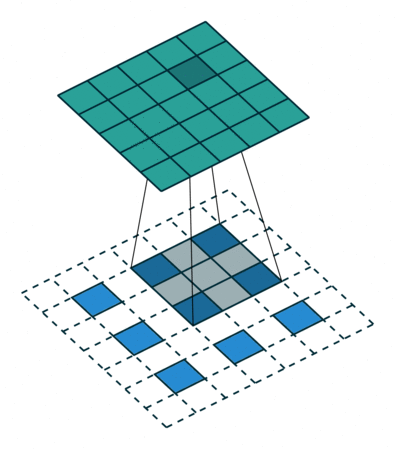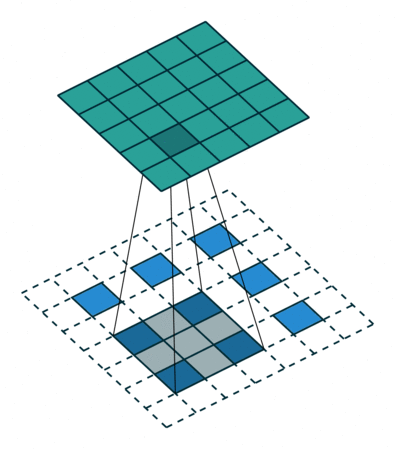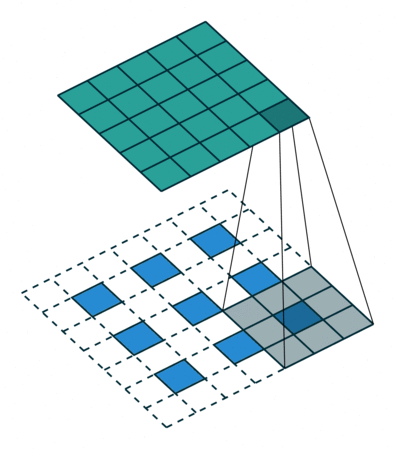
The definition of the Generator is very similar to the CNN architecture (normalization and activation function) but with these transposed convolutions instead of normal convolutions making it possible to go from noise to an image.
# Generator Code
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. ``(nc) x 64 x 64``
)
def forward(self, input):
return self.main(input)
The Discriminator is just like a normal Classifier like in CNN for image classification.
The Loss
As previously mentioned we have two separate networks that are trained by competing against each other.
The Discriminator's job is to tell real images apart from fake ones created by the Generator. It gives a probability between 0 and 1 that the input is real.
The goal of the Discriminator is to maximize the likelihood of correctly classifying real and fake images. Hence, the Discriminator loss is split into two parts:
Real data loss: The Discriminator tries to correctly classify real images as real.
Fake data loss: The Discriminator tries to correctly classify fake images (from the Generator) as fake.
The Generator's goal is to create fake images that are convincing enough to fool the Discriminator into thinking they are real. The Generator doesn't have access to the real or fake labels; instead, it learns through feedback from the Discriminator.
By minimizing its loss, the Generator improves at creating images that are increasingly similar to real images.
Minimax Game: The Adversarial Nature
GAN training can be understood as a minimax game between the Generator and the Discriminator, where each network tries to optimize its respective loss:
Discriminator: Maximizes ( log D(x) + log (1 - D(G(z))) ), to become better at distinguishing between real and fake images.
Generator: Minimizes ( log (1 - D(G(z))) ) or equivalently maximizes log D(G(z))(to fight vanishing gradients), to generate images that are more likely to be classified as real by the Discriminator.
The overall objective for GAN training is written as:
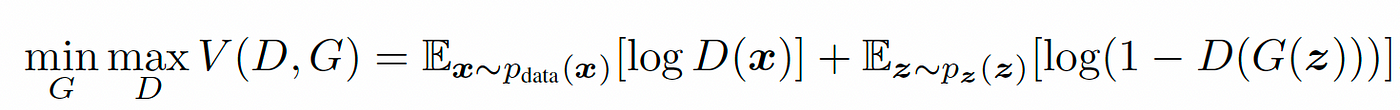
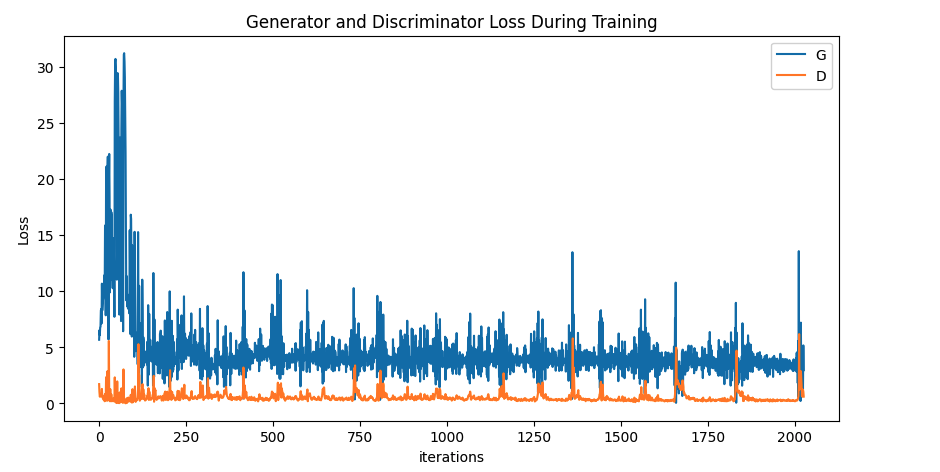
This Minimax game is well illustrated with the spikes in plot of the losses:
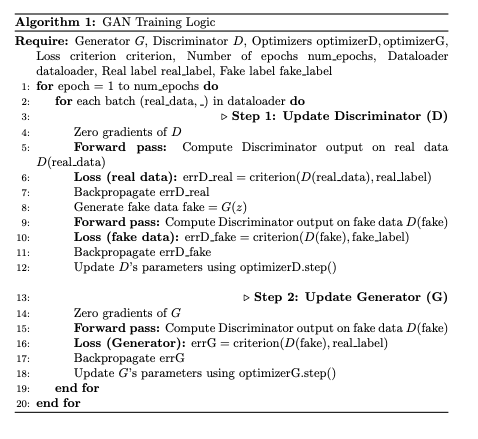
The training loop
Here's a brief explanation of the logic behind the steps involved in training the Discriminator and Generator in a GAN:
We start off by computing Loss Calculation for Real Data: By feeding real samples into the Discriminator and calculating log(D(x)), we assess how well the Discriminator identifies these as real (ideally close to 1). Then with Fake Data: By feeding fake samples (G(z)) into the Discriminator and calculating log(1 - D(G(z))), we assess how well the Discriminator identifies these as fake (ideally close to 0). After computing the losses for both real and fake data, we calculate the gradients through backpropagation and then update the Discriminator's weights using these accumulated gradients to improve its ability to differentiate between real and fake images.
Likewise for the Generator, but we compute the Loss by maximizing log(D(G(z))) which is the same as minimizing ( log(1 - D(G(z))) but can lead to poor gradient flow)
Overall, this adversarial process creates a feedback loop where the Discriminator and the Generator continually improve against each other, resulting in the Generator producing high-quality images over time.
Conclusion
We’ve seen how the architecture of the GAN, including techniques such as transposed convolution, enables the model to upscale and enhance image quality. The adversarial training process, involving careful adjustment of parameters and loss functions, allows GANs to systematically refine their outputs over time, ultimately leading to increasingly realistic images.
You can find the implementation for this project on my GitHub here.
I trained the model for about 30 epochs which only got me to the point where I was able to generate some monster faces (let’s consider it a feature)

For context, this is the how the noise at the beginning looks like:

If something wasn’t clear, if you want to expand on a topic, or if you just want to chat, feel free to reach out in the comments. Thanks for reading!
Subscribe to my newsletter
Read articles from Alexis VANNSON directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by