Monitoring the Health of Micro-Services: How we do it?
 Rakesh Vardan
Rakesh Vardan
In my recent project, we successfully integrated the API Health Checker Dashboard, developed by Osanda Deshan, a solution we have been using in our project for quite some time. This open-source solution provides real-time monitoring for the availability of backend and frontend services. This tool has significantly streamlined our ability to track and maintain the health of various APIs. I’d like to share my experience using it, along with a technical overview and a comparison to other solutions.
The Need for an On-Demand API Health Check Page
In our project, managing a growing number of backend services across multiple environments (development, multiple staging environments, UAT) became a significant challenge. We needed a way to quickly check the health of services without relying on constant, real-time monitoring. Instead, we were looking for a simple, on-demand health check solution that allowed our team to manually verify the status of services at key moments, such as before or after deployments, without unnecessary overhead.
This approach would act as a first quality gate—a quick check to ensure that all critical services are running as expected before moving on to more rigorous testing or deployments. We didn't need a complex, continuous monitoring tool with alerting, but rather an easy way to manually trigger health checks for services when necessary. This is especially useful in scenarios like:
Pre-deployment checks to confirm that services are functioning properly before pushing updates.
Post-deployment checks to verify that new releases haven't broken any dependencies or services.
On-demand troubleshooting when we see issues with the application, allow us to quickly check the availability of services.
After exploring various solutions, we found that many enterprise-grade tools such as Dynatrace or Prometheus were too complex and offered features we didn’t need, like constant uptime monitoring and alerts. What we needed was a simpler, open-source solution to display API statuses when requested.
That’s when we came across the API Health Checker Dashboard. This tool provided exactly what we were looking for:
On-demand health checks that allow us to see the current status of our services whenever we need to, without requiring continuous polling or monitoring.
A centralized view of all services across environments, making it easy for team members to verify the health of critical services before proceeding with further tasks.
Let’s have a detailed breakdown of how this tool works under the hood, its key features, and why it stands out in comparison to other monitoring solutions.
Key Features of API Health Checker Dashboard
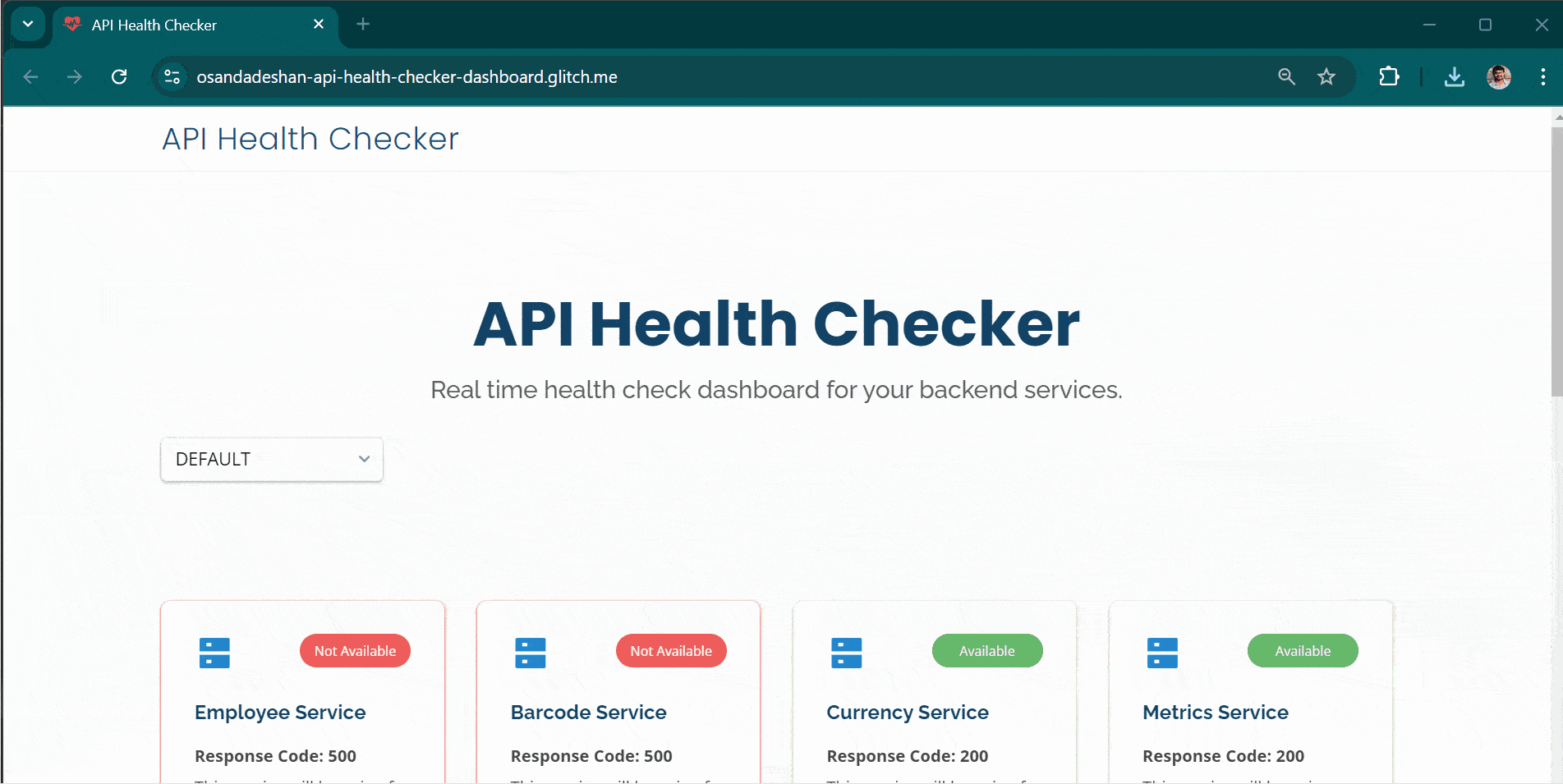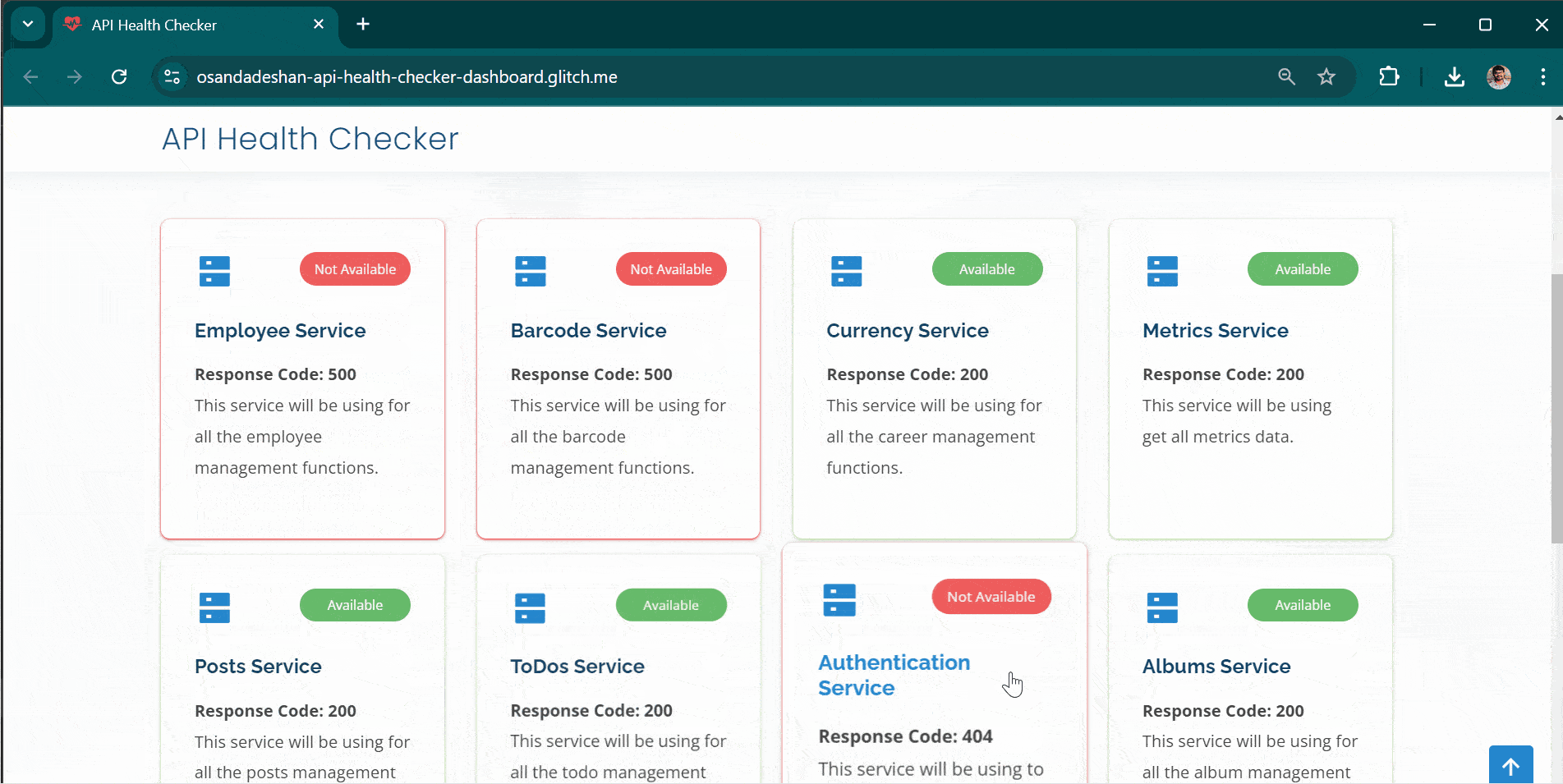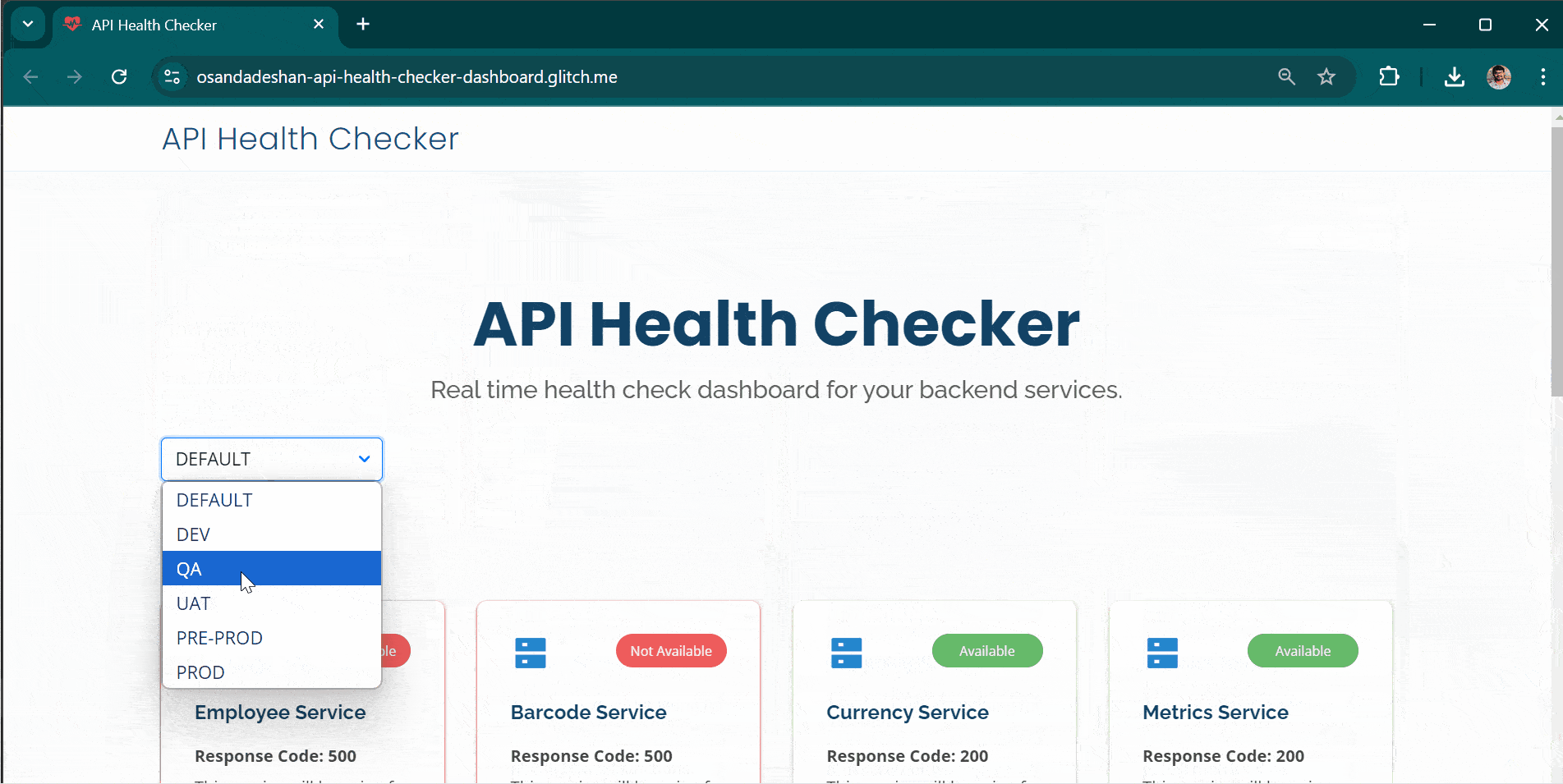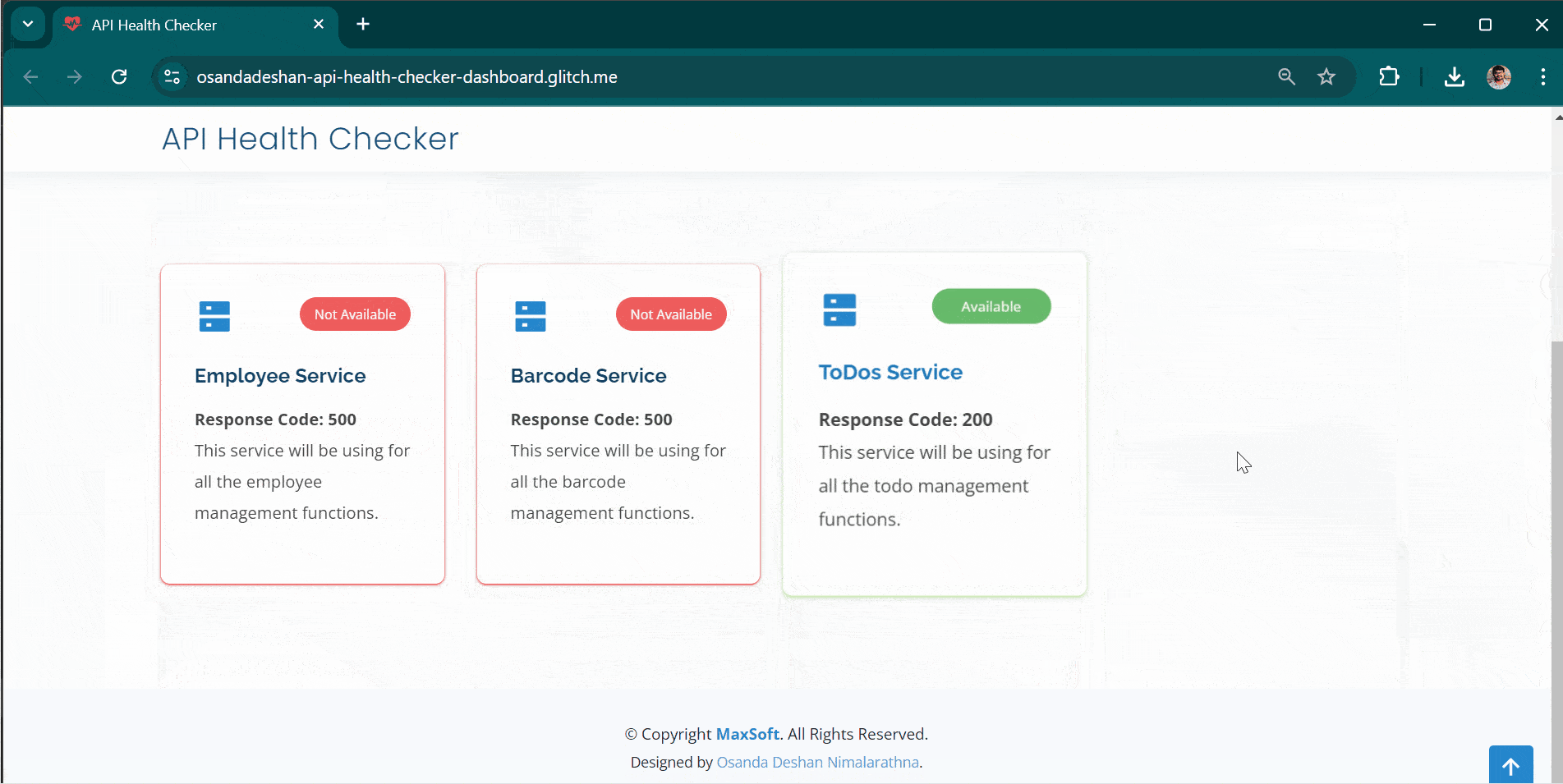
Real-Time Monitoring: The dashboard continuously monitors the availability of backend services by sending periodic requests to predefined health-check endpoints. It refreshes every "x" seconds (configurable), allowing near-instant visibility into the status of APIs.
Multi-Environment Support: You can maintain multiple environments such as production, staging, or development by configuring separate JSON files. This ensures that each environment’s health is tracked independently within the same dashboard.
Mobile-Friendly Interface: The dashboard's UI is responsive and can be accessed on both mobile and web browsers.
No CORS Issues: The tool includes a proxy layer to prevent CORS (Cross-Origin Resource Sharing) issues, ensuring smooth communication between different services across domains.
Demo Page Available: A live demo is hosted here, where you can interact with a sample dashboard to see the tool in action.
How It Works - Technical Breakdown
The API Health Checker Dashboard is built using Node.js and primarily operates by making HTTP requests to the health-check endpoints of the services you wish to monitor. Here’s a step-by-step breakdown of how it functions internally:

Polling Mechanism:
The system makes use of a polling mechanism, sending periodic requests to each service’s health-check endpoint. The interval for these requests can be set in the configuration file (default is every 30 seconds).
The system expects the endpoints to return an HTTP status code. If the status is in the 200-range, the service is considered “available.” Any other status code, or a timeout, marks the service as “unavailable.”
Service Configuration:
Services to be monitored are defined in JSON configuration files located in the
configdirectory. This is where you list your backend services’ health-check URLs.For each service, you can provide:
Name of the service (for display on the dashboard)
Health-check endpoint (URL)
Environment, Description and other details as below
//config/qa-config.json [ { "name": "Employee Service", "description": "This service will be using for all the employee management functions.", "id": "employee", "environment": "qa", "url": "http://dummy.restapiexample.com/api/v1/employees", "contact": "osanda@maxsoft.com" }, { "name": "ToDos Service", "description": "This service will be using for all the todo management functions.", "id": "todo", "environment": "qa", "url": "https://jsonplaceholder.typicode.com/todos/1", "contact": "osanda@maxsoft.com" } ]
Frontend Interface:
The user interface is built using standard web technologies—HTML, CSS, and JavaScript—allowing it to be highly customizable. It provides a dashboard view where all services are listed, showing their real-time status.
Each service is displayed as a tile with either a green or red status indicator, representing "healthy" or "unavailable" services. The status updates are fetched using AJAX calls, allowing for real-time updates without the need to refresh the page.
Handling CORS Issues:
- Many API health-check tools face CORS issues when making requests across different domains. To overcome this, the API Health Checker Dashboard includes a proxy layer. This proxy acts as an intermediary between the dashboard and the health-check services, routing requests in such a way that bypasses the CORS restrictions.
Real-Time Data Flow:
The Node.js backend sends requests to the specified endpoints and handles the incoming HTTP responses. The results are then passed to the front end, which updates the status tiles accordingly.
The update frequency (i.e., the polling interval) can be adjusted based on your preference by modifying the configuration settings.
Deployment:
The tool is designed to be easy to deploy. After cloning the repository, you can install the necessary dependencies using
npm install, then run the dashboard withnpm run dev. The dashboard will be accessible athttp://localhost:5000by default.You can also deploy this solution to a cloud platform or any server capable of running Node.js applications.
Our apps are deployed to the Pivotal Cloud Foundry environment, hence we
cf pushto deploy the health check app in a respective environment.
Comparing with Other Similar Solutions
Dynatrace
What it offers: Dynatrace is a powerful all-in-one monitoring tool that provides deep observability across applications, infrastructure, and cloud environments. It uses AI to detect anomalies and offers advanced alerting, real-time monitoring, and root-cause analysis.
Why it wasn't the right fit for staging: While Dynatrace excels in production with its full-scale monitoring and alerting capabilities, it can be overkill for non-production environments. Its complexity and cost don’t justify the overhead for staging environments, where we primarily need on-demand health checks rather than continuous monitoring.
Prometheus
What it offers: Prometheus is an open-source monitoring system designed for capturing metrics, which includes querying and alerting features. It’s highly flexible and customizable, especially when paired with Grafana for visualization.
Why we didn’t choose it: Prometheus requires significant setup and maintenance, and it’s tailored more for capturing time-series data and long-term metrics, which adds unnecessary complexity. We wanted a lightweight solution for quickly verifying API health, and setting up Prometheus with custom dashboards and metrics would be overkill for our needs.
Pingdom
What it offers: Pingdom is well-known for uptime monitoring, providing real-time alerts when services go down. It’s widely used for website and API uptime checks and offers easy-to-read dashboards.
Why it wasn’t ideal: While Pingdom is great for production environments, it comes with subscription costs that aren’t justified for non-production environments. Furthermore, its primary focus on uptime and real-time alerts isn't necessary for the on-demand checks we need in testing environments.
Atlassian Status Page
What it offers: Atlassian’s Status Page is a communication tool that allows companies to inform users about the operational status of their systems. It’s more focused on status reporting and sharing that information with stakeholders, rather than on real-time technical monitoring.
Why we didn’t choose it: This tool is mainly for communication with external stakeholders about service status rather than an internal tool for health-check verification. We needed a tool focused on internal, quick health checks that developers & testers could use during stage environment testing.
Final Thoughts
Using the API Health Checker Dashboard has allowed us to create a unified and reliable view of our API services' health without the need for complex configurations or expensive software. It’s a great fit for teams that require lightweight, real-time API monitoring without the overhead of larger, more complex tools. For those looking for an open-source alternative, I highly recommend trying this solution.
For more technical details and to get started, you can explore the project on GitHub
Subscribe to my newsletter
Read articles from Rakesh Vardan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rakesh Vardan
Rakesh Vardan
I am a Software Development Engineer in Test (SDET) specializing in CI/CD processes, with a strong background in UI and API test automation. My expertise lies in designing robust testing frameworks that integrate seamlessly with CI/CD workflows, guaranteeing software quality and reliability.