Little Bit of Analytics Engineering
 Sion Kim
Sion KimThis article is a note on a book Analytics Engineering with SQL and dbt.
Chapter 1. Analytics Engineering
Data Analytics Lifecycle
Problem definition
First, we need to understand the problem. Identify the business objectives and available resources to solve the problem.
Data modeling
Begin modeling data according to the modeling technique that fits the needs - diamond strategy, star schema, data vault, etc.
Data ingestion and transformation
Ingest and prepare data from source systems to match the models created.
Data storage and structuring
Decide the file format (Apache Parquet, Delta Lake, or Apache Iceberg), as well as partitioning strategies and storage components (S3, Redshift, Snowflake).
Data visualization and analysis
Visualize data to directly support decision making. This phase should be in close coordination with business stakeholders.
Data quality monitoring, testing, and documentation
Implement quality control to ensure that stakeholders can trust exposed data models, document transformation steps and semantic meanings, and ensure pipeline testing.
Why Use dbt
Enables organizations to perform complex data transformation tasks quickly and easily.
Integrates with other tools, like Apache Airflow, for complete data pipeline management.
dbt Features
Data modeling: Allows defining data models with SQL-based syntax.
Data testing: Provides a testing framework for teams to test their data models, ensuring accuracy and reliability.
Data documentation: Enables documentation of data models and services.
Data tracking capabilities: Allows tracing the origin of data models (data lineage).
Data governance capabilities: Enforces data governance policies, such as data access controls, data lineage, and data quality checks.
ELT
Data is first extracted and loaded into target system before transformation
Advantages over ETL:
Increased flexibility to support a wider range of data applications
Versatility in accommodating various data transformations and real-time insights directly within the target system
Derive actionable insights from the data more rapidly and adapt to changing analytical needs
Disadvantage:
- Higher storage and ingestion costs - this is justifiable with flexibility it brings to operations
Chapter 2. Data Modeling for Analytics
Data Modeling
Defining the structure, relationships, and attributes of data entities within a system
Essential aspect of data modeling is the normalization
Breaking data into logical units and organizing them into separate tables → eliminates data redundancy and improves data integrity
Normalization ensures that data is stored in a structured and consistent manner
With SQL, we can define tables, manipulate data, and retrieve information
- Complementary to SQL, dbt serves as a comprehensive framework for constructing and orchestrating complex data pipelines. Users can define transformation logic, apply essential business rules, and craft reusable modular code components, which is known as models
Phases of Data Modeling
Conceptual
Identify the purpose of the database and clarify problems or requirements with stakeholders. Understand the required data elements, relationships, and constraints with subject matter experts (SME).
Logical
Normalize the data to eliminate redundancies, improve data integrity, and optimize query performance. The normalized logical model reflects the relationships and dependencies among entities.
Physical
Translate the logical data model into a specific database implementation.
Data Normalization Process
1NF
Eliminate repeating groups by breaking the data into smaller atomic units (atomicity).
2NF
Examine dependencies within the data. Ensure that non-primary key columns depend on the primary key (redundancy).
3NF
Eliminate transitive dependencies by ensuring that non-primary key columns are only dependent on the primary key (transitivity).
Dimensional Data Modeling
A popular approach to data modeling is dimensional modeling, which focuses on modeling data to support analytics and reporting requirements. Particularly suited for DW and BI applications
Data modeling lays foundation for capturing and structuring data and dimensional modeling offers specialized technique that support analytical and reporting needs. Together, dimensional data modeling enables robust and flexible DB that facilitate transactional processing and in-depth data analysis
Referencing Data Models in dbt
Using Jinja template, user can establish clear dependencies among models, enhance code reusability, and ensure the consistency and accuracy of data pipeline
- Jinja: templating language that allows dynamic transformation within SQL
{{ref()}}: dbt can automatically detect and establish dependencies among models based on upstream tables
Staging Data Models
Staging layer serves as the basis for the modular construction of complex data models. Each staging model corresponds to a source table with 1:1 relationship
Example: select relevant columns from the raw table. Basic transformations such as rename column or convert data types
Intermediate Data Models
- Combine the atomic building blocks from the staging layer to create complex and meaningful models
Mart Models
Combine all relevant data from multiple sources and transform it into a cohesive view. Responsible for presenting business-defined entities via dashboards or applications
Typically materialized as tables. Materializing enables faster query execution
Testing in dbt
Tests are designed to identify rows or records that don’t meet the specified assertion criteria
Singular tests: specific and targeted tests written as SQL. Test specific aspects of data, such as
NULLvalue absence in a fact table or validationGeneric tests: versatile and can be applied to multiple models or data sources. Checking data consistency among tables or ensuring the integrity of specific columns
Chapter 3. SQL for Analytics
Views
A view is a virtual table in a DB defined by a query. View dynamically retrieves data from the tables when it’s accessed
Example
CREATE VIEW author_book_count AS SELECT COUNT(books.book_id) AS book_count FROM authors JOIN books ON authors.author_id = books.author_id GROUP BY authors.author_id
CTE (Common Table Expressions)
Acts as a temporary result set. Enhance readability of code by breaking queries into blocks
- Define once, use many times
WITHKeyword to declare the CTE.ASkeyword to define the CTE queryExample
WITH cte_one (column1, column2) AS ( ... ), cte_two (column3, column3) AS ( ... ) SELECT column1, column2 FROM cte_one
Window Functions
Performs an aggregate-like operation on a set of query rows
Example: perform calculation on a set of table rows related to the current row
SELECT book_id, book_title, publication_year, ROW_NUMBER() OVER (ORDER BY publication_year) AS running_count FROM books;PARTITION BYdivides the rows into partitions based on columns. The window function is applied separately to each partitionORDER BYspecifies columns to determine the order within each partition. Helps define the logical sequence
Practical dbt
Practical dbt use case demonstrated by Danggeun data team
Structure
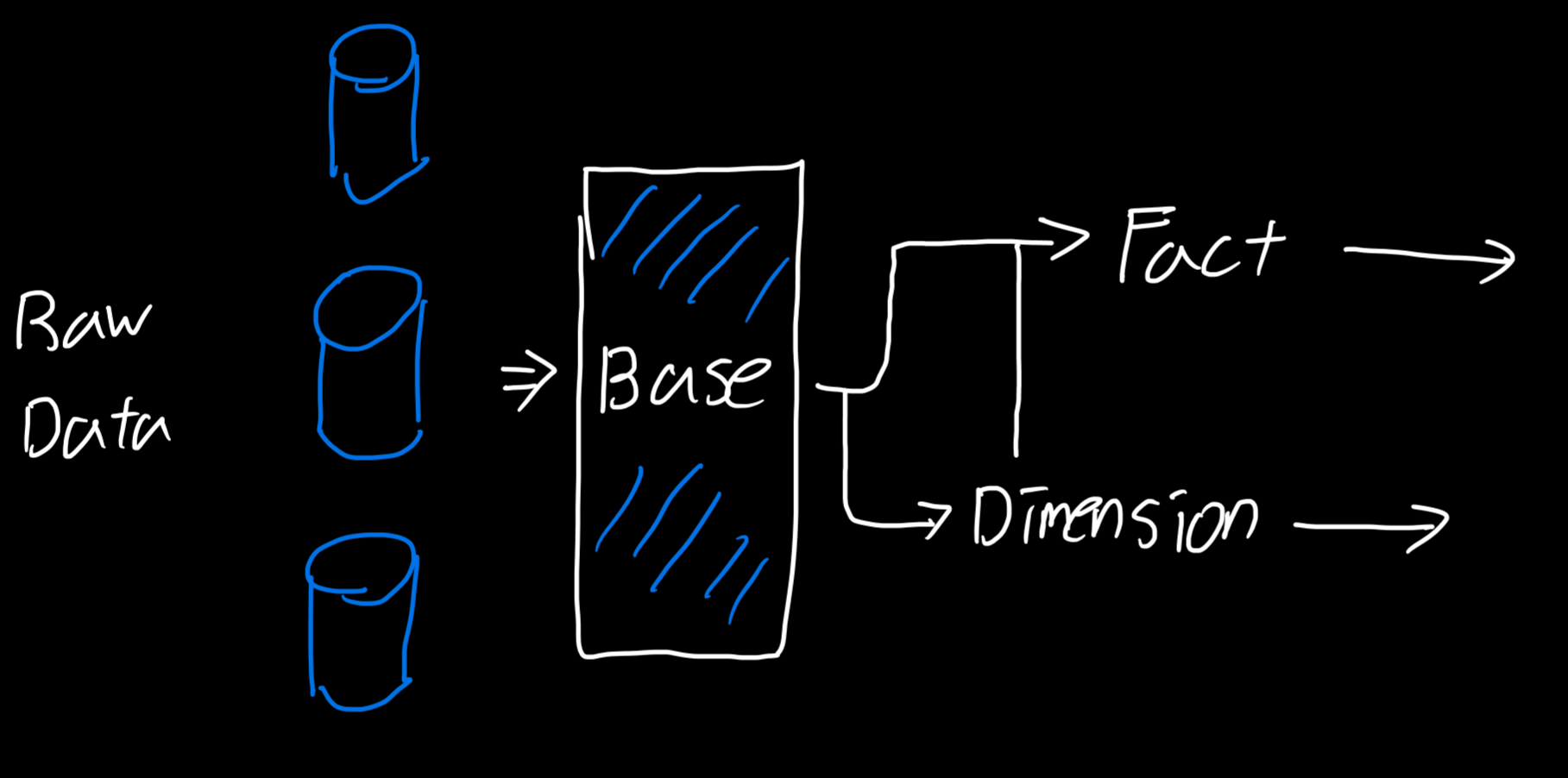
Source Layer (Raw): Source data from Data Warehouse
Base Layer (staging)
You can slightly transform data in this layer. Such as SELECT columns, data formatting, and type casting
Mapped 1:1 to source data
We don’t use physical table, instead materialize with view
Dimension Layer: Entity attributes, such as
UserandProductWe can use advanced operations, such as
JOIN, WHEREMaterialize with table
Need for fresh data → periodic calculation and we can auto adjust refresh period using
dbt tags
Fact Layer: Contains information
X did Y. User activity data, object creation, or transformation eventWe can use advanced operations like dimension layer here. However as time progress, more data get added → large data size
- Since data size is big and we can split data by time frame, we can Materialize incremental to take advantage of data lookup and storage efficiency
Like dimension layer, can use
dbt tagsto auto adjust refresh period
SQL
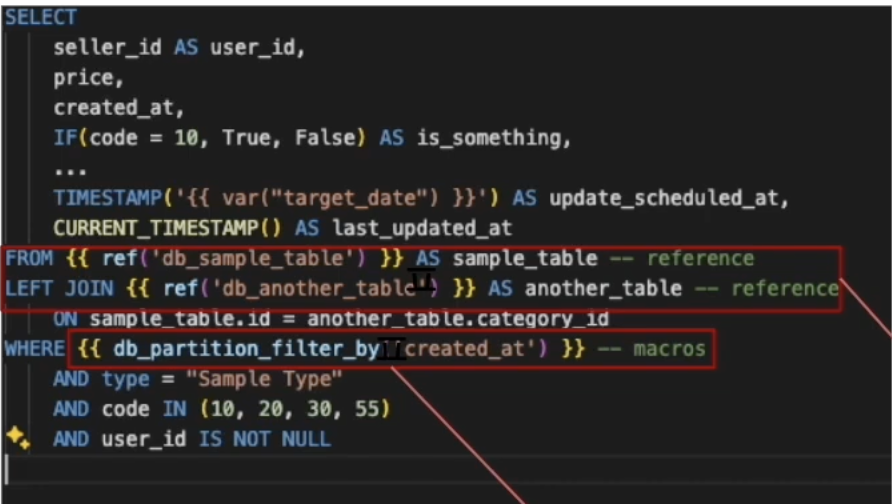
Use
refto depend on other models- Wrote defensive logic to protect cyclic situation
Created macros as needed by model attributes
- Example: automatically save snapshot, add custom label to bigquery query
yaml
- Easily define storing, partitioning, and clustering method by defining config in yaml and sql
Orchestration
Use Astronomer Cosmos to run pipeline
Observability using Datadog → Slack
Documentation
dbt docsto provide stakeholders 1. model definition and explanation 2. business logic
Subscribe to my newsletter
Read articles from Sion Kim directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sion Kim
Sion Kim
Associate Analyst at Reinsurance Group of America