All we need is Structure
 Timon Jucker
Timon Jucker
Do you remember when Dr. Carter, in the previous article "Demystifying Concurrency: Essential Clarifications," explained the difference between Async and Parallel? I think this story ended before touching on a crucial point. Even if you understand the core concepts and therefore have a better base than most people, it's easy to get into trouble with the implementation details. Like most explanations, it gave the impression that understanding the core concepts would be enough to master concurrency. Most people know this isn't true. But as we already established, it's not easy to not get drawn into detailed, complicated rabbit holes that sometimes lead to even more confusion. So, let's dive deeper into the problem and try to find best practices for these issues.
Let's start with the simplest part: the quadrant that does not include concurrency.
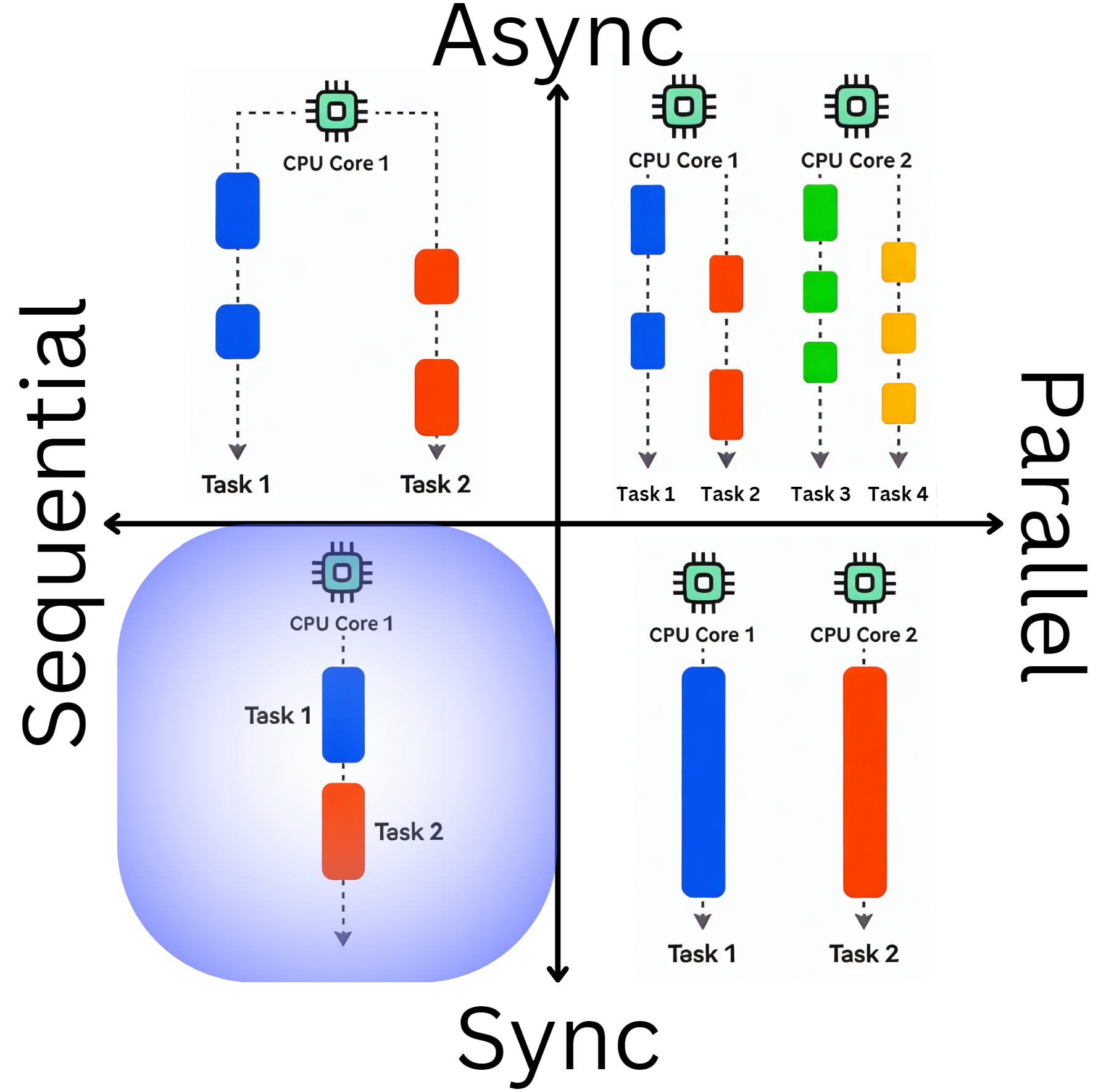
The concepts in this quadrant appear quite familiar. But it is helpful to build a solid foundation once again. What paradigm do we use here? Could this be object-oriented, modular, or functional programming? When we look at the evolution of paradigms in programming, it becomes evident that there is one paradigm that has truly endured and has never been seriously challenged. This paradigm is structured programming.
The principles of structured programming and by extension structured design have influenced all modern programming languages, going back even to C, Pascal, and Ada. Even today, the core ideas of structured programming are embedded in the design of contemporary languages and continue to guide best practices in software development. One of the main benefits of this pattern is that we can be sure Task 1 does not interfere with Task 2 and can therefore be considered completely isolated. This reduces the mental load significantly in all stages of the program lifecycle.
The first quadrant that is concerned with concurrency is the one that is concerned with multiple tasks running in parallel.
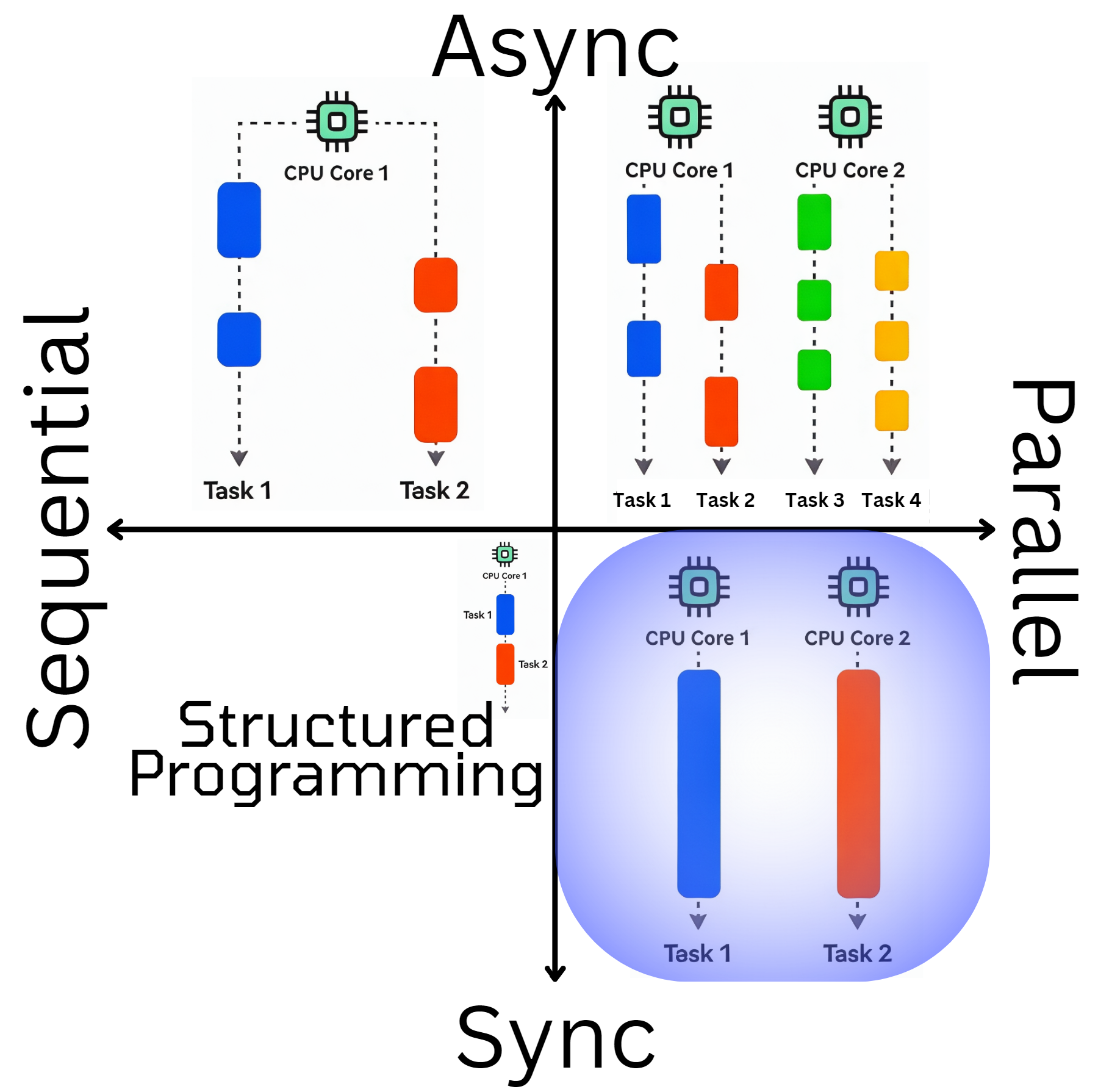
Definitions for Parallel computing are not that controversial and generally consistent. There are also well-established patterns for the synchronous part of parallel execution, such as Data-Parallelism, which have been proven effective, like PLinq in C# or MapReduce to keep it more general. Single instruction, multiple data (SIMD) is another method to achieve Data-Parallelism. Also, the techniques for executing code on the GPU are well-established and work effectively, as evidenced by Nvidia's success with Cuda in AI applications. It is well understood and reasonably intuitive what this means and why it's challenging. Having a focus on strict Data Partitioning also allows us to reason about these Tasks in Isolation and keep the non-concurrent mental model that we are used to, keeping the complexity at a reasonable level. Because it is possible to think about it as if all the Parallel executions would run in sequence without changing the final outcome.
The next quadrant is the one that is concerned with multiple Tasks running in a time-shared fashion, also called cooperative multitasking.
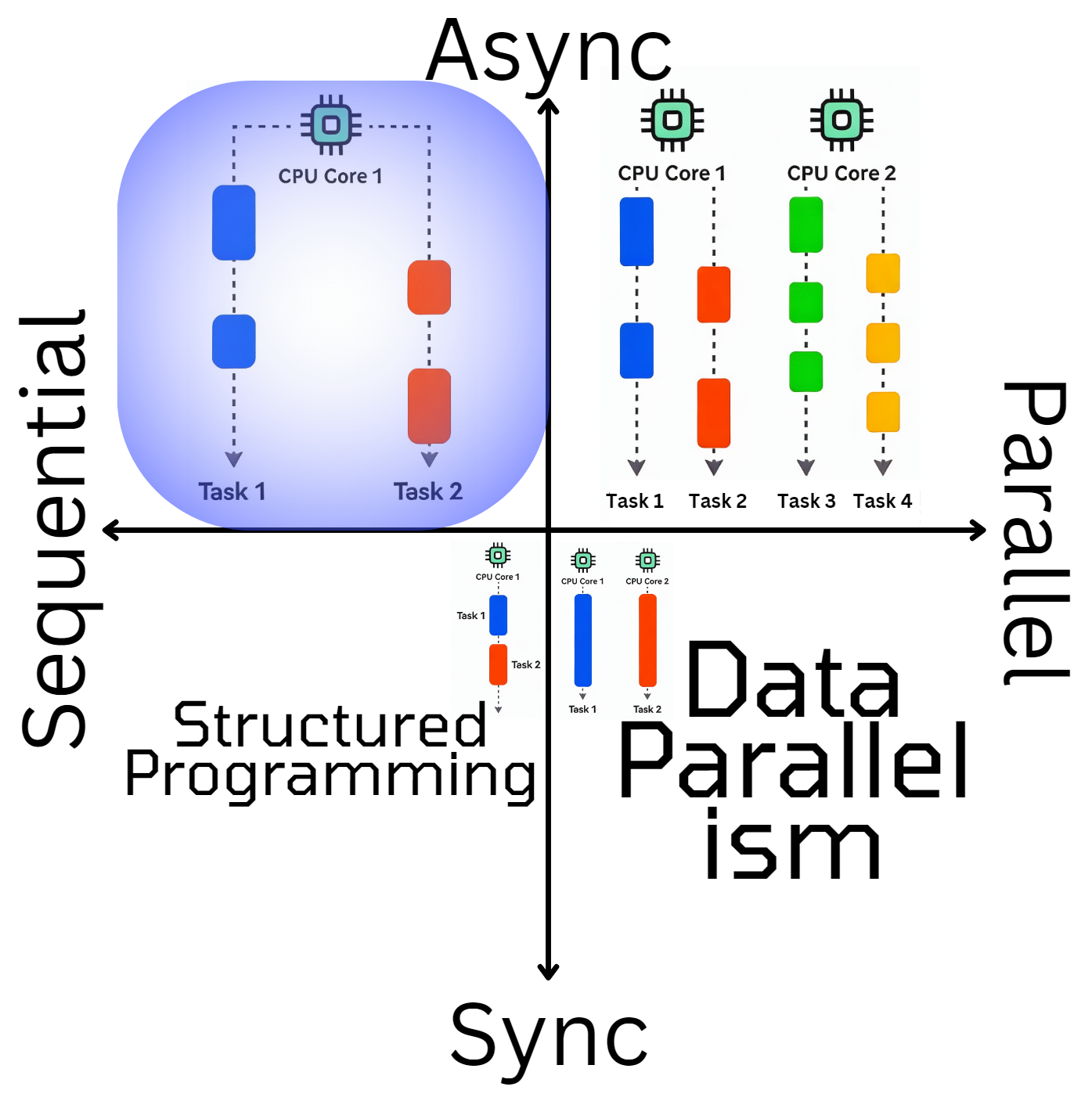
It looks like programming languages are converging on the async/await pattern for handling idle time. Even new experimental languages like Roc and Gleam are adopting and improving this pattern.

The async/await approach is clearly optimized for Sequential and Asynchronous code execution.

But not everyone is happy with this approach. Languages like Verse introduce the concept of time flow akin to control flow to address this problem by treating it as a special case of the larger async realm. So let's see how this evolves. But at the moment, it is the current best practice for handling idle time. Like Cory Benfield in The Function Colour Myth, I would also argue that the benefits outweigh the drawbacks of this approach. It lets you think of time-shared concurrency as sequences that get executed sequentially one after the other.
Most commonly, this is the case in node web servers where everything runs single-threaded but idle time can be used by other tasks. There are quite good explanations that showcase how this works with a (Micro)Task Queue. The most important part of all of this is that it allows us to reason about these tasks in isolation and keep the non-concurrent mental model that we are used to, keeping the complexity of the necessary mental model at a reasonable level.
You probably spotted the pattern. The goal is always to structure the concurrency in a way that allows us to isolate the data and execution. So let's discuss the last quadrant:
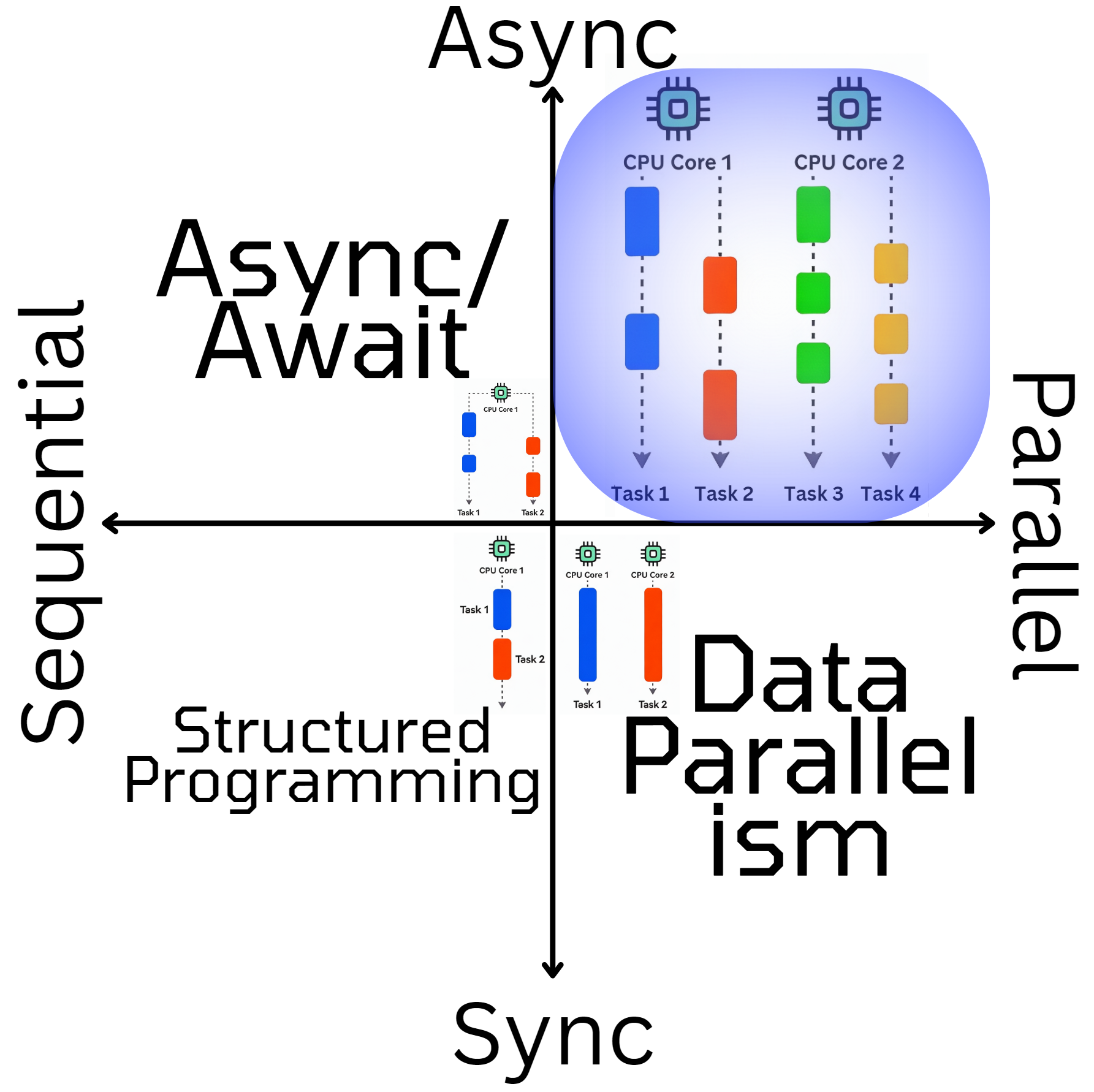
This part is often ignored or forgotten, probably because no one has used this visualization to explain it until now 😉. For the parallel async part of concurrency, there doesn't seem to be a clear standard. This is partly why Go was invented, and why people like Mads Torgersen, Lead Designer of C#, say things like:
The world is still short on languages that deal super elegantly and inherently and intuitively with concurrency
There are certainly approaches: Go has Goroutines, a variation of Coroutines available in many other programming languages. A similar pattern was explored in Java and other languages with Green Threads. Thread and process-based concurrency provided directly by the operating system is also widely used. Additionally, the Actor Model is implemented by many libraries. Or even consensus protocols like raft are a way to solve concurrency. But none of them seem to be the unified approach that can handle it really well.
Recently, a new pattern called Structured Concurrency emerged, first introduced in the Python community with Trio. It was almost independently adopted by Kotlin and, since Java 21, also in the main JVM language. Swift seems to put the most effort into it by trying to get the most out of this model, extending it with Actors and Sendable Types.
An easy-to-understand explanation of the basic Idea can be found here. It essentially extends the async/await pattern to work for parallel tasks. It improves cancellation, error handling, and shared resource management for concurrent tasks, and also improves readability, productivity, and correctness. The most beneficial part is probably the ability to check for correctness at compile time. Swift is even working to extend this pattern to ensure data-race safety. There are also libraries in other languages, such as StephenCleary/StructuredConcurrency, created by one of the key figures in the concurrency field.
As already mentioned Verse introduces the concept of time flow to implement Structured Concurrency. This is controlled with concurrent expressions like Sync, Race, Branch, etc. This is similar to structured flow control such as block, if, for, and loop that constrain to their associated scope. Similarly, in Swift, async/await is also a special case of Structured Concurrency as long as it is used within an async context like a task group or with async let bindings. I would argue that async/await is not generally a special case of Structured Concurrency because both Swift and Verse have the notion of Unstructured Concurrency. Most programming languages decided to implement async/await by default as Unstructured Concurrency; therefore, I like to think about it as a separate concept.
Down the C# Rabbit Hole: Untangling Async/Await, ConfigureAwait, and Concurrency Challenges
This section might be too detailed for this article. It assumes you are familiar with C#. However, it helped me understand the difference between Structured and Unstructured Concurrency better. If you're not interested in C# specifics, you can skip this part and start reading from "Debunking Async/Await Myths" onward as we also look at the general problem in the continuation context problem.
The C# folks probably had to deal with the difference between structured and unstructured concurrency without really knowing it. It has to do with the fact that C# has ConfigureAwait(false) and, for example, Node.js has nothing comparable. It has to do with the fact that C# has multithreading capabilities and Node.js runs in only one thread. That is why the continuation in Node.js is guaranteed to run on the same thread as the part before the await. This is the default configuration in C# as well, but when used in a multithreaded environment, this can lead to problems. The same problem is the reason for having to keep unstructured concurrency in languages like Swift and Verse. That is why I argue that async/await is not part of Structured Concurrency but can be used complementarily with async/await. If you want to go really deep into implementation details in C#, here is a really interesting link that is also helpful to understand the problems of async/await in other multithreaded contexts.
private HttpClient _client = new HttpClient();
async Task<List<string>> GetBothAsync(string url1, string url2)
{
var result = new List<string>();
var task1 = GetOneAsync(result, url1);
var task2 = GetOneAsync(result, url2);
await Task.WhenAll(task1, task2);
return result;
}
async Task GetOneAsync(List<string> result, string url)
{
var data = await _client.GetStringAsync(url);
result.Add(data);
}
Code like this looks like it belongs to Structured Concurrency but is really Unstructured Concurrency because of the implicit Parallelism even though everything is awaited in the block of code.
Let's also dive into the ConfigureAwait(false) topic itself, as I have rarely seen a good explanation of it. There are talks that improve year after year, like Correcting Common Async/Await Mistakes (let's hope it becomes excellent in a few years), but most explanations are quite bad or overly complicated. The common reason given for using ConfigureAwait(false) is that it reduces overhead, improves performance, and results in no or at least fewer deadlocks. While this is true, I have never seen a good visualization of it. First of all, it's important to understand that this configures where the continuation after the await gets executed. Intuitively, this would be preferable on the same context/thread as the initial task.
In most cases, it doesn't really matter for performance reasons which thread you continue on.
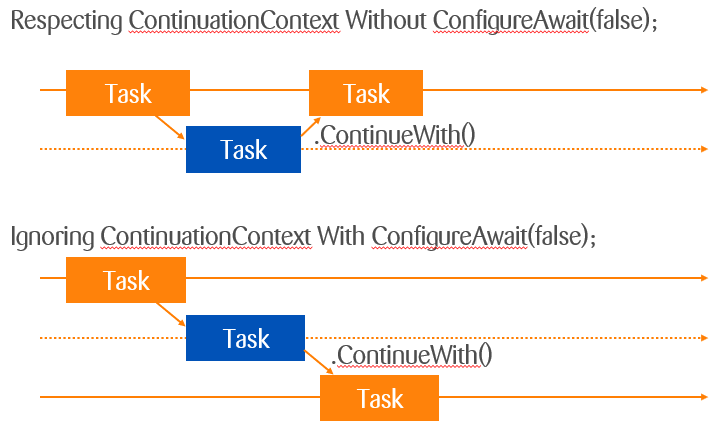
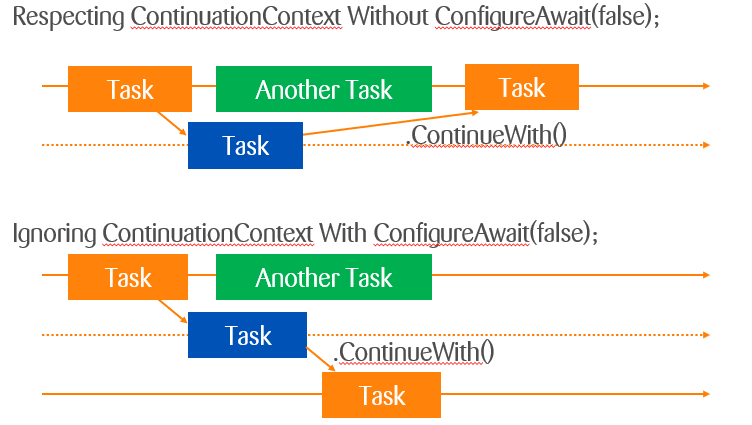
But if you have another task that occupies the thread for a long time, this becomes relevant:
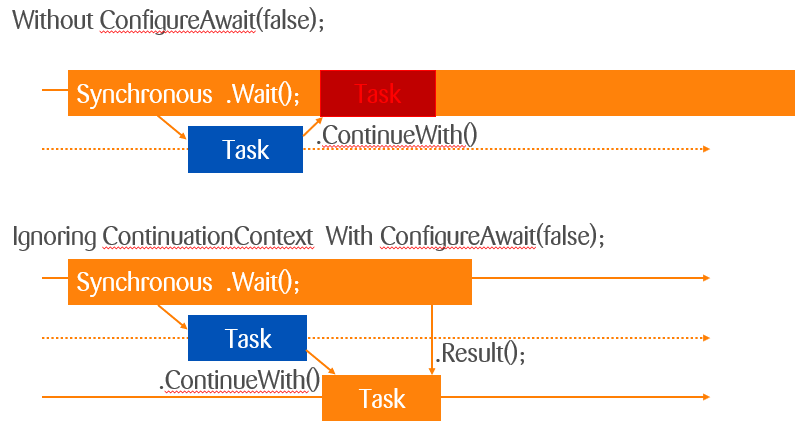
And that is why it deadlocks when you block synchronously, because you block the same thread by waiting on the continuation:
Debunking Async/Await Myths
Finally, let's try to clarify when a task gets split into continuations. This time, let's use Script to get everyone on board again. Many developers mistakenly believe that when you call a method with await, the method itself runs asynchronously. However, this is not the case. The await keyword doesn't make the called method execute asynchronously; instead, it pauses the execution of the surrounding function until the awaited promise is resolved or rejected.
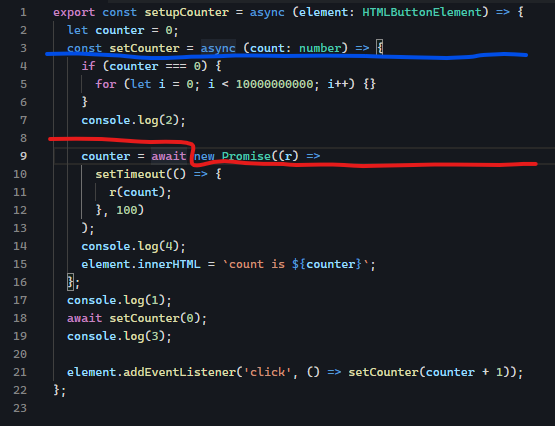
In other words, await doesn't wait for the start of the called task but for its completion. Everything in the code up to the first asynchronous operation—such as I/O, timers, or any other non-blocking task—runs synchronously. This means that if your code doesn't hit an asynchronous operation, it will execute entirely synchronously, potentially blocking the UI even though it was written using async/await. Let's look at an example:
export const setupCounter = async (element: HTMLButtonElement) => {
let counter = 0;
const setCounter = async (count: number) => {
if (counter === 0) {
for (let i = 0; i < 10000000000; i++) {}
}
console.log(2);
counter = await new Promise((r) =>
setTimeout(() => {
r(count);
}, 100)
);
console.log(4);
element.innerHTML = `count is ${counter}`;
};
console.log(1);
setCounter(0);
console.log(3);
element.addEventListener('click', () => setCounter(counter + 1));
};
I did leave out the await for setCounter(0). Many might argue that this should add the EventListener immediately. But this is not true; it executes synchronously until it hits the Promise, even if it would take several function calls down the call stack. If the Promise is only executed conditionally this will lead to codepaths that run completely synchronously. So the async boundary is at the red line, not the blue line:
This can be changed in C# to also introduce an async boundary by using configureAwait with ForceYielding.
If I add the await, this changes. But even this confused some people. There is a misconception that this could somehow lead to unblocking the UI. But this is not the case, and the sequence changes to 1, 2, 4, 3. This should not be surprising, but unfortunately, it is more often than I can believe. Put simply: adding await ALWAYS makes the code more blocking than without!
The Continuation Context Problem
We already discussed this in the C# section. But it is really important to understand the intricacies of Structured Concurrency and also to understand that this is not only a problem with multi threaded environments. The problem is that there are cases where you would like to keep context throughout the lifetime of a web request or any other asynchronous flow.
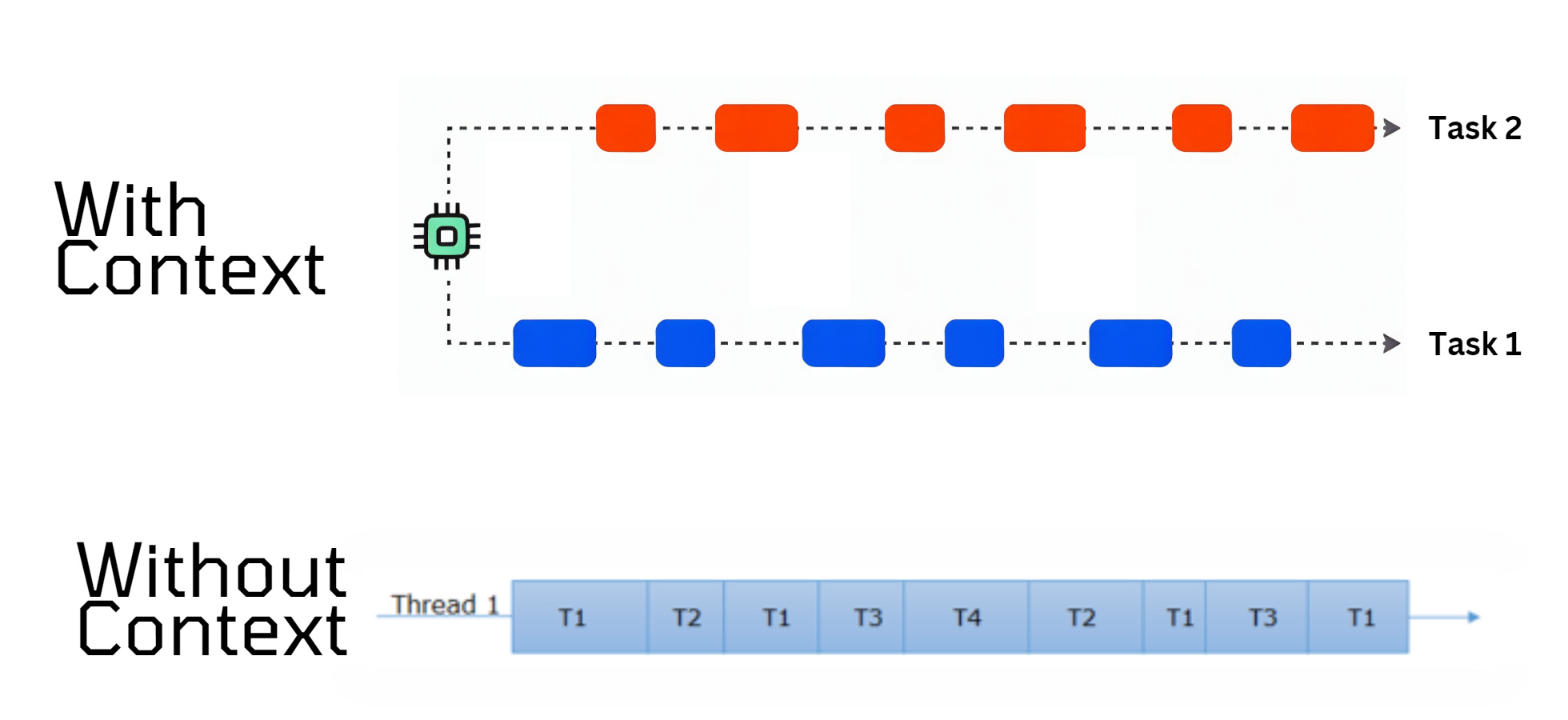
C# has multiple ways to solve it like Synchronization Contexts and increasingly popular also AsyncLocal. Angular solved this with Zone.js and recently Node.js has added Asynchronous context tracking that is used by Next.js to solve the same problem. So Structured Concurrency is not about how many threads or cpus are used but a lot more abstract just about execution contexts. If you care about the execution context/scope you probably benefit from Structured Concurrency. Otherwise you can handle the problem with Data-Parallelism or Async/Await with the mental model as if it was simple structured programming.
So I hope I could convince you that there are best Practices for all the quadrants:
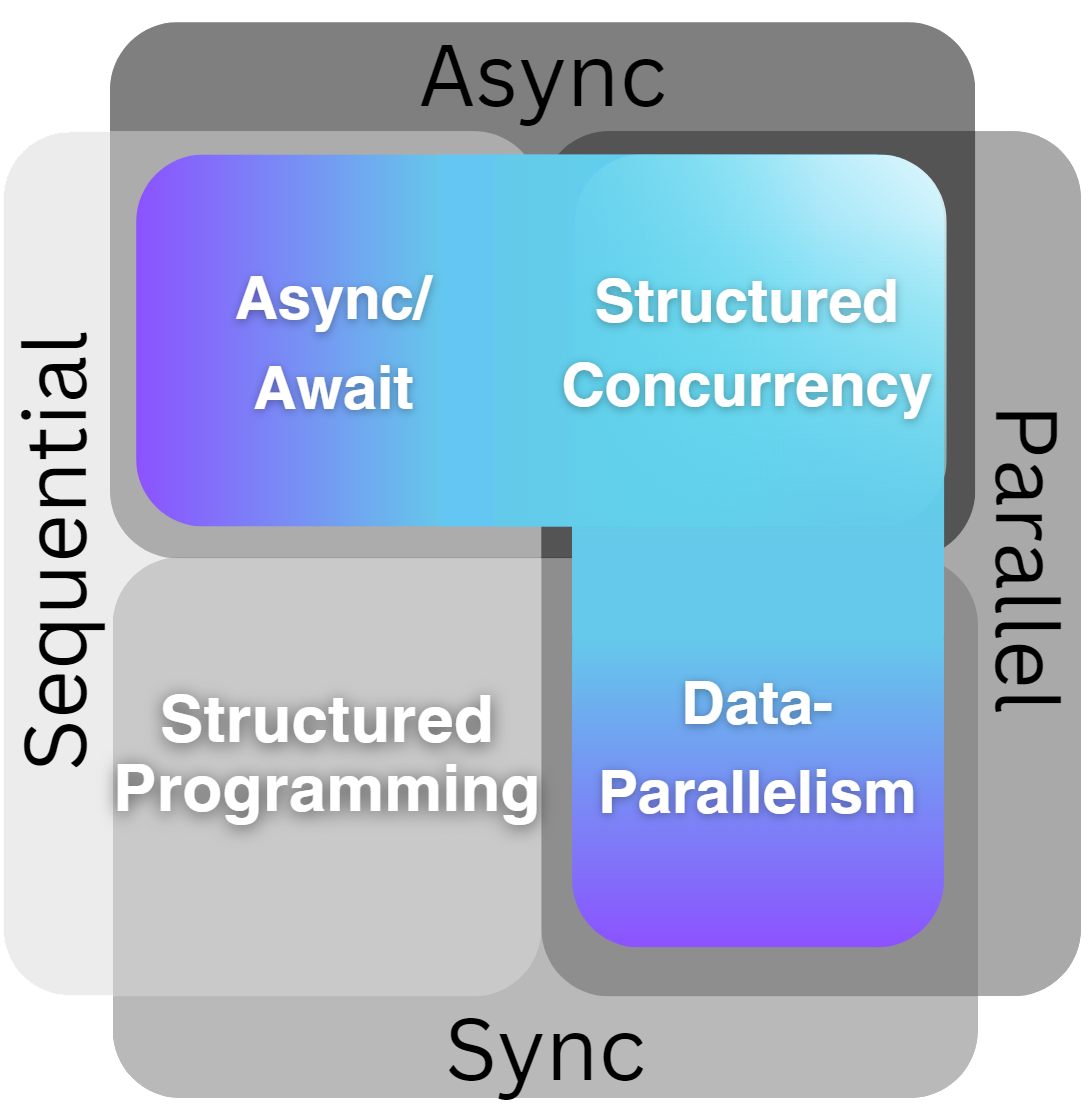
In most cases, it's beneficial when patterns converge, as it reduces misunderstandings and provides a shared, commonly accepted definition of terms. This clarity makes it easier to discuss important aspects and make informed decisions, including knowing what not to do. I want to emphasize that these approaches are not the only ways to handle concurrency—just as "goto" statements still exist and are used in modern languages like C#. This overview aims to highlight the current best practices in handling concurrency.
Keep in mind: concurrency should not be overused. If you constantly have to think about concurrency while writing or reading your code, you either have a very difficult problem and know exactly what you're doing, or you should reconsider your design. This article aims to help you understand where the benefits of these patterns are most significant. It does not mean they are the only correct solution in those cases!
Making trade offs well is one of the skills of being a programmer, and we should inform our community about that trade off, and then trust them to make the right call.
Subscribe to my newsletter
Read articles from Timon Jucker directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by