Semantic caching
 James Perkins
James PerkinsTable of contents

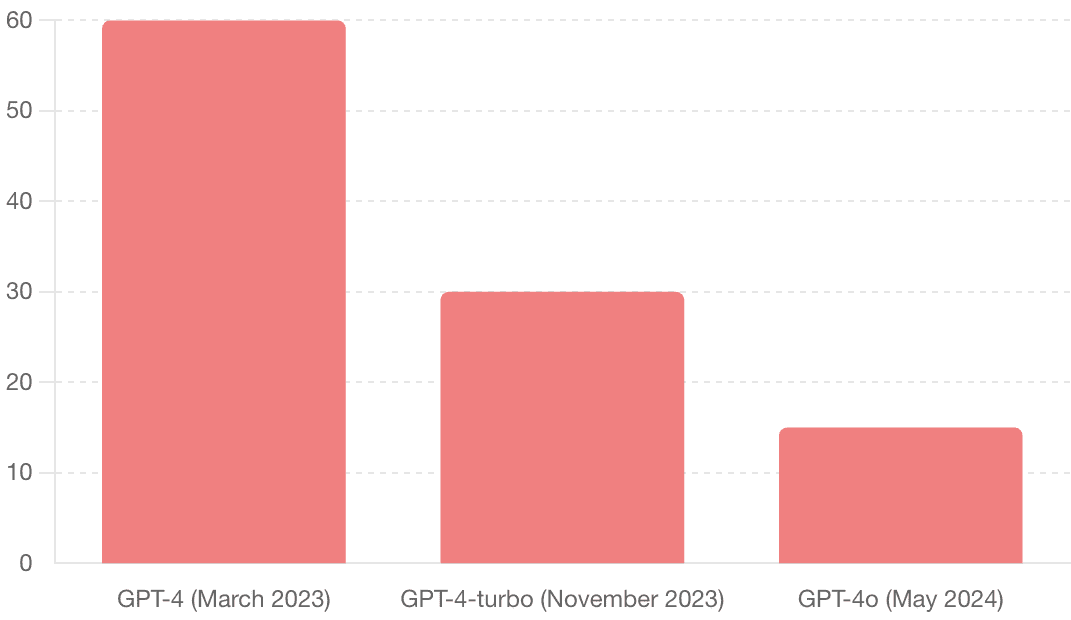
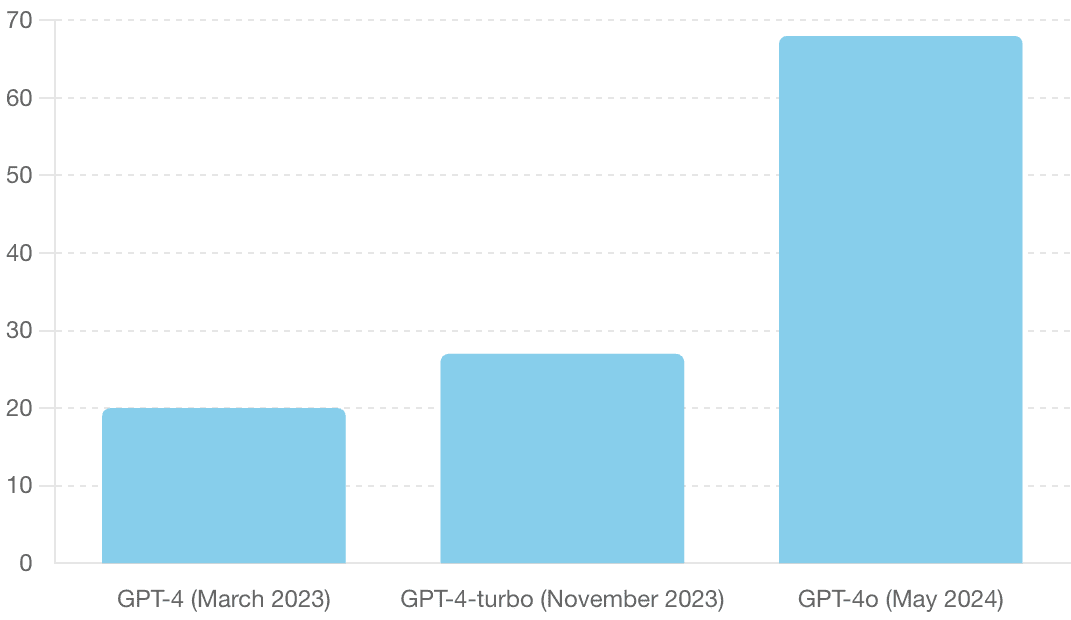
Large language models are getting faster and cheaper. The below charts show progress in OpenAI's GPT family of models over the past year:
Cost per million tokens ($)
Tokens per second
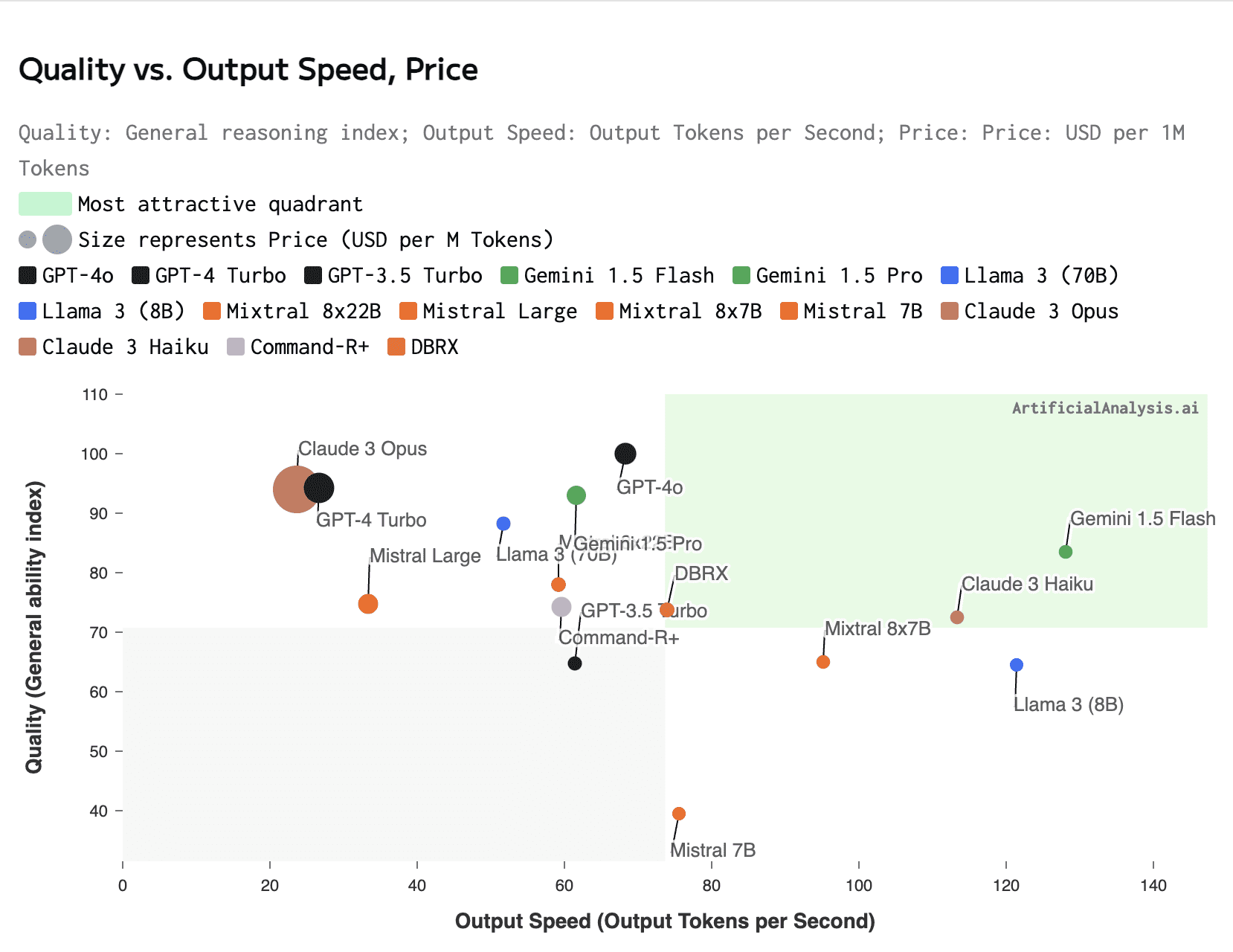
Recent releases like Meta's Llama 3 and Gemini Flash have pushed the cost / speed frontier further:
Below data is for May 2024
As cost and latency have decreased, more complex LLM workflows have become increasingly viable, which in turn bring their own set of challenges.
Since these workflows often involve multiple steps and retries, taking measures to reduce cost and latency remains helpful. One way to do so is via semantic caching.
Example use case: RAG
Say that you want to build a RAG (retrieval-augmented generation) chatbot for customer support. It can respond to user queries and suggest articles from your support center.
This workflow would involve multiple API calls:
Generate embedding of user query
Search vector DB for relevant embeddings and append to prompt
Query LLM API with enhanced prompt
Through caching, you could avoid doing this work except for when users ask questions that haven't been asked before - otherwise, re-use existing work.
Caching
A simple caching solution would be to cache results using the user query as the key, and the result of the workflow as the value.
This would enable re-use of responses between identical queries. But it would rely on user queries being phrased identically.
For instance, if two users asked "How do I cancel my subscription" then the second would be served the cached response. But if another user was to ask "I need to cancel my subscription - how?" then we'd see a cache miss. The question is the same in terms of its intent, but the phrasing is different.
This is how semantic caching can be useful: through caching based on the embedding of the query, we can ensure that all users who ask the same question receive a cache hit. The below diagrams give an overview of the architecture:
Try it now
In response to feedback from our AI customers, we're offering semantic caching now as part of Unkey. You can enable it now through signing up and changing the baseUrl parameter of the OpenAI SDK:
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: "https://<gateway>.llm.unkey.io", // change the baseUrl parameter to your gateway name
});
Unkey's semantic caching is free, supports streaming, and comes with built-in observability and analytics. In future we will offer deeper integration with Unkey's API keys for enhanced security and performance.
If you'd like to read more about how it works, check out our documentation.
Subscribe to my newsletter
Read articles from James Perkins directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by