Improve Application Speed with Strategic Data Denormalization
 Taiwo Ogunola
Taiwo Ogunola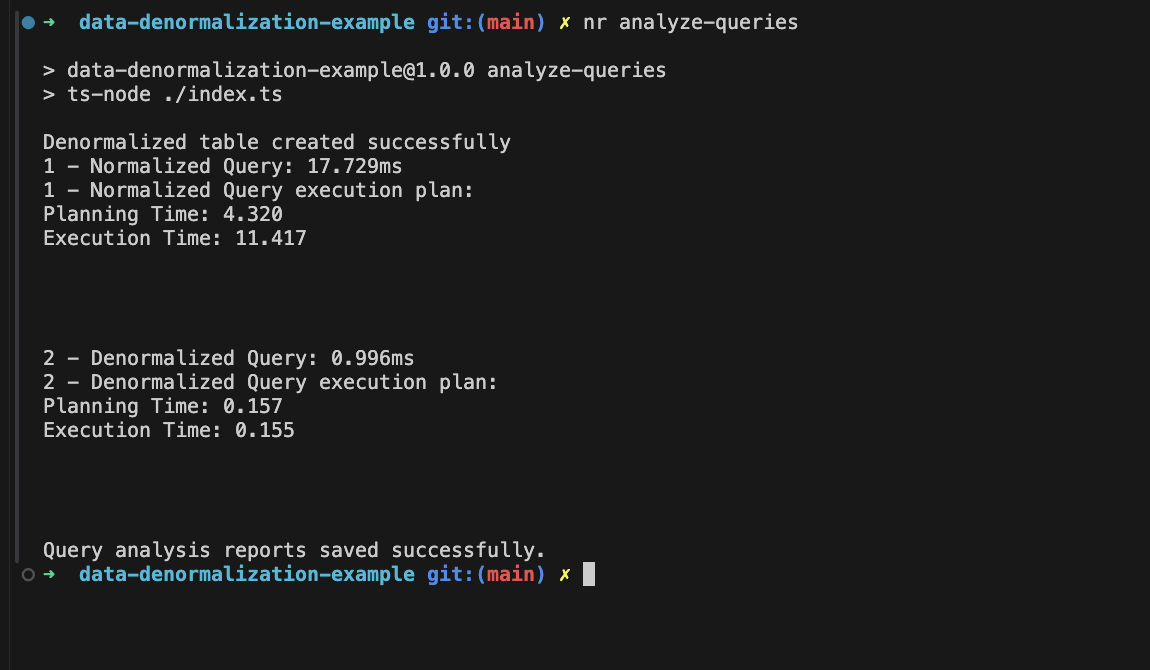
Database performance can become a significant issue as your application grows, often due to poor database design patterns. The key question is: how should you structure your database schema? The answer is not one-size-fits-all; it depends on various factors:
Does your application perform more read operations than write operations?
What data needs to be together when read from the database?
What performance considerations are there?
How large are the rows, and how large will they become?
How do you anticipate your data will grow and scale?
By asking these questions, you can design a database that offers better performance and scalability.
There are many techniques and database design patterns that can be considered when focusing on performance, but I am going to discuss data denormalization.
Data Normalization
SQL database is a type of relational database system that allows you to organize and manage data efficiently. By using a process called data normalization, you can reduce data duplication across your tables. This involves structuring your tables in a way that each piece of data is stored only once, which helps maintain data consistency throughout your database. Normalization typically involves dividing large tables into smaller, related tables and defining relationships between them. This approach not only minimizes redundancy but also ensures that updates to the data are reflected across the entire database, reducing the risk of inconsistencies. As a result, your database becomes more reliable and easier to maintain, especially as the volume of data grows over time.
Data Denormalization
Unlike normalization, data denormalization is the process of duplicating frequently-accessed data that are related in normalized database tables to improve read performance by reducing the need for complex joins, at the cost of increased data storage and potential data inconsistency during updates. Duplicating data provides the following benefits:
Better performance for read operations.
The ability to retrieve related data in a single database query.
In distributed systems, denormalized data can be more easily partitioned and distributed across multiple servers, improving scalability.
Denormalized data structures can make it easier to generate complex reports and perform analytics.
The ability to to update related data in a single atomic write operation in some cases.
Data denormalization creates redundant data to improve the performance of read operations at the expense of write operations. Sometimes this might be beneficial, and our app might tolerate this kind of data duplication. For instance, in our Order table, if some of the related data changes occasionally, we might want to keep the historical data for the ordering app.
In NoSQL databases, such as MongoDB, you have the flexibility to denormalize your data using various patterns, one of which is the Extended Reference Pattern. This pattern allows you to embed related data directly into a single document.Use cases for Data denormalization
You should consider consider denormalization if:
You have a high read-to-write ratio, as frequent data updates can add more overhead.
Your application can tolerate some temporary inconsistencies.
Data is frequently accessed together.
You need a unified view of customer data from multiple tables.
You need faster aggregations and calculations on large datasets, especially when complex queries on these datasets happen often.
By considering these factors, you can determine whether denormalization is suitable for your specific application needs, balancing the trade-offs between read performance and potential data redundancy.
Use case: Normalized Ecommerce Ordering DB
Relying only on the data normalization pattern can impact your query performance. For instance, if you need to display e-commerce orders with their related data, such as Customers, OrderItems, Products, Shipments, PaymentMethods, and Discounts tables, you would need to use multiple JOINs to combine the data.
SELECT
O.order_id,
O.order_date,
C.customer_name,
C.email,
P.product_name,
P.product_image_url,
OI.quantity,
OI.price_per_unit,
S.shipment_date,
S.tracking_number,
PM.payment_method,
PM.transaction_id,
D.discount_code,
D.discount_amount
FROM
Orders O
INNER JOIN Customers C ON O.customer_id = C.customer_id
INNER JOIN OrderItems OI ON O.order_id = OI.order_id
INNER JOIN Products P ON OI.product_id = P.product_id
INNER JOIN Shipments S ON O.order_id = S.order_id
INNER JOIN PaymentMethods PM ON O.payment_method_id = PM.payment_method_id
LEFT JOIN Discounts D ON O.discount_id = D.discount_id
WHERE
O.order_date >= '2023-01-01'
AND O.order_status = 'Completed'
ORDER BY
O.order_date DESC
Denormalizing our Ordering App
We can easily denormalized our Order Table by duplicating some of the needed related data like this:
CREATE TABLE Orders AS
SELECT
O.order_id, O.order_date, O.order_status,
C.customer_name, C.email,
P.product_name, P.product_image_url,
OI.quantity, OI.price_per_unit,
S.shipment_date, S.tracking_number,
PM.payment_method, PM.transaction_id,
D.discount_code, D.discount_amount
FROM
Orders O
INNER JOIN Customers C ON O.customer_id = C.customer_id
INNER JOIN OrderItems OI ON O.order_id = OI.order_id
INNER JOIN Products P ON OI.product_id = P.product_id
INNER JOIN Shipments S ON O.order_id = S.order_id
INNER JOIN PaymentMethods PM ON O.payment_method_id = PM.payment_method_id
LEFT JOIN Discounts D ON O.discount_id = D.discount_id
This would simply eliminate the need for adding multiple JOINs to our query:
SELECT * FROM Orders
WHERE order_date >= '2023-01-01' AND order_status = 'Completed'
ORDER BY order_date DESC
We can utilize the EXPLAIN ANALYZE profiling tool to conduct a detailed comparison of the queries before and after denormalization. This tool provides an in-depth analysis of how the database executes a query, revealing the execution plan and highlighting where the database spends time processing your query. By examining this information, you can gain insights into the efficiency of your queries, identify potential bottlenecks, and understand the reasons behind any performance issues. This analysis can be invaluable in optimizing your database operations and ensuring that your application runs smoothly and efficiently.
const queries = [
{
name: '1 - Normalized Query',
sql: `
EXPLAIN ANALYZE
SELECT
O.order_id, O.order_date,
C.name AS customer_name, C.email,
P.name AS product_name, OI.quantity, OI.price,
S.shipment_date, S.tracking_number,
PM.name AS payment_method,
D.code AS discount_code, D.amount AS discount_amount
FROM
Orders O
INNER JOIN Customers C ON O.customer_id = C.customer_id
INNER JOIN OrderItems OI ON O.order_id = OI.order_id
INNER JOIN Products P ON OI.product_id = P.product_id
INNER JOIN Shipments S ON O.order_id = S.order_id
INNER JOIN PaymentMethods PM ON O.payment_method_id = PM.payment_method_id
LEFT JOIN Discounts D ON O.discount_id = D.discount_id
LIMIT 1000
`,
},
{
name: '2 - Denormalized Query',
sql: `
EXPLAIN ANALYZE
SELECT *
FROM DenormalizedOrders
LIMIT 1000
`,
},
];
try {
for (const query of queries) {
console.time(query.name);
const result = await client.query(query.sql);
console.timeEnd(query.name);
console.log(`${query.name} execution plan:`);
result.rows.forEach((row) => console.log(row['QUERY PLAN']));
console.log('\n');
console.log('\n');
}
console.log('Query analysis reports saved successfully.');
} catch (e) {
throw e;
} finally {
client.release();
}
};
In the code above, I have used the Node.js pg library. You can find all the code in this repository. In the repository, I created some dummy data in seed.ts with faker-js.
You can start the project by running the following scripts:
Spin up a postgres docker image:
$ docker compose up -d
Install project dependencies:
$ npm i
Seed your database with some data:
$ npm run seed
Then, you can run the analysis script to compare both normalized and denormalized queries:
$ npm run analyze-queries
Here’s an example of the a result, you can see the:

In the result, the denormalized query is much faster due to simpler execution (sequential scan on one table), while the normalized query involves multiple nested joins, leading to higher costs and slower execution.
You can find the list of reports in the docs/reports.json file, which includes all of my test results. Many of them vary because of my environment and Postgres’ internal caching techniques.
Wrap Up
Strategic data denormalization can significantly enhance application speed by optimizing read performance. While normalization is essential for maintaining data consistency and reducing redundancy, denormalization offers a practical solution for applications with high read-to-write ratios and complex queries.
By carefully evaluating the specific needs of your application, such as the frequency of data access and the tolerance for temporary inconsistencies, you can effectively balance the trade-offs between read performance and potential data redundancy. Implementing denormalization thoughtfully can lead to improved scalability, faster data retrieval, and more efficient database operations, ultimately contributing to a smoother and more responsive user experience.
You can find all the code in this repository! Can't wait to see you in my next article! 🙂
Subscribe to my newsletter
Read articles from Taiwo Ogunola directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Taiwo Ogunola
Taiwo Ogunola
With over 5 years of experience in delivering technical solutions, I specialize in web page performance, scalability, and developer experience. My passion lies in crafting elegant solutions to complex problems, leveraging a diverse expertise in web technologies.