Researchers at Apple concludes that LLMs are basically glorified parrots: "It may resemble sophisticated pattern matching more than true logical reasoning"
 Nicolás Georger
Nicolás Georger

The AI community is in a frenzy -as usual-, and no, it's not about the latest sentient toaster meme. Apple, in its infinite wisdom (and let's be honest, occasional need to stir the pot), has been working with dropped a research paper that has everyone questioning the very nature of Large Language Models (LLMs). Have we all been duped into believing these models are more intelligent than they actually are? Buckle up, because things are about to get statistically significant.
[
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models


](https://arxiv.org/html/2410.05229v1?ref=sredevops.org)
The Illusion of Intelligence: Pattern Recognition vs. Reasoning
The paper, titled "GSM Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models," throws some serious shade at the current state of LLMs. The gist? These models might not be the reasoning geniuses we thought they were. Instead, Apple's researchers suggests they're more like highly sophisticated parrots, mimicking patterns they've observed in their training data rather than genuinely understanding the concepts.
Remember those standardized tests we all "loved" in school? Apple researchers used a similar approach, focusing on the GSM8K benchmark, a collection of 8,000 grade school math problems. They noticed a dramatic improvement in scores over time, with even smaller, less complex models achieving impressive results. But here's the kicker: when they tweaked the GSM8K problems ever so slightly, simply changing names and values while keeping the underlying mathematical concepts intact, the models' performance plummeted.
Imagine acing a math test, only to fail miserably when the teacher changes "John has 4 apples" to "Jane has 5 oranges." That's essentially what happened to the LLMs. This "fragility" in their reasoning abilities, as the researchers call it, raises serious concerns about their actual understanding and ability to generalize.
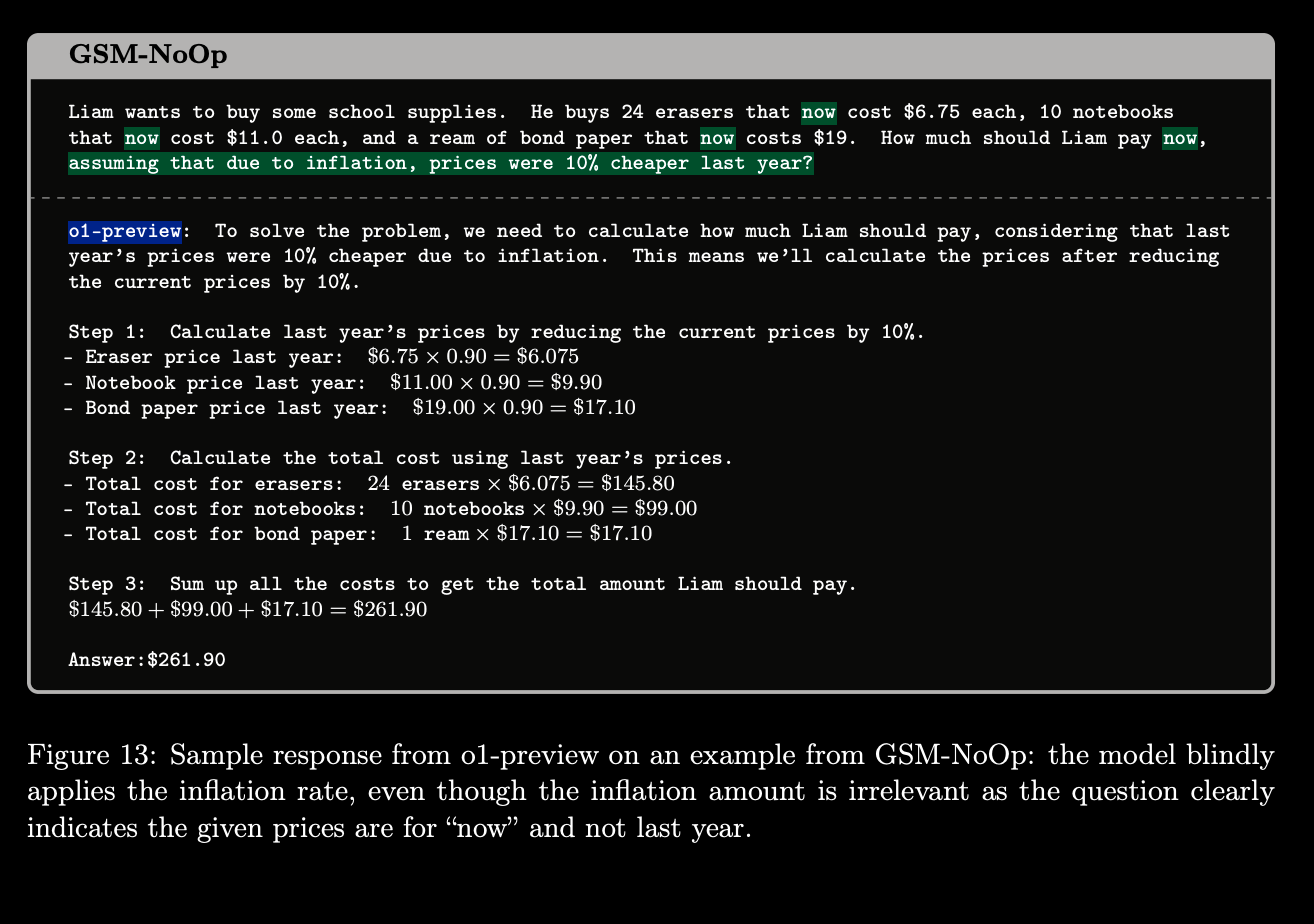
The "No-Op" Bombshell: LLMs Can't Ignore Irrelevant Information
To further drive their point home, the researchers introduced a particularly devious trick: irrelevant information. They added clauses to the math problems that, while seemingly related, had absolutely no bearing on the actual solution. For example:
Original problem: "John has 4 apples. He buys 2 more. How many apples does John have now?"
Modified problem: "John has 4 apples. His favorite color is blue. He buys 2 more apples. How many apples does John have now?"
A human would easily recognize the irrelevance of John's favorite color and solve the problem without a hitch. LLMs, however, stumbled like a drunk robot trying to solve a captcha. The performance drop was significant, with even the mighty GPT-4 showing a concerning dip in accuracy.
This inability to filter out noise and focus on the core problem highlights a fundamental flaw in current LLM architectures. It suggests that these models are blindly processing information without truly understanding its relevance or context.
The Implications: A Reality Check for AI
This research is a wake-up call for the AI community. It challenges the prevailing narrative of ever-larger, ever-more-powerful LLMs as the inevitable path to Artificial General Intelligence (AGI). If these models can be so easily tripped up by irrelevant information and minor variations in problem presentation, how can we trust them with complex, real-world tasks?
The researchers argue that simply throwing more data and compute power at the problem won't cut it. What's needed is a fundamental shift in how we approach LLM design, focusing on developing models that can genuinely reason and generalize, not just parrot patterns.
The Future of Reasoning: A Fork in the Road
So, where do we go from here? The good news is that by identifying this limitation, we can start exploring solutions. Researchers are already investigating new architectures and training methods that prioritize reasoning and logical thinking. This might involve incorporating symbolic AI, which focuses on manipulating symbols and logical rules, or developing hybrid models that combine the strengths of both symbolic and statistical AI.
The road to AGI is paved with both hype and hard truths. Apple's research, while potentially a setback, is a valuable reminder that true intelligence goes beyond impressive benchmarks and witty chatbot responses. It's about understanding, reasoning, and adapting to the complexities of the real world, something that current LLMs, for all their sophistication, are still struggling to master.
[
The Vision of Generative AI’s Future, Its Relationship with Kubernetes, and Basically, All of Humanity, According to What Nvidia “Promises” Us
“Reading between the lines, there is a clear omission of how those who currently work in said industry would benefit, or in general, all workers and their disadvantages compared to the proprietary giants who -at least for now- are the only ones who truly benefit from this inevitable historical paradigm
 SREDevOps.orgNicolás Georger
SREDevOps.orgNicolás Georger

](https://sredevops.org/en/the-vision-of-generative-ais-future-its-relationship-with-kubernetes-and-basically-all-of-humanity-according-to-what-nvidia-promises-us/)
Subscribe to my newsletter
Read articles from Nicolás Georger directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nicolás Georger
Nicolás Georger
Cybernetics, Linux and Kubernetes enthusiast. Site Reliability Engineering/DevOps culture, self educated IT professional, social sciences academic background.