Automated Lambda Deployment Using Terraform, Jenkins, and S3 Backup Solutions
 Nishank Koul
Nishank KoulTable of contents
- Building Terraform Configurations for AWS Lambda Deployment
- Creating a GitHub Repository for Code Storage and Setting Up an S3 Bucket
- Packaging and Deploying AWS Lambda Function Code: Preparing ZIP Files for Deployment
- Creating Jenkinsfile for Continuous Integration
- Creating and Installing Jenkins on an EC2 Instance
- Installing Essential Plugins and Managing Secret Credentials in the Credentials Manager
- Creating a Jenkins Pipeline Job for Automated Deployment
- Build the Pipeline Job
- Storing Statefile along with its backup inside the S3 Bucket
- Enable Versioning for the Lambda Function Code
- Storing the Backup Code Inside The Bucket
- Conclusion

This blog aims at automating the deployment of AWS Lambda using Terraform and Jenkins has streamlined the entire process, from provisioning the Lambda function to managing backups of the Terraform state file and Lambda code versions in an S3 bucket. With Terraform handling the infrastructure and Jenkins orchestrating the deployment, updates to the Lambda function are now automated and seamless. Each deployment triggers a backup of the previous Lambda version in S3, ensuring reliable version control and the ability to roll back if needed.
Building Terraform Configurations for AWS Lambda Deployment
Create the provider.tf file to specify the required AWS provider for the Terraform configuration. The file includes the following code, which sets the AWS provider and region:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
Next, create the main.tf file to define the AWS Lambda function and its associated resources. The aws_lambda_function resource sets parameters such as the function name, runtime (Node.js 18.x), environment variables, and the IAM role. A function URL is also included for easier access. The aws_iam_role provides Lambda with the necessary execution permissions; a basic execution policy is attached using the aws_iam_role_policy_attachment resource. The function URL is outputted at the end of the configuration for quick reference.
resource "aws_lambda_function" "hello_world" {
filename = "lambda_function.zip"
function_name = var.lambda_function_name
role = aws_iam_role.lambda_role.arn
handler = "index.handler"
source_code_hash = filebase64sha256("lambda_function.zip")
runtime = "nodejs18.x"
environment {
variables = {
VERSION = var.function_version
}
}
}
resource "aws_iam_role" "lambda_role" {
name = "hello_world_lambda_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "lambda_policy" {
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
role = aws_iam_role.lambda_role.name
}
resource "aws_lambda_function_url" "hello_world_url" {
function_name = aws_lambda_function.hello_world.function_name
authorization_type = "NONE"
}
output "function_url" {
value = aws_lambda_function_url.hello_world_url.function_url
}
The vars.tf file was created to define variables for the AWS region, Lambda function name, and function version. These variables enhance flexibility and make the deployment process easier to configure. Here's the code:
variable "aws_region" {
description = "AWS region for resources"
default = "Enter the region name here"
}
variable "lambda_function_name" {
description = "Name of the Lambda function"
default = "hello_world_function"
}
variable "function_version" {
description = "Version of the Lambda function"
default = "1.0.0"
}
Lastly, the backend.tf file was created to configure Terraform state management. It leverages an S3 bucket to store the Terraform state file, ensuring persistence and facilitating state sharing across multiple environments. Here's the code:
terraform {
backend "s3" {
bucket = "Enter your bucket name here"
key = "terraform.tfstate"
region = var.aws_region
}
}
Creating a GitHub Repository for Code Storage and Setting Up an S3 Bucket
To effectively manage code storage and backups, a GitHub repository was created specifically for the Terraform configuration files, which include provider.tf, main.tf, vars.tf, and backend.tf. This repository facilitates version control and enhances collaboration on the Terraform code, making it easier for teams to work together.
In addition to the GitHub setup, an S3 bucket was established to manage the Terraform state file and back up previous versions of the Lambda function code. The use of this S3 bucket ensures that the state file is stored securely and remains accessible to Terraform across various deployments. Moreover, it provides a robust mechanism for version control and backup, safeguarding the Lambda function code for future reference.
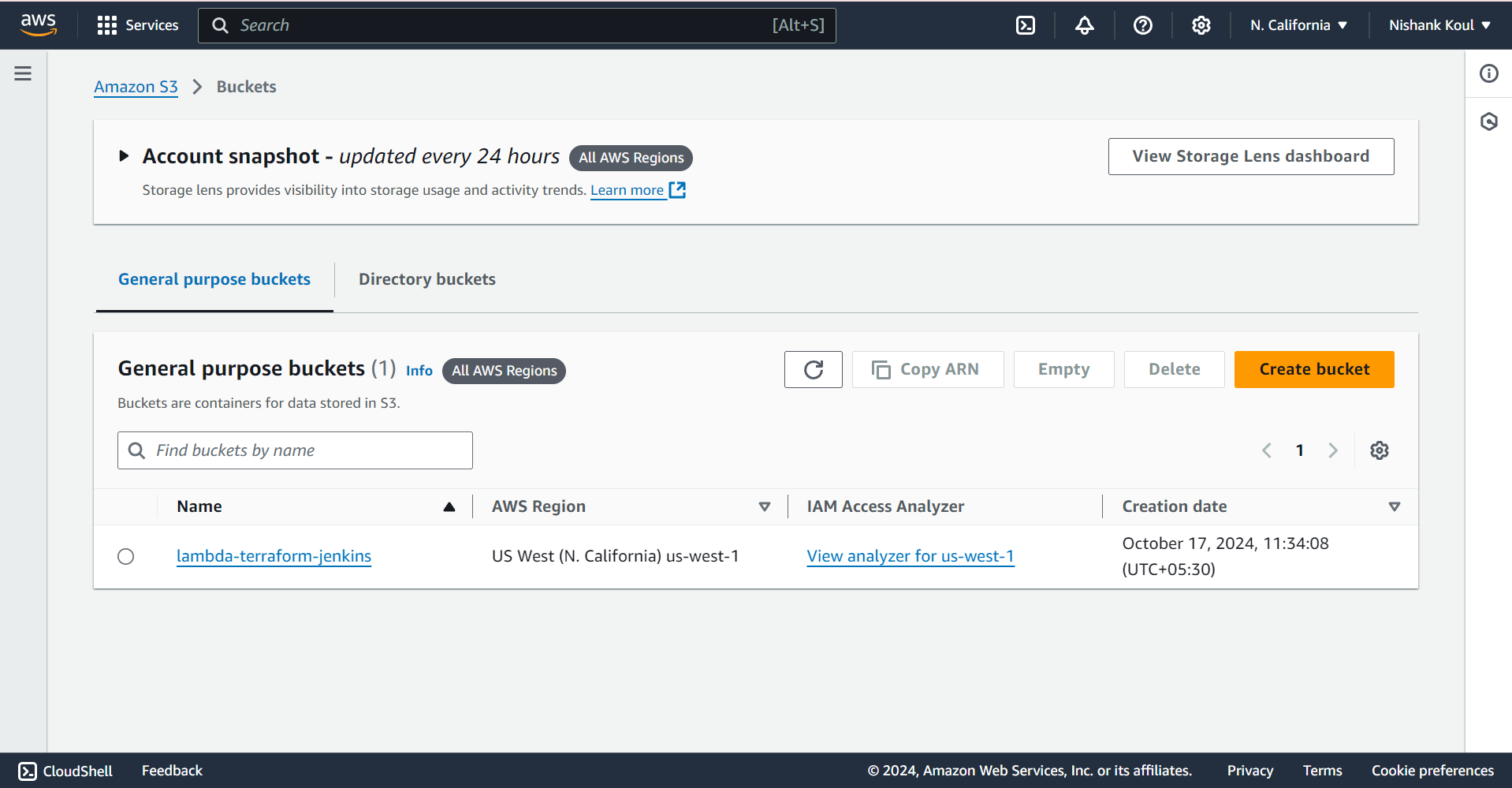
Packaging and Deploying AWS Lambda Function Code: Preparing ZIP Files for Deployment
To deploy the AWS Lambda function, the first step was to create the function code in Node.js. This code implements the core functionality of the Lambda, designed to respond to events with a simple "Hello World" message. After writing the code, it was packaged into a ZIP file named lambda_function.zip. This packaging step is crucial since AWS Lambda requires the function code to be uploaded as a ZIP file, which must include all necessary dependencies and the entry point for the function.
Packaging the Lambda function code into a ZIP file serves several important purposes. It ensures that all code dependencies are included, making the deployment to AWS Lambda straightforward and reliable. This method also allows for easy version management of the function code, simplifying the process of rolling back to previous versions if necessary. By maintaining a clean and organized deployment pipeline, this approach minimizes potential errors and ensures smooth updates and deployments.
Here’s the code for reference:
exports.handler = async (event) => {
const response = {
statusCode: 200,
body: JSON.stringify('Hello World!'),
};
return response;
};
Creating Jenkinsfile for Continuous Integration
A Jenkinsfile was created to automate the deployment of the AWS Lambda function, utilizing a series of stages to manage the entire deployment process seamlessly. The pipeline kicks off by retrieving the current Lambda function version from an S3 bucket, defaulting to version 1.0 if no version file is found. This initial step ensures that the deployment starts with the correct version.
Next, the pipeline initializes Terraform with the appropriate backend configuration to store the state file in S3, ensuring proper state management. For added security and version control, the state file is also backed up to S3.
Once Terraform is initialized, the pipeline generates a deployment plan and applies it to either deploy a new Lambda function or update an existing one. It then checks S3 for a previous version of the Lambda code. If a previous version exists, the pipeline updates the existing object; if not, it uploads the new Lambda code. The version and timestamp are then updated and saved back to S3.
Finally, the pipeline outputs the Lambda function URL, providing easy access to the deployed function. This Jenkinsfile not only streamlines the deployment process but also automates version control and ensures robust state and code management, making it an essential component of the deployment workflow.
pipeline {
agent any
environment {
AWS_ACCESS_KEY_ID = credentials('AWS_ACCESS_KEY_ID')
AWS_SECRET_ACCESS_KEY = credentials('AWS_SECRET_ACCESS_KEY')
FUNCTION_VERSION_FILE = 'version.txt'
S3_BUCKET = credentials('S3_BUCKET')
LAMBDA_CODE_KEY = 'lambda_function_code'
AWS_REGION = 'Enter the AWS region here'
STATE_BACKUP_KEY = 'terraform-backend.tfstate'
}
stages {
stage('Retrieve Version') {
steps {
script {
// Retrieve the version from S3
def result = sh(script: "aws s3 cp s3://${S3_BUCKET}/${FUNCTION_VERSION_FILE} version.txt --region ${AWS_REGION}", returnStatus: true)
if (result == 0) {
// Read the version from file
env.FUNCTION_VERSION = readFile('version.txt').split('\\|')[0].trim()
} else {
// Set default version if file does not exist
env.FUNCTION_VERSION = '1.0'
}
}
}
}
stage('Terraform Init') {
steps {
script {
// Initialize Terraform and store both state and backend in S3
sh '''
terraform init -upgrade \
-reconfigure \
-backend-config="bucket=${S3_BUCKET}" \
-backend-config="key=terraform.tfstate" \
-backend-config="region=${AWS_REGION}" \
-force-copy
'''
// Backup the state backend file in S3
sh '''
aws s3 cp .terraform/terraform.tfstate s3://${S3_BUCKET}/${STATE_BACKUP_KEY} --region ${AWS_REGION}
'''
}
}
}
stage('Terraform Plan') {
steps {
sh 'terraform plan -var="function_version=${FUNCTION_VERSION}" -out=tfplan'
}
}
stage('Terraform Apply') {
steps {
sh 'terraform apply -auto-approve tfplan'
}
}
stage('Backup and Update Lambda Code') {
steps {
script {
def currentVersion = env.FUNCTION_VERSION
def result = sh(script: "aws s3 ls s3://${S3_BUCKET}/${LAMBDA_CODE_KEY}.zip", returnStatus: true)
if (result == 0) {
echo "Updating existing object for version ${currentVersion}"
def newVersion = (currentVersion.toFloat() + 0.1).toString()
def timestamp = sh(script: "date +'%Y-%m-%d %H:%M:%S'", returnStdout: true).trim()
sh "aws s3 cp lambda_function.zip s3://${S3_BUCKET}/${LAMBDA_CODE_KEY}.zip"
// Store version and timestamp in version.txt
writeFile(file: 'version.txt', text: "${newVersion} | ${timestamp}")
sh "aws s3 cp version.txt s3://${S3_BUCKET}/${FUNCTION_VERSION_FILE} --region ${AWS_REGION}"
} else {
echo "Uploading new object for version ${currentVersion}"
def newVersion = (currentVersion.toFloat() + 0.1).toString()
def timestamp = sh(script: "date +'%Y-%m-%d %H:%M:%S'", returnStdout: true).trim()
sh "aws s3 cp lambda_function.zip s3://${S3_BUCKET}/${LAMBDA_CODE_KEY}.zip"
// Store version and timestamp in version.txt
writeFile(file: 'version.txt', text: "${newVersion} | ${timestamp}")
sh "aws s3 cp version.txt s3://${S3_BUCKET}/${FUNCTION_VERSION_FILE} --region ${AWS_REGION}"
}
}
}
}
stage('Output Function URL') {
steps {
sh 'echo "Function URL: $(terraform output -raw function_url)"'
}
}
}
}
Creating and Installing Jenkins on an EC2 Instance
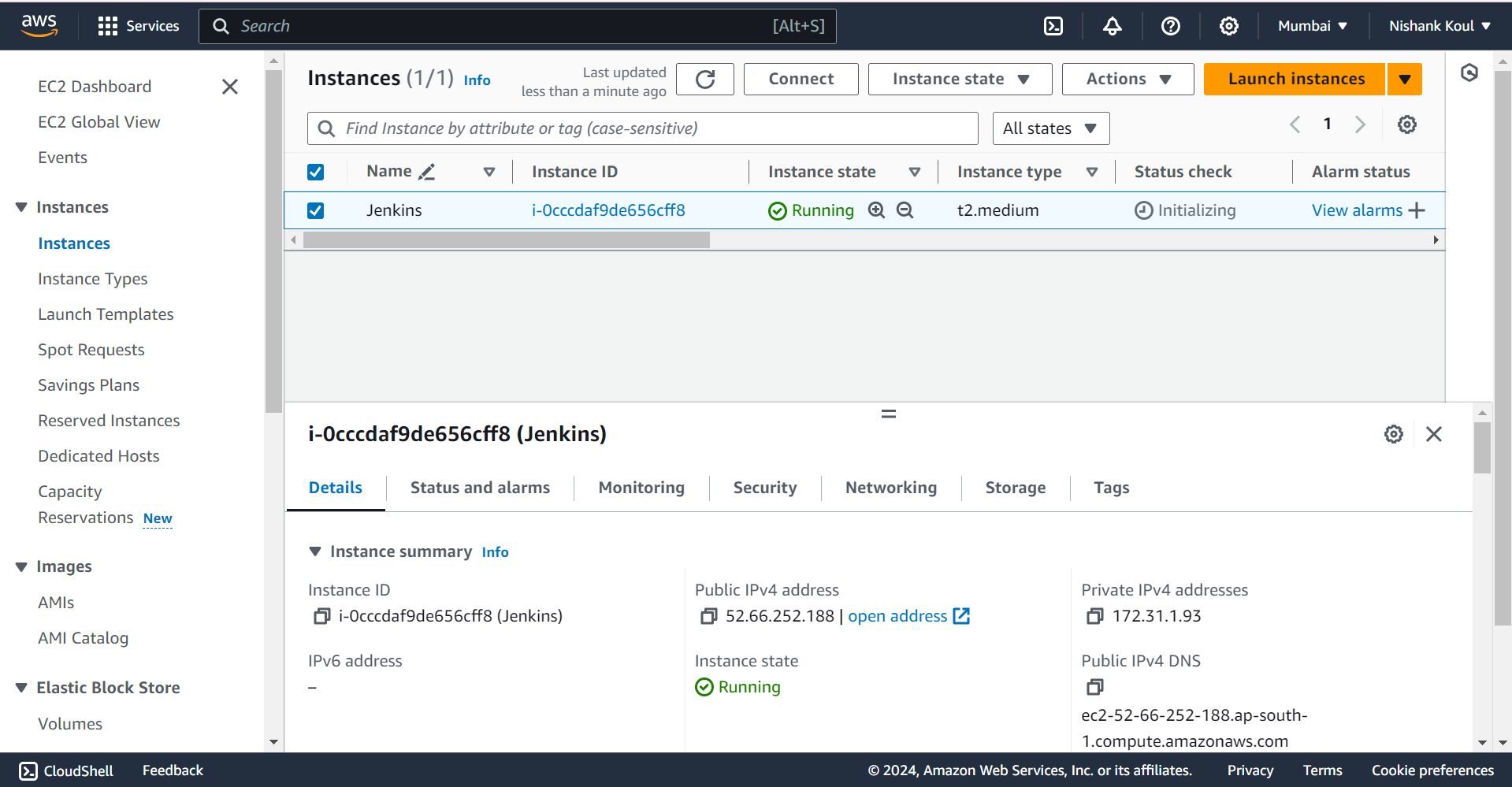
To create a robust CI/CD environment, Jenkins was set up on an Ubuntu EC2 instance (t2.medium instance type). After launching the EC2 instance and ensuring it was configured with the necessary security group rules, the installation of Jenkins began. This involved updating the package lists, adding the Jenkins repository, and installing the Jenkins package. Jenkins was configured to run on port 8080, its default port, and set to start automatically upon system boot.
For the initial setup, Jenkins was accessed through its web interface using port 8080. The admin password was retrieved from the instance's file system, a crucial step for accessing the Jenkins setup wizard for the first time. During this setup process, the suggested plugins were installed to enhance Jenkins's capabilities, and basic security settings were configured, including the creation of an administrative user.
This installation process established a fully functional Jenkins server, ready to efficiently manage automated deployments and continuous integration tasks, paving the way for streamlined development workflows.
Installing Essential Plugins and Managing Secret Credentials in the Credentials Manager
During the Jenkins setup process, several suggested plugins were installed to enhance its functionality. These included Git for seamless version control integration, Pipeline for building and managing complex build workflows, and AWS Steps for direct integration with AWS services from within Jenkins. These plugins offer essential capabilities that streamline automation for builds, facilitate deployment management, and enable efficient integration with both version control systems and cloud services, significantly improving the overall CI/CD workflow.
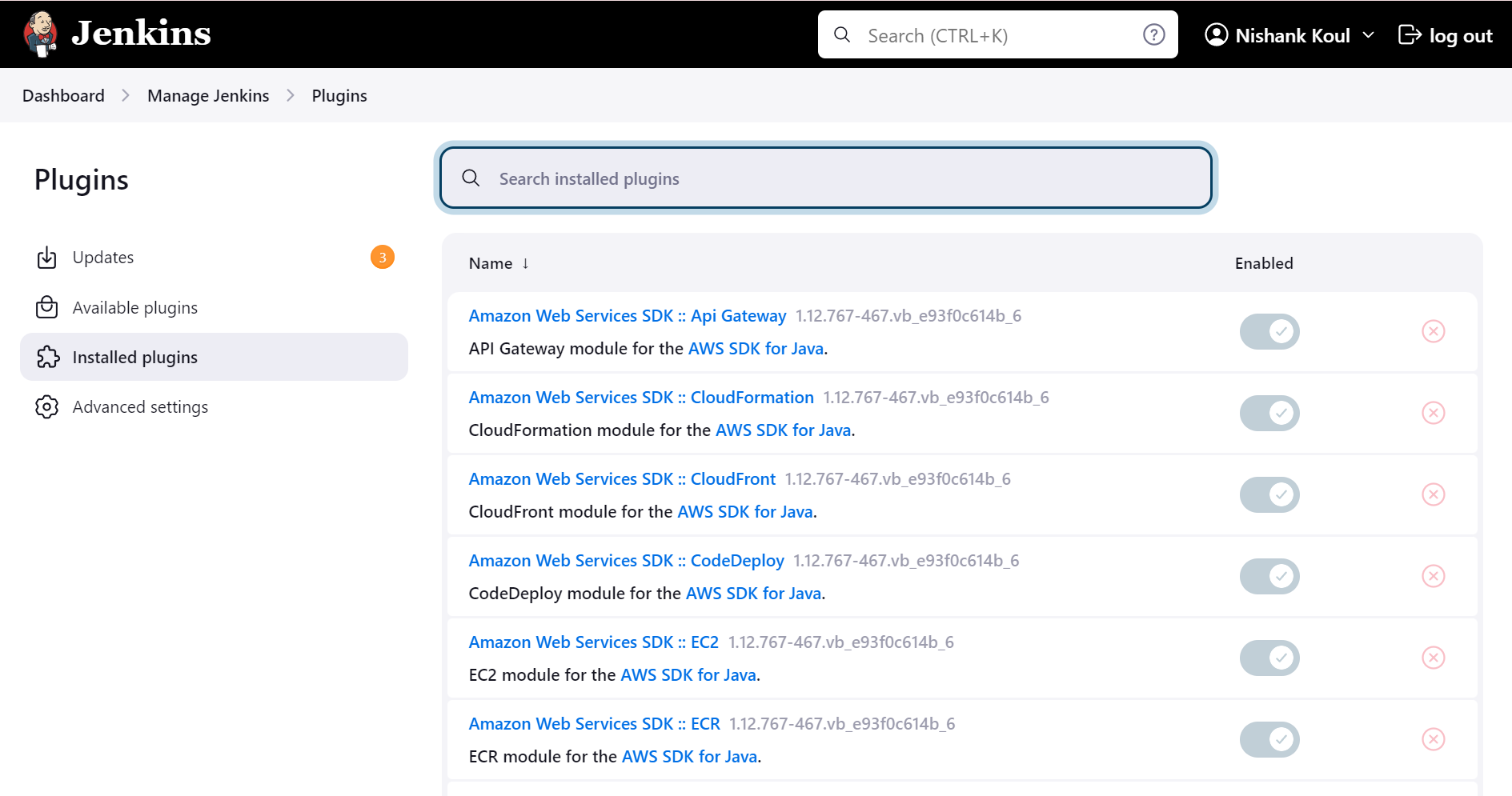
To securely manage credentials, the AWS access keys and S3 bucket name were stored in Jenkins's credentials manager. This approach guarantees that sensitive information, like AWS credentials, remains secure and separate from the pipeline scripts. By configuring these credentials within Jenkins, they can be referenced in the pipeline without exposing them directly in the code. This not only enhances security but also simplifies the management of deployment tasks, allowing for a streamlined workflow while protecting critical information.
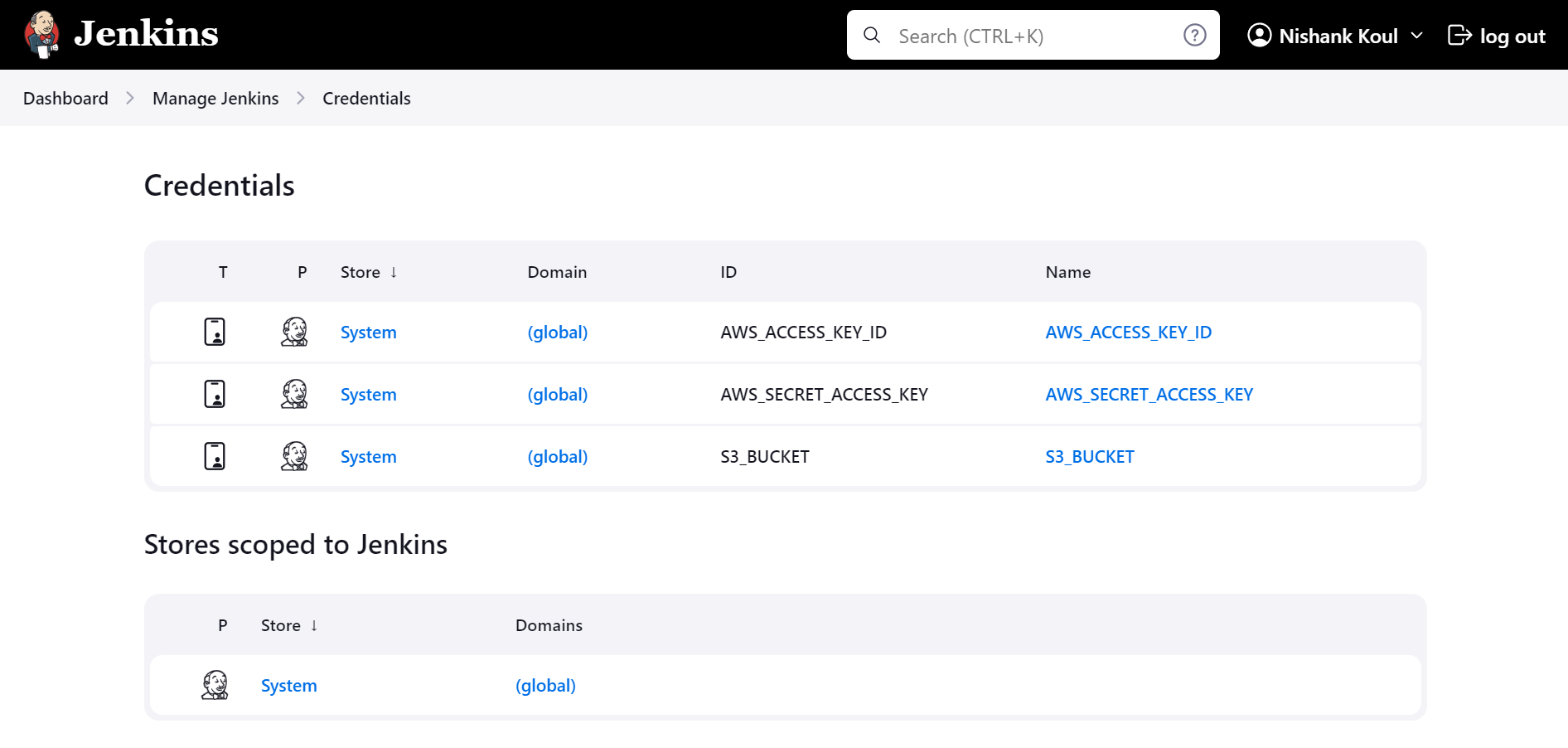
Creating a Jenkins Pipeline Job for Automated Deployment
A Jenkins pipeline was created to automate the deployment of the AWS Lambda function. This pipeline job was configured to utilize a Jenkinsfile that outlines the essential stages and steps for the deployment process, including Terraform initialization, planning, applying, and managing the Lambda code.
The Jenkins pipeline job was set up to use a pipeline script sourced from SCM (Source Code Management). Git was selected as the SCM, and the repository URL https://github.com/nishankkoul/Terraform-Serverless.git was provided. The Jenkinsfile, which contains the pipeline definitions, is located at the Jenkinsfile path within the repository. This configuration ensures that the pipeline job automatically pulls the latest version of the Jenkinsfile directly from the Git repository, facilitating continuous integration and automated deployment with the most up-to-date pipeline script. By leveraging SCM for the pipeline script, a centralized and version-controlled approach to managing Jenkins pipeline configurations is maintained, enhancing the overall efficiency of the deployment process.
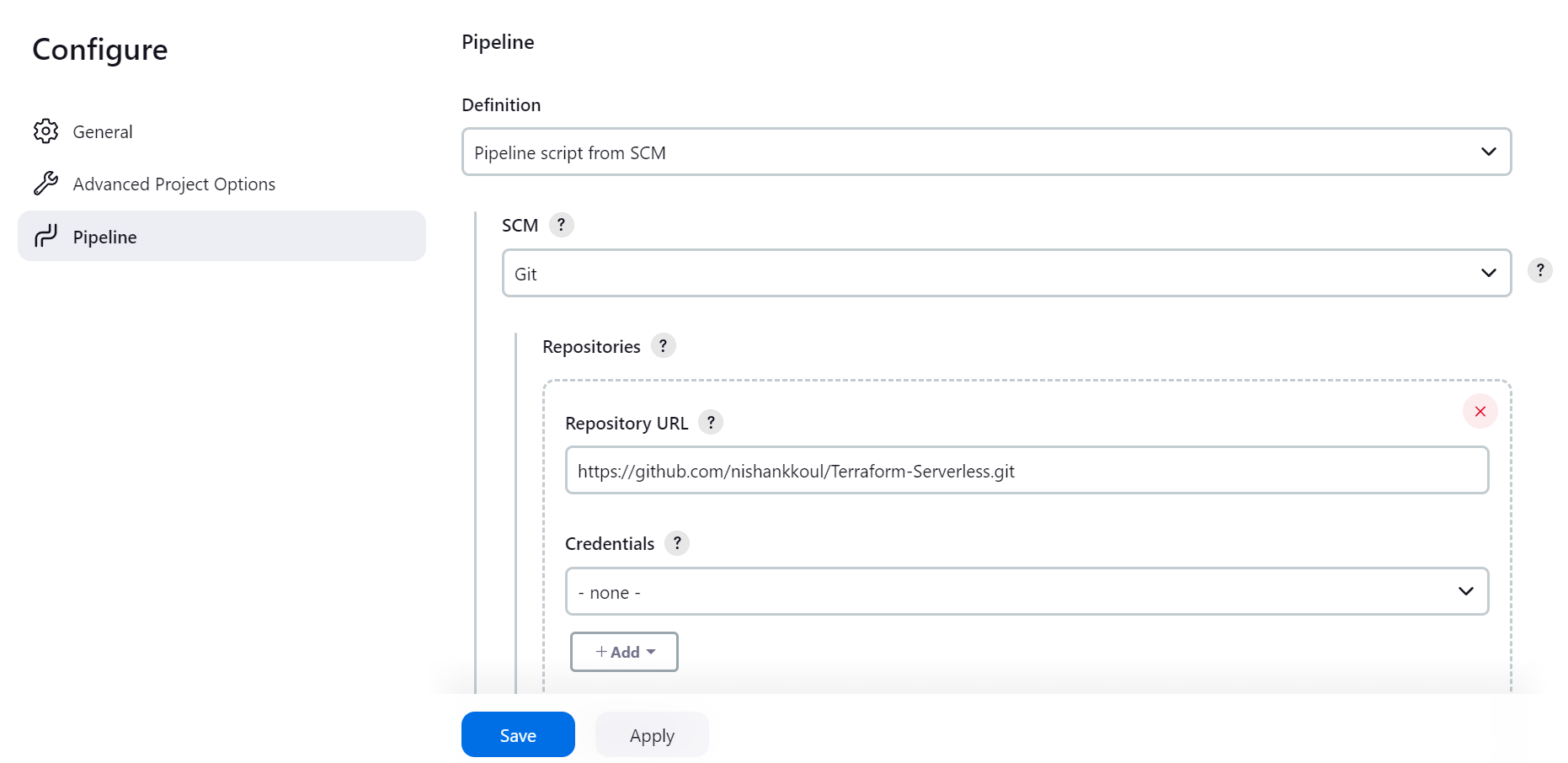
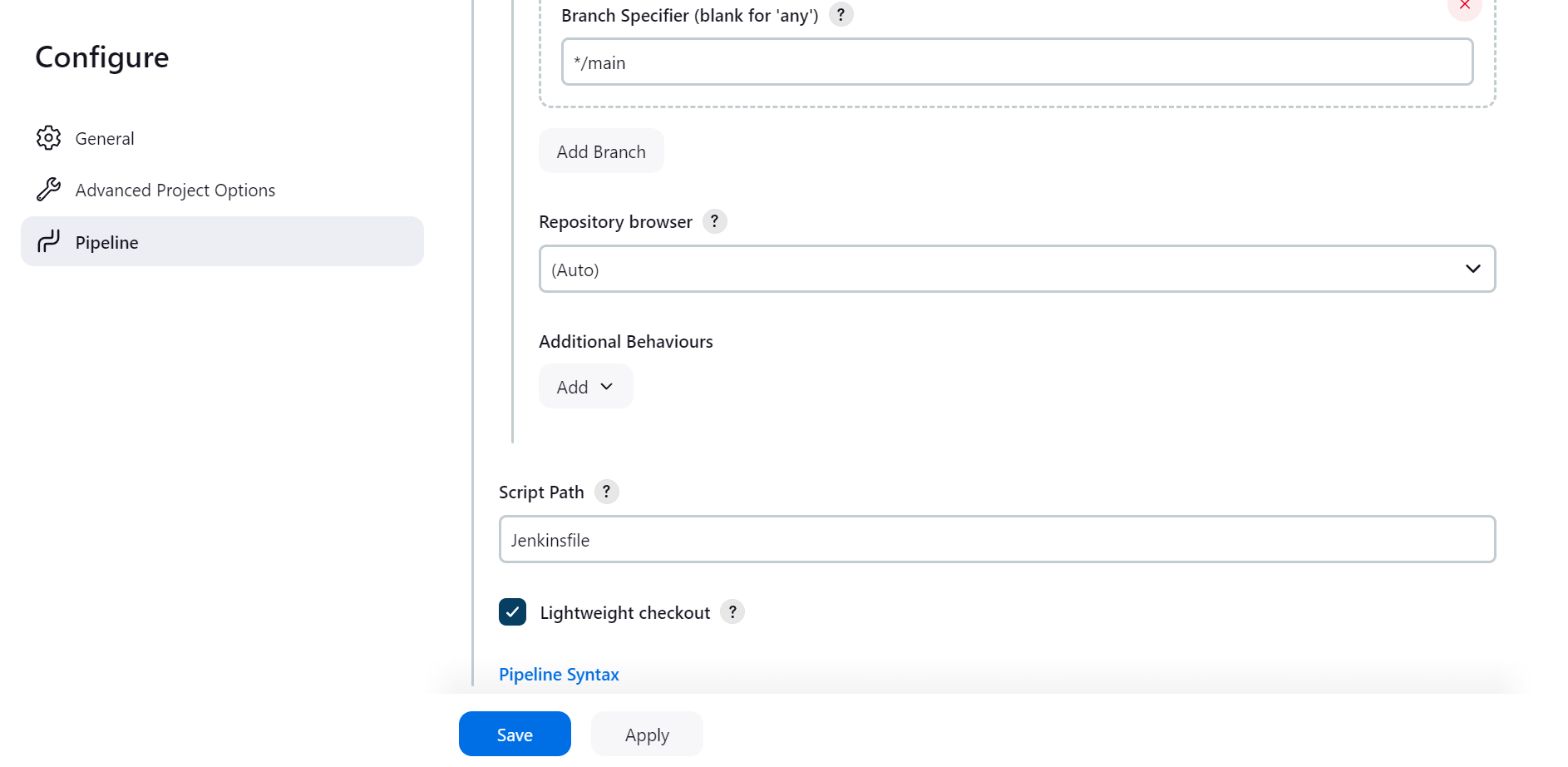
Build the Pipeline Job
After configuring the pipeline job, the next step was to click the "Build Now" button to initiate the execution of the pipeline. This action triggered the automated deployment process outlined in the Jenkinsfile, beginning with version retrieval and progressing through Terraform initialization, planning, application, and Lambda code management. This launch of the CI/CD workflow ensured that the latest changes were deployed under the defined pipeline stages, streamlining the entire deployment process and facilitating quick updates to the AWS Lambda function.
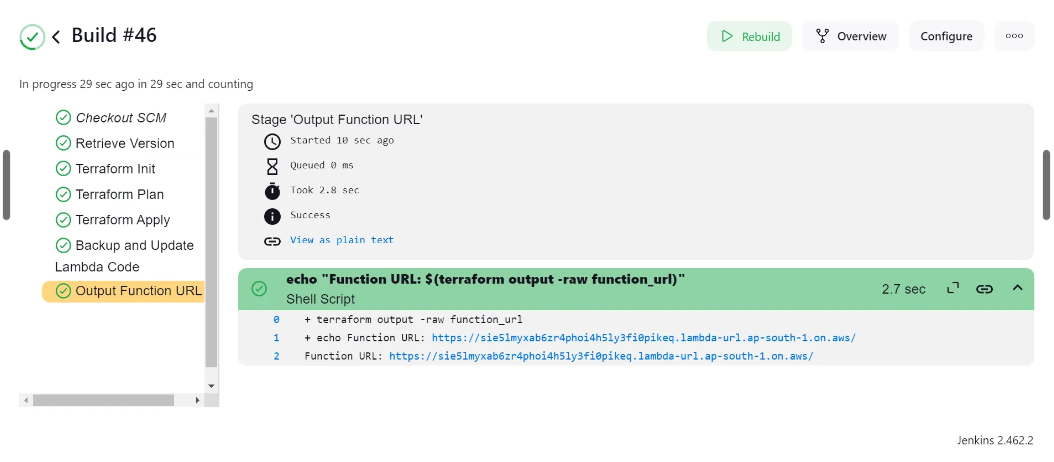
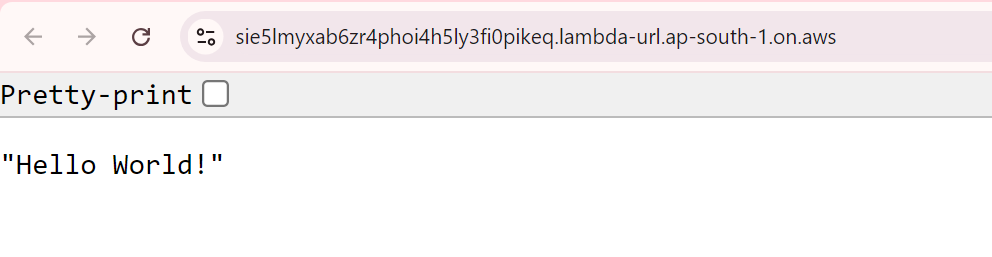
The pipeline has been executed successfully and we can the Lambda function URL as the output of the execution. If we click on the URL, we will be able to see ‘Hello World’ being displayed.
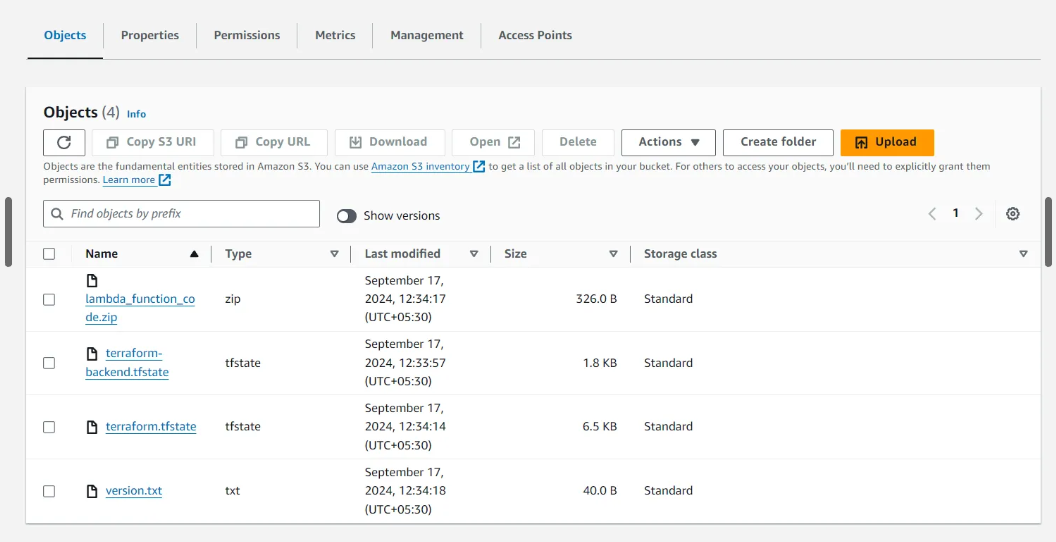
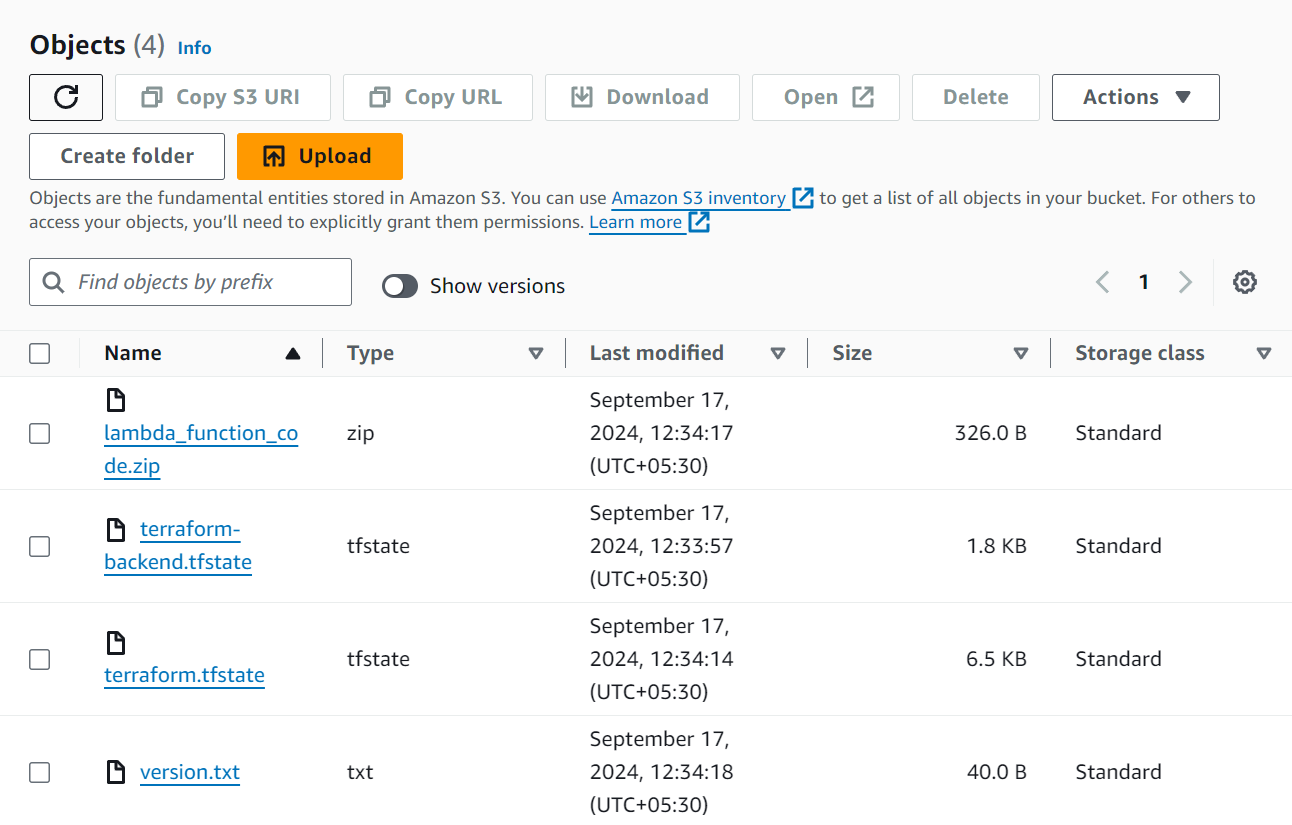
Storing Statefile along with its backup inside the S3 Bucket
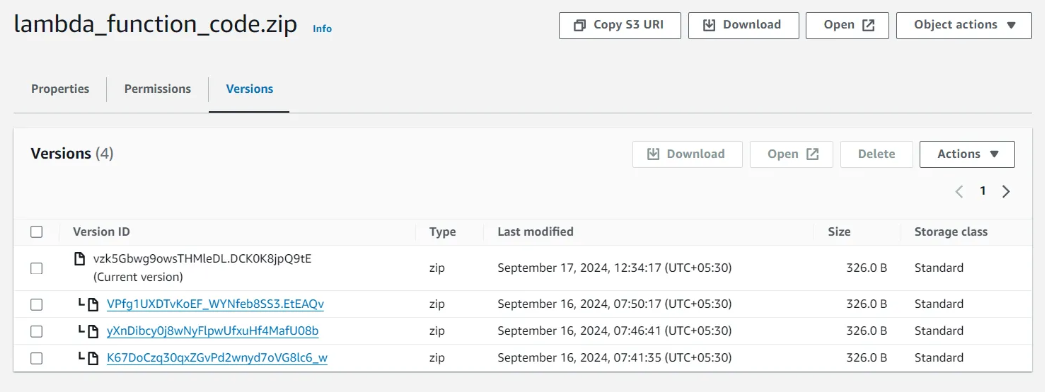
Enable Versioning for the Lambda Function Code
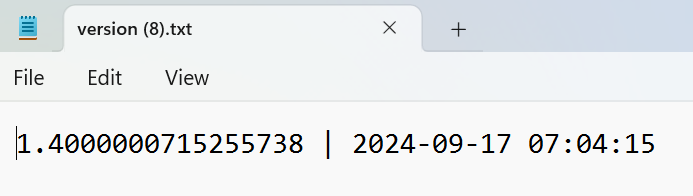
Storing the Backup Code Inside The Bucket
Conclusion
In summary, a Jenkins pipeline was successfully set up on an Ubuntu EC2 instance to automate the deployment of AWS Lambda functions. By configuring Jenkins to run on port 8080, installing essential plugins, and connecting it to a Git repository, a streamlined CI/CD process was created. The pipeline job was designed to execute the deployment steps defined in the Jenkinsfile. By simply clicking "Build Now," the pipeline is triggered, ensuring efficient management of deployments and seamless application of updates. This setup not only enhances the automation of the development process but also supports a more effective workflow, allowing for quicker iterations and improved productivity.
GitHub Repository: https://github.com/nishankkoul/Terraform-Serverless
Subscribe to my newsletter
Read articles from Nishank Koul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by