Cracking the Code of Language: The Art of Word Embeddings.
 TANBIR
TANBIR
🌟INTRODUCTION
What are these Word Embeddings? In a broad sense, these are just representations of words using numbers or vectors. Well, there’s more to it and In this blog, I will be going through the whole story of WORD EMBEDDINGS.
"Okay, but why 'numbers'?" you may ask. Well, in machine learning, the emphasis on "numbers" is because machine learning fundamentally relies on mathematical functions. Simply put, machine learning models can be seen as a "function" that takes in various inputs—often represented as numerical data—and produces corresponding outputs. This function is the core of machine learning algorithms, as it allows the system to learn and make predictions based on the input data it receives.
Inputs → f(x) → outputs
And these inputs have to be numbers. So when it comes to textual data we can’t just input the text itself, that would make no sense and the model won’t work. So we need a sort of representation of the textual data in terms of “numbers” to get a working model. Now that we have the motive and a basic idea, we can move forward.
You will come to appreciate the effectiveness of embedding as a technique for representing text. Before delving into the concept of embeddings, it is essential to explore our previous approaches to handling text data. This exploration will provide insight into the existing gaps and the rationale behind the adoption of embeddings.
📎EARLY APPROACHES TO WORD REPRESENTATION:
- BoW ( Bag of words )
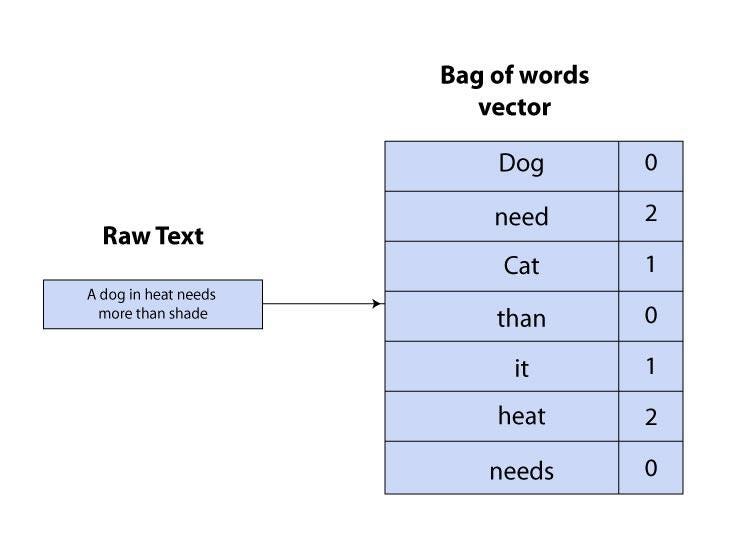
In BoW, each sentence is represented as a collection of its words, where the order of words doesn’t matter. It treats every word in the text as a feature and creates a vocabulary from the entire dataset of texts. Each sentence is then represented as a vector. Each element in the vector corresponds to a word in the vocabulary, and its value is the frequency (or sometimes a binary flag) of that word in the document.
- TF-IDF ( Term Frequency-Inverse Document Frequency )
Term Frequency measures how often a word occurs in a sentence and Inverse Document Frequency measures how rare a word is. I recommend reading this article( link ) to learn more about TF-IDF in-depth along with a simple application.
- One Hot Encoding
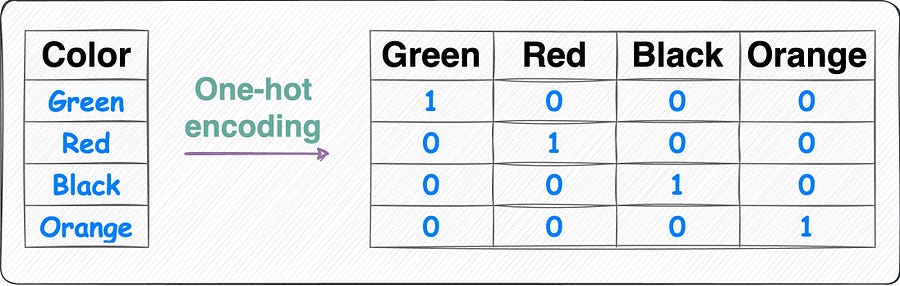
For example, we take the sentence, “A dog is on the road”, then our vocabulary becomes a list of all unique words,
Vocabulary: [ “a” , “dog” , “is” , “on” , “the” , “road ”]
“a” → index 0
“dog” → index 1
“is” → index 2
“on” → index 3
“the” → index 4
“road” → index 5
Think of it as, “0” means that indexed word is absent and “1" means that indexed word is present.
[1, 0, 0, 0, 0, 0], → “a”
[0, 1, 0, 0, 0, 0], → “dog”
[0, 0, 1, 0, 0, 0], → “is”
[0, 0, 0, 1, 0, 0], → “on”
[0, 0, 0, 0, 1, 0], → “the”
[0, 0, 0, 0, 0, 1] → “road”
📎WHAT DO WE LACK?
So what was lacking? We had all these methods but those failed to capture the Context & Semantic relationship between words. Also BoW and One Hot Encoding lead to higher dimensions, sparse vectors where most elements are “0”, these were given the name “Curse of dimensionality”. Also words like “Bank”, “River Bank”, and “Financial Bank” would be similar to these techniques but they aren’t, they have the same word “Bank” but in different contexts thus the meaning also changes.
For tackling these issues with context and semantic relationships Word embedding is preferred.
📎WORD EMBEDDINGS
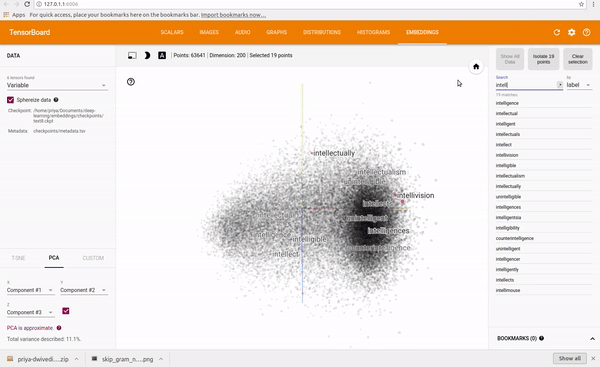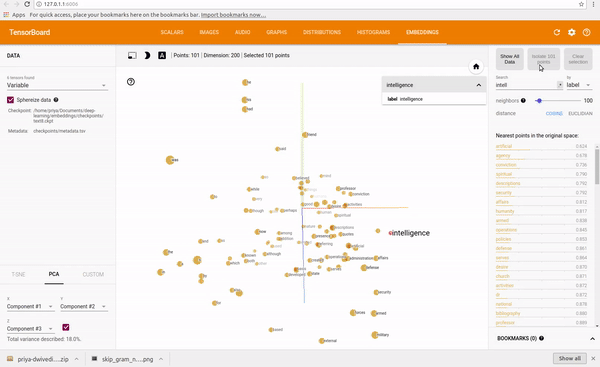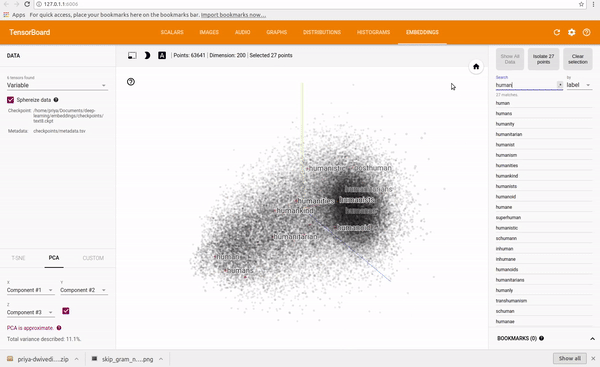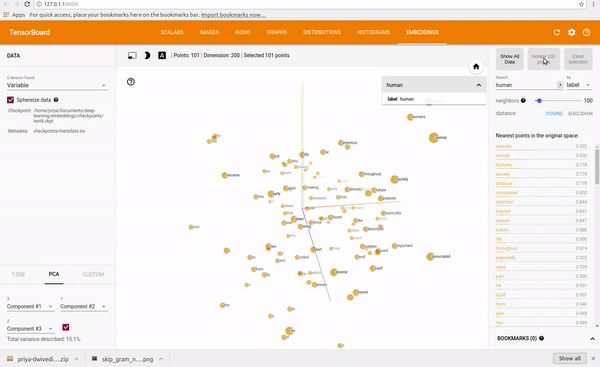
Explore It yourself, https://projector.tensorflow.org/
So at last, Word Embeddings captures the context of the paragraph/sentence along with its syntactic properties and semantic relationships between the words. And, To preserve this kind of semantic and syntactic relationship we need to demand more than just mapping a word in a sentence or document to mere numbers. We need a large representation of those numbers that can represent both semantic and syntactic properties, we need Vectors, not only that but Learnable vectors.
Example: dog → [0.2, 0.97, 0.82, 0.7, …..] ( a vector )
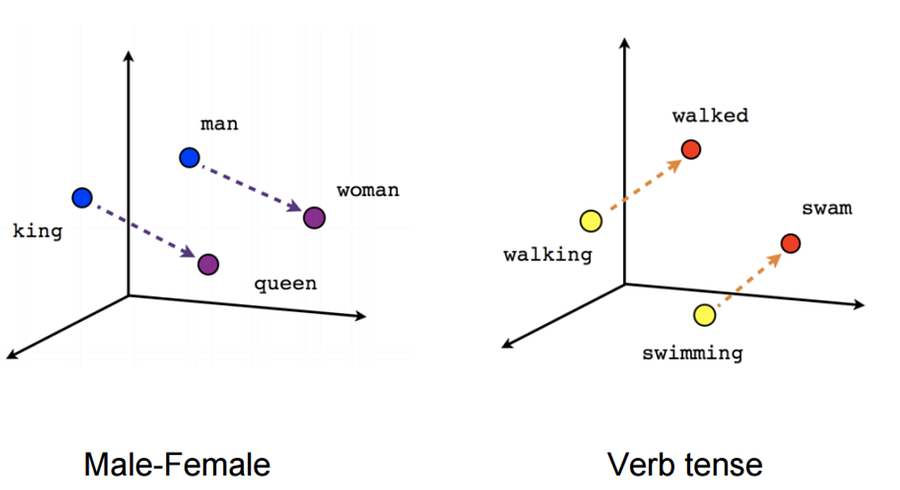
These vectors represent a point in the space and similar words will have points in the same region close to each other, words like { Cat, Dog, Kitten } will be closer in the space than words that don’t have any relation with them.
Example: {“dog”, “cat” }, {“King”, “Men”, “Boy”}, {“Queen”, “Women”, “girl” }
Will have vector space like in the figure ( here I have taken simpler 2D vectors for better illustrations but these vectors could be much much higher than that ).
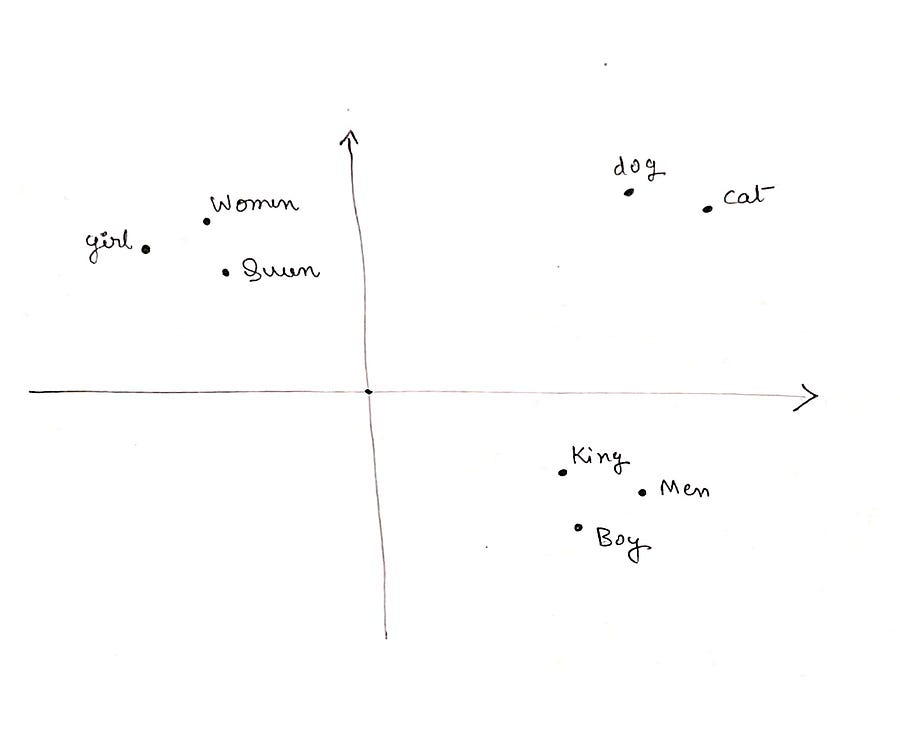
Fig: Word Embedding visual example
You can see that the words that are related are grouped, like dog & cat are together same as Queen, Women & girl, this is the main reason why word embedding is so efficient.
📎HOW DOES IT WORK?
But, how can we make simple vectors represent such relations and capture the meaning of words, sounds unreal, but now I will explain the training of a simple embedding layer, exciting isn’t it?
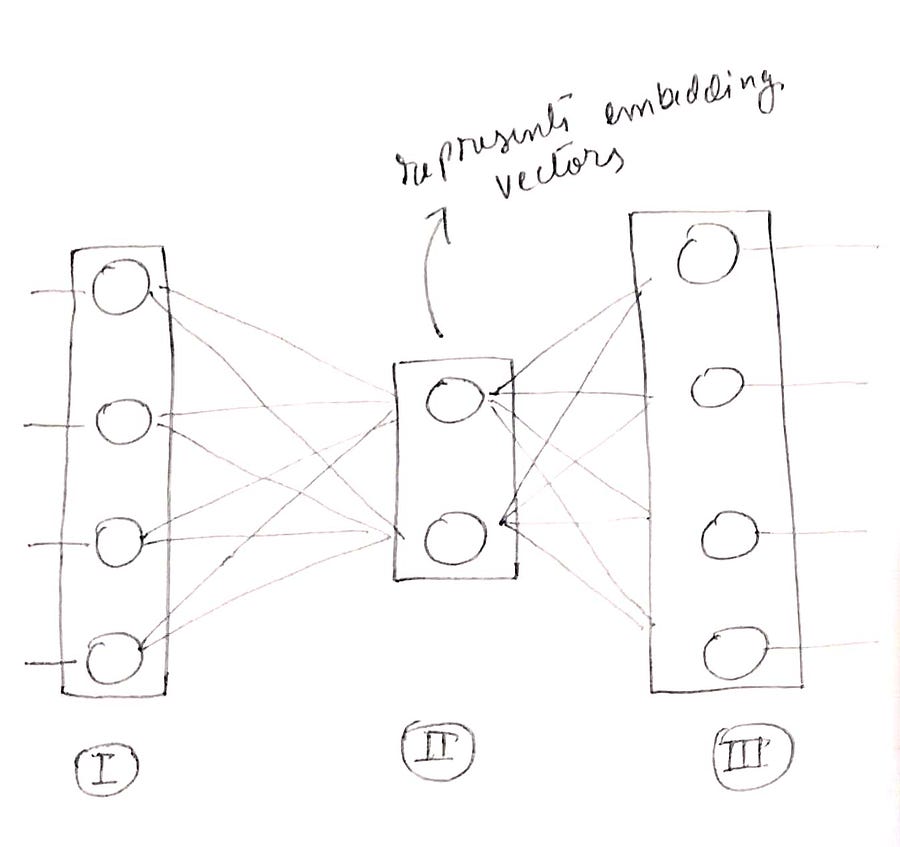
We will have the two examples as before, “Troll 2 is great” & “Gymkata is great”.
So we will input 4 words. We can make it as an input layer of 4 neurons and using one hot encoding technique we can represent when which word is the input for the layer.
The four neurons will each be for a unique word from our example, these are “Troll 2”, “is”, “great” and “Gymkata”. These will be our vocabulary.
Vocabulary = [ “Troll 2“, “is“, “great“, “gymkata“ ]
Then we will have a hidden layer with 2 neurons ( this is our learnable vector ), and these two values of numbers will represent our word vectors.
Then we will have an output layer with 4 neurons which will be trained with its actual labels using softmax regression.
( this is a very simplified model just to explain the working and how embeddings are done )
I want my model to predict the next word after a given input word. For example, if I input “Troll 2” I want the model to predict “is”. In the training sample, the input word “Troll 2” is represented as [1 0 0 0] and the true label “is” is represented as [0 1 0 0]
I won’t explain the entire forward pass and backward propagation, as those remain the same. During training, the model adjusts the values of these vectors (weights) based on the prediction task. For example, in a text classification task, it learns how words should be represented to achieve optimal classification performance.
Once training is complete and the model is performing well, these learned vectors from the embedding layer become the word embeddings. These vectors now capture the relationships between words in your vocabulary in a way that reflects the underlying semantics of our training data (vocabulary).
When we will be using word embeddings in our projects we won’t go around training our own model for that (unless required), we will be only extracting the trained weights of the pre-trained model, like Word2Vec which was trained on large vocabulary and representing the embeddings in very high dimensions capturing much more semantic and syntactic properties.
📎CONCLUSION
Word embeddings have changed how we represent text in machine learning by offering dense vectors that capture the meaning and context of words. Unlike traditional methods like one-hot encoding, embeddings solve issues like high dimensionality and lack of context. Today, we use pre-trained models like Word2Vec or GloVe, which make it easier to integrate meaningful word relationships into NLP tasks, leading to more effective and nuanced text analysis.
Subscribe to my newsletter
Read articles from TANBIR directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by