From Information to Knowledge: Ontology in Knowledge Graphs
 Ali Yazdizadeh
Ali Yazdizadeh
In the first part of this series, we explored how knowledge graphs are fundamentally different from traditional databases by shifting focus from isolated pieces of information to connected relationships. We also discussed various storage mechanisms for knowledge graphs, such as property graph databases and triple stores, and their use cases. Now, let’s take a deeper dive into one of the most critical components of a knowledge graph—ontology.
Recap
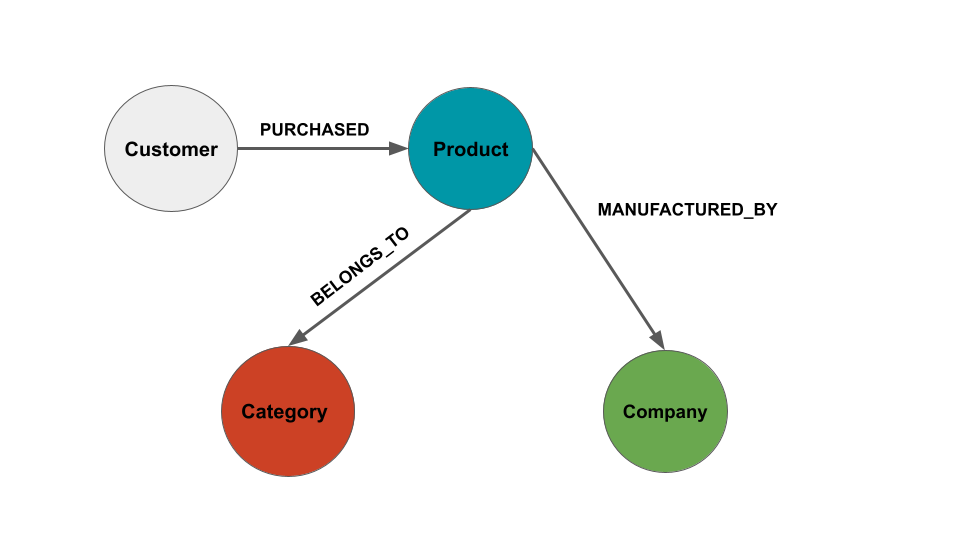
To recap: Imagine you’re building a knowledge graph for an e-commerce platform. Instead of simply storing isolated data like product descriptions, customer names, and orders, a knowledge graph allows you to store the relationships between these entities. For example:
A customer purchased a product.
A product belongs to a category.
A product is manufactured by a specific company.
These relationships are what make knowledge graphs powerful—they allow you to move beyond transactional queries ("What did the customer buy?") to more complex queries such as, "What products are frequently purchased together by customers in a specific region?" or "Which products tend to have delayed shipments from certain manufacturers?"
But how does the system understand what "purchased", "belongs to", and "manufactured by" actually mean? This is where ontology comes in.
What is Ontology?
At its core, an ontology is a formal representation of knowledge within a specific domain. It defines a set of concepts and categories, as well as the relationships between them. Ontologies help define the structure of a knowledge graph by answering questions like:
What entities exist in this domain?
What attributes do these entities have?
How are these entities related to each other?
In simpler terms, ontology provides the vocabulary and the rules that the knowledge graph follows. For example, if your domain is an e-commerce platform, your ontology might define entities like Customer, Product, Category, and Company, and relationships like "purchases", "belongs to", and "manufactured by". It also defines the attributes (or properties) these entities might have. For instance, a product might have attributes like price, weight, and brand, while a customer might have a name, address, and purchase history.
Without ontology, the knowledge graph would be disorganized and lacking in meaning—there would be no way to understand what kinds of entities or relationships exist in the data.
Why is Ontology the Core of a Knowledge Graph?
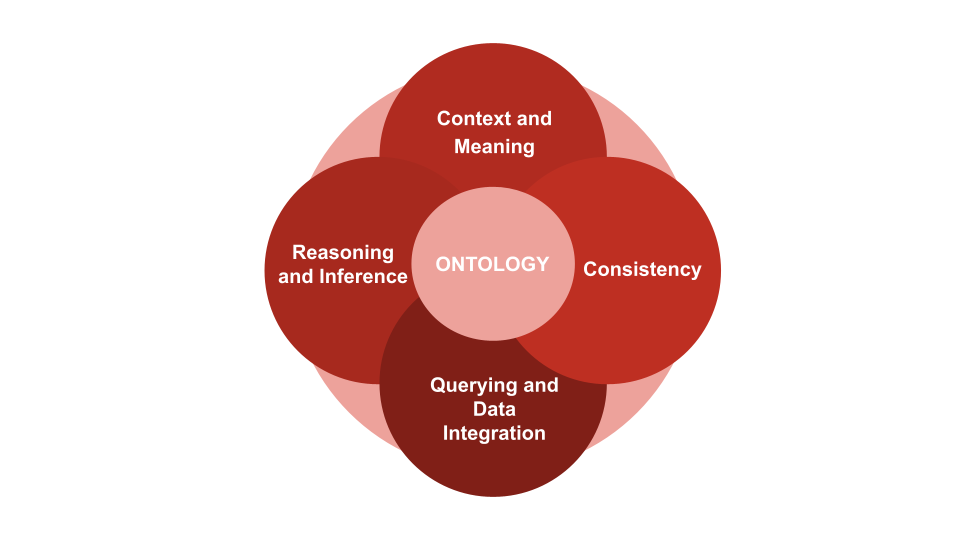
Ontology serves as the foundation of a knowledge graph because it structures and organizes the data in a meaningful way. Here’s why it’s essential:
Context and Meaning: Ontologies provide context to data by defining what each node and relationship in the graph means. This allows machines (and humans) to make sense of the data. Without ontology, a knowledge graph would just be a collection of unstructured entities with no inherent meaning.
Consistency: Ontologies ensure that the relationships and entities are consistent across the entire graph. For example, an ontology can ensure that every Product must have a manufacturer and every Customer must be associated with an Order.
Reasoning and Inference: Advanced knowledge graphs leverage reasoning engines that use ontologies to infer new knowledge from existing data. For example, if your ontology knows that every Laptop is a Product, and every Product has a manufacturer, it can infer that a specific laptop is also manufactured by a particular company, even if that specific connection wasn’t explicitly made in the graph.
Querying and Data Integration: Ontologies make it easier to query complex relationships and integrate data from different sources. For instance, if you integrate data from two different databases into your knowledge graph, ontology can ensure that both datasets follow the same structure and terminology.
What Sources Do We Have for Ontology?
Creating an ontology for a knowledge graph doesn't always mean starting from scratch. There are several established ontologies that can be used or extended depending on your needs.
General Ontologies
Schema.org: One of the most popular general-purpose ontologies, used for marking up web pages. It defines concepts like Person, Organization, Product, Event, and more, and provides standard relationships like "attends", "owns", and "works for". It’s a great starting point for building an ontology that will be widely understood.
FOAF (Friend of a Friend): This ontology focuses on people, their activities, and their relationships to other people and objects. It’s often used in social networking and community-based knowledge graphs.
Dublin Core: A simple ontology used for describing a wide variety of resources, including documents, images, and datasets. It defines basic metadata terms such as Title, Creator, Date, and Subject.
Field-Specific Ontologies
Medical Ontologies: If your knowledge graph is in the healthcare domain, you can leverage existing ontologies such as SNOMED CT, which provides a standardized vocabulary for medical terms, or the Gene Ontology, which focuses on biological and genetic entities.
Financial Ontologies: For finance and economics, ontologies like FIBO (Financial Industry Business Ontology) are available. FIBO defines entities related to financial instruments, transactions, and organizations, providing a solid base for financial knowledge graphs.
Geospatial Ontologies: Geospatial data is often integrated into knowledge graphs to analyze relationships between places and events. Ontologies like GeoNames and GADM provide structured vocabularies for geographic regions and locations.
What If We Need to Expand Our Ontology?
While starting with a predefined ontology can save time, you may eventually need to expand it to fit your specific use case. Here are a few strategies to do so:
Custom Classes and Relationships: You can add custom classes and relationships that reflect the specific entities and interactions in your domain. For example, if you are creating a knowledge graph for a fashion retailer, you might want to add specific relationships like "designed by" or custom entities like Fashion Line or Designer.
Data-Driven Expansion: As you collect more data, you may discover new relationships or entities that weren’t part of the original ontology. For example, by analyzing customer behavior, you might realize there is a relationship between customers who review products and their likelihood to recommend them.
Ontology Merging: If you're integrating data from multiple sources that use different ontologies, you can create a mapping between the different terms to unify the data into a coherent whole. This process is known as ontology alignment or merging.
Inference and Reasoning: Use reasoning engines to automatically expand the knowledge graph based on logical rules. For instance, if your ontology states that "Every laptop is a product," and "Every product has a manufacturer," the engine can infer new relationships between laptops and manufacturers without you having to manually input every connection.
Conclusion
Ontology is at the core of a knowledge graph. Without it, a knowledge graph would just be a collection of loosely connected data points with no clear meaning. By defining the entities, relationships, and rules within a specific domain, ontology turns raw data into useful, actionable knowledge.
- In the next part of this series, we’ll explore how to interact with knowledge graphs using query languages like Cypher, SPARQL, and Gremlin, and discuss how recent advances in large language models (LLMs) can help make this process even more intuitive.
Subscribe to my newsletter
Read articles from Ali Yazdizadeh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by