How to Scrape Dynamic Websites Using Browserless?
 nstbrowser
nstbrowser
What Is a Dynamic Web Page?
A dynamic web page is one where the content is not all directly embedded in static HTML but is generated through server-side or client-side rendering.
It can display data in real time based on user actions, such as loading more content when the user clicks a button or scrolls down the page (such as infinite scrolling). This design improves the user experience and allows users to get relevant information without reloading the entire page.
To determine whether a website is a dynamic web page, you can disable JavaScript in your browser. If the website is dynamic, most of the content will disappear.
Challenges when Scraping Dynamic Websites
Fingerprinting and Blocking
Fingerprinting techniques: Many websites use fingerprinting techniques to detect and block automated scrapers. These techniques create a unique "fingerprint" for each visitor by analyzing information such as browser behavior, screen resolution, plugins, time zone, etc. If anomalies are detected or inconsistent with regular user behavior, the website may block access.
Blocking mechanisms: To protect their content, websites implement various blocking mechanisms, such as:
- IP blocking: When frequent requests come from the same IP address, the website may temporarily or permanently ban access from that IP address.
- CAPTCHA verification: Websites may introduce CAPTCHA when automated traffic is detected to confirm that the visitor is human.
- Traffic limiting: Set a request rate limit, and when the request rate exceeds the preset threshold, the website will reject further requests.
Local loading challenges
- Resource consumption: Dynamic pages usually require more system resources for rendering and data crawling. When using tools like Puppeteer or Selenium, it may cause high memory and CPU usage, especially when crawling multiple pages.
- Latency and time cost: Due to the need to wait for the page to be fully loaded (including JavaScript execution and AJAX requests), the time cost of crawling dynamic pages may be high, which will affect the efficiency of the entire crawler.
- Concurrent processing: Under high load conditions, processing multiple crawling tasks at the same time may cause system overload, resulting in request failure or timeout. This requires reasonable task scheduling and resource management strategies.
Do you have any wonderful ideas or doubts about web scraping and Browserless? Let's see what other developers are sharing on Discord and Telegram!
6 Effective Ways for Scraping Dynamic Websites
1. Intercept XHR/Fetch requests
An effective method to intercept XHR (XMLHttpRequest) and Fetch requests during the scraping process is to inspect the browser's Network tab to identify API endpoints that provide dynamic content. Once these endpoints are identified, HTTP clients such as the Requests library can be used to send requests directly to these APIs to obtain data.
- Pros: This method is generally fast and can extract data efficiently because it only fetches the required content instead of the entire web page.
- Cons: This can be challenging if the data is stored in the DOM as JSON instead of being returned by the API. In addition, the process of simulating API requests can be affected by API changes, rate limits, and authentication requirements, resulting in poor scalability.
2. Use a headless browser
Using a headless browser like Puppeteer or Selenium allows full simulation of user behavior, including page loading and interaction. These tools are able to process JavaScript and scrape dynamically generated content.
- Pros: This method is able to scrape highly dynamic websites and support complex user interactions.
- Cons: high resource consumption, slow crawling speed, and may need to deal with complex page structures and dynamic content.
3. API request
Requesting data directly from the website's API is an efficient way to crawl. Analyze the website's network requests, find the API endpoint, and use the HTTP client to request data. - Pros: Ability to directly obtain the required data and avoid the complexity of parsing HTML.
- Cons: If the API requires authentication or has a request frequency limit, it may affect crawling efficiency.
4. Crawl AJAX requests
By monitoring network requests, identifying AJAX calls, and reproducing them, dynamically loaded data can be extracted.
- Pros: Directly obtain data sources and reduce unnecessary loading.
- Cons: Need to have a certain understanding of the parameters and format of AJAX requests, and may also face authentication and rate limit issues.
5. Proxy and IP rotation
In order to avoid being blocked by the website, using proxy services and IP rotation is an important strategy. This can help disperse requests and reduce the risk of detection.
- Pros: Reduce the probability of being blocked and can maintain effectiveness in a large number of requests.
- Cons: Using proxy services may increase crawling costs and require maintaining a proxy list.
6. Simulate user behavior
Writing scripts to simulate human browsing behavior, such as adding delays between requests, randomizing the order of operations, etc., can help reduce the risk of being identified as a crawler by the website.
- Pros: Data crawling can be performed more naturally, reducing the risk of being detected.
- Cons: The implementation is relatively complex, and it takes time to adjust and optimize the simulated behavior.
What Is Browserless?
Browserless is a headlesschrome cloud service that operates online applications and automates scripts without a graphical user interface. For jobs like web scraping and other automated operations, it is especially helpful.
Browserless Makes Scraping Dynamic Web Pages Easily
Browserless is also a powerful headless browser. Next, we will use Browserless as an example to crawl dynamic web pages.
Prerequisite
Before we start, we need to have a Browserless service. Using Browserless can solve complex web crawling and large-scale automation tasks, and now fully managed cloud deployment has been achieved.
Browserless adopts a browser-centric strategy, provides powerful headless deployment capabilities, and provides higher performance and reliability. You can read the document in the website to learn more about the configuration of Browserless services.
At the very beginning, we needed to get the API KEY of Nstbrowser. You can go to the Browserless menu page of the Nstbrowser client, or you can go to the Browserless panel in the clien to visit.
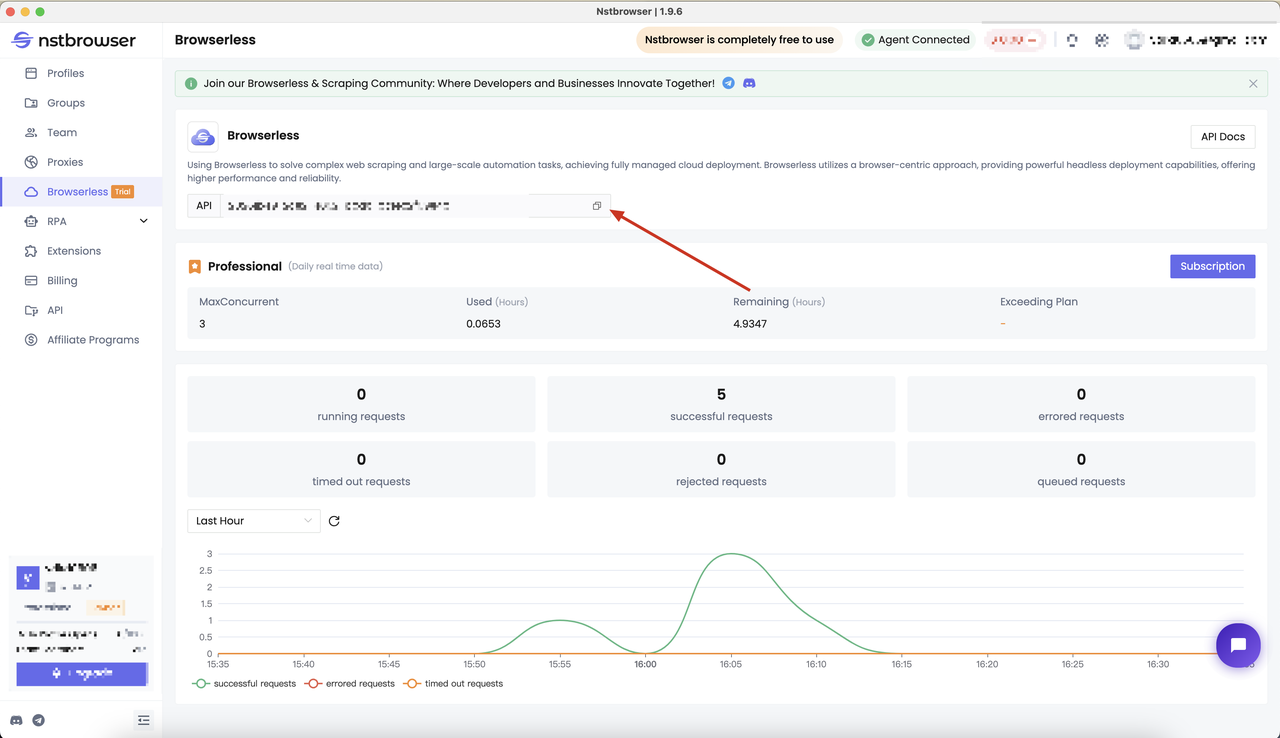
Determine the crawling target
Before we start, let's determine the goal of this test. We will use Puppeteer and Playwright to get the page title content of dynamic websites:
- Visit the target website: https://www.nstbrowser.io/en
- Get the dynamic page title content
Initialize the project
Follow the steps below to install dependencies:
- Step 1: Create a new folder in Vs code
- Step 2: Open the Vs code terminal and run the following commands to install related dependencies
npm init -y
pnpm add playwright puppeteer-core
Scrape dynamic web pages using Playwright and Browserless
- Create a crawling script
const { chromium } = require('playwright');
async function createBrowser() {
const token = ''; // required
const config = {
proxy:
'', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '124', // support: 113, 120, 124
// args: {
// '--proxy-bypass-list': 'detect.nstbrowser.io',
// }, // browser args
// fingerprint: {
// userAgent:
// 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36',
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `ws://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await chromium.connectOverCDP(browserWSEndpoint);
const context = await browser.newContext();
const page = await context.newPage();
page.goto('https://www.nstbrowser.io/en');
// sleep for 5 seconds
await new Promise((resolve) => setTimeout(resolve, 5000));
const h1Element = await page.$('h1');
const content = await h1Element?.textContent();
console.log(`Playwright: The content of the h1 element is: ${content}`)
await page.close();
await page.context().close();
}
createBrowser().then();
- Check the scraping result

Scrape dynamic web pages using Puppeteer and Browserless
- Create a crawling script
const puppeteer = require('puppeteer-core');
async function createBrowser() {
const token = ''; // required
const config = {
proxy:
'', // required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
// platform: 'windows', // support: windows, mac, linux
// kernel: 'chromium', // only support: chromium
// kernelMilestone: '124', // support: 113, 120, 124
// args: {
// '--proxy-bypass-list': 'detect.nstbrowser.io',
// }, // browser args
// fingerprint: {
// userAgent:
// 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36',
// },
};
const query = new URLSearchParams({
token: token, // required
config: JSON.stringify(config),
});
const browserWSEndpoint = `ws://less.nstbrowser.io/connect?${query.toString()}`;
const browser = await puppeteer.connect({
browserWSEndpoint: browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://www.nstbrowser.io/en');
// sleep for 5 seconds
await new Promise((resolve) => setTimeout(resolve, 5000));
const h1Element = await page.$('h1');
if (h1Element) {
const content = await page.evaluate((el) => el.textContent, h1Element); // use page.evaluate to get the text content of the h1 element
console.log(`Puppeteer: The content of the h1 element is: ${content}`);
} else {
console.log('No h1 element found.');
}
await page.close();
}
createBrowser().then();
- Check the scraping result

Conclusion
Crawling dynamic web pages is always more complicated than crawling ordinary web pages. It is easy to encounter various troubles during the crawling process. Through the introduction of this blog, you must have learned:
- 6 effective ways to crawl dynamic web pages
- Use Browserless to easily crawl dynamic web pages.
Subscribe to my newsletter
Read articles from nstbrowser directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by