Running Small Language Models with HuggingFace, Ollama, and LM Studio
 Sakalya Mitra
Sakalya Mitra
In the ever-evolving landscape of artificial intelligence, a new player has emerged that's challenging the notion that bigger is always better. Small Language Models (SLMs), a category of AI models that are proving that sometimes, less really is more. In this blog post, we'll dive deep into the world of SLMs, exploring what they are, why they matter, and how they're reshaping the AI landscape, with a comprehensive hands-on implementation of running some SLMs on our own.
What are Small Language Models?
Small Language Models (SLMs) are a subset of language models that are designed to be more compact and efficient than their larger counterparts. While models like GPT-3 and GPT-4 boast billions of parameters and require substantial computational resources, SLMs typically have fewer parameters, making them easier to deploy and use in various applications.
Typical Size and Architecture of SLMs
Small Language Models (SLMs) are defined by their reduced size and simplified architecture compared to larger models like GPT-3 or GPT-4. Typically, SLMs range from a few million to a few hundred million parameters. For example, while GPT-3 has 175 billion parameters, models like DistilBERT and TinyGPT have around 66 million and 15 million parameters, respectively. This reduction in size enhances efficiency in memory usage and computational requirements.
Architecture
SLMs often retain the core principles of larger models but are streamlined for efficiency.
Transformer Architecture: Most SLMs are based on the transformer architecture, utilizing self-attention mechanisms. However, they typically have fewer layers or reduced hidden dimensions.
Layer Sharing: Models like ALBERT implement weight sharing across layers, reducing the total number of parameters while maintaining performance.
Distillation Techniques: Many SLMs use model distillation, where a smaller model (the student) learns to replicate the behavior of a larger model (the teacher), retaining much of the larger model's knowledge.
Pruning and Quantization: Techniques such as pruning (removing less important parameters) and quantization (reducing weight precision) further decrease the size of SLMs without significantly impacting performance.
Trade-offs Between Size and Performance
The trade-offs between size and performance in SLMs are crucial for developers and researchers.
1. Performance vs. Efficiency: Larger models excel in complex tasks due to their extensive training data and parameter space, capturing intricate language patterns. SLMs, while potentially less capable in complex tasks, offer faster inference times and lower resource consumption, making them suitable for real-time applications.
2. Generalization vs. Specialization: Larger models generalize better across diverse tasks due to extensive training. SLMs on the other hand can be fine-tuned on specific datasets, performing exceptionally well in niche applications.
3. Training Time and Cost: Larger models require significant time and resources for training, often necessitating powerful hardware. Training and deploying larger models can be prohibitively expensive, while SLMs can be trained and deployed at a fraction of the cost, making them more accessible.
4. Deployment and Accessibility: Larger models often need specialized infrastructure, complicating integration. SLMs are more easily deployable on various platforms, including mobile devices. Lower resource requirements make SLMs accessible to a broader audience, enabling developers with limited resources to leverage advanced language processing capabilities.
Key Differences Between SLMs and Larger Models
Size and Complexity:
Larger Models: GPT-3, for instance, has 175 billion parameters, while GPT-4 is even more extensive. This size allows them to capture intricate patterns in language but also requires significant computational power and memory.
SLMs: In contrast, SLMs may have anywhere from a few million to a few hundred million parameters. This reduction in size often leads to faster inference times and lower resource requirements.
Training Data:
Larger Models: These models are trained on diverse and extensive datasets, which contribute to their ability to generate high-quality text across various domains.
SLMs: While SLMs may be trained on smaller datasets, they can still perform well in specific tasks, especially when fine-tuned on domain-specific data.
Use Cases:
Larger Models: Due to their complexity, larger models are often used for tasks requiring deep understanding and generation capabilities, such as creative writing or complex question-answering.
SLMs: SLMs are particularly effective for applications where speed and efficiency are paramount, such as mobile applications, real-time chatbots, and embedded systems.
Examples of Small Language Models
TinyLlama: TinyLlama is a compact model with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
DistilBERT: A smaller, faster, and lighter version of BERT, DistilBERT retains 97% of BERT's language understanding while being 60% faster and requiring less memory. This makes it ideal for applications where computational resources are limited.
Phi 2: Microsoft’s Phi 2 is a transformer-based Small Language Model (SLM) engineered for efficiency and adaptability in both cloud and edge deployments. According to Microsoft, Phi 2 exhibits state-of-the-art performance in domains such as mathematical reasoning, common sense, language understanding, and logical reasoning.
GPT-Neo and GPT-J: GPT-Neo and GPT-J are scaled-down iterations of OpenAI’s GPT models, offering versatility in application scenarios with more limited computational resources.
TinyGPT: A smaller variant of the GPT architecture, TinyGPT is designed for applications that require quick responses and lower resource consumption, making it suitable for mobile devices and edge computing.
If you are curious to learn more about the different SLMs and their applications, you can checkout AIDemos. You will get a comprehensive and extensive list of AI Tools powered by SLMs and LLMs. Not only limited to the diverse demos, you can also explore AI Tools and AI PlayGround, to try some trending AI Applications like Image Captioning, Text-to-Speech and many more using different state-of-the-art models and play around with them!
Advantages of Small Language Models
Efficiency: SLMs require less computational power, making them faster and more energy-efficient.
Cost-Effective: Lower resource requirements translate to reduced costs for both development and deployment.
Edge Deployment: Their smaller size allows SLMs to run on edge devices, enabling offline use and enhancing privacy.
Focused Expertise: SLMs can be fine-tuned for specific tasks, often outperforming general-purpose large models in niche applications.
Reduced Latency: Smaller models can process requests more quickly, crucial for real-time applications.
Interpretability: With fewer parameters, SLMs are often easier to analyze and understand.
Hands-on Implementation of SLMs
We have already glided through a lot of information about the what and why of SLMs. Now it’s time to see the SLMs in action and see their power in limited memory environments. We will be seeing our very own Llama Variant SLM, TinyLlama in action through different methods:
Setting up environment and running TinyLlama using LMStudio
Setting up Ollama and running TinyLlama locally using Ollama
Running TinyLlama using HuggingFace
Running TinyLlama using LMStudio
LMStudio is a powerful software designed specifically for downloading, running and working with language models, including Small Language Models (SLMs) locally. It provides a user-friendly and intuitive interface and a suite of tools that simplify the process of training, fine-tuning, and deploying language models. With LMStudio, developers can easily experiment with various SLMs, streamline their workflows, and enhance their productivity.
Before you can run TinyLlama using LMStudio, you need follow these steps to complete the LMStudio Setup:
Install LMStudio: Download and install LMStudio from the official website. Follow the installation instructions for your operating system (Windows, macOS, or Linux).
Create a New Project: Open LMStudio and create a new project. This will serve as your workspace for running SLMs.
Select a Small Language Model: Choose an SLM that you want to work with. Popular options include TinyLlama, DistilBERT, TinyGPT. You can simply search, explore and download models with a single click.
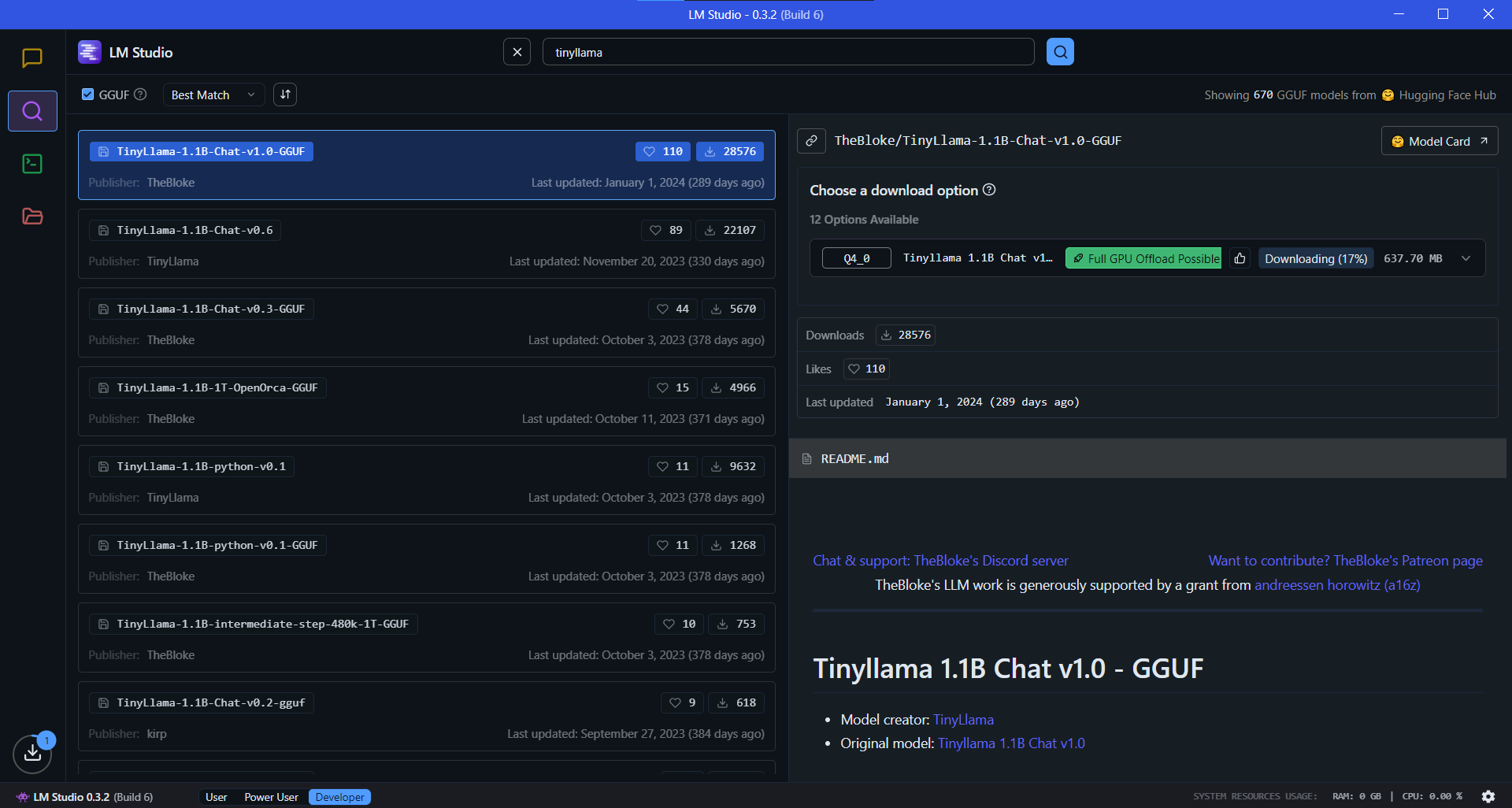
Once downloaded, the model will appear in your project and you can simply start chatting with your SLM seamlessly.
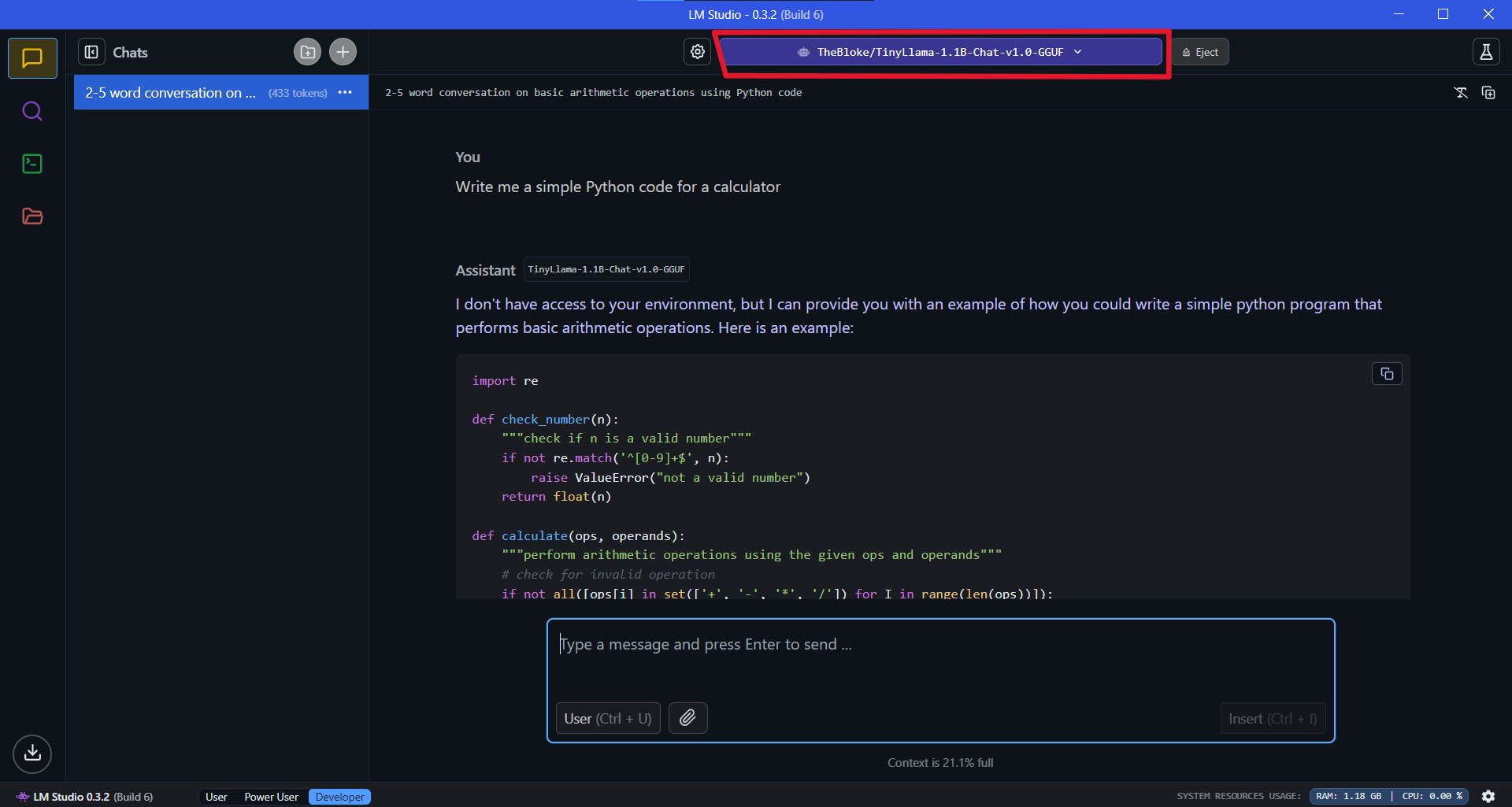
Running TinyLlama using Ollama
Ollama is an open-source platform that lets users run large language models (LLMs) locally on their computers. Ollama allows users to run LLMs without an internet connection, which can help secure sensitive data and provide more control over the AI models. It can also reduce costs and eliminate concerns about data ending up in online AI vendor databases.
In order to run TinyLlama using Ollama, you can follow these 3 simple steps:
Download and install Ollama from the official website suitable for your operating system.
Install Ollama once downloaded.
Open your Terminal and just type
ollama run tinyllama
And that’s it! You will see a Chat Interface in your terminal where you can chat with your TinyLlama model and get your queries answered.
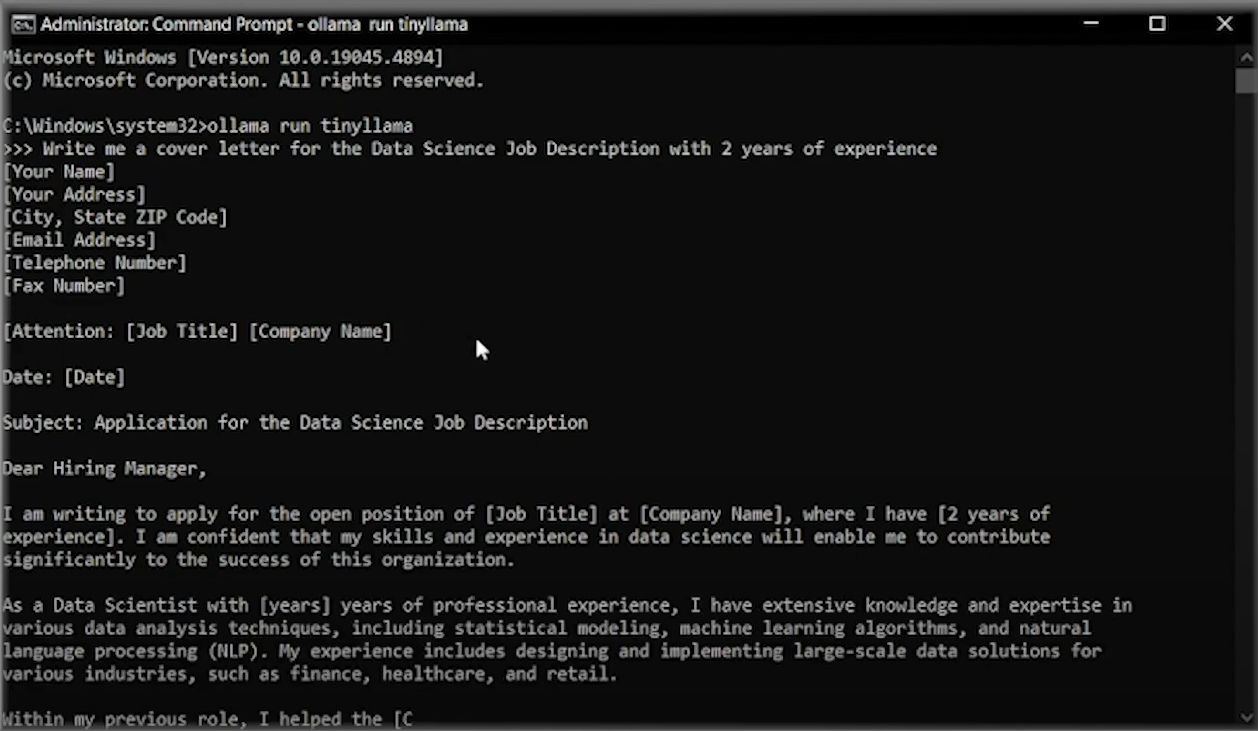
You can use any SLM of your choice. The comprehensive list of SLMs supported by Ollama can be found in their library.
If you want a more comprehensive walkthrough of how to run SLMs using LMStudio or Ollama on your PC, you can check out this video!
Running TinyLlama using HuggingFace
Leveraging the HuggingFace Transformers library, you can easily load and run TinyLlama or any SLM using simple inference API’s provided by HuggingFace. A few lines of code and some very easy to follow steps is enough to have your SLM ready to respond to your queries using HuggingFace.
Go to HuggingFace Hub and search your desired mode. For this blog we have used the TinyLlama model.
Click on the Use this model button in the page and then select Transformers.
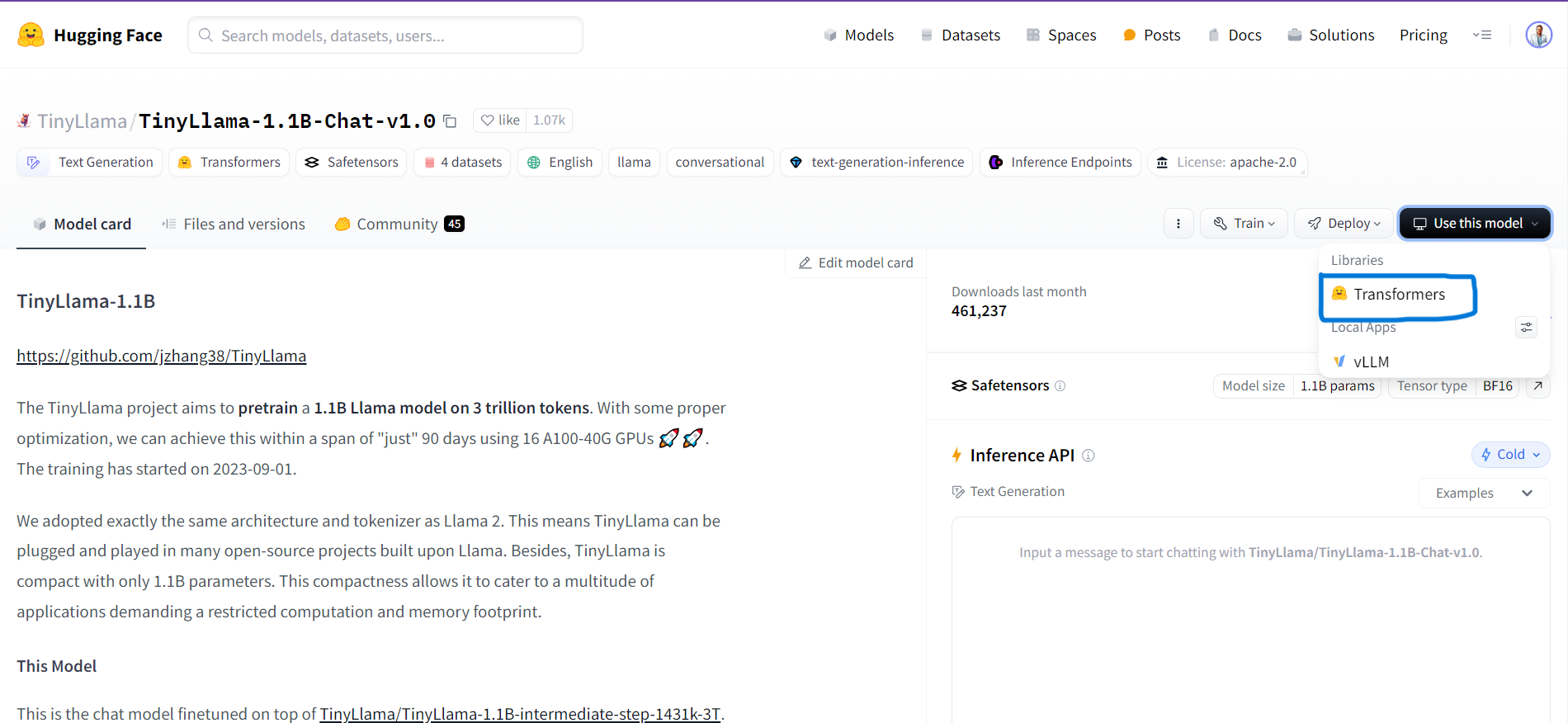
You can alternatively also use the HuggingFace Inference API. Click on the Deploy button and select Inference API(Serverless)
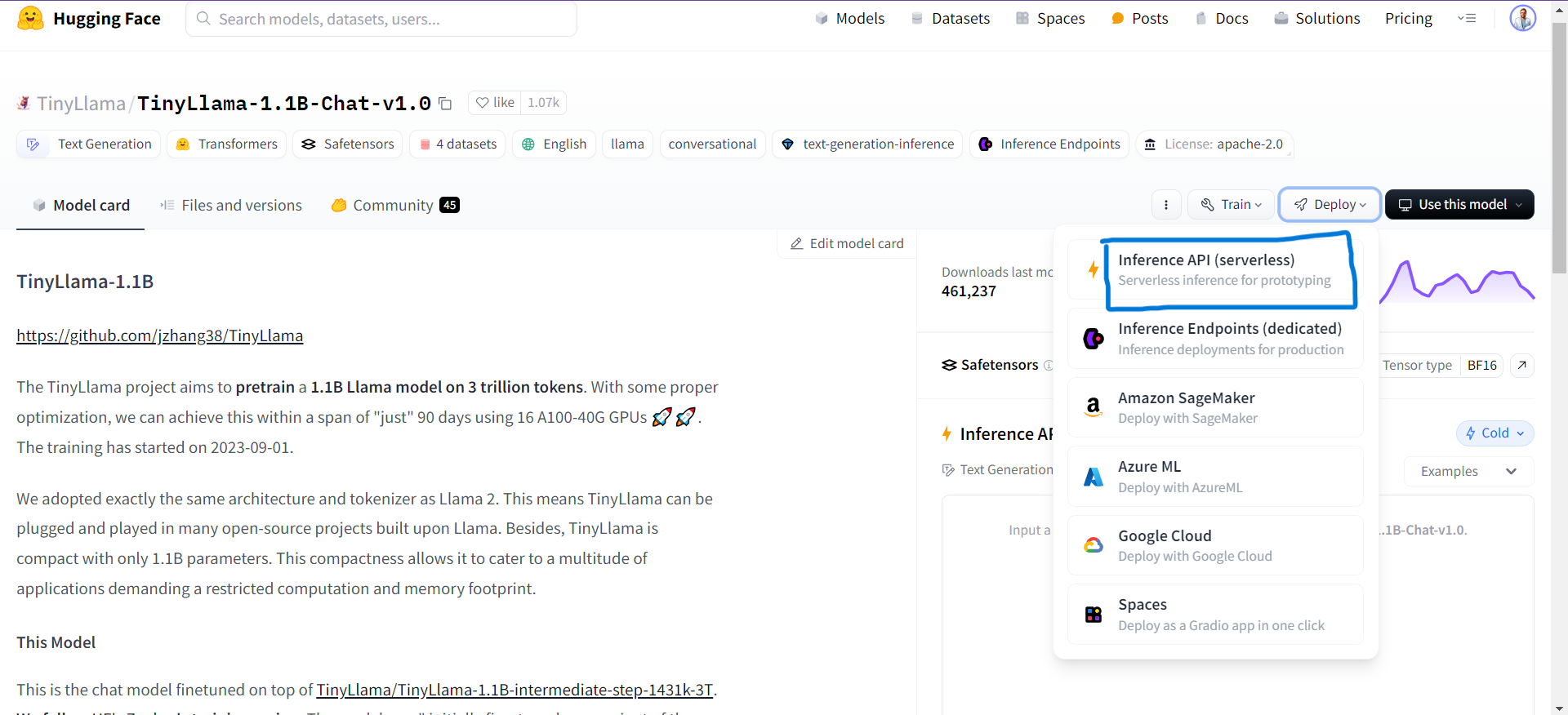
For using SLMs using Inference API, you would require HF Access Token. You can check out the video below on using HuggingFace Inference APIs to learn about the process in detail.
Copy the code provided
Using HuggingFace Text Generation Pipeline
# Use a pipeline as a high-level helper from transformers import pipeline messages = [ {"role": "user", "content": "Who is the Capital of France?"}, ] pipe = pipeline("text-generation", model="TinyLlama/TinyLlama-1.1B-Chat-v1.0") pipe(messages)Using Inference API
from huggingface_hub import InferenceClient client = InferenceClient(api_key="hf_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx") for message in client.chat_completion( model="TinyLlama/TinyLlama-1.1B-Chat-v1.0", messages=[{"role": "user", "content": "What is the capital of France?"}], max_tokens=500, stream=True, ): print(message.choices[0].delta.content, end="")Open Google Colab, Paste the code and Run it to see your SLM in action!
Output Using HuggingFace Text Generation Pipeline
[{'generated_text': [{'role': 'user', 'content': 'What is the capital of France?'}, {'role': 'assistant', 'content': 'The capital of France is Paris.'}]}]Output Using Inference API
The capital of France (le chef-lieu de France) is Paris. Paris is the seat of the Parliament of France, the National Assembly, the Conseil d'Etat, the French Council of State, the Constitutional Council, and some public offices.
That’s it! You have successfully run TinyLlama in Colab✨
Challenges and Limitations of Leveraging SLMs
While SLMs offer numerous advantages, they're not without their challenges:
Limited Scope:
SLMs often operate within a narrower range of knowledge compared to their larger counterparts. This limitation can hinder their ability to tackle tasks that require extensive background information or complex reasoning.Task-Specific Training:
To achieve optimal performance, SLMs frequently require fine-tuning tailored to specific applications. This process can be resource-intensive and may necessitate a significant amount of labeled data.Contextual Understanding:
Smaller models may encounter difficulties in grasping nuanced language and context. They might misinterpret idiomatic expressions, sarcasm, or culturally specific references, leading to responses that lack the depth or appropriateness expected in human communication.Continuous Learning:
Unlike larger models that can be retrained on vast datasets to incorporate recent developments, SLMs may require more manual intervention to refresh their knowledge base.
Conclusion
As we've explored in this blog post, Small Language Models (SLMs) are proving that in the world of AI, bigger isn't always better. By offering efficiency, accessibility, and focused expertise, SLMs are opening up new possibilities for AI implementation across a wide range of industries and applications.
While large language models will continue to play a crucial role in pushing the boundaries of what's possible in AI, SLMs are carving out their own niche. They're making AI more accessible, more efficient, and more practical for everyday use.
At FutureSmart AI, we specialize in helping companies build cutting-edge AI solutions tailored to their unique needs—whether that involves leveraging the power of SLMs or other advanced AI technologies. Our team can help you create scalable, efficient, and innovative AI-driven applications that can transform your business operations.
To see real-world examples of our expertise, explore our case studies. If you're ready to build an AI solution that is customized for your business application, contact us at contact@futuresmart.ai. Let us help you stay ahead of the curve in this rapidly evolving AI landscape.
Resources
For those interested in diving deeper into the concepts and tools used in this tutorial, here are some valuable resources:
Hugging Face Transformers Library: Comprehensive documentation for the Transformers library, which we used extensively in this tutorial.
Hugging Face Hub: Explore other models, datasets, and spaces that could be useful for your projects.
Hugging Face Course: A free course that covers many of the concepts used in this tutorial in greater depth.
AI Demos YouTube: Learn about various latest AI Developments and their hands-on implementation within few minutes
LMStudio : Learn more about the other capabilities and services offered by LMStudio
Ollama: Learn about a diverse range of Language Models and their workings
By leveraging these resources, you can continue to expand your knowledge and skills in the exciting field of vision-language models and natural language processing.
Subscribe to my newsletter
Read articles from Sakalya Mitra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sakalya Mitra
Sakalya Mitra
NLP Intern @FutureSmart AI | Former- Scaler, ITJobxs, Speakify | ML, DL Enthusiast| Researcher - Healthcare, AI