Let's build a Full-Text Search engine (Part 2)
 Olalekan Adekola
Olalekan Adekola“Where is part one?” asked the reader.
Part one was written by Artem Krylysov and is a prerequisite to understanding this article. You can find part one here.
I’d like to mention that besides introducing a disk-based persistence layer for the project, the other changes are merely cosmetic improvements. For example, adding a HTTP web server interface to query and retrieve search results, caching search results, pagination, modularizing the code into different packages, adding json support etc.
In Part 1, the index was stored in memory, which caused it to be rebuilt every time the application started, causing wait times of around 30-50 seconds before the application starts. The memory footprint of the application was also high on startup.

The memory usage was as high as 461 MB the first time. After persisting the index to disk, the startup time was around 40ms and the memory usage dropped below 10% of the initial value.
Choosing a storage engine for the index
There are quite a few options when looking to persist data on disk, ranging from fully featured SQL/NoSQL database management systems to embedded database engines like SQLite. I chose an embedded engine because it eliminates network overhead. The database is directly contained within the application itself so read and write operations are much faster because there are no roundtrip network calls. Amongst the list of popular battle-tested embedded databases such as RocksDB, LevelDB, BoltDB, PebbleDB and BadgerDB, I settled on RocksDB because I have some familiarity with it and its support for column family handles— more on this later. In practice, any of the above listed databases would work without problems and the ones written purely in Go would be more convenient to setup than RocksDB because they require no CGO configuration.
RocksDB
RocksDB is an embeddable persistent key-value store for fast storage. The key and values are arbitrary byte streams. Anything can be a key or value as long as it can be represented in bytes (which is everything btw 😉). RocksDB also has a notorious reputation for being hard to configure.

Luckily, I found some sane defaults while I was exploring Trezor’s Blockbook codebase and they work well for this project’s use case.
Talk is cheap, show me the code now !!!
In order to reduce article length, I have condensed the code samples to show the most important changes. Please refer to the code repository for detailed walkthrough
Loading the Documents
We start by creating the RocksDB configurations, opening the database and loading all the documents from the compressed archive into the database.
RocksDB has support for column family handles (CFHs). CFHs are a way to logically partition the database. In analogy with relational databases, a column family is the equivalent of a table. We create five column families (our application only uses four)
Default - the default column family required by RocksDB
Meta - this table is for storing metadata like no of documents in the database, no of tokens in the index, when the documents table was built, etc
Index - This table stores the key/value pairs of the inverted index.
Docs - This table stores the documents so we don’t have to read it into memory from the archive everytime we load the application.
Search Results - This table stores the query results for caching and pagination purposes.
// index/index.go
// create column families
const (
cfhDefault = iota
cfhDbMeta
cfhInvertedIdx
cfhDocuments
cfhSearchResults
)
var cfNames = []string{"default", "meta", "index", "docs", "results"}
// create db options
func getDbOptions() *grocksdb.Options {
bbto := grocksdb.NewDefaultBlockBasedTableOptions()
bbto.SetBlockCache(grocksdb.NewLRUCache(3 << 30))
bbto.SetBlockSize(32 << 10) // 32kB
bbto.SetFilterPolicy(grocksdb.NewBloomFilter(float64(10)))
opts := grocksdb.NewDefaultOptions()
opts.SetBlockBasedTableFactory(bbto)
opts.SetCreateIfMissing(true)
opts.SetCreateIfMissingColumnFamilies(true)
return opts
}
// create new database instance
func New(dataDir string) (*Index, error) {
opts := getDbOptions()
cfOptions := []*grocksdb.Options{opts, opts, opts, opts, opts}
db, cfh, err := grocksdb.OpenDbColumnFamilies(opts, dataDir, cfNames, cfOptions)
if err != nil {
return nil, err
}
return &Index{
ro: grocksdb.NewDefaultReadOptions(),
wo: grocksdb.NewDefaultWriteOptions(),
cfh: cfh,
db: db,
}, nil
}
In the above snippet, we created an instance of the database type Index struct {...}, it contains all options and methods required to access and perform operations on the database.
// engine/engine.go
func (f *FtsEngine) loadDocuments(path string) error {
log.Println("Starting...")
metaFieldName := "docsMeta"
lastDocument := f.index.GetMostRecentDocument()
if lastDocument != nil {
docsMeta := f.index.GetMeta(metaFieldName)
log.Printf("Documents already loaded in database at %v. Skipping ⏭️⏭️ \n", docsMeta.LastUpdatedAt)
log.Printf("Documents count = %v \n", docsMeta.Count)
return nil
}
ch := make(chan bool)
go utils.Spinner(ch, "Loading Documents...")
start := time.Now()
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close()
gz, err := gzip.NewReader(file)
if err != nil {
return err
}
defer gz.Close()
decoder := xml.NewDecoder(gz)
dump := struct {
Documents []index.Document `xml:"doc"`
}{}
if err := decoder.Decode(&dump); err != nil {
return err
}
wb := f.index.NewWriteBatch()
defer wb.Destroy()
for i := range dump.Documents {
dump.Documents[i].ID = i
docJson, err := json.Marshal(dump.Documents[i])
if err != nil {
log.Printf("Failed to marshal document at index %v \n", i)
continue
}
key := strconv.Itoa(i)
f.index.WriteDocumentsBatch(wb, key, docJson)
}
recordsCount := f.index.BulkSave(wb)
f.index.SaveMeta(metaFieldName, recordsCount)
log.Printf("\n %v Documents loaded in %s ✅✅ \n", recordsCount, time.Since(start))
ch <- true
return nil
}
In the loadDocuments function, we check the database to retrieve the last saved document f.index.GetMostRecentDocument if we find a document, we assume that we’ve previously loaded the document and we exit the function. Otherwise, we read the compressed file into memory, parse it and save it to the database. RocksDB has support for batching, so all the documents are written onto a write batch instance
f.index.WriteDocumentsBatch(wb, key, docJson)
and a bulk save operation is used to commit the changes to the database.
recordsCount := f.index.BulkSave(wb) // bulk save
f.index.SaveMeta(metaFieldName, recordsCount) // update the metadata
It took about 19 seconds for this to complete.
Building the Index
After the documents have been loaded, we proceed to build the index.
func (f *FtsEngine) buildIndex() {
metaFieldName := "indexMeta"
lastToken := f.index.GetMostRecentIndexedToken()
if lastToken != nil {
meta := f.index.GetMeta(metaFieldName)
log.Printf("Index was built at %v, skipping ⏭️⏭️ \n", meta.LastUpdatedAt)
log.Printf("Index contains %v tokens \n", meta.Count)
return
}
ch := make(chan bool)
go utils.Spinner(ch, "Building Index...")
start := time.Now()
recordsCount := f.index.BuildIndex()
f.index.SaveMeta(metaFieldName, recordsCount)
ch <- true
log.Printf("\n Index built in %s ✅✅. No of tokens = %v \n", time.Since(start), recordsCount)
}
Similar to the loadDocuments function, we check if we’ve previously persisted the index to disk by retrieving the most recent token. If it exists, we skip the process, else we build the index.
// index/index.go
func (d *Index) BuildIndex() int {
it := d.db.NewIteratorCF(d.ro, d.cfh[cfhDocuments])
defer it.Close()
inMemoryIndex := make(map[string][]int)
for it.SeekToFirst(); it.Valid(); it.Next() {
key := string(it.Key().Data())
value := it.Value().Data()
var doc Document
err := json.Unmarshal(value, &doc)
if err != nil {
log.Println("Failed to Unmarshal document with id", key)
continue
}
for _, token := range analyzer.Analyze(doc.Text) {
ids, ok := inMemoryIndex[token]
if ok && slices.Contains(ids, doc.ID) {
continue
}
inMemoryIndex[token] = append(ids, doc.ID)
}
}
wb := d.NewWriteBatch()
defer wb.Destroy()
for token, ids := range inMemoryIndex {
key := []byte(token)
values := []byte(utils.IntArrayToString(ids))
wb.PutCF(d.cfh[cfhInvertedIdx], key, values)
}
count := d.BulkSave(wb)
return count
}
In the above snippet, we iterate over every key/value pair in the documents column family handle (CFH) and we construct the inverted index in memory.
In Part 1 of the article, The following check was added to ensure that we don’t add a document id multiple times for a token.
ids := idx[token]
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(ids, doc.ID)
I had to modify the check. The initial check assumes that the ids are in ascending order, so by always checking the last item in the ids array, it can determine whether an id has been previously added.
However, this does not work with the RocksDB because RocksDB uses SSTables i.e The ordering of the keys in the CFH is based on the string representation of the key not their numerical representation. For example, when iterating over the documents CFH, a document with id of 17 comes before one with id of 2.
This is similar to sorting an array of numbers in javascript without passing a comparator function to ascertain the sort order.

Therefore, I opted to use slices.Contains for the check. It goes without saying that this increased the runtime complexity from O(n^2) to O(n^3). After the inverted index has been built in memory, we initialise a write batch to commit all the changes to the database just like we did earlier in the loadDocuments function.
As stated earlier, RocksDB is a key/value store where the key and values are arbitrary sized bytes, our index is a hashmap where the key is a string and the value is an integer slice.
inMemoryIndex := make(map[string][]int)
So we need to serialize both the keys and values into bytes. I created a helper to convert the integer slice into a string.
// utils/utils.go
func IntArrayToString(numbers []int) string {
str := make([]string, len(numbers))
for i, number := range numbers {
str[i] = strconv.Itoa(number)
}
return strings.Join(str, separator)
}
The string values are further converted to bytes which can be saved in the database.
key := []byte(token)
values := []byte(utils.IntArrayToString(ids))
wb.PutCF(d.cfh[cfhInvertedIdx], key, values)
Similar to the loadDocuments function, We use a write batch to commit the inverted index keys/values to the database. The entire index building process takes about 19 seconds.
Searching
Now that the documents and the inverted index are both saved to disk, The application is ready to start accepting search queries. The search functionality is exposed over an http interface and it accepts parameters like:
Query - The search term
Exact - A boolean to indicate if we want exact matches or not. In the case of non-exact (i.e partial) matches, the results will be assigned a score and ranked in descending order— from the closest matches to the furthest. (default to false)
Page - for Pagination purposes (defaults to 1)
Limit - The number of results to return per page (defaults to 100)
// engine/engine.go
type SearchParams struct {
Page int
Limit int
Query string
Exact bool
}
type SearchResults struct {
Meta struct {
Count int `json:"totalResultsCount"`
PageCount int `json:"currentPageCount"`
TimeTakenSecs string `json:"timeTaken"`
Query string `json:"searchQuery"`
Page int `json:"page"`
Limit int `json:"limit"`
} `json:"meta"`
Data []index.Document `json:"data"`
}
func (f *FtsEngine) Search(params *SearchParams) []byte {
startTime := time.Now()
docs := f.index.GetCachedSearchResults(params.Query, params.Exact)
if len(docs) == 0 {
docs = f.getDocs(params.Query, params.Exact)
// save search results for caching and pagination purposes
f.index.CacheSearchResults(params.Query, docs, params.Exact)
}
results := SearchResults{}
start := (params.Page - 1) * params.Limit
end := start + params.Limit
// handle out of bounds
if end > len(docs) {
end = len(docs)
if start > end {
start = end
}
}
results.Data = docs[start:end]
results.Meta.Count = len(docs)
results.Meta.Query = params.Query
results.Meta.Limit = params.Limit
results.Meta.Page = params.Page
results.Meta.PageCount = len(results.Data)
results.Meta.TimeTakenSecs = fmt.Sprintf("%.9f seconds", time.Since(startTime).Seconds())
res, err := json.Marshal(results)
if err != nil {
log.Println("Failed to json.Marshal results", err)
return make([]byte, 0)
}
return res
}
We check the search results table if we’ve previously searched and cached the results for the search parameters, if there’s a cache hit, we use the cached result.
// index/index.go
func (d *Index) GetCachedSearchResults(query string, exact bool) []Document {
key := getSearchResultKey(query, exact)
val, _ := d.db.GetCF(d.ro, d.cfh[cfhSearchResults], []byte(key))
defer val.Free()
var docs []Document
if val.Exists() {
json.Unmarshal(val.Data(), &docs)
}
return docs
}
Otherwise we search the inverted index, retrieve the documents and cache it.
// index/index.go
func (f *FtsEngine) getDocs(text string, exactResults bool) []index.Document {
var r []int
searchTokens := analyzer.Analyze(text)
for _, token := range searchTokens {
val := f.index.GetFromInvertedIndex(token)
if val == "" {
continue
}
ids := utils.StringToIntArray(val)
if r == nil {
r = ids
} else {
if exactResults {
r = utils.Intersection(r, ids) // exact matches
} else {
r = append(r, ids...) // partial to exact matches
}
}
}
docs := []index.Document{}
for _, id := range r {
doc, err := f.index.GetDocument(strconv.Itoa(id))
if err != nil {
log.Printf("Failed to retrieve docId: %v , err: %s \n", id, err)
continue
}
// assign default rank
doc.Rank = 1
docs = append(docs, doc)
}
// no need to rank if results are exact matches
if exactResults {
return docs
}
return f.rankResults(docs, searchTokens)
}
For partial matches, we rank the results by how close they are to the search term.
func (f *FtsEngine) rankResults(docs []index.Document, searchTokens []string) []index.Document {
// for each document, calculate the relevance by counting the amount of
// searchTokens that can be found in the document.Text
for i := range docs {
score := 0
resultTokens := analyzer.Analyze(docs[i].Text)
resultTokensMap := make(map[string]bool)
for _, resultToken := range resultTokens {
resultTokensMap[resultToken] = true
}
for _, searchToken := range searchTokens {
if _, exists := resultTokensMap[searchToken]; exists {
score++
}
}
docs[i].Rank = (float64(score) / float64(len(searchTokens)))
}
// order by relevance...
sort.Slice(docs, func(i, j int) bool {
return docs[i].Rank > docs[j].Rank
})
return docs
}
Exposing the Search functionality via a HTTP Server
// main.go
func main() {
pathToDump := flag.String("path", "<path_to_wikipedia_archive_dump>", "Path to dump file")
port := flag.String("port", "5000", "The server port")
dataDir := flag.String("dataDir", "data", "the directory where the index should be saved")
flag.Parse()
ftsEngine, err := engine.New(*pathToDump, *dataDir)
if err != nil {
log.Fatal("Failed to build index:", err)
}
server.Start(ftsEngine, *port)
}
// server/server.go
func Start(e *engine.FtsEngine, port string) {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
searchTerm := r.URL.Query().Get("q")
exact := r.URL.Query().Get("exact")
page, pageErr := strconv.Atoi(r.URL.Query().Get("page"))
limit, limitErr := strconv.Atoi(r.URL.Query().Get("limit"))
if pageErr != nil {
page = 1
}
if limitErr != nil {
limit = 100
}
if searchTerm == "" {
w.WriteHeader(http.StatusBadRequest)
w.Write([]byte("Search term cannot be blank"))
return
}
w.Header().Set("Content-Type", "application/json")
params := &engine.SearchParams{
Page: page,
Limit: limit,
Query: searchTerm,
Exact: exact == "true",
}
w.Write(e.Search(params))
})
http.HandleFunc("/stats", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json")
w.Write(e.GetStats())
})
log.Printf("Server is up and running 🚀🚀🚀 on %s \n", port)
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%s", port), nil))
}
We create and expose two endpoints on the http server.
Searching - To execute search queries
Stats - To retrieve stats such the amount of documents, tokens and other metadata
Our application is complete and we can now serve requests over http. To start the app, run the start.sh script. You should ensure the value of the -path flag matches the name of the wikipedia dump file you downloaded. I renamed the wikipedia dump file I downloaded to dump.gz on my end.
go run fts.io -port=3000 -path=./dump.gz -dataDir=data
Running the application for the first time takes about 40 seconds to load the documents and build the index.
➜ fts git:(main) ✗ ./start.sh
2024/10/05 14:34:57 Starting...
🌓 Loading Documents...2024/10/05 14:35:15
684495 Documents loaded in 18.033509875s ✅✅
🌘 Building Index...2024/10/05 14:35:34
Index built in 18.568278209s ✅✅. No of tokens = 291503
2024/10/05 14:35:34 Server is up and running 🚀🚀🚀 on 3000
Subsequent runs are are under 40 milliseconds since the documents and index have been previously saved to disk.
➜ fts git:(main) ✗ ./start.sh
2024/10/05 14:37:36 Starting...
2024/10/05 14:37:36 Documents already loaded in database at Sat Oct 5 14:35:15 CEST 2024. Skipping ⏭️⏭️
2024/10/05 14:37:36 Documents count = 684495
2024/10/05 14:37:36 Index was built at Sat Oct 5 14:35:33 CEST 2024, skipping ⏭️⏭️
2024/10/05 14:37:36 Index contains 291503 tokens
2024/10/05 14:37:36 Server is up and running 🚀🚀🚀 on 3000
Testing the Endpoints
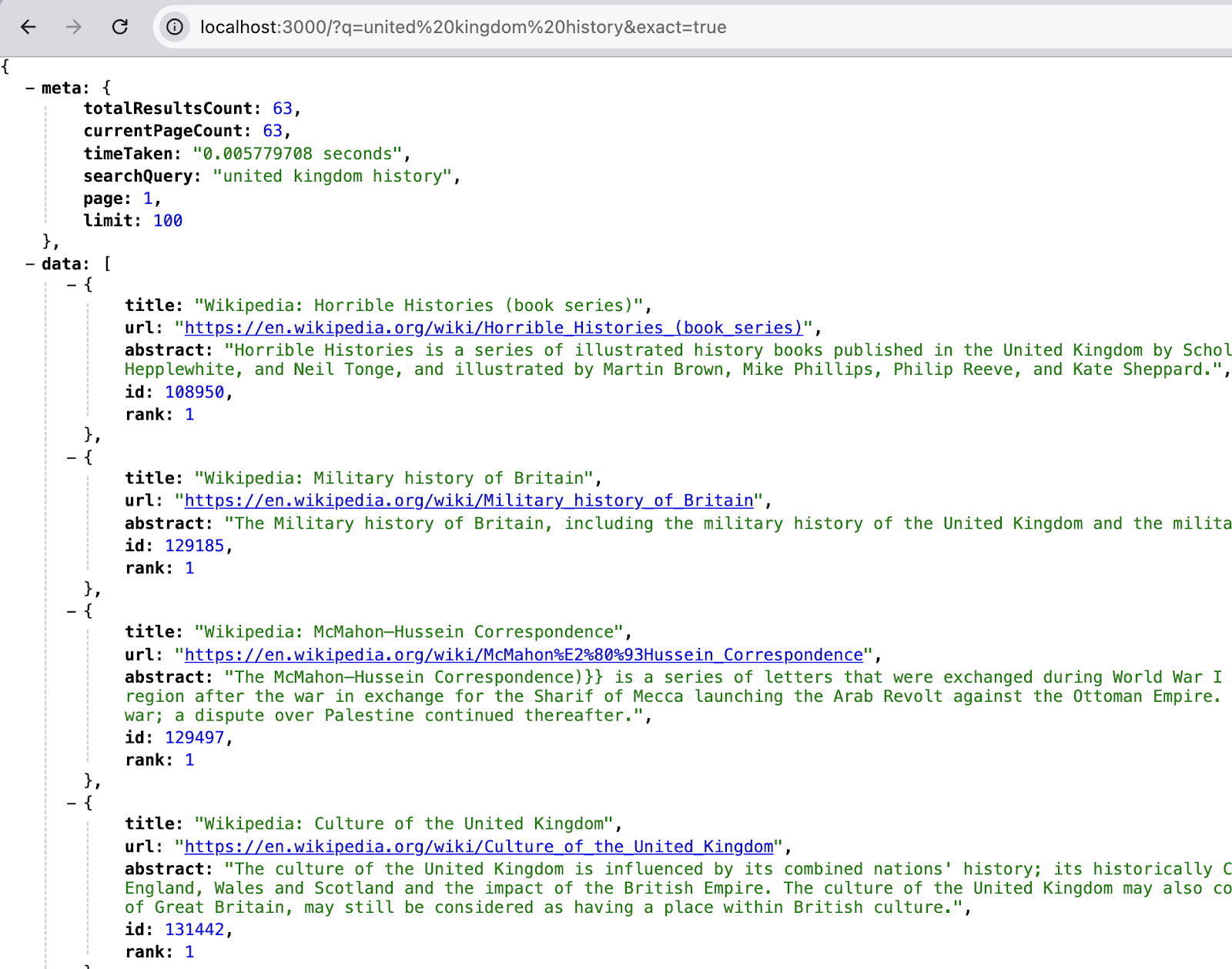
Querying for q=united kingdom history and exact=true parameter
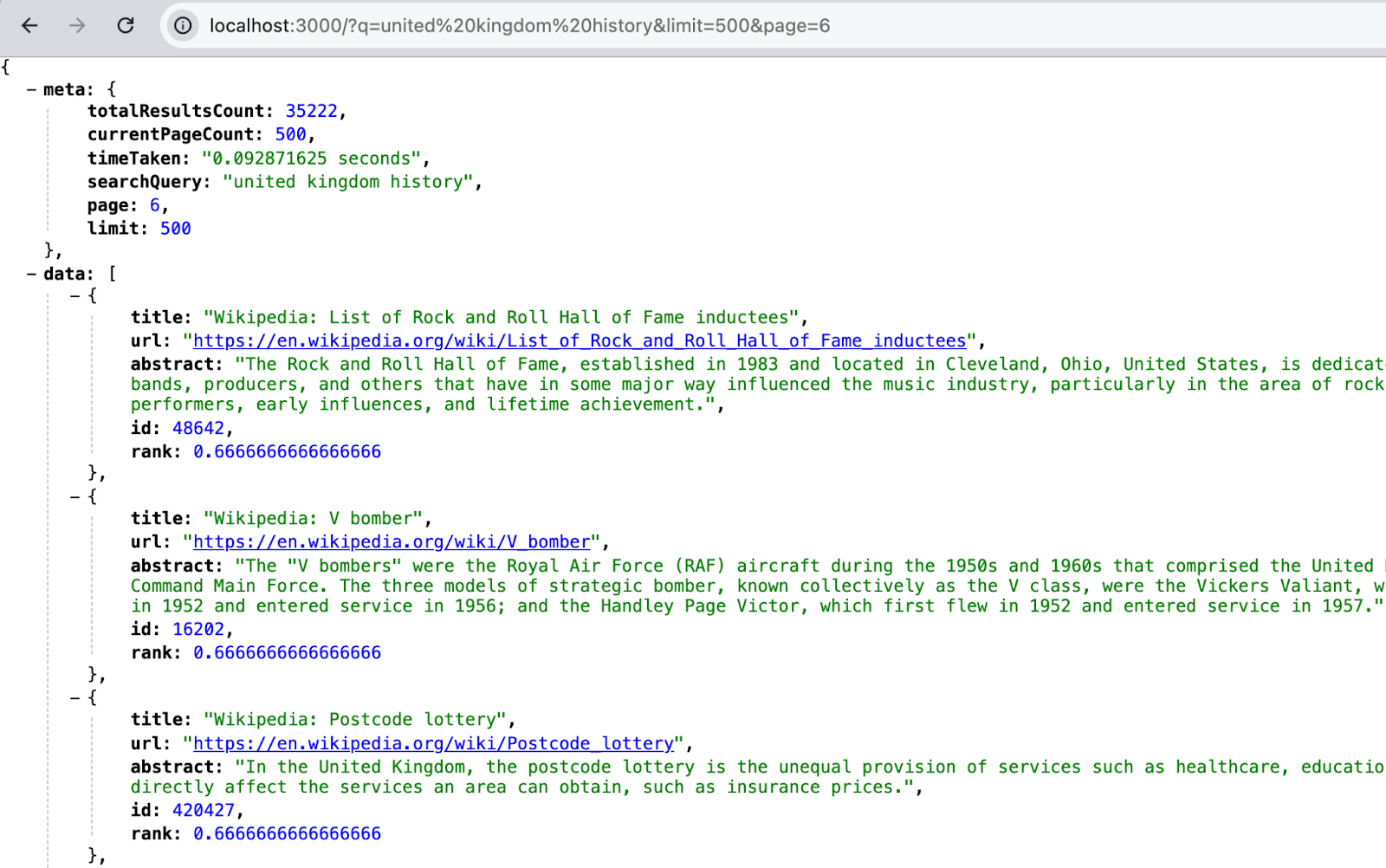
Querying for q=united kingdom history, page=6 and limit=500
Querying the stats endpoint

Improvements
Consider using custom comparators for storing keys in the documents CFH. This way, document IDs can be retrieved in chronological order, helping to avoid the O(n^3) runtime when building the index.
Improve result ranking to account for tokens that do not exist in our inverted index.
Expose a data ingestion endpoint for adding and indexing new documents
Invalidate cached search results
Optimize/reduce the number of serialization/deserialization operations. There’s quite a number of
json.Marshalandjson.UnMarshalcalls going on.
Conclusions
While searching and indexing are solved problems in the field of computer science, we can see that it gets very complex if you want to build a highly sophisticated, reliable and performant search engine software from scratch e.g Solr or Lucene/ElasticSearch or Algolia from scratch.
A simple thought exercise: Think about implementing Faceted search, real-time indexing, hit highlighting, replication, database clustering and integrations, a query language, log metrics and performance dashboards on top our current setup. IT IS A LOT
There is no free lunch. For every convenience you get out of a system, you pay for it— either in memory usage, disk usage or time.
In the original implementation where the inverted index was in memory, search queries for
“small wild cat”completed in less than0.000025 seconds (25 µs). After we persisted the index to disk. it takes0.000764758 seconds (764 µs)—more than 30x longer. Even after caching search results and reading from the database (RocksDB) , it took0.000097026 seconds (97.026 µs).RocksDB also implements it’s own in-memory LRU cache for frequent hits— not every key retrieval request is served from disk, some are retrieved from memory if available— which in turn speeds up the response time. Subsequent queries for same search term resolved within
40µs-70 µs.
bbto := grocksdb.NewDefaultBlockBasedTableOptions()
bbto.SetBlockCache(grocksdb.NewLRUCache(3 << 30))
bbto.SetBlockSize(32 << 10) // 32kB
bbto.SetFilterPolicy(grocksdb.NewBloomFilter(float64(10)))
On a barebones level, the RAM can be up to 3000 times faster than SSD but it (RAM) is ephemeral with no durability guarantee. You can also look at these latency numbers to have a general idea what should be taking how long.
Artem Krylysov,The author of part one was kind enough to leave some feedback on the initial draft. He shared some suggestions which I will be adding in a follow up post.
Subscribe to my newsletter
Read articles from Olalekan Adekola directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Olalekan Adekola
Olalekan Adekola
I am a software engineer with 5 years experience building products.