Understanding Parsers - Part 1 : Theory
 Sawez Faisal
Sawez Faisal
My introduction to parsers
So, when the Lexer of Sodum got completed i was able to generate a stream of tokens from the incoming raw source code . Now WHAT!!! , what should i do with these tokens , How do i make sense out of it , How will the machine process it . In short what should i do next was the question lying in front of me .
The answer to all these questions is a PARSER .
What is a Parser Anyway?
Let me paint a picture. Imagine you're writing some code, and all the computer sees is a huge mess of characters. Before the machine can actually do something useful with it, there’s a chain of processes. First, a lexer (or tokenizer) breaks that mess into small pieces called tokens—think of them like words in a sentence. Then, it’s the parser’s job to read those tokens and organize them into a structure that actually means something. In simpler terms, it transforms chaos into order.
For Sodum, I needed the parser to read function declarations, loops, conditions—basically all the elements you’d find in a programming language—and convert them into something I could later compile into machine code. It sounds simple on paper, but it was anything but.
Why Even Bother with a Parser?
Now, why bother with this part? Couldn't I just write some quick code that takes tokens and spits out machine instructions? The short answer is: you can't skip the parser. Without it, you’d have no way of organizing or validating the structure of your language.
When I first started writing Sodum, I didn’t fully appreciate this. I naively thought I could keep things loose, but the parser is like the skeleton of your language. It not only organizes everything but also helps enforce the rules and semantics. As I discovered, trying to build a language without a proper parser is like trying to write a novel without knowing grammar—chaotic and error-prone.
Types of parsers
Before I go deeper into my experience, let’s talk about the types of parsers out there. There are mainly two categories:
Top-Down Parsers: These parsers start from the highest-level rule in your grammar(I have talked about my grammar here →https://sawezfaisal.hashnode.dev/chapter-5-grammar-of-the-language ) and try to break it down recursively into smaller pieces. This was the approach I ended up using for Sodum. Examples include Recursive Descent Parsers (which I used) and LL Parsers.
Bottom-Up Parsers: These parsers, like LR Parsers, start from the lowest level—essentially the tokens—and build upwards. These are a bit more powerful than top-down parsers because they can handle a wider range of grammars, but they are harder to implement and maintain.
Now, when you're writing a custom language like Sodum, a top-down parser is often a good starting point because it’s easier to map out and control manually.
What is an LL(K) Parser?
Let’s get into a bit of theory now that I have your attention. You might hear people talk about LL(K) parsers when dealing with top-down parsers. So, what does LL(K) even mean? It's actually not as scary as it sounds.
L: The first L means that it reads the input from left to right.
L: The second L means that it creates a leftmost derivation, which essentially means it’s processing the input in the order it appears.
K: The K refers to how many tokens the parser looks ahead to decide what to do next. In an LL(1) parser, for instance, it looks just one token ahead.
In my case, as I was working through Sodum, I found that getting my grammar as close to LL(1) as possible made things a lot easier. It reduced the complexity of decision-making in the parser. Whenever possible, if you can stick with LL(1), it keeps the process a lot more streamlined—less ambiguity and less complexity.
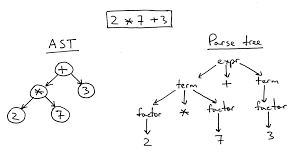
Syntax Tree vs AST (Abstract Syntax Tree)
Let’s talk trees! As I worked on Sodum, one thing became very clear—there’s a difference between a Syntax Tree and an Abstract Syntax Tree (AST). But when you're new to this, you don't really understand why they matter. So let me break it down as I learned it.
A Syntax Tree (sometimes called a Parse Tree) represents everything in your language, including all the syntactic sugar (like semicolons, parentheses, etc.). It’s like writing down every single detail of a conversation, including the "uhs" and "ums."
On the other hand, an AST simplifies things. It gets rid of all that unnecessary fluff and focuses on the core structure—just what matters for execution. It's like taking the conversation, removing all the filler words, and keeping only the important ideas. In the context of Sodum, when building the AST, I only cared about the actual operations—like function calls, conditionals, and loops—because these are the things the machine needs to know to execute the code.
Early on, I started with the idea of building a Syntax Tree, but I quickly realized an AST was much more practical. Why? Because it strips out the noise and gives you a clearer, more manageable representation of your program. As a result, i didn’t spend much time processing things that is not so important in the final output.This solely depends on the complexity and your own personal requirements for the project , and considering the fact that Sodum is more of an experiment to understand the underlying workings of a compiler and eventually a programming langauge i decided to keep things simple as of now.
Spending Some Time on Grammar Paid Off
I’ll be honest—spending some time refining the grammar was tedious, but it was the best decision I made. Initially, I had some ambiguity in my grammar, which meant the parser couldn't decide how to interpret certain sequences of tokens. And trust me, ambiguity in your grammar is like inviting bugs to a party—they’ll show up and wreak havoc.
To solve this, I decided to make my parser LL(1) or as close to it as possible. This means that the parser only needs to look at one token ahead to decide what to do next. This made my life a lot easier when writing the parser because it simplified the logic.
Syntax Tree or AST: What Worked for Sodum?
For Sodum, I chose to focus on building an AST directly. Here’s why: as I mentioned earlier, the AST cuts out the unnecessary bits and simplifies the structure. And since I knew that my parser had to generate LLVM IR later on (which is the next step in compiling the language), working with an AST gave me a cleaner way to represent the structure of my code in a form that was easy to compile down to machine code.
When I started building the parser, I realized this decision saved me a lot of headaches. I didn’t need separate nodes for things like semicolons or parentheses in the AST. Those were just syntactic sugars—the actual work was in the expressions, statements, and control flow.
My Best Approach: Top-Down and Almost LL(1)
As for the approach, I went with a top-down recursive descent parser. This is one of the simplest kinds of parsers you can build, and it’s almost like translating grammar rules directly into code. The parser starts from the highest-level rules and works its way down to the more detailed ones.
For Sodum, I structured the grammar to avoid ambiguity, which made it easier to follow the LL(1) strategy. This way, when I read tokens, I only had to look ahead one step to decide what the next step should be. It might sound overly technical, but trust me, simplifying the lookahead process makes parsing a lot smoother.
Conclusion: Your Grammar is the Backbone of Your Language
Looking back, one thing became crystal clear—getting the grammar right is the key to everything. I didn’t realize at first just how much it would influence the entire process. If your grammar is ambiguous or too complex, your parser is going to struggle, and so will you. It’s not just about making the parser work; it’s about making sure that when you add new features down the road, your language doesn’t fall apart.
I spent a lot of time fine-tuning the grammar for Sodum, and I’m glad I did. It made building the parser so much easier. More importantly, it gave me a solid foundation to build on as I continue developing the language. If I had skipped this step or rushed through it, I’m sure I’d be dealing with endless bugs right now.
In the next part, I’ll dive into the actual code and walk you through how I implemented the parser, how I structured the different parts of the AST, and how I handled those inevitable errors that crop up. But if there’s one thing I’d recommend to anyone starting out: take the time to really get your grammar right. It might feel slow at first, but it will make everything that follows so much easier—and your future self will definitely thank you.
Subscribe to my newsletter
Read articles from Sawez Faisal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sawez Faisal
Sawez Faisal
New to the field and eager to learn how complex systems work smoothly. From building compilers to scalable systems, I’m solving problems as they come—whatever the domain—and sharing all the highs, lows, and lessons along the way!