Hash Tables: Finding Duplicates in an Array | Day #19
 Bonaventure Ogeto
Bonaventure Ogeto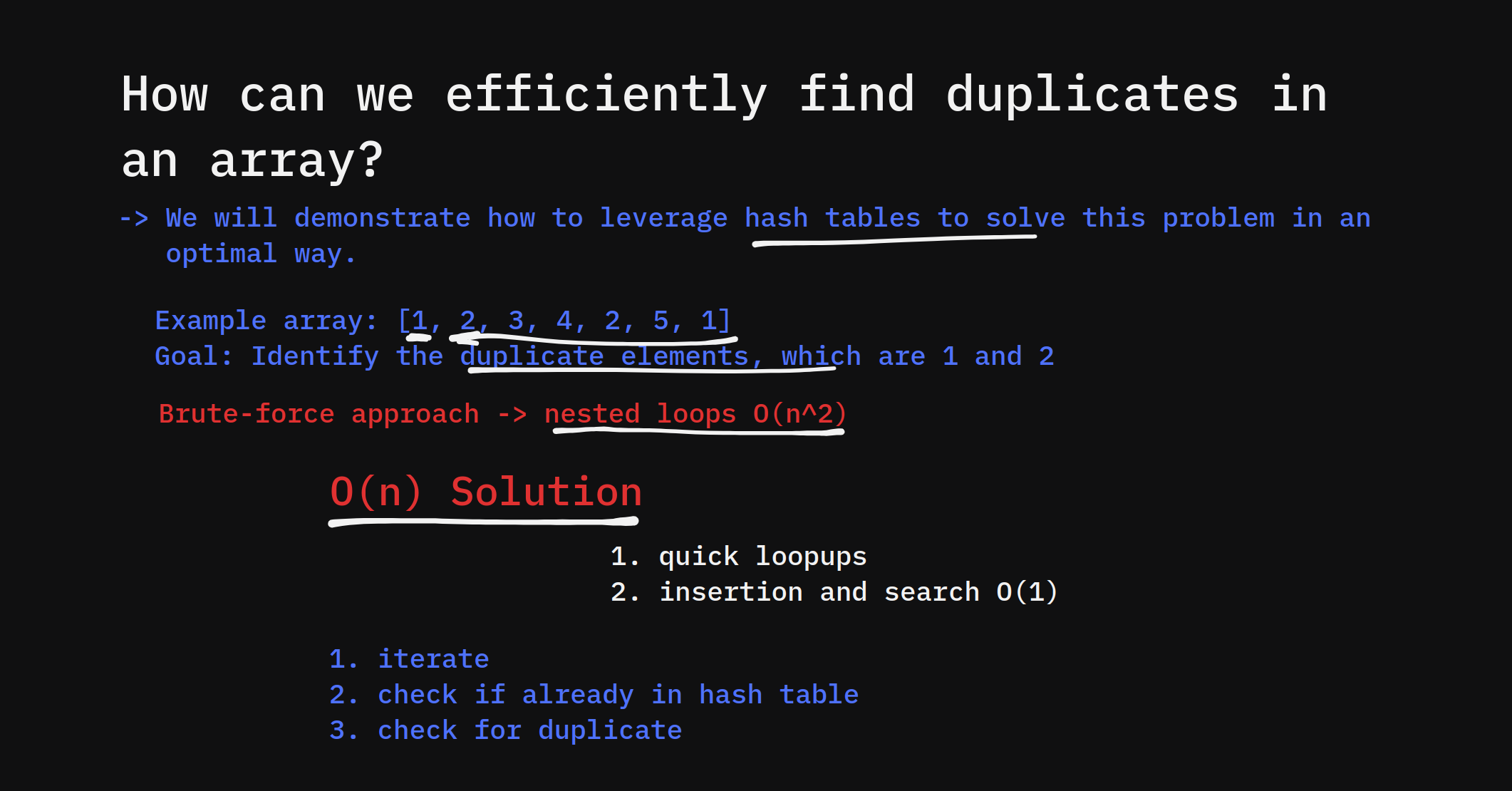
Introduction
Finding duplicates in an array is a common problem in software development, with applications ranging from detecting repeated data entries in databases to validating user inputs in forms. In large datasets, identifying duplicates efficiently is crucial, as traditional approaches like brute force comparison can be too slow.
A hash table provides a highly efficient way to solve this problem. By leveraging the O(1) time complexity of hash table operations, we can quickly track elements and identify duplicates with minimal overhead. If you’re new to hash tables, be sure to check out our YouTube video on What is a hash table? for more context.
In this guide, we’ll explore how hash tables can efficiently find duplicates, walk through implementation in Python and JavaScript, and cover real-world use cases and edge cases.
How Hash Tables Help Identify Duplicates
A hash table stores data as key-value pairs, where each key corresponds to an element and maps to a specific memory location through a hash function. This structure allows for constant time lookups and insertions, making it ideal for tracking elements in an array as you traverse it.
Logic Behind the Approach
To find duplicates, follow these steps:
Initialize an empty hash table.
Traverse the array element by element.
For each element:
If the element is already in the hash table, it’s a duplicate.
If the element is not in the hash table, add it.
This algorithm ensures that every element is checked only once, making it very efficient.
Algorithm Overview
Here’s a step-by-step breakdown:
Initialize an empty hash table (can be an object or dictionary).
Iterate through the array.
Check if the element exists in the hash table:
If it exists, add it to the duplicates list.
If it doesn’t exist, store it in the hash table.
Return the duplicates list at the end.
Using a hash table allows us to avoid costly nested loops and detect duplicates in O(n) time.
Code Implementation
Below are code examples in Python and JavaScript to demonstrate how to implement this solution.
Python Code Example
def find_duplicates(arr):
hash_table = {} # Initialize an empty hash table
duplicates = [] # Store found duplicates
for num in arr:
if num in hash_table:
duplicates.append(num) # Add duplicate to the list
else:
hash_table[num] = True # Insert the element in the hash table
return duplicates
# Test the function
print(find_duplicates([1, 2, 3, 2, 4, 3])) # Output: [2, 3]
JavaScript Code Example
function findDuplicates(arr) {
const hashTable = {}; // Initialize an empty hash table
const duplicates = []; // Store found duplicates
arr.forEach(num => {
if (hashTable[num]) {
duplicates.push(num); // Add duplicate to the list
} else {
hashTable[num] = true; // Insert the element in the hash table
}
});
return duplicates;
}
// Test the function
console.log(findDuplicates([1, 2, 3, 2, 4, 3])); // Output: [2, 3]
Both examples demonstrate a simple approach using hash tables to find duplicates in O(n) time. You can read more about the time complexity of hash tables in our detailed guide on How hash tables work.
Time Complexity Analysis
Using a hash table for finding duplicates provides optimal performance.
Time Complexity:
Insertion and lookup in a hash table take O(1) on average.
Traversing the array takes O(n), where n is the size of the array.
Therefore, the overall time complexity is O(n).
Space Complexity:
- A hash table requires O(n) space in the worst case to store all elements.
This makes hash tables an ideal solution for large datasets where performance is critical.
Edge Cases
It’s essential to handle special scenarios to ensure your code works in all situations:
Empty Arrays:
Input:
[]Output:
[]Explanation: No elements mean no duplicates.
Arrays with Unique Elements:
Input:
[1, 2, 3, 4]Output:
[]Explanation: All elements are unique, so no duplicates are found.
Arrays with Large Datasets:
- When handling large arrays, ensure that your hash function distributes elements evenly to avoid collisions. For more on this, see our article on hash table collision handling.
Real-World Use Cases
Hash tables are extensively used in practical applications for duplicate detection, including:
E-commerce platforms: Detecting repeated product listings in carts or catalogs.
Web forms: Ensuring users don't submit duplicate registrations or responses.
Database management: Identifying redundant entries to maintain data integrity.
These use cases highlight how hash tables provide efficient and practical solutions in everyday programming tasks.
Conclusion
Using hash tables to find duplicates in an array is a fast and efficient approach, especially for large datasets. By leveraging the O(1) lookup time, you can quickly determine if an element has been seen before and avoid expensive nested loops.
If you’re interested in exploring more about hash tables, check out:
Call to Action
Now that you’ve learned how to use hash tables to find duplicates, try implementing the solution from scratch with different datasets and explore how the performance varies. You can also experiment with alternative methods like sorting-based duplicate detection.
Feel free to share your results and questions in the comments section, and dive deeper into the world of hash tables!
Subscribe to my newsletter
Read articles from Bonaventure Ogeto directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bonaventure Ogeto
Bonaventure Ogeto
Software Engineer & Technical Writer