Building a Production-Ready RAG Chatbot with FastAPI and LangChain
 Pradip Nichite
Pradip Nichite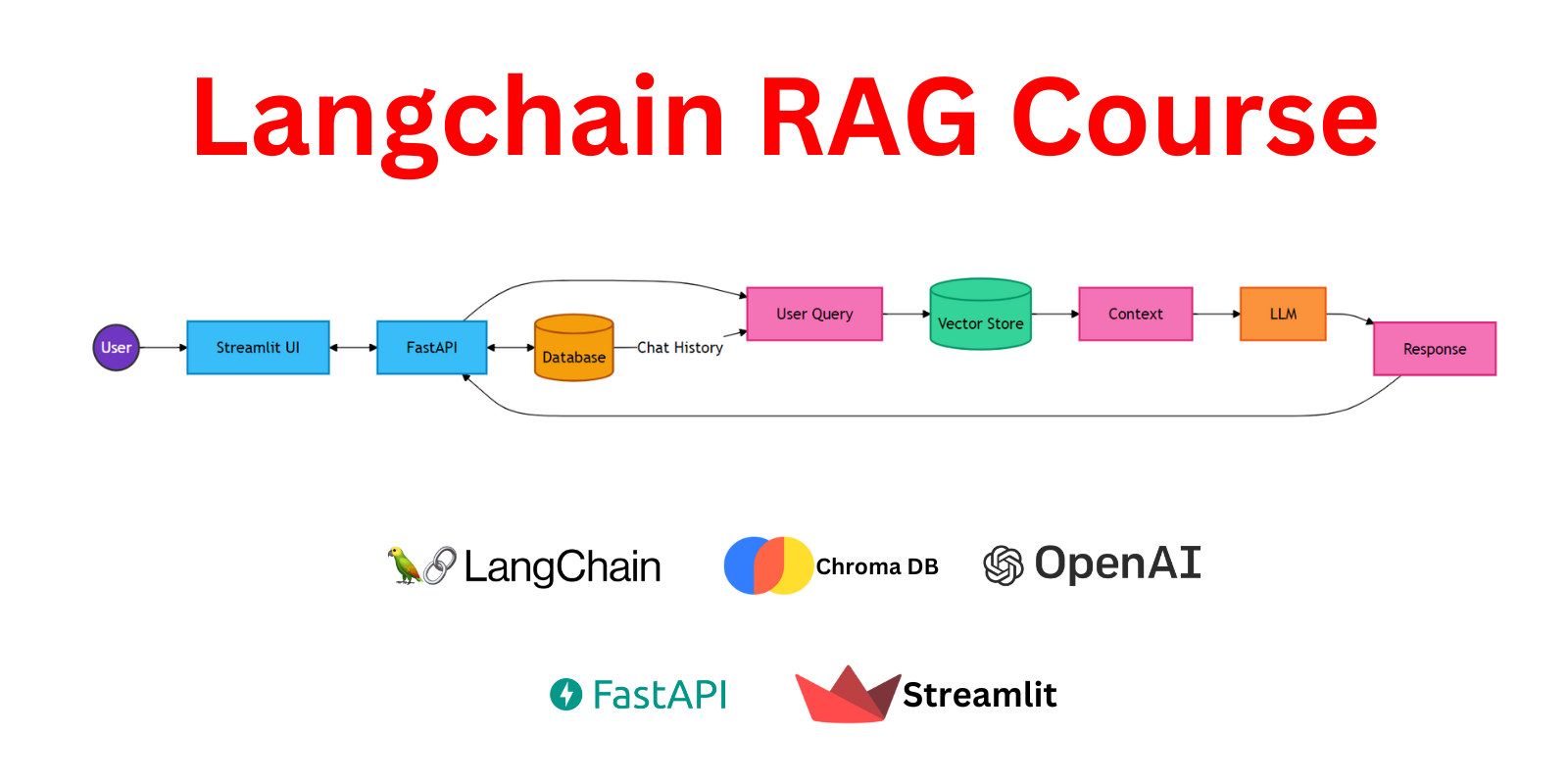
Introduction
In our previous article, we delved into the fundamentals of Retrieval-Augmented Generation (RAG) using LangChain. We explored the core concepts, built a basic RAG system, and demonstrated its capabilities in a Jupyter notebook environment. While this approach is excellent for prototyping and understanding the underlying mechanics, it's not quite ready for real-world applications.
Today, we're taking the next crucial step: transforming our RAG prototype into a production-ready API. We'll be using FastAPI, a modern, fast (high-performance) web framework for building APIs with Python. FastAPI is particularly well-suited for our needs due to its speed, ease of use, and built-in support for asynchronous programming.
What We'll Build
In this tutorial, we'll create a robust API that offers the following functionalities:
A chat endpoint that processes queries using our RAG system
Document upload and indexing capabilities
Ability to list and delete indexed documents
Proper error handling and logging
We'll structure our application in a modular, maintainable way, making it easy to extend and deploy in a production environment.
Prerequisites
Before we dive in, make sure you have the following:
Basic understanding of Python and asynchronous programming
Familiarity with RESTful APIs
Knowledge of RAG systems and LangChain (covered in Part 1 of this series)
Python 3.8+ installed on your system
pip for installing required packages
Project Setup
First, let's set up our project environment. Create a new directory for your project and navigate into it:
mkdir rag-fastapi-project
cd rag-fastapi-project
Now, let's install the necessary packages. Create a requirements.txt file with the following content:
langchain
langchain-openai
langchain-core
langchain_community
docx2txt
pypdf
langchain_chroma
python-multipart
fastapi
uvicorn
Install these packages using pip:
pip install -r requirements.txt
With our environment set up, we're ready to start building our production-ready RAG chatbot API. In the next section, we'll dive into the project structure and begin implementing our FastAPI application.
Certainly! Let's move on to the next section, where we'll discuss the project structure overview. This section will help readers understand how we're organizing our code for better maintainability and scalability.
Project Structure Overview
When transitioning from a prototype to a production-ready application, proper code organization becomes crucial. A well-structured project is easier to maintain, test, and extend. For our RAG chatbot API, we'll use a modular structure that separates concerns and promotes code reusability.
Here's an overview of our project structure:
rag-fastapi-project/
│
├── main.py
├── chroma_utils.py
├── db_utils.py
├── langchain_utils.py
├── pydantic_models.py
├── requirements.txt
└── chroma_db/ (directory for Chroma persistence)
Let's break down the purpose of each file:
main.py: This is the entry point of our FastAPI application. It defines the API routes and orchestrates the different components of our system.chroma_utils.py: Contains utilities for interacting with the Chroma vector store, including functions for indexing documents and performing similarity searches.db_utils.py: Handles database operations, including storing and retrieving chat history and document metadata.langchain_utils.py: Encapsulates the LangChain-specific logic, such as creating the RAG chain and configuring the language model.pydantic_models.py: Defines Pydantic models for request and response validation, ensuring type safety and clear API contracts.requirements.txt: Lists all the Python packages required for the project.
Benefits of This Structure
Separation of Concerns: Each file has a specific responsibility, making the code easier to understand and maintain.
Modularity: Components can be developed and tested independently, facilitating collaboration and reducing the risk of conflicts.
Scalability: As the project grows, new functionalities can be added by introducing new modules without significantly altering existing code.
Reusability: Utility functions and models can be easily reused across different parts of the application.
Readability: With clear file names and separated concerns, new developers can quickly understand the project structure and locate specific functionalities.
This structure follows best practices for FastAPI applications and provides a solid foundation for building our RAG chatbot API. As we progress through the tutorial, we'll dive into each of these files, explaining their contents and how they work together to create our production-ready system.
Setting Up the FastAPI Application
The main.py file is the core of our FastAPI application. It defines our API endpoints and orchestrates the interaction between different components of our system. Let's break down the key elements of this file:
from fastapi import FastAPI, File, UploadFile, HTTPException
from pydantic_models import QueryInput, QueryResponse, DocumentInfo, DeleteFileRequest
from langchain_utils import get_rag_chain
from db_utils import insert_application_logs, get_chat_history, get_all_documents, insert_document_record, delete_document_record
from chroma_utils import index_document_to_chroma, delete_doc_from_chroma
import os
import uuid
import logging
import shutil
# Set up logging
logging.basicConfig(filename='app.log', level=logging.INFO)
# Initialize FastAPI app
app = FastAPI()
Here, we import necessary modules and initialize our FastAPI application. We've also set up basic logging to keep track of important events in our application.
Defining API Endpoints
Now, let's look at our main API endpoints:
- Chat Endpoint:
@app.post("/chat", response_model=QueryResponse)
def chat(query_input: QueryInput):
session_id = query_input.session_id or str(uuid.uuid4())
logging.info(f"Session ID: {session_id}, User Query: {query_input.question}, Model: {query_input.model.value}")
chat_history = get_chat_history(session_id)
rag_chain = get_rag_chain(query_input.model.value)
answer = rag_chain.invoke({
"input": query_input.question,
"chat_history": chat_history
})['answer']
insert_application_logs(session_id, query_input.question, answer, query_input.model.value)
logging.info(f"Session ID: {session_id}, AI Response: {answer}")
return QueryResponse(answer=answer, session_id=session_id, model=query_input.model)
This endpoint handles chat interactions. It generates a session ID if not provided, retrieves chat history, invokes the RAG chain to generate a response, logs the interaction, and returns the response.
- Document Upload Endpoint:
@app.post("/upload-doc")
def upload_and_index_document(file: UploadFile = File(...)):
allowed_extensions = ['.pdf', '.docx', '.html']
file_extension = os.path.splitext(file.filename)[1].lower()
if file_extension not in allowed_extensions:
raise HTTPException(status_code=400, detail=f"Unsupported file type. Allowed types are: {', '.join(allowed_extensions)}")
temp_file_path = f"temp_{file.filename}"
try:
# Save the uploaded file to a temporary file
with open(temp_file_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
file_id = insert_document_record(file.filename)
success = index_document_to_chroma(temp_file_path, file_id)
if success:
return {"message": f"File {file.filename} has been successfully uploaded and indexed.", "file_id": file_id}
else:
delete_document_record(file_id)
raise HTTPException(status_code=500, detail=f"Failed to index {file.filename}.")
finally:
if os.path.exists(temp_file_path):
os.remove(temp_file_path)
This endpoint handles document uploads. It checks for allowed file types, saves the file temporarily, indexes it in Chroma, and updates the document record in the database.
- List Documents Endpoint:
@app.get("/list-docs", response_model=list[DocumentInfo])
def list_documents():
return get_all_documents()
This simple endpoint returns a list of all indexed documents.
- Delete Document Endpoint:
@app.post("/delete-doc")
def delete_document(request: DeleteFileRequest):
chroma_delete_success = delete_doc_from_chroma(request.file_id)
if chroma_delete_success:
db_delete_success = delete_document_record(request.file_id)
if db_delete_success:
return {"message": f"Successfully deleted document with file_id {request.file_id} from the system."}
else:
return {"error": f"Deleted from Chroma but failed to delete document with file_id {request.file_id} from the database."}
else:
return {"error": f"Failed to delete document with file_id {request.file_id} from Chroma."}
This endpoint handles document deletion, removing the document from both Chroma and the database.
Data Models with Pydantic
Pydantic is a data validation library that uses Python type annotations to define data schemas. In our FastAPI application, we use Pydantic models to define the structure of our request and response data. Let's break down the models defined in pydantic_models.py:
from pydantic import BaseModel, Field
from enum import Enum
from datetime import datetime
class ModelName(str, Enum):
GPT4_O = "gpt-4o"
GPT4_O_MINI = "gpt-4o-mini"
class QueryInput(BaseModel):
question: str
session_id: str = Field(default=None)
model: ModelName = Field(default=ModelName.GPT4_O_MINI)
class QueryResponse(BaseModel):
answer: str
session_id: str
model: ModelName
class DocumentInfo(BaseModel):
id: int
filename: str
upload_timestamp: datetime
class DeleteFileRequest(BaseModel):
file_id: int
Let's examine each model and its purpose:
ModelName(Enum):This enum defines the available language models for our RAG system.
Using an enum ensures that only valid model names can be used.
QueryInput:Represents the input for a chat query.
question: The user's question (required).session_id: Optional session ID. If not provided, one will be generated.model: The language model to use, defaulting to GPT4_O_MINI.
QueryResponse:Represents the response to a chat query.
answer: The generated answer.session_id: The session ID (useful for continuing conversations).model: The model used to generate the response.
DocumentInfo:Represents metadata about an indexed document.
id: Unique identifier for the document.filename: Name of the uploaded file.upload_timestamp: When the document was uploaded and indexed.
DeleteFileRequest:Represents a request to delete a document.
file_id: The ID of the document to be deleted.
Using Pydantic Models in FastAPI
In our main.py, we use these models to define the shape of our request and response data. For example:
@app.post("/chat", response_model=QueryResponse)
def chat(query_input: QueryInput):
# Function implementation
Here, FastAPI uses QueryInput to validate the incoming request data and QueryResponse to validate and serialize the response. This ensures that our API behaves consistently and provides clear error messages when invalid data is provided.
Extensibility
As our API grows, we can easily extend these models. For instance, if we want to add more metadata to our document info, we can simply add fields to the DocumentInfo model:
class DocumentInfo(BaseModel):
id: int
filename: str
upload_timestamp: datetime
file_size: int # New field
content_type: str # New field
FastAPI and Pydantic will automatically handle the new fields, providing validation and documentation without any changes to our endpoint logic.
By using Pydantic models, we've created a robust foundation for our API, ensuring data integrity and providing clear contracts for our endpoints. This approach significantly reduces the amount of manual validation code we need to write and helps prevent bugs related to incorrect data handling.
Managing Documents and Chat History
The db_utils.py file contains functions for interacting with our SQLite database. We use SQLite for its simplicity and ease of setup, making it perfect for prototyping and small to medium-scale applications. Let's break down the key components of this file:
import sqlite3
from datetime import datetime
DB_NAME = "rag_app.db"
def get_db_connection():
conn = sqlite3.connect(DB_NAME)
conn.row_factory = sqlite3.Row
return conn
We start by importing the necessary modules and defining our database name. The get_db_connection() function creates a connection to our SQLite database, setting the row factory to sqlite3.Row for easier data access.
Creating Database Tables
def create_application_logs():
conn = get_db_connection()
conn.execute('''CREATE TABLE IF NOT EXISTS application_logs
(id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id TEXT,
user_query TEXT,
gpt_response TEXT,
model TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP)''')
conn.close()
def create_document_store():
conn = get_db_connection()
conn.execute('''CREATE TABLE IF NOT EXISTS document_store
(id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
upload_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP)''')
conn.close()
These functions create our two main tables:
application_logs: Stores chat history and model responses.document_store: Keeps track of uploaded documents.
Managing Chat Logs
def insert_application_logs(session_id, user_query, gpt_response, model):
conn = get_db_connection()
conn.execute('INSERT INTO application_logs (session_id, user_query, gpt_response, model) VALUES (?, ?, ?, ?)',
(session_id, user_query, gpt_response, model))
conn.commit()
conn.close()
def get_chat_history(session_id):
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute('SELECT user_query, gpt_response FROM application_logs WHERE session_id = ? ORDER BY created_at', (session_id,))
messages = []
for row in cursor.fetchall():
messages.extend([
{"role": "human", "content": row['user_query']},
{"role": "ai", "content": row['gpt_response']}
])
conn.close()
return messages
These functions handle inserting new chat logs and retrieving chat history for a given session. The chat history is formatted to be easily usable by our RAG system.
Managing Document Records
def insert_document_record(filename):
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute('INSERT INTO document_store (filename) VALUES (?)', (filename,))
file_id = cursor.lastrowid
conn.commit()
conn.close()
return file_id
def delete_document_record(file_id):
conn = get_db_connection()
conn.execute('DELETE FROM document_store WHERE id = ?', (file_id,))
conn.commit()
conn.close()
return True
def get_all_documents():
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute('SELECT id, filename, upload_timestamp FROM document_store ORDER BY upload_timestamp DESC')
documents = cursor.fetchall()
conn.close()
return [dict(doc) for doc in documents]
These functions handle CRUD operations for document records:
Inserting new document records
Deleting document records
Retrieving all document records
Initialization
At the end of the file, we initialize our database tables:
# Initialize the database tables
create_application_logs()
create_document_store()
This ensures that our tables are created when the application starts, if they don't already exist.
By centralizing our database operations in db_utils.py, we maintain a clean separation of concerns. Our main application logic doesn't need to worry about the details of database interactions, making the code more modular and easier to maintain.
In a production environment, you might consider using an ORM (Object-Relational Mapping) library like SQLAlchemy for more complex database operations and better scalability. However, for our current needs, this straightforward SQLite implementation serves well.
Vector Store Integration
The chroma_utils.py file contains functions for interacting with the Chroma vector store, which is essential for our RAG system's retrieval capabilities. Let's break down the key components of this file:
from langchain_community.document_loaders import PyPDFLoader, Docx2txtLoader, UnstructuredHTMLLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from typing import List
from langchain_core.documents import Document
import os
# Initialize text splitter and embedding function
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, length_function=len)
embedding_function = OpenAIEmbeddings()
# Initialize Chroma vector store
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=embedding_function)
Here, we import necessary modules and initialize our text splitter, embedding function, and Chroma vector store. The RecursiveCharacterTextSplitter is used to split documents into manageable chunks, while OpenAIEmbeddings provides the embedding function for our documents.
Document Loading and Splitting
def load_and_split_document(file_path: str) -> List[Document]:
if file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
elif file_path.endswith('.docx'):
loader = Docx2txtLoader(file_path)
elif file_path.endswith('.html'):
loader = UnstructuredHTMLLoader(file_path)
else:
raise ValueError(f"Unsupported file type: {file_path}")
documents = loader.load()
return text_splitter.split_documents(documents)
This function handles loading different document types (PDF, DOCX, HTML) and splitting them into chunks. It uses the appropriate loader based on the file extension and then applies our text splitter to create manageable document chunks.
Indexing Documents
def index_document_to_chroma(file_path: str, file_id: int) -> bool:
try:
splits = load_and_split_document(file_path)
# Add metadata to each split
for split in splits:
split.metadata['file_id'] = file_id
vectorstore.add_documents(splits)
return True
except Exception as e:
print(f"Error indexing document: {e}")
return False
This function takes a file path and a file ID, loads and splits the document, adds metadata (file ID) to each split, and then adds these document chunks to our Chroma vector store. The metadata allows us to link vector store entries back to our database records.
Deleting Documents
def delete_doc_from_chroma(file_id: int):
try:
docs = vectorstore.get(where={"file_id": file_id})
print(f"Found {len(docs['ids'])} document chunks for file_id {file_id}")
vectorstore._collection.delete(where={"file_id": file_id})
print(f"Deleted all documents with file_id {file_id}")
return True
except Exception as e:
print(f"Error deleting document with file_id {file_id} from Chroma: {str(e)}")
return False
This function deletes all document chunks associated with a given file ID from the Chroma vector store. It first retrieves the documents to confirm their existence, then performs the deletion.
Integration with RAG System
While not explicitly shown in this file, the Chroma vector store is crucial for our RAG system's retrieval step. In langchain_utils.py, we use this vector store to create a retriever:
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
This retriever is then used in our RAG chain to fetch relevant document chunks based on the user's query.
By centralizing our vector store operations in chroma_utils.py, we maintain a clean separation of concerns and make it easier to swap out or upgrade our vector store implementation in the future if needed.
LangChain RAG Implementation
The langchain_utils.py file is where we implement the core of our Retrieval-Augmented Generation (RAG) system using LangChain. This file sets up the language model, retriever, and the RAG chain. Let's break down its key components:
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from typing import List
from langchain_core.documents import Document
import os
from chroma_utils import vectorstore
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
output_parser = StrOutputParser()
Here, we import necessary LangChain components and set up our retriever using the Chroma vectorstore we created earlier. We also initialize a string output parser for processing the language model's output.
Setting Up Prompts
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
])
qa_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Use the following context to answer the user's question."),
("system", "Context: {context}"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
We define two main prompts:
contextualize_q_prompt: Used to reformulate the user's question based on chat history.qa_prompt: Used to generate the final answer based on the retrieved context and chat history.
Creating the RAG Chain
def get_rag_chain(model="gpt-4o-mini"):
llm = ChatOpenAI(model=model)
history_aware_retriever = create_history_aware_retriever(llm, retriever, contextualize_q_prompt)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
return rag_chain
This function creates our RAG chain:
It initializes the language model (
ChatOpenAI) with the specified model name.Creates a history-aware retriever that can understand context from previous interactions.
Sets up a question-answering chain that combines retrieved documents to generate an answer.
Finally, it creates the full RAG chain by combining the retriever and question-answering chain.
Integration with Main Application
In our main.py, we use this RAG chain in the chat endpoint:
@app.post("/chat", response_model=QueryResponse)
def chat(query_input: QueryInput):
# ... (other code)
rag_chain = get_rag_chain(query_input.model.value)
answer = rag_chain.invoke({
"input": query_input.question,
"chat_history": chat_history
})['answer']
# ... (rest of the function)
This shows how the RAG chain is instantiated with the user-specified model and invoked with the user's question and chat history.
By centralizing our LangChain logic in langchain_utils.py, we maintain a clean separation of concerns and make it easier to modify or extend our RAG system in the future. This modular approach allows us to easily experiment with different models, retrievers, or chain structures without affecting the rest of the application.
Conclusion
Throughout this tutorial, we've walked through the process of building a production-ready Retrieval-Augmented Generation (RAG) chatbot using FastAPI and LangChain. Let's recap what we've accomplished and discuss some key takeaways and potential next steps.
What We've Built
FastAPI Application (
main.py): We created a robust API with endpoints for chat interactions, document management, and system information.Data Models (
pydantic_models.py): We defined clear, type-safe models for our API's requests and responses.Database Utilities (
db_utils.py): We implemented SQLite database operations for managing chat logs and document metadata.Vector Store Integration (
chroma_utils.py): We set up document indexing and retrieval using the Chroma vector store.LangChain RAG Implementation (
langchain_utils.py): We created a flexible, history-aware RAG chain using LangChain components.
This architecture allows for a scalable, maintainable, and extensible RAG system that can be deployed in a production environment.
Potential Improvements and Extensions
Authentication and Authorization: Implement user authentication to secure the API and enable user-specific document access.
Asynchronous Processing: Convert synchronous operations to asynchronous for better performance, especially for document processing.
Advanced Retrieval Techniques: Experiment with techniques like hybrid search or re-ranking to improve retrieval quality.
Monitoring and Logging: Implement comprehensive logging and monitoring for better observability in production.
Scalability: Consider distributed architectures for handling larger document collections and higher request volumes.
Fine-tuning: Explore fine-tuning the language model on domain-specific data for improved performance.
UI Integration: Develop a user interface (e.g., a web application or chat interface) to interact with the API.
Containerization: Package the application using Docker for easier deployment and scaling.
Testing: Implement comprehensive unit and integration tests to ensure system reliability.
Caching: Introduce caching mechanisms to improve response times for frequent queries.
Final Thoughts
Building a production-ready RAG chatbot involves more than just connecting a language model to a document store. It requires careful consideration of data flow, error handling, scalability, and user experience. The system we've built provides a solid foundation that can be adapted and extended to meet specific business needs.
As AI and natural language processing technologies continue to evolve, systems like this will become increasingly important for creating intelligent, context-aware applications. By understanding the principles and components of RAG systems, you're well-equipped to build and improve upon this technology in your own projects.
Remember, the key to a successful RAG system lies not just in the individual components, but in how they work together to create a seamless, intelligent interaction. Continual testing, monitoring, and refinement based on real-world usage will be crucial to ensuring the long-term success and effectiveness of your RAG chatbot.
Additional Resources
To help you further understand and implement this RAG chatbot system, I've prepared some additional resources:
Video Tutorial: For a comprehensive walkthrough of this entire project, including live coding and explanations, check out my YouTube video:
Watch the Full RAG Chatbot Tutorial
In this video, I cover all three parts of our blog series, demonstrating the implementation details and providing additional insights.
GitHub Repository: The complete source code for this project is available on GitHub. You can clone, fork, or download the repository to explore the code in detail or use it as a starting point for your own projects:
The repository includes all the components we've discussed: the FastAPI backend, Streamlit frontend, and associated utilities.
FutureSmart AI: Your Partner in Custom NLP Solutions
At FutureSmart AI, we specialize in building custom Natural Language Processing (NLP) solutions tailored to your specific needs. Our expertise extends beyond RAG systems to include:
Natural Language to SQL (NL2SQL) interfaces
Advanced document parsing and analysis
Custom chatbots and conversational AI
And much more in the realm of NLP and AI
We've successfully implemented these technologies for various industries, helping businesses leverage the power of AI to enhance their operations and user experiences.
Interested in Learning More?
Check out our case studies: FutureSmart AI Case Studies Explore real-world applications of our NLP solutions and see how they've transformed businesses across different sectors.
Get in touch: Have a project in mind or want to discuss how NLP can benefit your business? We'd love to hear from you! Contact us at contact@futuresmart.ai
Whether you're looking to implement a RAG system like the one we've built in this tutorial, or you have more specific NLP needs, our team at FutureSmart AI is here to help turn your AI aspirations into reality.
Subscribe to my newsletter
Read articles from Pradip Nichite directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pradip Nichite
Pradip Nichite
🚀 I'm a Top Rated Plus NLP freelancer on Upwork with over $300K in earnings and a 100% Job Success rate. This journey began in 2022 after years of enriching experience in the field of Data Science. 📚 Starting my career in 2013 as a Software Developer focusing on backend and API development, I soon pursued my interest in Data Science by earning my M.Tech in IT from IIIT Bangalore, specializing in Data Science (2016 - 2018). 💼 Upon graduation, I carved out a path in the industry as a Data Scientist at MiQ (2018 - 2020) and later ascended to the role of Lead Data Scientist at Oracle (2020 - 2022). 🌐 Inspired by my freelancing success, I founded FutureSmart AI in September 2022. We provide custom AI solutions for clients using the latest models and techniques in NLP. 🎥 In addition, I run AI Demos, a platform aimed at educating people about the latest AI tools through engaging video demonstrations. 🧰 My technical toolbox encompasses: 🔧 Languages: Python, JavaScript, SQL. 🧪 ML Libraries: PyTorch, Transformers, LangChain. 🔍 Specialties: Semantic Search, Sentence Transformers, Vector Databases. 🖥️ Web Frameworks: FastAPI, Streamlit, Anvil. ☁️ Other: AWS, AWS RDS, MySQL. 🚀 In the fast-evolving landscape of AI, FutureSmart AI and I stand at the forefront, delivering cutting-edge, custom NLP solutions to clients across various industries.