Building a User-Friendly Interface with Streamlit for Our RAG Chatbot
 Pradip Nichite
Pradip NichiteTable of contents
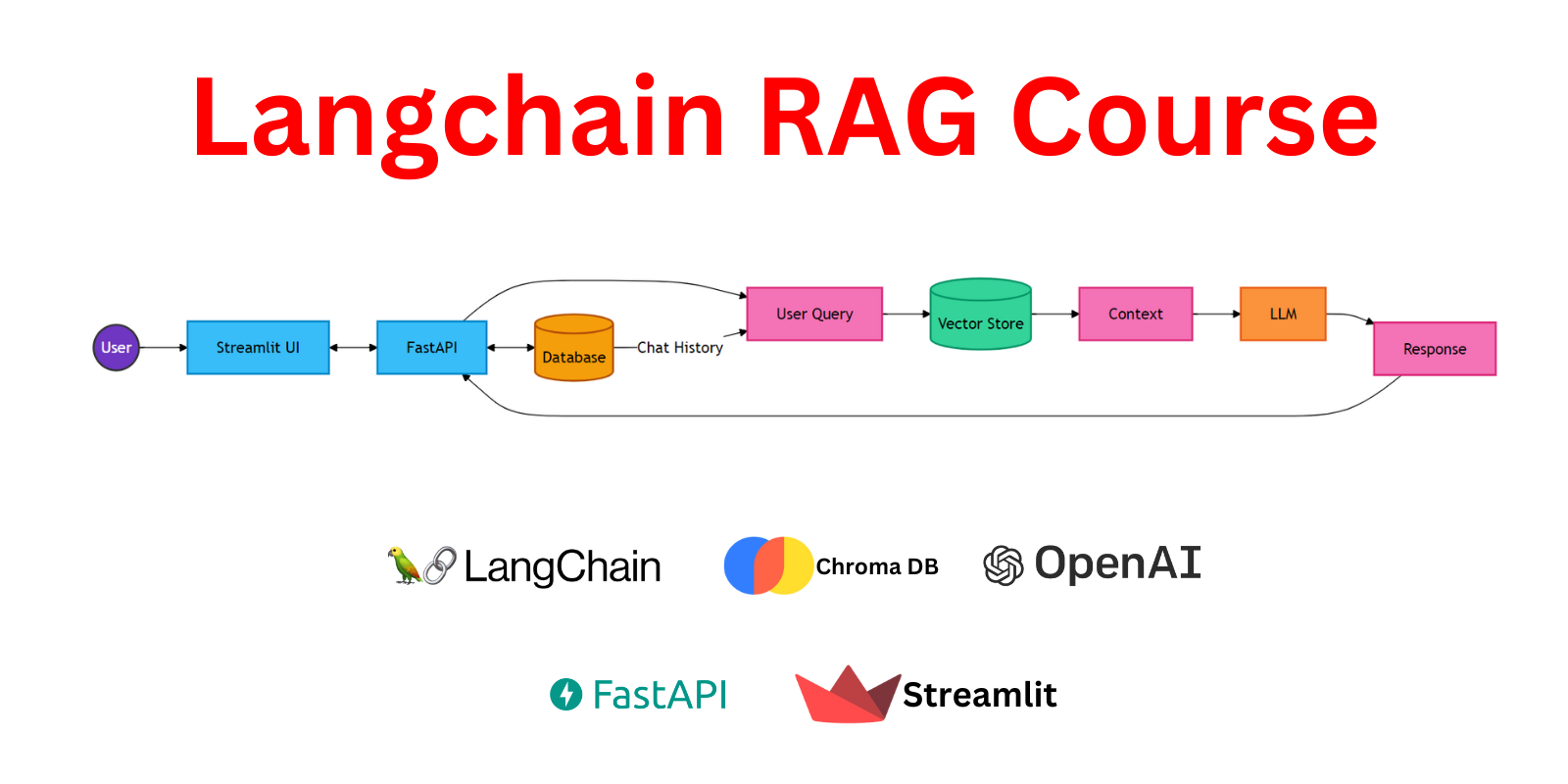
In this section, we'll explore how we've used Streamlit to create an intuitive front-end for our RAG chatbot. This interface allows users to interact with the chatbot, upload documents, and manage their document collection, all while communicating seamlessly with our FastAPI backend.
1. Main Application Structure (streamlit_app.py)
import streamlit as st
from sidebar import display_sidebar
from chat_interface import display_chat_interface
st.title("Langchain RAG Chatbot")
# Initialize session state variables
if "messages" not in st.session_state:
st.session_state.messages = []
if "session_id" not in st.session_state:
st.session_state.session_id = None
# Display the sidebar
display_sidebar()
# Display the chat interface
display_chat_interface()
This file serves as the entry point for our Streamlit application. Here's what it does:
Sets up the main title of the application.
Initializes session state variables:
messages: Stores the chat history.session_id: Keeps track of the current chat session.
Calls functions to display the sidebar and chat interface.
The use of st.session_state is crucial here. It allows us to persist data across reruns of the Streamlit app, ensuring that chat history and session information are maintained.
2. Sidebar Functionality (sidebar.py)
The sidebar handles document management and model selection:
import streamlit as st
from api_utils import upload_document, list_documents, delete_document
def display_sidebar():
# Model selection
model_options = ["gpt-4o", "gpt-4o-mini"]
st.sidebar.selectbox("Select Model", options=model_options, key="model")
# Document upload
uploaded_file = st.sidebar.file_uploader("Choose a file", type=["pdf", "docx", "html"])
if uploaded_file and st.sidebar.button("Upload"):
with st.spinner("Uploading..."):
upload_response = upload_document(uploaded_file)
if upload_response:
st.sidebar.success(f"File uploaded successfully with ID {upload_response['file_id']}.")
st.session_state.documents = list_documents()
# List and delete documents
st.sidebar.header("Uploaded Documents")
if st.sidebar.button("Refresh Document List"):
st.session_state.documents = list_documents()
# Display document list and delete functionality
if "documents" in st.session_state and st.session_state.documents:
for doc in st.session_state.documents:
st.sidebar.text(f"{doc['filename']} (ID: {doc['id']})")
selected_file_id = st.sidebar.selectbox("Select a document to delete",
options=[doc['id'] for doc in st.session_state.documents])
if st.sidebar.button("Delete Selected Document"):
delete_response = delete_document(selected_file_id)
if delete_response:
st.sidebar.success(f"Document deleted successfully.")
st.session_state.documents = list_documents()
Key features:
Model Selection: Users can choose between different language models.
Document Upload: Allows users to upload PDF, DOCX, or HTML files.
Document Listing: Displays all uploaded documents with their IDs.
Document Deletion: Provides an option to delete selected documents.
Each action (upload, list, delete) interacts with our FastAPI backend through functions in api_utils.py.
3. Chat Interface (chat_interface.py)
This component handles the main chat interaction:
import streamlit as st
from api_utils import get_api_response
def display_chat_interface():
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Handle new user input
if prompt := st.chat_input("Query:"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# Get API response
with st.spinner("Generating response..."):
response = get_api_response(prompt, st.session_state.session_id, st.session_state.model)
if response:
st.session_state.session_id = response.get('session_id')
st.session_state.messages.append({"role": "assistant", "content": response['answer']})
with st.chat_message("assistant"):
st.markdown(response['answer'])
with st.expander("Details"):
st.subheader("Generated Answer")
st.code(response['answer'])
st.subheader("Model Used")
st.code(response['model'])
st.subheader("Session ID")
st.code(response['session_id'])
else:
st.error("Failed to get a response from the API. Please try again.")
Key features:
Displays the entire chat history.
Handles new user inputs and sends them to the API.
Shows the chatbot's responses in a chat-like interface.
Provides an expandable section with additional details about each response.
The chat interface maintains continuity by using the session_id returned from the API, allowing for context-aware conversations.
4. API Utilities (api_utils.py)
This file contains functions for interacting with our FastAPI backend:
import requests
import streamlit as st
def get_api_response(question, session_id, model):
headers = {'accept': 'application/json', 'Content-Type': 'application/json'}
data = {"question": question, "model": model}
if session_id:
data["session_id"] = session_id
try:
response = requests.post("http://localhost:8000/chat", headers=headers, json=data)
if response.status_code == 200:
return response.json()
else:
st.error(f"API request failed with status code {response.status_code}: {response.text}")
return None
except Exception as e:
st.error(f"An error occurred: {str(e)}")
return None
def upload_document(file):
try:
files = {"file": (file.name, file, file.type)}
response = requests.post("http://localhost:8000/upload-doc", files=files)
if response.status_code == 200:
return response.json()
else:
st.error(f"Failed to upload file. Error: {response.status_code} - {response.text}")
return None
except Exception as e:
st.error(f"An error occurred while uploading the file: {str(e)}")
return None
def list_documents():
try:
response = requests.get("http://localhost:8000/list-docs")
if response.status_code == 200:
return response.json()
else:
st.error(f"Failed to fetch document list. Error: {response.status_code} - {response.text}")
return []
except Exception as e:
st.error(f"An error occurred while fetching the document list: {str(e)}")
return []
def delete_document(file_id):
headers = {'accept': 'application/json', 'Content-Type': 'application/json'}
data = {"file_id": file_id}
try:
response = requests.post("http://localhost:8000/delete-doc", headers=headers, json=data)
if response.status_code == 200:
return response.json()
else:
st.error(f"Failed to delete document. Error: {response.status_code} - {response.text}")
return None
except Exception as e:
st.error(f"An error occurred while deleting the document: {str(e)}")
return None
These functions handle all communication with our FastAPI backend:
get_api_response: Sends chat queries and receives responses.upload_document: Handles file uploads to the backend.list_documents: Retrieves the list of uploaded documents.delete_document: Sends requests to delete specific documents.
Each function includes error handling and user feedback through Streamlit's st.error() function.
Integration and Data Flow
User Interaction:
- Users interact with the Streamlit interface, entering queries or managing documents.
Streamlit to FastAPI:
User actions trigger API calls to our FastAPI backend.
For example, when a user sends a chat message,
get_api_response()is called, which sends a POST request to the/chatendpoint.
FastAPI Processing:
- The backend processes these requests, interacting with the RAG system, database, and vector store as needed.
Response Handling:
Responses from the API are processed and displayed in the Streamlit interface.
For chat, responses are added to the chat history and displayed.
For document operations, success messages or error notifications are shown.
State Management:
- Streamlit's session state (
st.session_state) is used to maintain chat history and current session information across interactions.
- Streamlit's session state (
Key Benefits of This Implementation
User-Friendly Interface: Streamlit provides an intuitive, interactive interface for our RAG chatbot.
Real-Time Interaction: Users can chat, upload documents, and manage their document collection in real-time.
Seamless Integration: The Streamlit frontend integrates smoothly with our FastAPI backend.
Stateful Conversations: The use of session IDs allows for context-aware, stateful conversations.
Flexible Document Management: Users can easily upload, view, and delete documents, enhancing the RAG system's utility.
Conclusion
This Streamlit implementation creates a user-friendly front-end for our RAG chatbot, effectively bridging the gap between the sophisticated backend we built and the end-user. It demonstrates how Streamlit can be used to rapidly develop interactive web applications that interface with complex AI systems.
The modular structure and clear separation of concerns between the frontend and backend allow for easy maintenance and future enhancements. As the application grows, you can easily add new features, improve the user interface, and scale the backend to handle more users and larger document collections.
This implementation completes our RAG chatbot project, providing an accessible interface for users to leverage the power of retrieval-augmented generation in their interactions with the AI model.
Certainly! Adding links to your YouTube video and GitHub repository is an excellent way to provide additional resources for your readers. Let's add this information to the conclusion of your blog post.
In this series, we've walked through the process of building a production-ready Retrieval-Augmented Generation (RAG) chatbot using FastAPI, LangChain, and Streamlit. We've covered everything from the core concepts of RAG systems to implementing a robust backend API and creating an intuitive user interface.
Here's a quick recap of what we've accomplished:
Built a RAG system using LangChain, integrating language models with document retrieval.
Developed a FastAPI backend to handle chat interactions and document management.
Created a user-friendly Streamlit frontend for seamless interaction with our RAG chatbot.
This project demonstrates the power of combining modern AI technologies with web development frameworks to create sophisticated, yet accessible applications.
Additional Resources
To help you further understand and implement this RAG chatbot system, I've prepared some additional resources:
Video Tutorial: For a comprehensive walkthrough of this entire project, including live coding and explanations, check out my YouTube video:
Watch the Full RAG Chatbot Tutorial
In this video, I cover all three parts of our blog series, demonstrating the implementation details and providing additional insights.
GitHub Repository: The complete source code for this project is available on GitHub. You can clone, fork, or download the repository to explore the code in detail or use it as a starting point for your own projects:
The repository includes all the components we've discussed: the FastAPI backend, Streamlit frontend, and associated utilities.
Thank you for following along with this series. I hope you've found it informative and inspiring for your own AI development journey. Happy coding!
FutureSmart AI: Your Partner in Custom NLP Solutions
At FutureSmart AI, we specialize in building custom Natural Language Processing (NLP) solutions tailored to your specific needs. Our expertise extends beyond RAG systems to include:
Natural Language to SQL (NL2SQL) interfaces
Advanced document parsing and analysis
Custom chatbots and conversational AI
And much more in the realm of NLP and AI
We've successfully implemented these technologies for various industries, helping businesses leverage the power of AI to enhance their operations and user experiences.
Interested in Learning More?
Check out our case studies: FutureSmart AI Case Studies Explore real-world applications of our NLP solutions and see how they've transformed businesses across different sectors.
Get in touch: Have a project in mind or want to discuss how NLP can benefit your business? We'd love to hear from you! Contact us at contact@futuresmart.ai
Whether you're looking to implement a RAG system like the one we've built in this tutorial, or you have more specific NLP needs, our team at FutureSmart AI is here to help turn your AI aspirations into reality.
Subscribe to my newsletter
Read articles from Pradip Nichite directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pradip Nichite
Pradip Nichite
🚀 I'm a Top Rated Plus NLP freelancer on Upwork with over $300K in earnings and a 100% Job Success rate. This journey began in 2022 after years of enriching experience in the field of Data Science. 📚 Starting my career in 2013 as a Software Developer focusing on backend and API development, I soon pursued my interest in Data Science by earning my M.Tech in IT from IIIT Bangalore, specializing in Data Science (2016 - 2018). 💼 Upon graduation, I carved out a path in the industry as a Data Scientist at MiQ (2018 - 2020) and later ascended to the role of Lead Data Scientist at Oracle (2020 - 2022). 🌐 Inspired by my freelancing success, I founded FutureSmart AI in September 2022. We provide custom AI solutions for clients using the latest models and techniques in NLP. 🎥 In addition, I run AI Demos, a platform aimed at educating people about the latest AI tools through engaging video demonstrations. 🧰 My technical toolbox encompasses: 🔧 Languages: Python, JavaScript, SQL. 🧪 ML Libraries: PyTorch, Transformers, LangChain. 🔍 Specialties: Semantic Search, Sentence Transformers, Vector Databases. 🖥️ Web Frameworks: FastAPI, Streamlit, Anvil. ☁️ Other: AWS, AWS RDS, MySQL. 🚀 In the fast-evolving landscape of AI, FutureSmart AI and I stand at the forefront, delivering cutting-edge, custom NLP solutions to clients across various industries.