Using Custom Python Libraries Without Fabric Environment
 William Crayger
William Crayger
Fabric Environment artifacts, where to begin…
If you’re not familiar, the environment artifact, in part, is intended to mimic the functionality of the Synapse Workspace by allowing you to do things like install packages for easy reusability across your Spark workloads.
Conceptually, I love the idea of having the ability to pre-define my spark pool configurations and easily install my custom python libraries. However, the current state of the environment item leaves a lot to desire.
During active development cycles, using an environment has actually increased my development time exponentially simply due to how long it takes to publish changes. The UI often reflects inaccurate information regarding the state of your installed libraries, reflecting libraries that no longer exist or wanting me to publish changes that will delete my library without me asking to do so.
I would often open my environment to see the following:
Seemingly, it appears the environment doesn’t recognize the state of the packages installed and often wants to remove them.
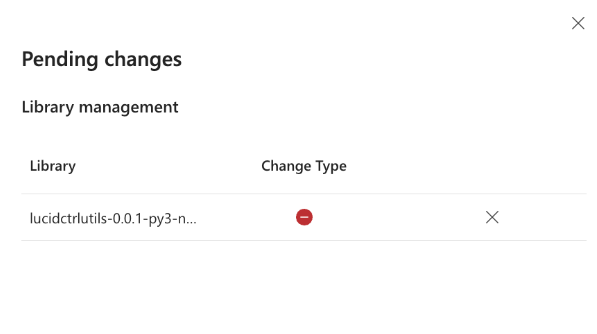
Taking the various bugs into consideration along with the immediate loss of using the starter pools really makes it challenging to see the benefits. As such, I’ve stopped using them altogether in favor of a more efficient approach that allows me to continue using starter pools while still leveraging my reusable libraries.
Before we start, if you’re not familiar with creating and managing .whl files I recommend checking out my buddy Sandeep’s blog:
Installing and Managing Python Packages in Microsoft Fabric
When working with custom packages, .whl files are how you package up and deploy your code. The .whl files are what would be installed to your Fabric library or Synapse Workspace as a prerequisite for installing them in your notebook.
However, we can also use inline installation by running a command such as:
# Install lucid python utility library
!pip install /lakehouse/default/Files/python_utility/lucidctrlutils-0.0.1-py3-none-any.whl
But, what if you want to install from a location other than the default lakehouse for the notebook, or a notebook without an attached lakehouse at all?
For example, when creating a new feature branch, notebooks retain attachment defaults from the state in which they were branched from. Said differently, your notebook will remain attached to the default lakehouse in the workspace your feature branch originated from (this warrants an entire blog post on its own). In this scenario, if you’re wanting to test modifications to your library you have to shuffle through the notebook and lakehouse settings which gets quite redundant.
Instead of doing the notebook dance, you can do something like this:
try:
# Define the ADLS path and local file path
install_path = "abfss://xxxxxxx@onelake.dfs.fabric.microsoft.com/xxxxxxx/Files/ctrlPythonLibrary/lucidctrlutils-0.0.1-py3-none-any.whl"
local_filename = "/tmp/lucidctrlutils-0.0.1-py3-none-any.whl"
# Use mssparkutils to copy the file from storage account to the local filesystem
mssparkutils.fs.cp(install_path, f"file:{local_filename}", True)
# Install the .whl file locally using pip
!pip install {local_filename}
# Import modules for data processing
from lucid_ctrl_utils import *
print("Successfully installed the utility library.")
except Exception as e:
print(f"An error occurred while installing the utility library: {str(e)}")
The above snippet reads the .whl file from your specified path, copies it to a temp directory, and allows you to execute !pip install. However, this code still requires you to manually update the install_path. Surely, we can do better.
In my scenario, I want to use the lakehouse name as my storage identifier instead of the GUID so we’ll have to write a bit more code.
try:
# Install semantic link
!pip install semantic-link --q
import sempy.fabric as fabric
# Set lakehouse name
lakehouse_name = 'stage'
# Get workspace id and list of items in one step
notebook_workspace_id = fabric.get_notebook_workspace_id()
df_items = fabric.list_items(workspace=notebook_workspace_id)
# Filter the dataframe by 'Display Name' and 'Type'
df_filtered = df_items.query(f"`Display Name` == '{lakehouse_name}' and `Type` == 'Lakehouse'")
# Ensure there's at least one matching row
if df_filtered.empty:
raise ValueError("No matching rows found for Display Name = 'stage' and Type = 'Lakehouse'")
# Get the 'Id' from the filtered row
stage_lakehouse_id = df_filtered['Id'].iloc[0]
except ValueError as ve:
# Handle specific errors for value-related issues
raise ve
except Exception as e:
# Catch and raise any unexpected exceptions
raise ValueError(f"An error occurred: {str(e)}")
The above code uses semantic-link to dynamically access the GUIDs for the workspace and lakehouse for my feature branch, removing the need to hardcode these values in install_path. Now, I can construct the path without any manual input.
try:
# Define the ADLS path and local file path
install_path = f"abfss://{notebook_workspace_id}@onelake.dfs.fabric.microsoft.com/{stage_lakehouse_id}/Files/ctrlPythonLibrary/lucidctrlutils-0.0.1-py3-none-any.whl"
local_filename = "/tmp/lucidctrlutils-0.0.1-py3-none-any.whl"
# Use mssparkutils to copy the file from storage account to the local filesystem
mssparkutils.fs.cp(install_path, f"file:{local_filename}", True)
# Install the .whl file locally using pip
!pip install {local_filename} --no-cache-dir --q > /dev/null 2>&1
# Import modules for data processing
from lucid_ctrl_utils import *
print("Successfully installed the utility library.")
except Exception as e:
print(f"An error occurred while installing the utility library: {str(e)}")
Great, we now have the library installed. But, this is a lot of code to move around to all my notebooks. The overhead introduced is going to be a PITA, right? Well, we can optimize one step further by keeping this in an isolated “utility” notebook and activate it using the %run command in subsequent notebooks.
%run nb_lucid_ctrl_utils
So, why go through all this effort? Why not use the environment item? Well, there’s a few reasons beyond avoiding the bugs mentioned earlier in the article.
With this approach I get to abuse the quick spin-up time of the starter pool rather than waiting 90+ seconds for a custom pool to come online.

If I gained nothing else, this is a huge W in my opinion. However, this also solves a REALLY frustrating issue with branching, which I’ll address in another blog coming soon.
If you'd like to learn more about how Lucid can support your team, let's connect on LinkedIn and schedule an intro call.
Subscribe to my newsletter
Read articles from William Crayger directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by