Learning AWS Day by Day — Day 81 — Disaster Recovery — Part 1
 Saloni Singh
Saloni Singh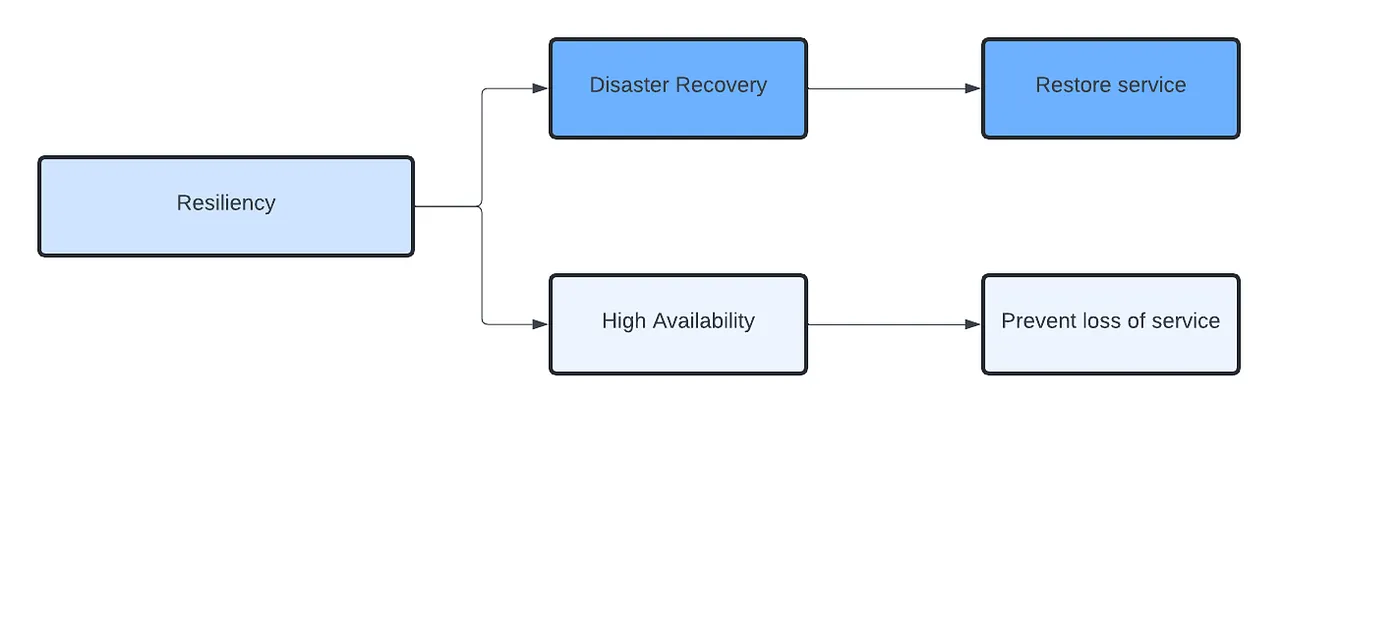
Exploring AWS!
Day 81:
Disaster Recovery (DR) — Part 1

For any tools or services you use, we prefer having some backup always, or atleast something that can support you in the times when you really need something and the main primary part has failed. Lets say, your battery just drains out and there is no power, your power bank always saves you there, but imagined what if there was no power bank as well? And you had some important call to attend?
Do you remember the Flight 777, it gives us an idea why resiliency is important, that was the plane which caught fire and somehow managed to land with only one engine working, so they had to keep the high availability and proper maintenance for these jet engines which are a business contiguity.
Now you see, its important to have a disaster recovery, even if you have a backup
About Business Contiguity:
There are various types of disasters, some larger scaled, less frequent events like Natural disasters including floods or fire or tsunamis or might be earthquakes. Then we have technical disasters like human actions, maybe hacking or intentional deletions.
This contiguity term measures a one time event: Recovery Time, Recovery Point.
High Availability: About application availability, smaller scaled which have to face more frequent events like component failures, network issues, load spikes, etc.
The measures mean over time which are ‘The 9s’ (99.99% availability).
So, Disaster Recovery is recovering from a loss of service due to some event or disaster, whereas High Availability is all about preventing these.
What is a disaster?
We all know about AWS Regions and AZs, these regions are the physical locations around the world where we cluster data centres. 33 geographic regions around the world, with announced plans for 12 more AZs and 4 more regions in Germany, Malaysia, New Zealand and Thailand.
These AZs, they are placed at proper distance for better operation to avoid disasters, but close enough to allow synchronous replications. So you can say, maximum distance of 60 miles or 100 kms.
We need to think of types of disasters when planning these DR strategies and what can be the outcome and effect of such a disaster on your data.
Shared Responsibility model for Resiliency: AWS & Customer responsible.
Customer Responsibility for resiliency ‘IN’ the cloud:
Server data backup
Workload architecture
Change management
Failure management
Networking, Quotas and Constraints
AWS Responsibilty for resiliency ‘OF’ the cloud:
Hardware and services
Compute, Storage Database, Networking
AWS Global Infrastructure
Regions, AZs, Edge locations
Note: High Availability is not a DR.
Subscribe to my newsletter
Read articles from Saloni Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saloni Singh
Saloni Singh
• A Software Engineer with hands-on experience in AWS and Aws DevOps • Experience in CodePipeline using CodeCommit, CodeBuild and CodeDeploy • Experience with Terraform, Gitlab, Kubernetes, AWS DevOps, Helm charts, Golang, Python and NodeJS • Hands-on experience on AWS Migration projects including services - DMS, Glue, Aurora, Lambda, S3 • Possesses good knowledge on Bash Shell Scripting and Python Programming