How to Find and Replace Text in PDF with Python: A Developer’s Guide
 Casie Liu
Casie Liu
When working with PDF files, it's common to update information like changing dates, names, or other specific data. However, dealing with large PDFs can quickly become a tedious task. While many PDF tools, such as Adobe Acrobat, offer built-in "Find and Replace" features, manually processing multiple files is still time-consuming. In this article, we’ll introduce a faster and more efficient alternative: using Python to find and replace text in PDF documents, streamlining your workflow, and saving valuable time.
Python Library to Find and Replace Text in PDF
In this blog, to finish the task, it is recommended to try Spire.PDF for Python. This tool is one of the best Adobe Acrobat alternatives. You can use it to perform almost all the functions Adobe Acrobat offers, such as creating, editing, compressing, and converting PDF documents. One of its standout features is its ability to quickly handle multiple tasks, eliminating the need to wait for Adobe Acrobat to load and process files.
Install it by the pip command: pip install Spire.PDF
How to Find and Replace the First Match Text in PDF
Generally, there are two types of find and replace operations: replacing only the first matching text and replacing all matching instances. In this section, we'll focus on the first type.
Spire provides the PdfTextReplacer.ReplaceText() method to accomplish this. By creating an instance of the PdfTextReplacer class and calling the method, you can accurately find and replace specific words, phrases, or sentences within the PDF.
Steps to find and replace the first matching word in PDF:
Create an object of the PdfDocument class, and load a PDF file from the local storage using the PdfDocument.LoadFromFile() method.
Get a certain page with the Pages.get_Item() method.
Create a PdfTextReplacer instance.
Find and replace the first matching text by calling the PdfTextReplacer.ReplaceText() method.
Save the modified PDF as a new PDF document with the PdfDocument.SaveToFile() method and close the document.
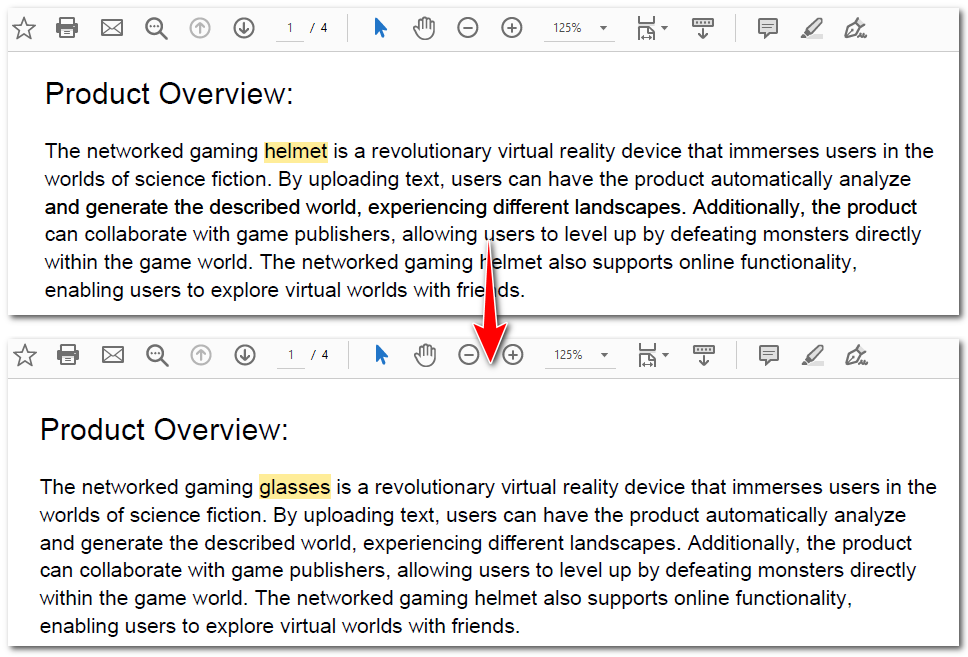
Here is the code example of finding the first “helmet” and replacing it with “glasses”:
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("/sample.pdf")
# Get a page in the PDF document
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class
replacer = PdfTextReplacer(page)
# Find and replace the first matched text
replacer.ReplaceText("helmet", "glasses")
# Save the document
pdf.SaveToFile("/ReplaceFirstMatch.pdf")
# Release the document
pdf.Close()
Find and Replace All Matching Text in PDF with Python
In this part, we are going to take a step further and review how to find and replace all matching text in PDF. Considering that PDF files often contain multiple pages, if you want to replace all matching text at once, you'll need to loop through all pages before applying the find and replacements. After locating the text, you can use the appropriate method to perform the replacements on each page efficiently. Let’s take a closer look.
Steps to search and replace all matching text in PDF:
Import essential modules from Spire.PDF.
Instantiate a PdfDocument class, and specify the file path of a PDF document with the PdfDocument.LoadFromFile() method.
Iterate through all pages in the PDF and locate a certain page.
Create an object of the PdfTextReplacer class.
Replace all matching text in PDF by calling the PdfTextReplacer.ReplaceAllText() method.
Write the updated PDF document to file using the PdfDocument.SaveToFile() method and release the resource.
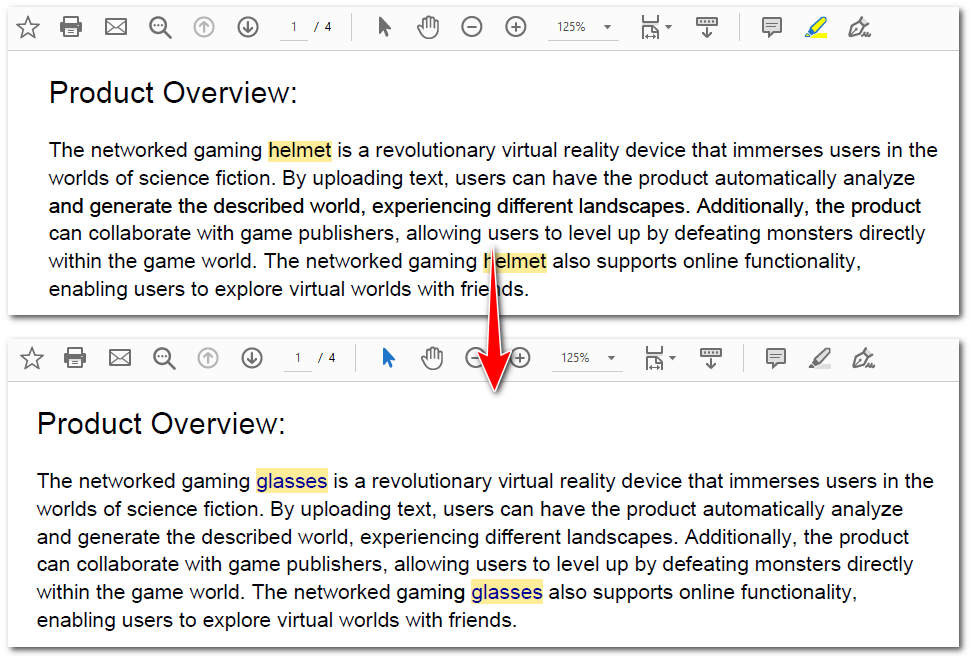
Below is the code example of finding and replacing all matching text in PDFs:
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("/sample.pdf")
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextReplacer class based on the page
replacer = PdfTextReplacer(page)
# Find and replace all matched text with a new color
replacer.ReplaceAllText("helmet", "glasses", Color.get_Blue())
# Save the document as a new PDF file
pdf.SaveToFile("/ReplaceAllMatches.pdf")
# Close the document
pdf.Close()
The Bottom Line
This page demonstrates how to find and replace text in PDF documents, whether you're replacing the first matching text or all matching instances. You'll find step-by-step instructions and real code examples to guide you through the process. After reading this article, searching and replacing text will be a breeze! We hope you find it helpful!
Subscribe to my newsletter
Read articles from Casie Liu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by